论文信息
论文标题:A Two-Stage Framework with Self-Supervised Distillation For Cross-Domain Text Classification
论文作者:Yunlong Feng, Bohan Li, Libo Qin, Xiao Xu, Wanxiang Che
论文来源:2023 aRxiv
论文地址:download
论文代码:download
视屏讲解:click
1 介绍
动机:以前的工作主要集中于提取 域不变特征 或 任务不可知特征,而忽略了存在于目标域中可能对下游任务有用的域感知特征;
贡献:
-
- 提出一个两阶段的学习框架,使现有的分类模型能够有效地适应目标领域;
- 引入自监督蒸馏,可以帮助模型更好地从目标领域的未标记数据中捕获域感知特征;
- 在 Amazon 跨域分类基准上的实验表明,取得了 SOTA ;
2 相关
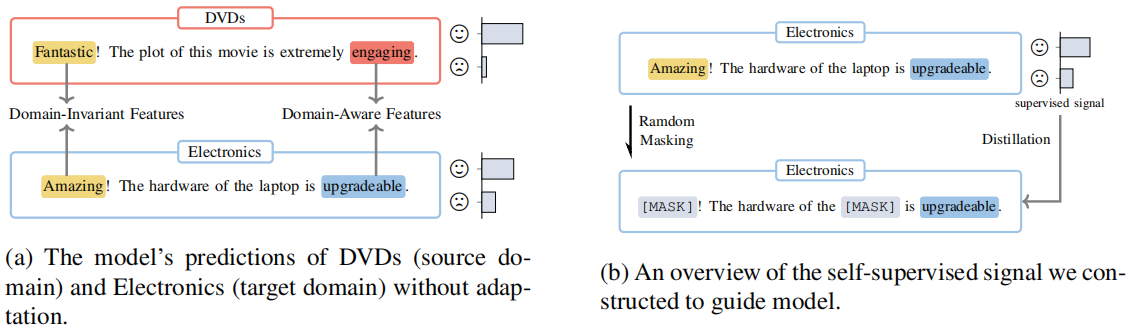
Figure 1(a):阐述域不变特征和域感知特征与任务的关系;
Figure 1(b):阐述遮蔽域不变特征和域感知特征与预测的关系:
-
- 通过掩盖域不变特征,模型建立预测和域感知特征的相关性;
- 通过掩盖域感知特征,模型加强了预测和域不变特征的关系;
一个文本提示组成如下:
$\boldsymbol{x}_{\mathrm{p}}=\text { "[CLS] } \boldsymbol{x} \text {. It is [MASK]. [SEP]"} \quad\quad(1)$
$\text{PLM}$ 将 $\boldsymbol{x}_{\mathrm{p}}$ 作为输入,并利用上下文信息用词汇表中的一个单词填充 $\text{[MASK]}$ 作为输出,输出单词随后被映射到一个标签 $\mathcal{Y}$。
PT 的目标:
$\mathcal{L}_{p m t}\left(\mathcal{D}^{\mathcal{T}} ; \theta_{\mathcal{M}}\right)=-\sum_{\boldsymbol{x}, y \in \mathcal{D}} y \log p_{\theta_{\mathcal{M}}}\left(\hat{y} \mid \boldsymbol{x}_{\mathrm{p}}\right)$
使用 $\text{MLM }$ 来避免快捷学习($\text{shortcut learning}$),并适应目标域分布。具体来说,构造了一个掩蔽文本提示符 $\boldsymbol{x}_{\mathrm{pm}}$:
$\boldsymbol{x}_{\mathrm{pm}}=\text { "[CLS] } \boldsymbol{x}_{\mathrm{m}} \text {. It is [MASK]. [SEP]"}$
其中,$m\left(y_{\mathrm{m}}\right)$ 和 $\operatorname{len}_{m\left(\boldsymbol{x}_{\mathrm{m}}\right)}$ 分别表示 $x_{\mathrm{m}}$ 中的掩码词和计数;
SSKD
核心:使模型能够在预测和目标域的域感知特征之间建立联系;
具体:模型迫使 $x_{\mathrm{p}}$ 的预测和 $\boldsymbol{x}_{\mathrm{pm}}$ 的未掩蔽词之间联系起来,本文在 $p_{\theta}\left(y \mid \boldsymbol{x}_{\mathrm{pm}}\right)$ 和 $p_{\theta}\left(y \mid \boldsymbol{x}_{\mathrm{p}}\right)$ 的预测之间进行 $\text{KD}$:
$\mathcal{L}_{s s d}\left(\mathcal{D} ; \theta_{\mathcal{M}}\right)=\sum_{\boldsymbol{x} \in \mathcal{D}} K L\left(p_{\theta_{\mathcal{M}}}\left(y \mid \boldsymbol{x}_{\mathrm{pm}}\right)|| p_{\theta_{\mathcal{M}}}\left(y \mid \boldsymbol{x}_{\mathrm{p}}\right)\right)$
注意:$\boldsymbol{x}_{\mathrm{pm}}$ 可能包含域不变、域感知特征,或两者都包含;
2 方法
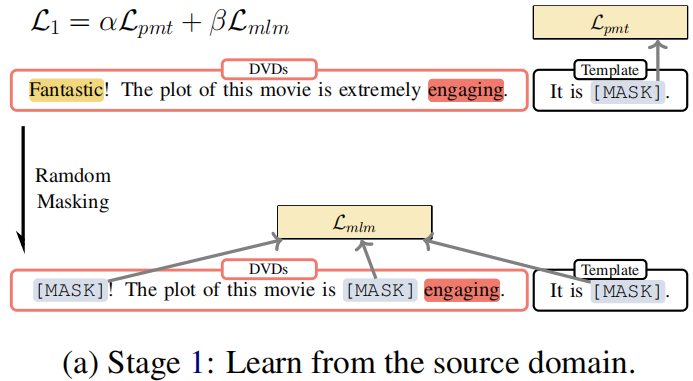
Procedure:
-
- Firstly, we calculate the classification loss of those sentences and update the parameters with the loss, as shown in line 5 of Algorithm 1.
- Then we mask the same sentence and calculate mask language modeling loss to update the parameters, as depicted in line 8 of Algorithm 1. The parameters of the model will be updated together by these two losses.
Objective:
$\begin{array}{l}\mathcal{L}_{1}^{\prime}\left(\mathcal{D}^{\mathcal{T}} ; \theta_{\mathcal{M}}\right)=\alpha \mathcal{L}_{p m t}\left(\mathcal{D}^{\mathcal{T}} ; \theta_{\mathcal{M}}\right) \\\mathcal{L}_{1}^{\prime \prime}\left(\mathcal{D}^{\mathcal{T}} ; \theta_{\mathcal{M}}\right)=\beta \mathcal{L}_{m l m}\left(\mathcal{D} ; \theta_{\mathcal{M}}\right)\end{array}$
Stage 2: Adapt to the target domain
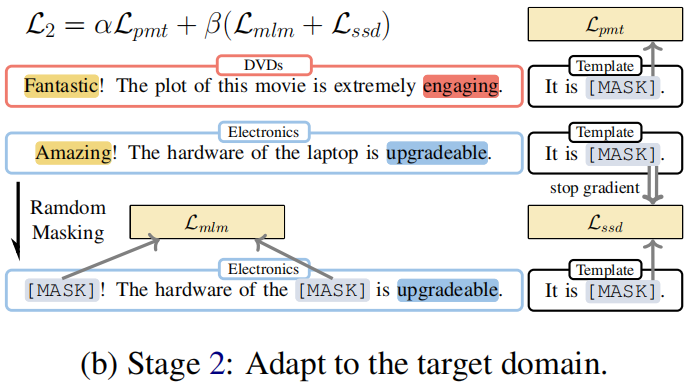
Procedure:
-
- Firstly, we sample labeled data from the source domain $\mathcal{D}_{S}^{\mathcal{T}} $ and calculate sentiment classification loss. The model parameters are updated using this loss in line 5 of Algorithm 2.
- Next, we sample unlabeled data from the target domain $\mathcal{D}_{T} $ and mask the unlabeled data to do a masking language model and selfsupervised distillation with the previous prediction.
Objective:
$\begin{aligned}\mathcal{L}_{2}^{\prime}\left(\mathcal{D}_{S}^{\mathcal{T}}, \mathcal{D}_{T} ; \theta_{\mathcal{M}}\right) & =\alpha \mathcal{L}_{p m t}\left(\mathcal{D}_{S}^{\mathcal{T}} ; \theta_{\mathcal{M}}\right) \\\mathcal{L}_{2}^{\prime \prime}\left(\mathcal{D}_{S}^{\mathcal{T}}, \mathcal{D}_{T} ; \theta_{\mathcal{M}}\right) & =\beta\left(\mathcal{L}_{m l m}\left(\mathcal{D}_{T} ; \theta_{\mathcal{M}}\right)\right. \left.+\mathcal{L}_{s s d}\left(\mathcal{D}_{T} ; \theta_{\mathcal{M}}\right)\right)\end{aligned}$
Algorithm

3 实验
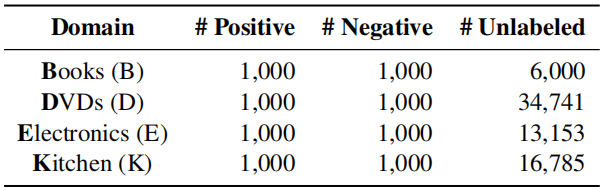
Dataset
Amazon reviews dataset
- $\text{R-PERL }$(2020): Use BERT for cross-domain text classification with pivot-based fine-tuning.
- $\text{DAAT}$ (2020): Use BERT post training for cross-domain text classification with adversarial training.
- $\text{p+CFd}$ (2020): Use XLM-R for cross-domain text classification with class-aware feature self-distillation (CFd).
- $\text{SENTIX}_{\text{Fix}}$ (2020): Pre-train a sentiment-aware language model by several pretraining tasks.
- $\text{UDALM}$ (2021): Fine-tuning with a mixed classification and MLM loss on domain-adapted PLMs.
- $\text{AdSPT}$ (2022): Soft Prompt tuning with an adversarial training object on vanilla PLMs.
- During Stage 1, we train 10 epochs with batch size 4 and early stopping (patience =3 ) on the accuracy metric. The optimizer is AdamW with learning rate 1 $\times 10^{-5}$ . And we halve the learning rate every 3 epochs. We set $\alpha=1.0$, $\beta=0.6$ for Eq.6 .
- During Stage 2, we train 10 epochs with batch size 4 and early stopping (patience =3 ) on the mixing loss of classification loss and mask language modeling loss. The optimizer is AdamW with a learning rate $1 \times 10^{-6}$ without learning rate decay. And we set $\alpha=0.5$, $\beta=0.5$ for Eq. 7 .
- In addition, for the mask language modeling objective and the self-supervised distillation objective, we randomly replace 30% of tokens to [MASK] and the maximum sequence length is set to 512 by truncation of inputs. Especially we randomly select the equal num unlabeled data from the target domain every epoch during Stage 2.
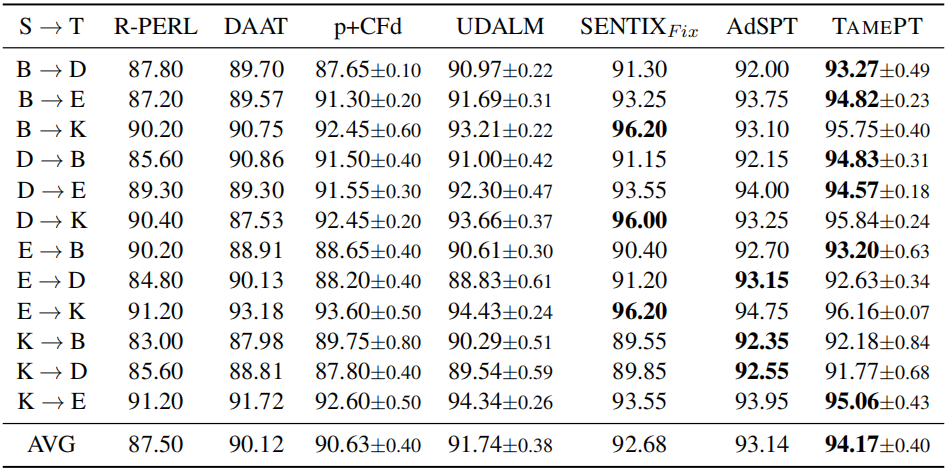
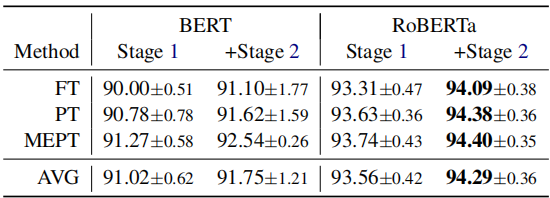
Single-source domain adaptation on Amazon reviews
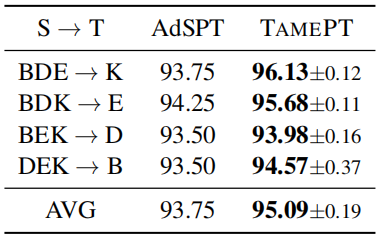
Multi-source domain adaptation on Amazon reviews
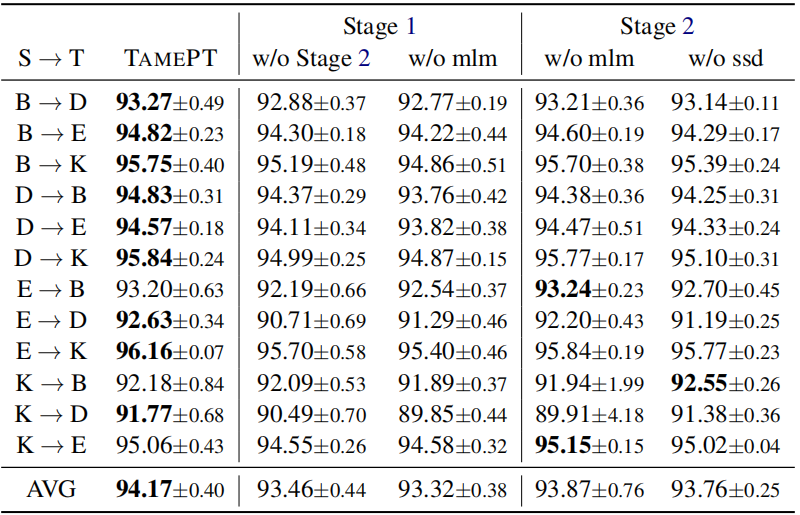
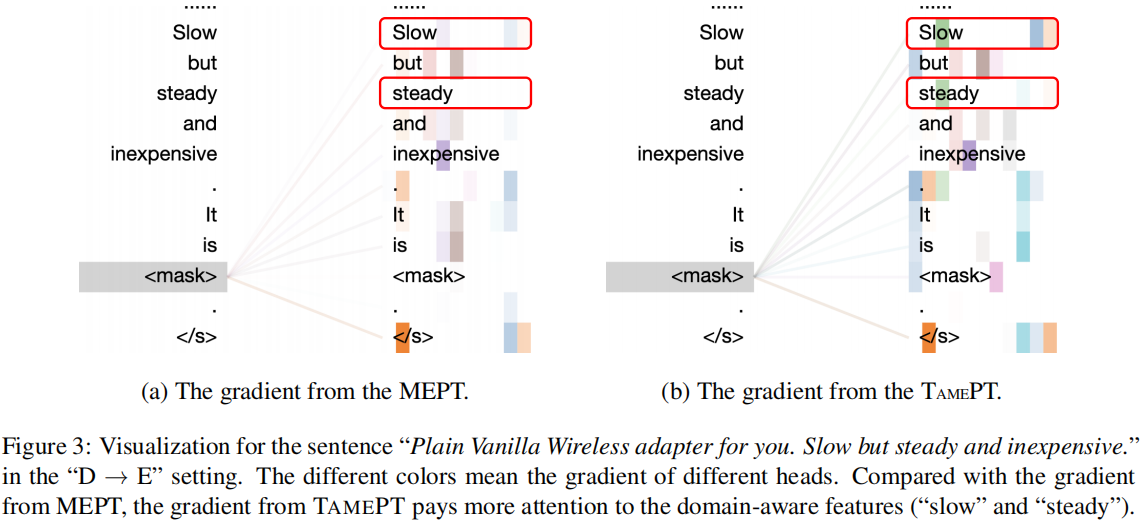

- Self-Supervised Classification Distillation Cross-Domain Supervisedself-supervised classification distillation self-supervised self-supervised exploration generative supervised self-supervised transformers lightweight supervised self-supervised interpretable adversarial generative self-supervised bidirectional supervised learning domain classification cross-domain multi-source self-supervised transformers supervised empirical classification cross-domain cnn-based learning language-guided self-supervised segmentation