
We've trained language models that are much better at following user intentions than GPT-3 while also making them more truthful and less toxic, using techniques developed through our alignment research. These InstructGPT models, which are trained with humans in the loop, are now deployed as the default language models on our API.
January 27, 2022
我们训练的语言模型比 GPT-3 更能遵循用户意图,同时使用我们的对齐研究(alignment research)开发的技术使它们更真实、毒性更小。 这些 InstructGPT 模型是在循环中由人类训练的,现在已部署为我们 API 上的默认语言模型。
2022 年 1 月 27 日
More resources 更多资源
Language, Human feedback, Safety & Alignment, Responsible AI, Milestone, Publication
Since InstructGPT is trained to follow instructions, it can be susceptible to misuse.
由于 InstructGPT 经过训练可以遵循指令,因此很容易被误用。
Sample 1

Sample 2

Sample 3

Sample 4

Sample 5

Sample 6

GPT-3 models aren't trained to follow user instructions. Our InstructGPT models (highlighted) generate much more helpful outputs in response to user instructions.
The OpenAI API is powered by GPT-3 language models which can be coaxed to perform natural language tasks using carefully engineered text prompts. But these models can also generate outputs that are untruthful, toxic, or reflect harmful sentiments. This is in part because GPT-3 is trained to predict the next word on a large dataset of Internet text, rather than to safely perform the language task that the user wants. In other words, these models aren't aligned with their users.
GPT-3 模型并未接受过遵循用户指令的训练。我们的 InstructGPT 模型(突出显示)会根据用户指令生成更有用的输出。
OpenAI API 由 GPT-3 语言模型提供支持,可以使用精心设计的文本提示(text prompt)来引导该模型执行自然语言任务。但这些模型也可能产生不真实的(untruthful)、有毒的(toxic)或反映有害情绪(harmful sentiments)的输出。这部分是因为 GPT-3 被训练来预测大型互联网文本数据集上的下一个单词,而不是安全地执行用户想要的语言任务。换句话说,这些模型与其用户不对齐。
To make our models safer, more helpful, and more aligned, we use an existing technique called reinforcement learning from human feedback (RLHF). On prompts submitted by our customers to the API,A our labelers provide demonstrations of the desired model behavior, and rank several outputs from our models. We then use this data to fine-tune GPT-3.
为了使我们的模型更安全、更有帮助、更一致(aligned),我们使用了一种称为基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback, RLHF) 的现有技术。 根据我们的客户向 API 提交的提示,A 我们的标注人员(labelers)对期望的模型行为进行了演示,并对我们模型的多个输出进行排名。 然后我们使用这些数据来微调 GPT-3。
The resulting InstructGPT models are much better at following instructions than GPT-3. They also make up facts less often, and show small decreases in toxic output generation. Our labelers prefer outputs from our 1.3B InstructGPT model over outputs from a 175B GPT-3 model, despite having more than 100x fewer parameters. At the same time, we show that we don't have to compromise on GPT-3’s capabilities, as measured by our model’s performance on academic NLP evaluations.
These InstructGPT models, which have been in beta on the API for more than a year, are now the default language models accessible on our API.B
由此产生的 InstructGPT 模型在遵循指令方面比 GPT-3 好得多。他们编造事实的频率也较低,并且有毒输出的产生也略有减少。 尽管参数少了 100 倍以上,但与 175B GPT-3 模型的输出相比,我们的标注人员(labelers)更喜欢 1.3B InstructGPT 模型的输出。 同时,我们表明,我们无需在 GPT-3 的性能方面做出妥协,正如在学术 NLP 评估中,我们的模型性能度量指标所展现的。
这些 InstructGPT 模型已经在 API 上进行beta测试一年多了,现在是我们的API 上可访问的默认语言模型。B
We believe that fine-tuning language models with humans in the loop is a powerful tool for improving their safety and reliability, and we will continue to push in this direction.
This is the first time our alignment research, which we’ve been pursuing for several years,1,2,3 has been applied to our product. Our work is also related to recent research that fine-tunes language models to follow instructions using academic NLP datasets, notably FLAN4 and T0.5 A key motivation for our work is to increase helpfulness and truthfulness while mitigating the harms and biases of language models.6,7,8,9,10 Some of our previous research in this direction found that we can reduce harmful outputs by fine-tuning on a small curated dataset of human demonstrations.11 Other research has focused on filtering the pre-training dataset,12 safety-specific control tokens,13,14 or steering model generations.15,16 We are exploring these ideas and others in our ongoing alignment research.
我们相信,在人类参与的情况下,微调语言模型是提高其安全性和可靠性的强大工具,我们将继续朝这个方向努力。
这是我们多年来一直探索的对齐研究(alignment research)1,2,3 首次应用于我们的产品。 我们的工作还与最近的研究相关,该研究使用学术 NLP 数据集(特别是 FLAN4 和 T0.5)微调语言模型以遵循指令。我们工作的一个关键动机是增加帮助性(helpfulness)和真实性(truthfulness),同时减轻语言模型的危害和偏见。6,7,8,9,10 我们之前在这个方向上的一些研究发现,我们可以通过对人类演示的小型精选数据集(curated dataset)进行微调来减少有害输出。11 其他研究侧重于过滤预训练数据集,12 特定于安全的控制令牌,13,14 或指导模型生成。15,16我们正在进行的对齐研究中探索这些想法和其他的想法。
Results 结果
We first evaluate how well outputs from InstructGPT follow user instructions, by having labelers compare its outputs to those from GPT-3. We find that InstructGPT models are significantly preferred on prompts submitted to both the InstructGPT and GPT-3 models on the API. This holds true when we add a prefix to the GPT-3 prompt so that it enters an “instruction-following mode.”
我们首先通过让标注人员将其输出与 GPT-3 的输出进行比较,来评估 InstructGPT 的输出遵循用户指令的情况。 我们发现,在提交提示(prompt)给 API 上的 InstructGPT 和 GPT-3 模型时,InstructGPT 模型明显更受青睐。 当我们向 GPT-3 提示添加前缀以使其进入“指令跟随模式”(instruction-following mode)时,情况也是如此。

Quality ratings of model outputs on a 1–7 scale (y-axis), for various model sizes (x-axis), on prompts submitted to InstructGPT models on our API. InstructGPT outputs are given much higher scores by our labelers than outputs from GPT-3 with a few-shot prompt and without, as well as models fine-tuned with supervised learning. We find similar results for prompts submitted to GPT-3 models on the API.
根据在我们的 API 上提交给 InstructGPT 模型的提示,对各种模型大小(x 轴)的模型输出按 1-7 级(y 轴)进行质量评级。 我们的标注人员(labelers)对 InstructGPT 输出的评分比带有或不带有few-shot提示的 GPT-3 以及通过监督学习微调过的模型输出要高得多。 对于在 API 上提交给 GPT-3 模型的提示,我们发现有类似的结果。
To measure the safety of our models, we primarily use a suite of existing metrics on publicly available datasets. Compared to GPT-3, InstructGPT produces fewer imitative falsehoods (according to TruthfulQA17) and are less toxic (according to RealToxicityPrompts18). We also conduct human evaluations on our API prompt distribution, and find that InstructGPT makes up facts (“hallucinates”) less often, and generates more appropriate outputs.C
为了衡量模型的安全性,我们主要使用公开数据集上的一套现有指标。与 GPT-3 相比,InstructGPT 产生的模仿性错误(imitative falsehoods)更少(根据 TruthfulQA17),并且毒性更小(根据 RealToxicityPrompts18)。我们还对我们的 API 提示分布进行了人工评估,发现 InstructGPT 编造事实(“幻觉”,即hallucination)的频率较低,并生成更合适的输出。C
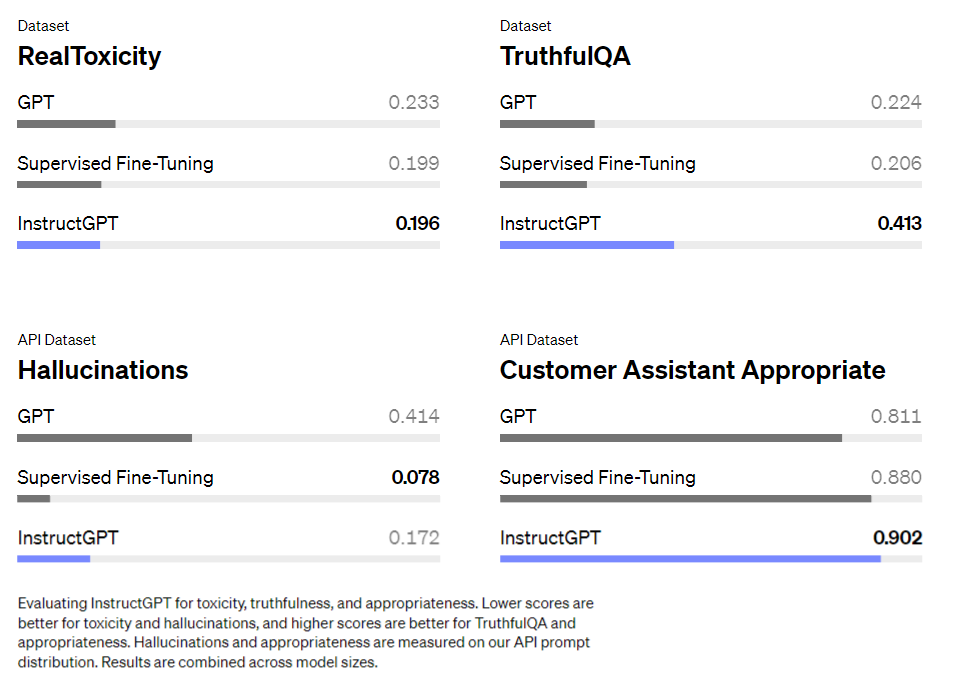
Evaluating InstructGPT for toxicity, truthfulness, and appropriateness. Lower scores are better for toxicity and hallucinations, and higher scores are better for TruthfulQA and appropriateness. Hallucinations and appropriateness are measured on our API prompt distribution. Results are combined across model sizes.
评估 InstructGPT 的毒性(toxicity)、真实性(truthfulness)和适当性(appropriateness)。毒性和幻觉(hallucination)分数越低越好,真实性和适当性分数越高越好。幻觉和适当性是基于我们的 API 提示分布来衡量的。结果会根据模型尺寸进行组合。
Finally, we find that InstructGPT outputs are preferred to those from FLAN4 and T05 on our customer distribution. This indicates that the data used to train FLAN and T0, mostly academic NLP tasks, is not fully representative of how deployed language models are used in practice.
最后,我们发现 InstructGPT 输出在我们的客户分布(customer distribution)中优于 FLAN4 和 T05 的输出。这表明用于训练 FLAN 和 T0 的数据(主要是学术 NLP 任务)并不能完全代表已部署的语言模型在实践中的使用方式。
Methods 方法

To train InstructGPT models, our core technique is reinforcement learning from human feedback (RLHF), a method we helped pioneer in our earlier alignment research. This technique uses human preferences as a reward signal to fine-tune our models, which is important as the safety and alignment problems we are aiming to solve are complex and subjective, and aren’t fully captured by simple automatic metrics.
为了训练 InstructGPT 模型,我们的核心技术是根据人类反馈进行强化学习 (Reinforcement Learning from Human Feedback, RLHF),这是我们在早期对齐研究中帮助开创者(pioneer)的一种方法。这项技术使用人类偏好(human preferences)作为奖励信号来微调我们的模型,这很重要,因为我们要解决的安全和对齐问题是复杂且主观的,并且不能通过简单的自动指标完全捕获。
We first collect a dataset of human-written demonstrations on prompts submitted to our API, and use this to train our supervised learning baselines. Next, we collect a dataset of human-labeled comparisons between two model outputs on a larger set of API prompts. We then train a reward model (RM) on this dataset to predict which output our labelers would prefer. Finally, we use this RM as a reward function and fine-tune our GPT-3 policy to maximize this reward using the PPO algorithm.
我们首先收集人工编写的演示数据集,此数据集的数据来自提交到我们的 API 上的提示(prompt),并用这个数据集来训练我们的监督学习基线(supervised learning baselines)。 接下来,我们在一组更大的 API 提示上收集两个模型输出之间人工标记的比较数据集。 然后,我们在此数据集上训练奖励模型 (Reward Model, RM),以预测我们的标注人员更喜欢哪个输出。最后,我们使用这个 RM 作为奖励函数(reward function),并使用近端策略优化(Proximal Policy Optimization, PPO)算法微调我们的 GPT-3 策略以最大化该奖励。
One way of thinking about this process is that it “unlocks” capabilities that GPT-3 already had, but were difficult to elicit through prompt engineering alone: this is because our training procedure has a limited ability to teach the model new capabilities relative to what is learned during pretraining, since it uses less than 2% of the compute and data relative to model pretraining.
思考这个过程的一种方式是,它“解锁”了 GPT-3 已经拥有的能力(capabilities),但仅通过提示工程(prompt engineering)很难获得这些能力:这是因为我们的训练程序(training procedure)教授模型新功能(capabilities)的能力(ability)有限。模型能力是在预训练(pretraining)期间学习的,因为与模型预训练(model pretraining)相比,模型训练使用的计算和数据不到模型预训练的2%。
A limitation of this approach is that it introduces an “alignment tax”: aligning the models only on customer tasks can make their performance worse on some other academic NLP tasks. This is undesirable since, if our alignment techniques make models worse on tasks that people care about, they’re less likely to be adopted in practice. We’ve found a simple algorithmic change that minimizes this alignment tax: during RL fine-tuning we mix in a small fraction of the original data used to train GPT-3, and train on this data using the normal log likelihood maximization .D
This roughly maintains performance on safety and human preferences, while mitigating performance decreases on academic tasks, and in several cases even surpassing the GPT-3 baseline.
这种方法的局限性在于它引入了“对齐税”(alignment tax):仅在客户任务上对齐模型可能会使模型在其他一些学术 NLP 任务上的表现更差。这是不可取的,因为如果我们的对齐技术使模型在人们关心的任务上变得更糟,那么它们在实践中被采用的可能性就较小。 我们发现了一个简单的算法改变,可以最大限度地减少这种对齐负担:在增强学习(Reinforcement Learning, RL)微调期间,我们混合了一小部分的原始数据,用于训练 GPT-3,并使用正态对数似然(normal log likelihood)最大化来训练这些数据。D
这大致保持了安全性(safety)和人类偏好(human preferences)方面的性能,同时减轻了学术任务方面的性能下降,在某些情况下甚至超过了 GPT-3 基线(baseline)。
Generalizing to broader preferences 泛化到更广泛的偏好
Our procedure aligns our models’ behavior with the preferences of our labelers, who directly produce the data used to train our models, and us researchers, who provide guidance to labelers through written instructions, direct feedback on specific examples, and informal conversations. It is also influenced by our customers and the preferences implicit in our API policies. We selected labelers who performed well on a screening test for aptitude in identifying and responding to sensitive prompts. However, these different sources of influence on the data do not guarantee our models are aligned to the preferences of any broader group.
我们的程序使模型的行为与标注人员的偏好保持一致,标注人员直接生成用于模型训练的数据,而我们的研究人员则通过书面说明、对具体示例的直接反馈和非正式对话为标注人员提供指导。它还受到我们的客户和 API 政策中隐含的偏好的影响。我们进行了对识别和响应敏感提示(sensitive prompts)的能力筛选测试(screening test for aptitude),从中选择了表现良好的标注人员。然而,这些对数据影响的不同来源并不能保证我们的模型符合任何更广泛群体的偏好。
We conducted two experiments to investigate this. First, we evaluate GPT-3 and InstructGPT using held-out labelersE who did not produce any of the training data, and found that these labelers prefer outputs from the InstructGPT models at about the same rate as our training labelers. Second, we train reward models on data from a subset of our labelers, and find that they generalize well to predicting the preferences of a different subset of labelers. This suggests that our models haven’t solely overfit to the preferences of our training labelers. However, more work is needed to study how these models perform on broader groups of users, and how they perform on inputs where humans disagree about the desired behavior.
我们进行了两个实验来研究这一点。首先,我们使用未生成任何训练数据的保留标注人员E 来评估 GPT-3 和 InstructGPT,并发现这些标注人员更喜欢 InstructGPT 模型的输出,其比率与我们培训的标注人员大致相同。其次,基于来自我们的标注人员子集的数据,训练奖励模型,并发现它们可以很好地概括为预测不同标注人员子集的偏好。这表明我们的模型不仅仅过度适合我们培训的标注人员的偏好。然而,还需要做更多的工作来研究这些模型如何在更广泛的用户群体中执行,以及它们如何在人们对期望行为存在分歧的情况下执行。
Limitations 限制
Despite making significant progress, our InstructGPT models are far from fully aligned or fully safe; they still generate toxic or biased outputs, make up facts, and generate sexual and violent content without explicit prompting. But the safety of a machine learning system depends not only on the behavior of the underlying models, but also on how these models are deployed. To support the safety of our API, we will continue to review potential applications before they go live, provide content filters for detecting unsafe completions, and monitor for misuse.
尽管取得了重大进展,但我们的 InstructGPT 模型还远未完全对齐或完全安全;他们仍然会在没有明确提示的情况下产生有毒或有偏见的输出、编造事实并产生性和暴力内容。但机器学习系统的安全性不仅取决于底层模型(underlying models)的行为,还取决于这些模型的部署方式。 为了支持我们的 API 的安全,我们将继续在潜在的应用程序上线之前对其进行审查,提供内容过滤器来检测不安全的补全(completions),并监控滥用情况。
A byproduct of training our models to follow user instructions is that they may become more susceptible to misuse if instructed to produce unsafe outputs. Solving this requires our models to refuse certain instructions; doing this reliably is an important open research problem that we are excited to tackle.
训练我们的模型遵循用户指令的副产品是,如果被指示产生不安全的输出,那么它们可能会更容易被误用。解决这个问题需要我们的模型拒绝某些指令;可靠地做到这一点是我们很高兴能够解决的一个重要的开放的研究问题。
Further, in many cases aligning to the average labeler preference may not be desirable. For example, when generating text that disproportionately affects a minority group, the preferences of that group should be weighted more heavily. Right now, InstructGPT is trained to follow instructions in English; thus, it is biased towards the cultural values of English-speaking people. We are conducting research into understanding the differences and disagreements between labelers’ preferences so we can condition our models on the values of more specific populations. More generally, aligning model outputs to the values of specific humans introduces difficult choices with societal implications, and ultimately we must establish responsible, inclusive processes for making these decisions.
此外,在许多情况下,与平均标注人员偏好保持一致,可能并不理想。例如,当生成不成比例地影响少数群体的文本时,应该更重视该群体的偏好。目前,InstructGPT 经过训练可以遵循英语指令;因此,它偏向于英语国家的文化价值观。我们正在进行研究,以了解标注人员偏好之间的差异和分歧,以便我们可以根据更特定人群的价值观来调整我们的模型。更一般地说,将模型输出与特定人类的价值观保持一致,会带来具有社会影响的困难选择,最终我们必须建立负责任的、包容性的流程,来做出这些决策。
Next steps 下一步
This is the first application of our alignment research to our product. Our results show that these techniques are effective at significantly improving the alignment of general-purpose AI systems with human intentions. However, this is just the beginning: we will keep pushing these techniques to improve the alignment of our current and future models towards language tools that are safe and helpful to humans.
这是我们的对齐研究首次应用于我们的产品。我们的结果表明,这些技术可以有效地显著提高通用人工智能系统(general-purpose AI systems)与人类意图(human intentions)的一致性(alignment)。然而,这仅仅是开始:我们将继续推动这些技术,以改善我们当前和未来模型对语言工具的对齐性(alignment),以确保这些语言工具对人类是安全的且有帮助的。
If you’re interested in these research directions, we’re hiring!
如果您对这些研究方向感兴趣,我们正在招聘!
Footnotes 脚注
[A] We only use prompts submitted through the Playground to an earlier version of the InstructGPT models that was deployed in January 2021. Our human annotators remove personal identifiable information from all prompts before adding it to the training set.↩︎
[B] The InstructGPT models deployed in the API are updated versions trained using the same human feedback data. They use a similar but slightly different training method that we will describe in a forthcoming publication.↩︎
[C] We also measure several other dimensions of potentially harmful outputs on our API distribution: whether the outputs contain sexual or violent content, denigrate a protected class, or encourage abuse. We find that InstructGPT doesn’t improve significantly over GPT-3 on these metrics; the incidence rate is equally low for both models.↩︎
[D] We found this approach more effective than simply increasing the KL coefficient.↩︎
[E] These labelers are sourced from Scale AI and Upwork, similarly to our training labelers, but do not undergo a screening test.↩︎
[A] 我们仅使用通过 Playground 提交的提示(prompt),这些提示被提交到在2021 年 1 月部署的早期版本的InstructGPT 模型。我们的人工注释者(human annotators)会先从所有提示中删除个人身份信息,然后再将其添加到训练集中。
[B] API 中部署的 InstructGPT 模型使用相同的人类反馈数据(human feedback data)训练的更新版本。他们使用类似但略有不同的训练方法,我们将在即将出版的出版物中描述该方法。
[C] 我们还衡量 API 提示分布中潜在有害输出的其他几个维度:输出是否包含性或暴力内容、诽谤受保护群体(protected class)或鼓励滥用(abuse)。 我们发现 InstructGPT 在这些指标上,与GPT-3相比,并没有显着改善;对于这个两种模型,其发生率同样低。
[D] 我们发现这种方法比简单地增加 KL 系数(Kullback–Leibler divergence coefficient, KL coefficient)更有效。
[E] 这些标注人员来自 Scale AI 和 Upwork,与我们培训的标注人员类似,但没有经过筛选测试。
References 参考资料
- Christiano, P., Leike, J., Brown, T.B., Martic, M., Legg, S. and Amodei, D., 2017. Deep reinforcement learning from human preferences. arXiv preprint arXiv:1706.03741.↩︎
- Stiennon, N., Ouyang, L., Wu, J., Ziegler, D.M., Lowe, R., Voss, C., Radford, A., Amodei, D. and Christiano, P., 2020.↩︎
- Wu, J., Ouyang, L., Ziegler, D.M., Stiennon, N., Lowe, R., Leike, J. and Christiano, P., 2021. Recursively summarizing books with human feedback. arXiv preprint arXiv:2109.10862.↩︎
- Wei, J., Bosma, M., Zhao, V.Y., Guu, K., Yu, A.W., Lester, B., Du, N., Dai, A.M. and Le, Q.V., 2021. Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652.↩︎↩︎
- Sanh, V., Webson, A., Raffel, C., Bach, S.H., Sutawika, L., Alyafeai, Z., Chaffin, A., Stiegler, A., Scao, T.L., Raja, A. and Dey, M., 2021. Multitask prompted training enables zero-shot task generalization. arXiv preprint arXiv:2110.08207.↩︎↩︎
- Bender, E.M., Gebru, T., McMillan-Major, A. and Shmitchell, S., 2021, March. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big??. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (pp. 610-623). ↩︎
- Bommasani, R., Hudson, D.A., Adeli, E., Altman, R., Arora, S., von Arx, S., Bernstein, M.S., Bohg, J., Bosselut, A., Brunskill, E. and Brynjolfsson, E., 2021. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258.↩︎
- Kenton, Z., Everitt, T., Weidinger, L., Gabriel, I., Mikulik, V. and Irving, G., 2021. Alignment of Language Agents. arXiv preprint arXiv:2103.14659. ↩︎
- Weidinger, L., Mellor, J., Rauh, M., Griffin, C., Uesato, J., Huang, P.S., Cheng, M., Glaese, M., Balle, B., Kasirzadeh, A. and Kenton, Z., 2021. Ethical and social risks of harm from Language Models. arXiv preprint arXiv:2112.04359.↩︎
- Tamkin, A., Brundage, M., Clark, J. and Ganguli, D., 2021. Understanding the Capabilities, Limitations, and Societal Impact of Large Language Models. arXiv preprint arXiv:2102.02503.↩︎
- Solaiman, I. and Dennison, C., 2021. Process for Adapting Language Models to Society (PALMS) with Values-Targeted Datasets. arXiv preprint arXiv:2106.10328.↩︎
- Ngo, H., Raterink, C., Araújo, J.G., Zhang, I., Chen, C., Morisot, A. and Frosst, N., 2021. Mitigating harm in language models with conditional-likelihood filtration. arXiv preprint arXiv:2108.07790.↩︎
- Xu, J., Ju, D., Li, M., Boureau, Y.L., Weston, J. and Dinan, E., 2020. Recipes for safety in open-domain chatbots. arXiv preprint arXiv:2010.07079. ↩︎
- Keskar, N.S., McCann, B., Varshney, L.R., Xiong, C. and Socher, R., 2019. Ctrl: A conditional transformer language model for controllable generation. arXiv preprint arXiv:1909.05858. ↩︎
- Krause, B., Gotmare, A.D., McCann, B., Keskar, N.S., Joty, S., Socher, R. and Rajani, N.F., 2020. Gedi: Generative discriminator guided sequence generation. arXiv preprint arXiv:2009.06367.↩︎
- Dathathri, S., Madotto, A., Lan, J., Hung, J., Frank, E., Molino, P., Yosinski, J. and Liu, R., 2019. Plug and play language models: A simple approach to controlled text generation. arXiv preprint arXiv:1912.02164.↩︎
- Lin, S., Hilton, J. and Evans, O., 2021. TruthfulQA: Measuring how models mimic human falsehoods. arXiv preprint arXiv:2109.07958.↩︎
- Gehman, S., Gururangan, S., Sap, M., Choi, Y. and Smith, N.A., 2020. RealToxicityPrompts: Evaluating neural toxic degeneration in language models. arXiv preprint arXiv:2009.11462. ↩︎
Authors 作者
Acknowledgments 致谢
We’d like to thank our paper co-authors: Long Ouyang, Jeff Wu, Roger Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, and Paul Christiano, along with everyone who provided feedback on the paper and blog post. We’d also like to thank the Comms team for their guidance and assistance, including Steve Dowling, Hannah Wong, Elie Georges, Alper Ercetin, Jared Salzano, Allan Diego, and Justin Jay Wang. Finally, we’d like to thank our labelers, without whom this project would not have been possible.
英文原始链接:https://openai.com/research/instruction-following
-------------------------------------------------------------------------------------------------
转载请注明出处,谢谢!