DDPM

1. 大致流程
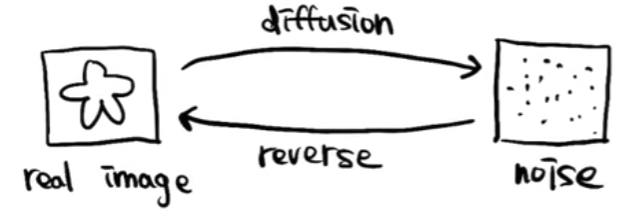
1.1 宏观流程
1.2 训练过程

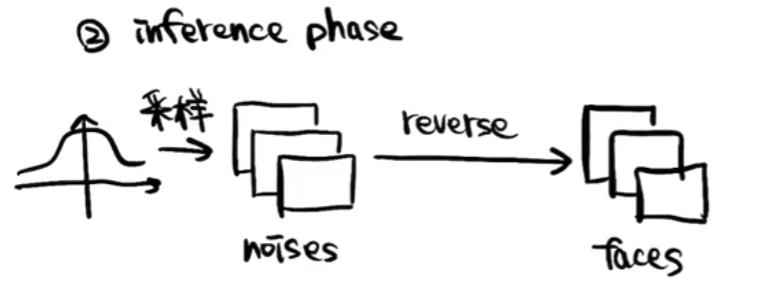
1.3 推理过程
2. 对比GAN
2.1 GAN流程

2.2 相比GAN优点
训练过程更稳定,损失函数指向性更强(loss数值大小指示训练效果好坏)
3. 详细流程
3.1 扩散阶段
如下图,X0为初始干净图像,XT由X0逐步添加噪声所得到

具体到一次Xt-1到Xt的扩散过程如下图,Zt为此时刻添加的随机噪声(服从标准正态分布),β随着时间t从0到T的过程逐步线性增大,通常扩散次数T选择1000(2000也行),选择这样的次数主要是希望最后得到的是一个完全噪声的图片,而不是还能看出图片中的内容

如上得到了每一步之间的扩散步骤,那么由最初的X0扩散到最终的XT,推导过程如下:
- 先用α替换掉β

- Xt由Xt-2表示

- Xt由X0表示

- t换成T来表示(最终XT是一个服从标准正态分布的随机噪声,即可以约等于噪声Z,即αT拔约等于0)
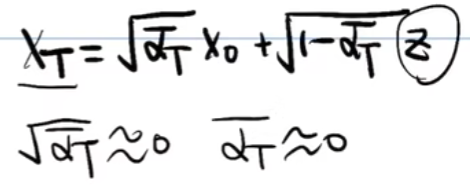
3.2 去噪重建阶段
- 大体过程
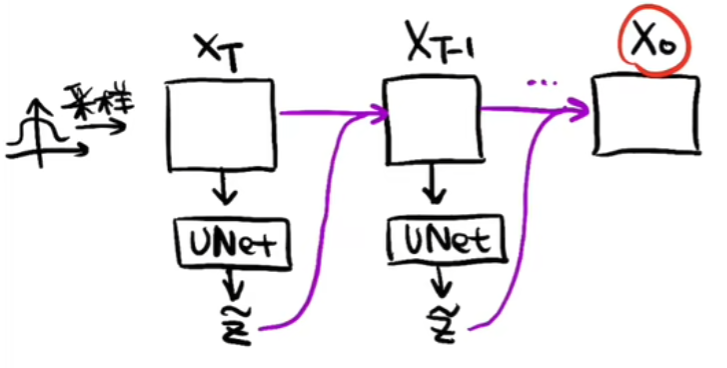
如下图,在去噪重建的过程中,先随机采样一个随机噪声XT,将XT放入U-Net预测噪声Z,然后将XT去除噪声Z得到XT-1,再将XT-1放入U-Net预测噪声...重复上述过程,直至最终预测出X0

- 用于预测噪声的U-Net如下,传入噪声Xt和t,t可以理解为positional embedding,因为在前向的扩散过程中每一时刻添加的噪声强度是不一样的,所以在进行预测的时候,预测出的每一时刻的噪声强度也是不一样的

- 如上我们已经可以使用U-Net预测出每一时刻的噪声了,那我们怎么通过预测出的噪声预测出上一时刻的图片呢?也就是怎么得到如下图的推理公式呢?
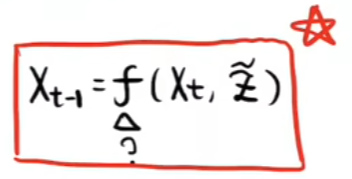
- 如下一系列图片即进行上述问题的推理
首先观察如何从Xt得到Xt-1,利用贝叶斯公式进行如下转化
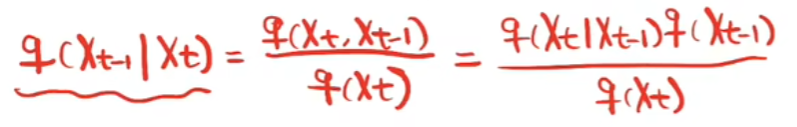
然后根据如下扩散过程推出上述每一部分的表达式


然后根据标准正态分布,求出整体表达式
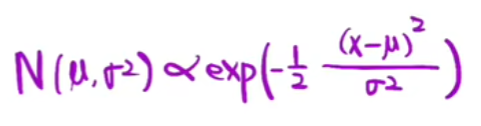
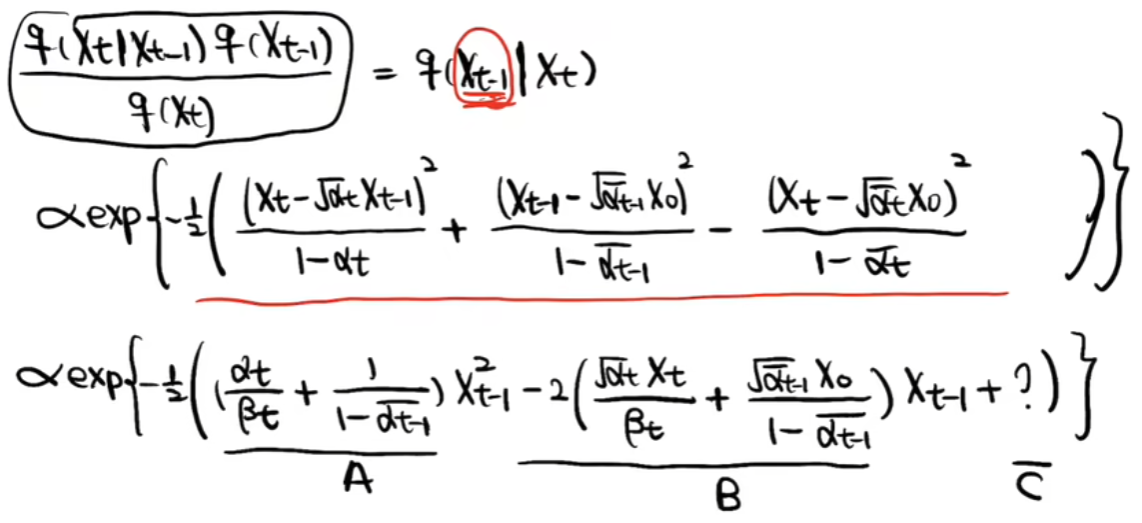
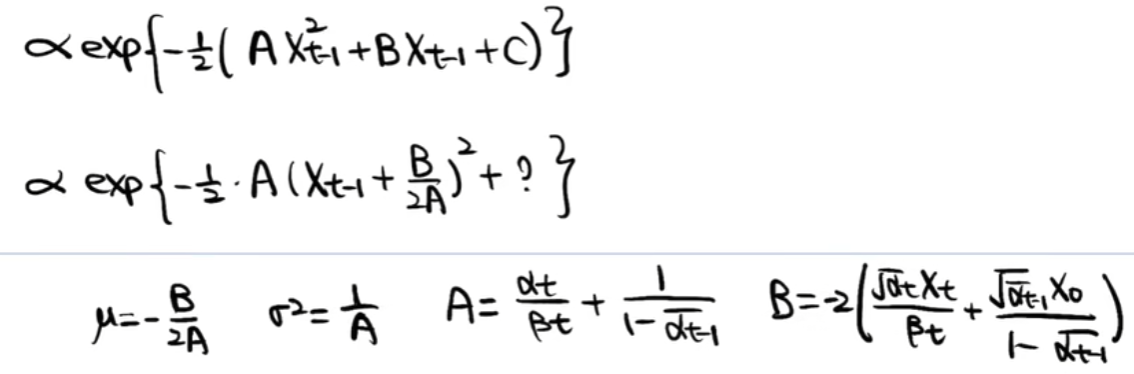

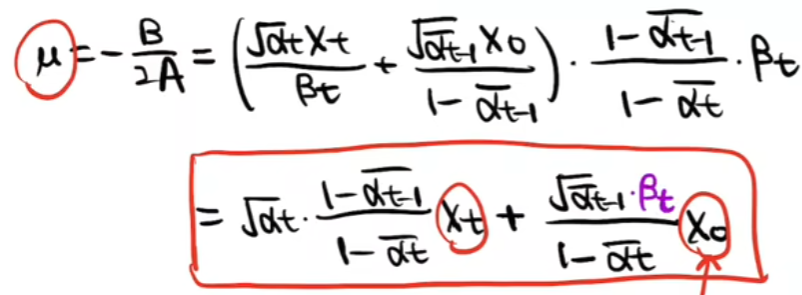


最终得出XT到XT-1的表达式

如上,便完成了一次使用U-Net预测出的噪声对随机采样的噪声去噪,接下来就是从XT一直去噪到X0的过程
4. 论文算法
4.1 Training
实际的训练过程中,没有如上所描述的那样繁琐,总的来说如下:
repeat
在均匀分布T里随机采一个t
随机采样一个标准分布的噪声ε
使用t和ε计算出Xt
将Xt和t放入U-Net预测出噪声(εθ(Xt,t)即为U-Net)
计算εθ和ε损失
until 收敛

4.2 Sampling
去噪的生成过程中,需要注意一点,当逐步去噪到t=1时,不需要再随机采样一个标准正态分布的Z,因为此时求的是X0(最后的干净图片),干净图片再添加一个噪声就变得不干净了。
