本章节介绍Harris角点检测,SIFT关键点检测,shi-Tomasi角点检测,SURF特征检测,ORB特征检测。
特征检测是提取图像信息,决定每个图像的点是否属于一个图像特征。其结果是把图像上的点分为不同的子集,这些子集往往属于孤立的点,连续的曲线或连续的区域。
特征检测包括边缘检测,角检测,区域检测和脊检测。
特征检测应用场景有图像搜索(以图搜图),拼图游戏,图像拼接等。
特征是唯一的,是可追踪的,是能比较的。在图像特征中最重要的是角点,哪些是角点(1 灰度梯度最大值对应的像素,2 两条线的交点,3 极值点(一阶导数最大,二阶导数为0))。
1 Harris角点检测
harris角点检测的基本原理:对于一个小的图像区域,如果它发生了任意方向的灰度变化,那么这个区域中的像素点都会发生相应的灰度变化。而对于平坦区域,即使发生了灰度变化,变化程度也很小。因此,可以通过计算图像中每个像素点的灰度变化程度来判断这个点是否为角点。
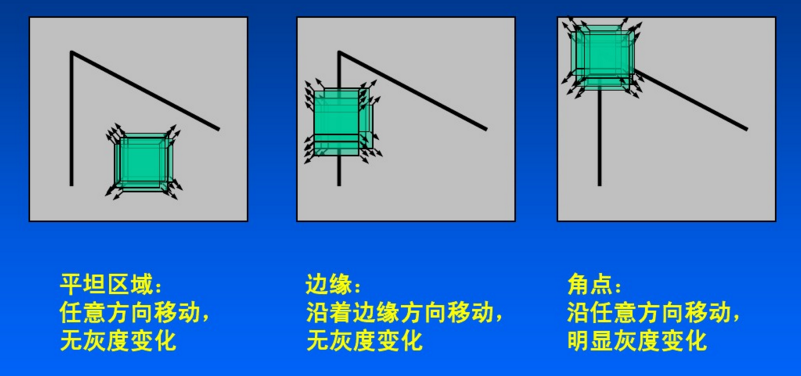
Harris的实现步骤如下:
1 计算梯度
需要计算图像中每个像素点的梯度,可以使用sobel算子或其他算子实现。对于一幅大小为M*N的图像,可以得到它的横向和纵向梯度分别为Gx,Gy。
2 计算协方差矩阵
计算梯度后,需要计算每个像素点周围的领域内的灰度变化程度,这个可以通过计算其协方差矩阵M来实现。


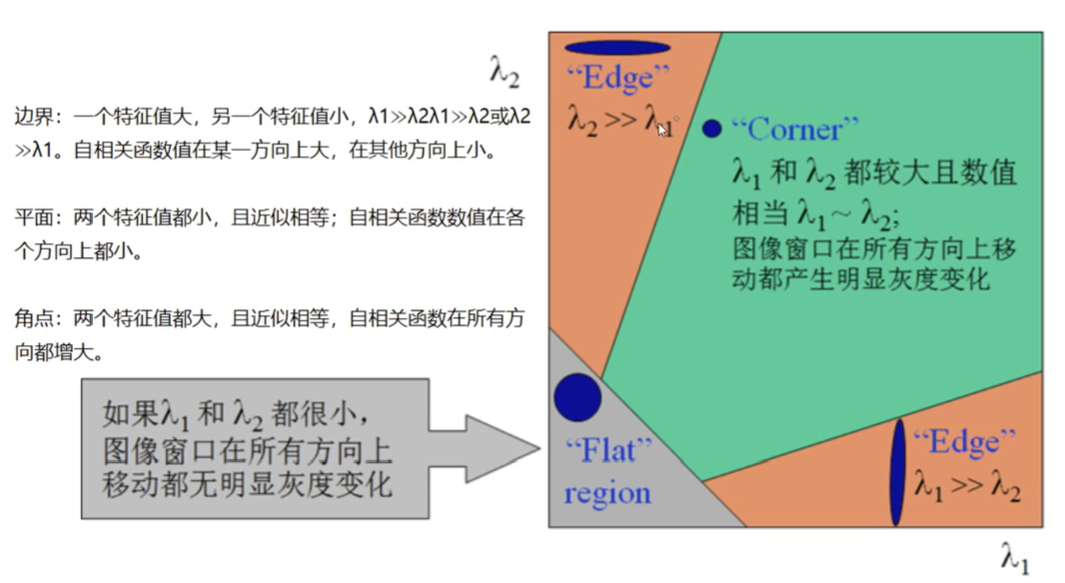
3 计算响应函数
根据协方差矩阵M的特征值,可以计算每个像素点的响应函数R。

4 非极大值抑制
由于角点通常是一幅图像中灰度变化比较突出的点,因此在响应函数R中,值较大的点往往是角点。为了得到角点,需要对响应函数进行非极大值抑制,即在每个局部极大值处保留点,其余点舍弃。
5 设置阈值
由于图像中不仅存在角点,还存在其他类型的特征点,因此需要设置一个阈值来筛选出角点。通常,可以根据响应函数R的最大值和平均值来确定阈值。
Harris角点检测的优点:亮度和对比度的变化对角点无影响;Harris角点检测算子具有旋转不变性;Harris角点检测不具有尺度不变性(尺度变化,角点检测性能下降)。
opencv中的Harris角点检测: dst = cornerHarris(img, blocksize, ksize, k)
bolcksize表示检测窗口大小,ksize表示sobel算子的卷积核(计算的时候涉及到一阶偏导),k表示权重系数,一般取0.04-0.06之间,默认0.04
import cv2
import numpy as np
img = cv2.imread('./contours.png')
img_gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
dst = cv2.cornerHarris(img_gray,blockSize=4,ksize=5,k=0.04) #返回角点响应,每一个像素都有对应的角点响应 dst.shape == img_gray.shape
print(dst)
#显示角点,设置阈值 dst.max()
img[dst > (0.01*dst.max())] = [0,0,255]
cv2.imshow('img',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
检测结果如下:
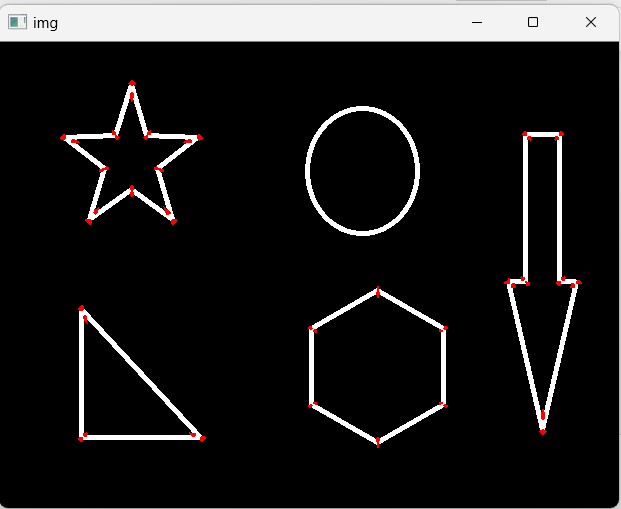
2 SIFT关键点检测
Harris角点检测具有旋转不变的特性,但是缩放后,原来的角点可能就不再是角点了。可以用 SIFT (尺度不变特征变换)关键点检测,这种方法具有尺度不变性,可以在图像中检测出关键点,是一种局部特征描述子。
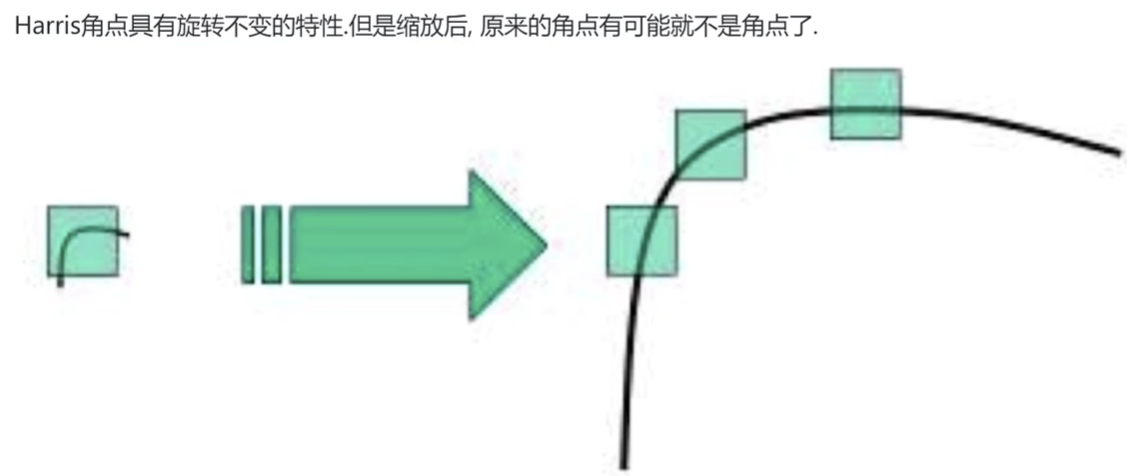
SIFT算法的实质是在不同的尺度空间上寻找关键点(特征点),计算关键点的大小,方向,尺度信息,利用这些信息组成关键点对特征点进行描述的问题。
SIFT特征提取和匹配的步骤,如下:
1 )生成高斯差分金字塔(DOG金字塔),尺度空间构建。
尺度空间的获取通常使用高斯模糊来实现,不同Sigma的高斯函数决定了对图像的模糊程度,越大的值图像越模糊。

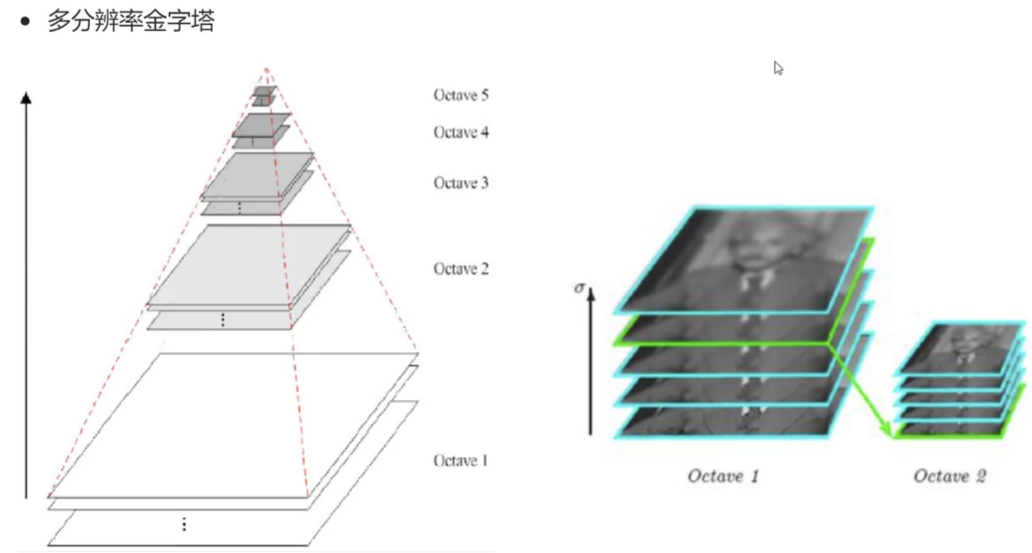
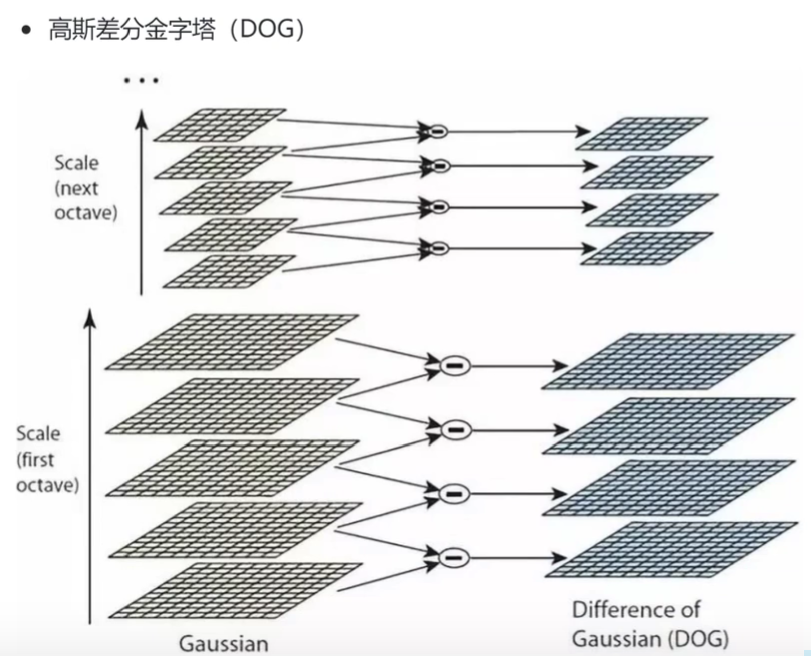
每一组在层数上,DOG金字塔比高斯金字塔少一层。后续Sift特征点的提取都是在DOG金字塔上进行的。
2)尺度空间的极值检测(关键点的初步查探)。
为了寻找尺度空间(DOG函数)的极值点,每个像素点要和其图像域(同一尺度空间)和尺度域(相邻的尺度空间)的所有相邻点进行比较,当其大于(或小于)所有相邻点时,该点就是极值点。如下图所示,中间的检测点要和其所在图像的3*3邻域8个像素点,以及其相邻的上下两层图像(在同一组内的尺度空间上)的3*3领域的18 个像素点,共 26个像素点进行比较。
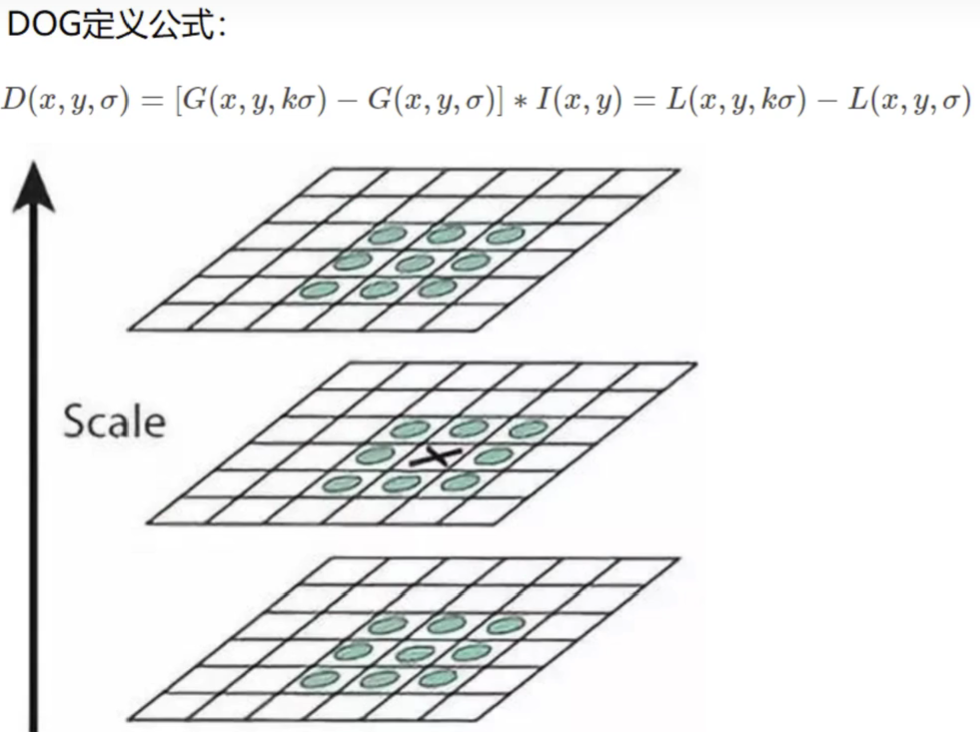
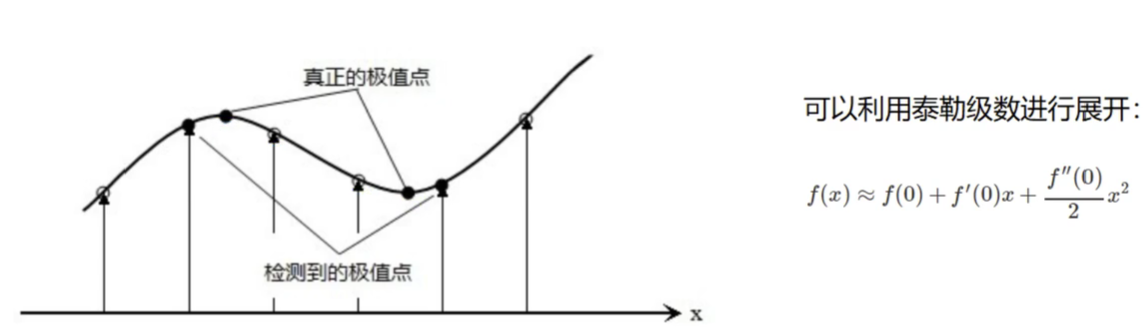
3)稳定关键点的精确定位(特征点定位)。
在每个候选的位置上,通过拟合精细模型来确定位置尺度,关键点的选取依据他们的稳定程度。这些候选关键点是DOG空间的局部极值点,而且这些极值点均为离散的点,精确定位极值点的一种方法是,对尺度空间的 DOG 函数进行曲线拟合,计算其极值点,从而实现关键点的精确定位。
4)稳定关键点方向信息分配(特征点的主方向)。
为关键点分配方向信息所要解决的问题是使得关键点对图像角度和旋转具有不变形。方向的分配是通过求每个极值点的梯度来实现的。每个特征点可以得到三个信息(x, y, σ, Θ),即位置,尺度和方向。具有多个方向的关键点可以被复制成多份,然后将方向值分别赋予复制后的特征点,一个特征点就产生了多个坐标,尺度相等,但是方向不同的特征点。
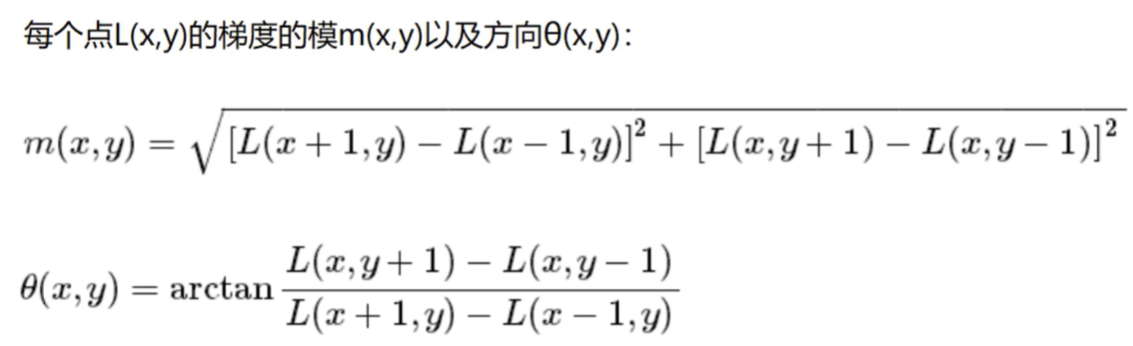
在完成关键点的梯度计算后,使用直方图统计邻域内像素的梯度和方向:

将梯度方向直方图中纵坐标最大的项代表的方向分配给当前关键点作为主方向,若在梯度直方图中存在一个相当于主峰值 80% 能量的峰值,则将这个方向认为是关键点的辅助方向。
5)关键点描述(特征点描述)。
对关键点的描述是后续实现匹配的关键步骤,描述其实就是一种以数学方式定义关键的过程。描述子不但包含关键点,也包含关键点周围对其有贡献的邻域点。为了保证特征矢量的旋转不变性,要以特征点为中心,在附近领域内将坐标轴旋转 Θ 角度,即将坐标轴旋转为特征点的主方向。

旋转之后的主方向为中心取8*8的窗口,求每个像素的梯度幅值和方向,箭头方向代表梯度方向,长度代表梯度幅值,然后利用高斯窗口对其进行加权运算,最后在每个4*4的小块上绘制8个方向的梯度直方图,计算每个梯度方向的累加值,即可形成一个种子点,即每个特征由4个种子点组成,每个种子点有8个方向的向量信息。
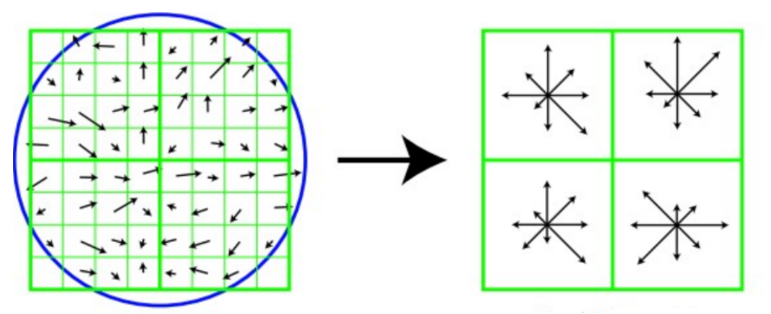
论文中建议对每个关键点使用 4*4 共 16个种子点来描述,这样一个关键点就产生 128 维的SIFT特征向量。即采用128维向量的描述子进行关键点表征,综合效果最佳:
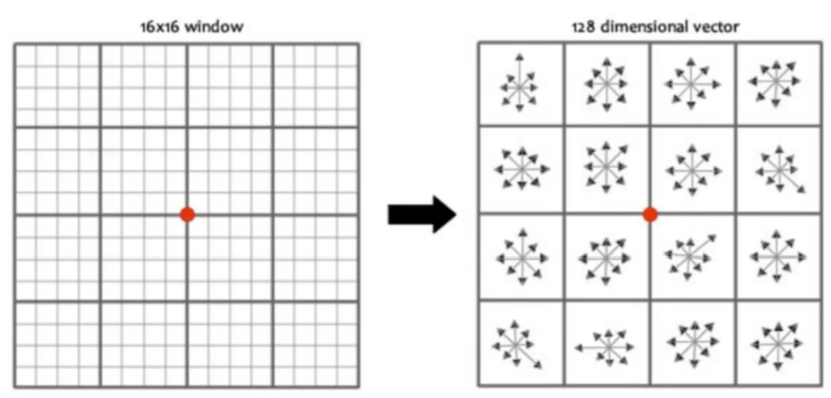
6)特征点匹配。
特征点的匹配通过计算两组特征点的 128 维的关键点的欧式距离实现的。欧式距离越小,则相似度越高,当欧式距离小于设定的阈值时,可以判定为匹配成功。
SIFT关键点检测的python实现如下:
import cv2
import numpy as np #sift关键点检测 (速度慢一些,准确率高一些)
# 关键点:位置,大小,方向
# 关键点描述子:记录了关键点周围对其有共享的像素点的一组向量值,其不受仿射变换,光照变换等影响。描述子的作用就是进行特征匹配。
img = cv2.imread('./contours.png')
img_gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#创建sift对象
sift = cv2.xfeatures2d.SIFT_create()
#进行检测
kpoint = sift.detect(img_gray)
#kpoint,des = sift.detectAndCompute(img_gray,mask=None) #同时进行检测关键点和计算描述子,每个关键点的描述子由128个值的向量组成
print(type(kpoint))
#计算描述子
kpoint,des = sift.compute(img_gray,kpoint)
print(des.shape)
print(des[0])
#绘制关键点
cv2.drawKeypoints(img_gray,kpoint,img)
cv2.imshow('sift',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
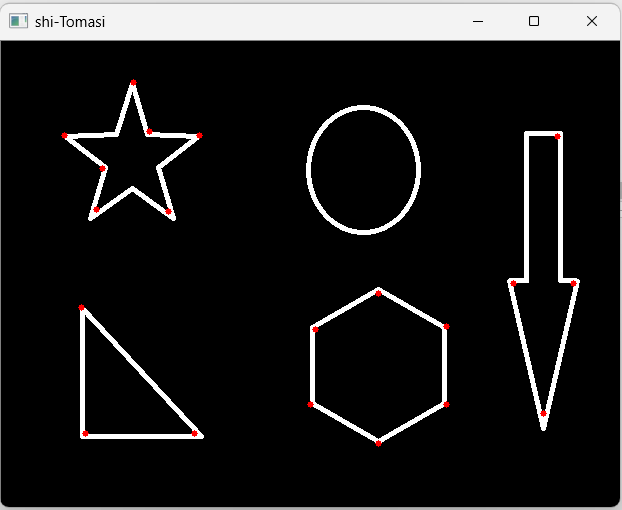
3 shi-Tomasi角点检测
shi-Tomasi角点检测 Harris角点检测的改进,harris计算的稳定性和k值有关,k是经验值,不好设置。shi-Tomasi 发现,角点检测和矩阵M的较小特征值有关,于是可以用较小的特征值作为分数。
opencv中提供的算法是:goodFeaturesToTrack(img,maxCorners,qualityLevel,minDistance,mask=Noen)
maxCorners 表示角点的最大数,为0表示没有限制;
qualityLevel 表示角点质量,一般在0.01-0.1之间;
minDistance 表示角之间最小欧氏距离(像素距离),忽略小于该值的点;
mask 表示感兴趣区域。
import cv2
import numpy as np
img = cv2.imread('./contours.png')
img_gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#shi-tomasi角点检测,返回的numpy.array,包含了检测的角点坐标
corners = cv2.goodFeaturesToTrack(img_gray,maxCorners=20,qualityLevel=0.06,minDistance=40)
# print(corners)
corners = np.int32(corners)
# print(corners) #三维数组
#画出检测的角点
for i in corners:
# i 相当于corners中的每一行数据,二维
x,y = i.ravel() #把二维变成一维,返回的就是两个数
cv2.circle(img,(x,y),3,[0,0,255],-1)
cv2.imshow('corners',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
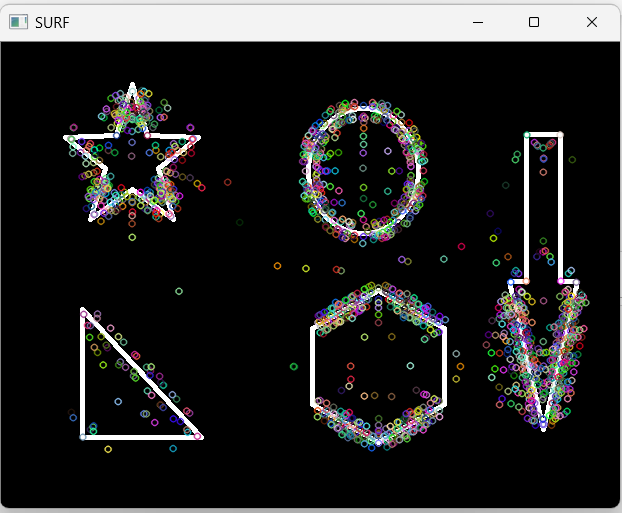
4 SURF特征检测
SIFT最大的问题是速度慢,而SURF是对其进行改进,提升了算法的执行效率。(速度快些,准确率差些),在实时系统中应用比较方便。
import cv2
import numpy as np
img = cv2.imread('./contours.png')
img_gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#创建SURF对象
surf = cv2.xfeatures2d.SURF_create()
kpoint,des = surf.detectAndCompute(img_gray,None) #同时进行检测关键点和计算描述子,每个关键点的描述子由64个值的向量组成
print(des.shape)
#画出检测点
cv2.drawKeypoints(img_gray,kpoint,img)
cv2.imshow('SURF',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
5 ORB特征检测
ORB算法分为两部分,分别是特征点提取和特征点描述。特征点提取是由FAST算法发展而来,特征点描述是根据BRIEF特征描述算法改进的。
ORB也是sift的改进,最大的优势是可以做到 实时检测,但是准确性有所下降。
import cv2
import numpy as np
img = cv2.imread('./contours.png')
img_gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#创建ORB对象
orb = cv2.ORB_create()
kpoint,des = orb.detectAndCompute(img_gray,None) #同时进行检测关键点和计算描述子,每个关键点的描述子由32个值的向量组成
print(des.shape)
#画出检测点
cv2.drawKeypoints(img_gray,kpoint,img)
cv2.imshow('ORB',img)
cv2.waitKey(0)
cv2.destroyAllWindows()

- opencv-python 特征 opencv pythonopencv-python特征opencv python opencv-python轮廓 特征opencv opencv-python opencv-python opencv python opencv-python opencv python cv2 python opencv-python exception opencv opencv-python opencv python视频 opencv-python python_pip install python opencv-python pyproject building命令 opencv-python图像opencv python