1. 简述
COGMEN :基于上下文化图神经网络的多模式情感识别架构,该架构既解决了上下文对语句的影响,也解决了用于预测会话中每个说话者的每一语句情感的相互依赖性和内部依赖性
COGMEN有以下特点:
- 基于上下文化图神经网络(GNN)的多模式情感识别架构,用于预测会话中每语句每说话者的情感
- 模型在对话中同时利用了本地和全局信息
- 使用图形变换器在多模态情感识别系统中建模说话人关系
2. 整体架构
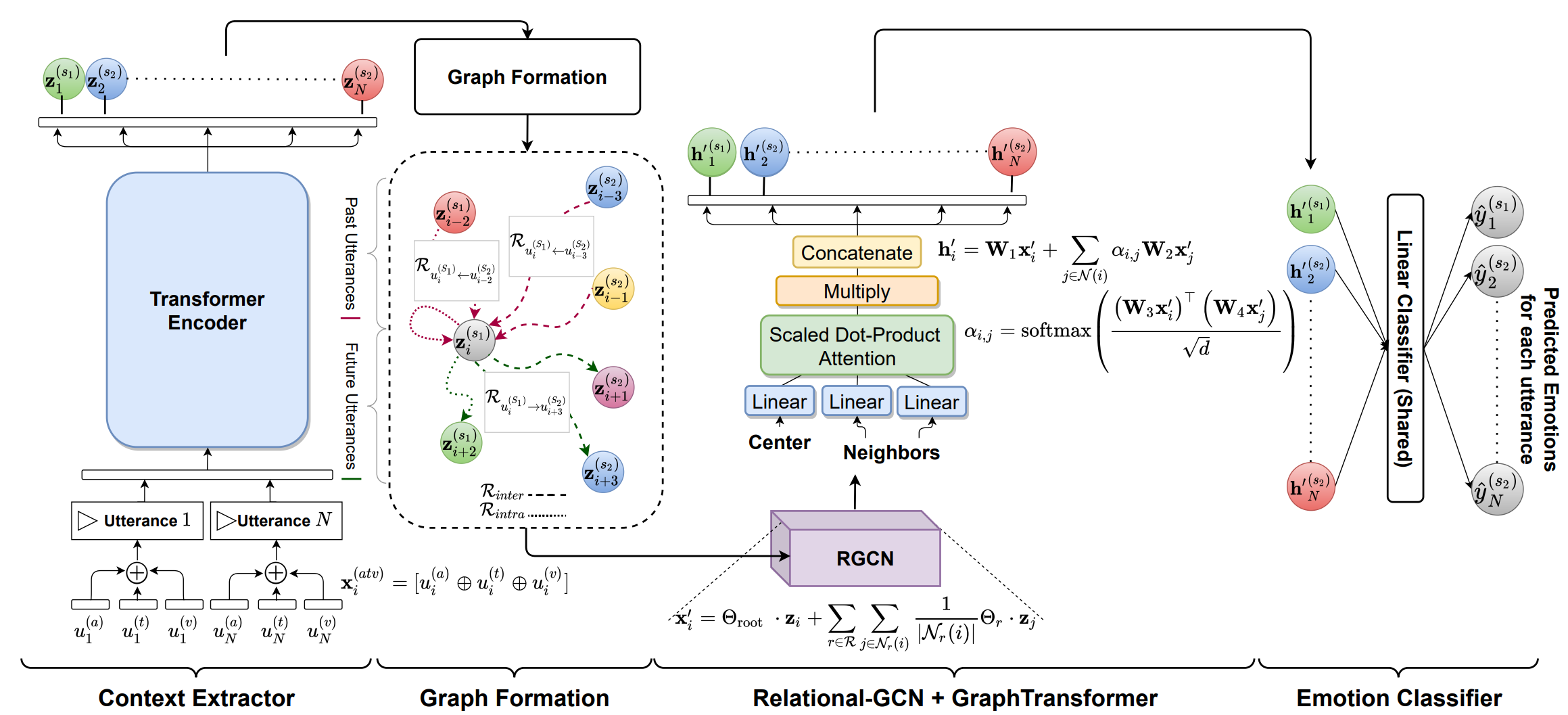
输入的话语作为语境提取器模块的输入,该模块负责捕获全局语境。语境提取器为每个话语(utterance)提取的特征形成了一个基于说话人之间交互的图(Graph Formation)。该图作为Relational - GCN的输入,然后是graph transformer,graph transformer使用形成的图来捕捉话语之间的内部和内部关系。最后,作为情感分类器的两个线性层使用所有话语获得的特征来预测相应的情感.
2.1 语境提取器 Context Extractor
- 对每个语句\(u_i\),使用其音频、文本、视频形成对应的输入特征\(x\);
其中$d=d_a+d_t+d_v$
-
使用Transformer 编码器捕获上下文
Transformer 编码器
利用自注意力 (Self-attention)机制来捕获上下文信息
Transformer编码器流程图如下: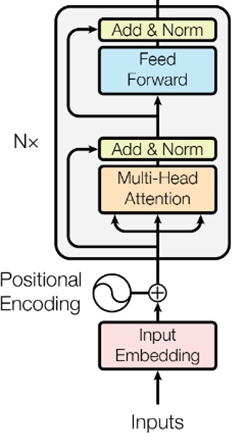
- 计算所以语句的特征\(x\)的Query、Key、Value
\[Q^{(h)}=XW_{h,q},\\ K^{(h)}=XW_{h,k},\\ V^{(h)}=XW_{h,v}, \]- 利用softmax函数计算单注意力头的权重
\[α^{(h)}=σ_j(\frac{Q^{(h)}(K^{(h)})^T}{\sqrt{k}}) \]- 计算多头注意力权重的加权和
\[\begin{align} head^{(h)}&=α^{(h)}(V^{(h)})∈\mathbb{R}^{n×k}\notag\\ U^′&= [head^{(1)}⊕head^{(2)}⊕...head^{(H)}]W^o\notag \end{align} \]- 添加残差连接,应用LayerNorm、前馈层和Add & Norm层
\[\begin{align} \rm U &= \rm LayerNorm(X+U^′;γ_1,β_1);\notag\\ \rm Z^′&= \rm ReLU (UW_1)W_2;\notag \\ \rm Z&= \rm LayerNorm(U+Z^′;γ_2,β_2);\notag \end{align} \]其中,\(γ_1,β_1∈\mathbb{R}^d\),\(W_1∈\mathbb{R}^{d×m}\),\(W_2∈\mathbb{R}^{m×d}\),\(γ_2,β_2∈\mathbb{R}^d\).
Transformer编码器提供了与对话中的每个语句相对应的特征\(([z_1,z_2,...,z_n]^T=Z∈\mathbb{R}^{n×d})\)。
2.2 图形形成 Graph Formation
将说话者内部和说话者之间的依赖关系形成一张图表,以便在图形变换器中建模。
每个语句都充当一个使用有向关系(过去和将来关系)连接的图的节点。
设置一个窗口大小用于限制每个话语前后的语句数量,并使用\(\mathcal{P}\)和\(\mathcal{F}\)作为超参数,在对话中的每个语句中形成过去\(\mathcal{P}\)语句和未来\(\mathcal{F}\)语句之间的关系。
例如,语句\(u^{(S1)}_i\)(说话者1发言)中的\(R_{intra}\)和\(R_{inter}\)被定义为:
其中\(←\)和\(→\)分别代表过去和未来的关系类型
2.3 关系GCN RGCN
RGCN是一种用于处理多边类型图的图卷积神经网络。它是在GCN的基础上,为了解决多边类型图中不同边关系对节点的影响而提出的
使用RGCN捕捉说话者之间和说话者内部对连接语句的依赖
其中\(\mathcal{N}_r(i)\)表示关系\(r∈ \mathbb{R}\)下节点\(i\)的相邻集,\(Θ_{root}\)和\(Θ_r\)表示RGCN的可学习参数,\(|\mathcal{N}_r{(i)}|\)是归一化常数,\(\rm z_j\)是来自Transformer的语句水平特征。
2.4 图形变换器 Graph Transformer
GraphTransformer是一种图上的Transformer,它在transformer的注意力分数中,添加了边信息和空间信息。这种方法更好地利用图数据集以edge attribute的形式提供的丰富特征信息
使用Graph Transformer赋予从RGCN获取的节点特征 \(H=x^′_1,x^′_2,...,x^′_n\),
其中,注意系数\(α_{i,j}\)由多头点积注意力计算获得:
2.5 情绪分类 Emotion Classifier
GraphTransformer \((h^′_i)\)提取的特征之上的线性层,用于预测与语句对应的情绪。
其中\(\hat{y}_i\)是为语句\(u_i\)预测的情感标签
3. 实验结果分析
3.1 IEMOCAP和MOSEI 数据集上的结果
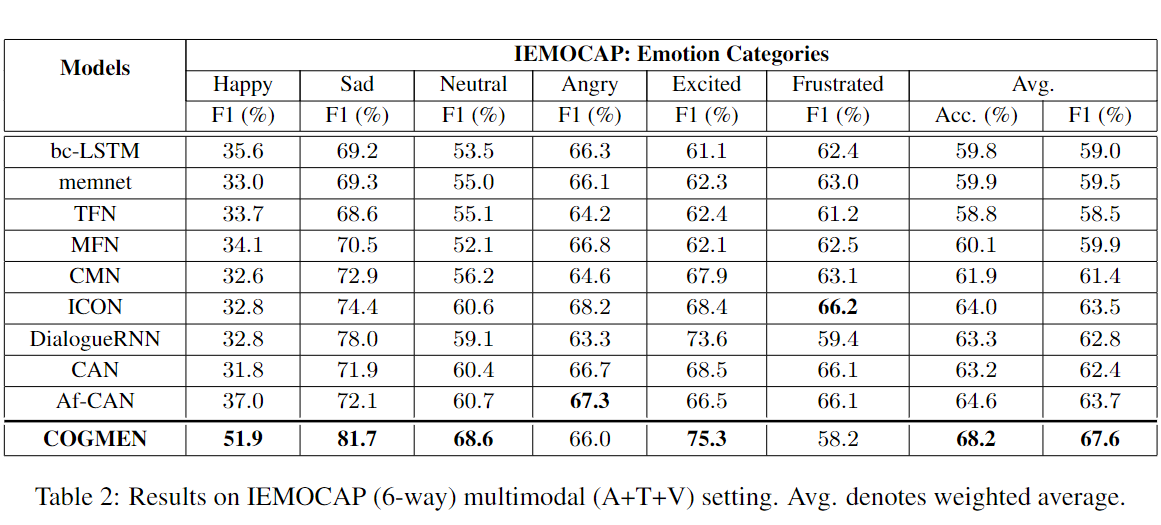
IEMOCAP
-
COGMEN在使用准确性和F1-score测量时表现得比之前的所有基线都要好
-
快乐、悲伤、中性和兴奋情绪的分类F1的改善
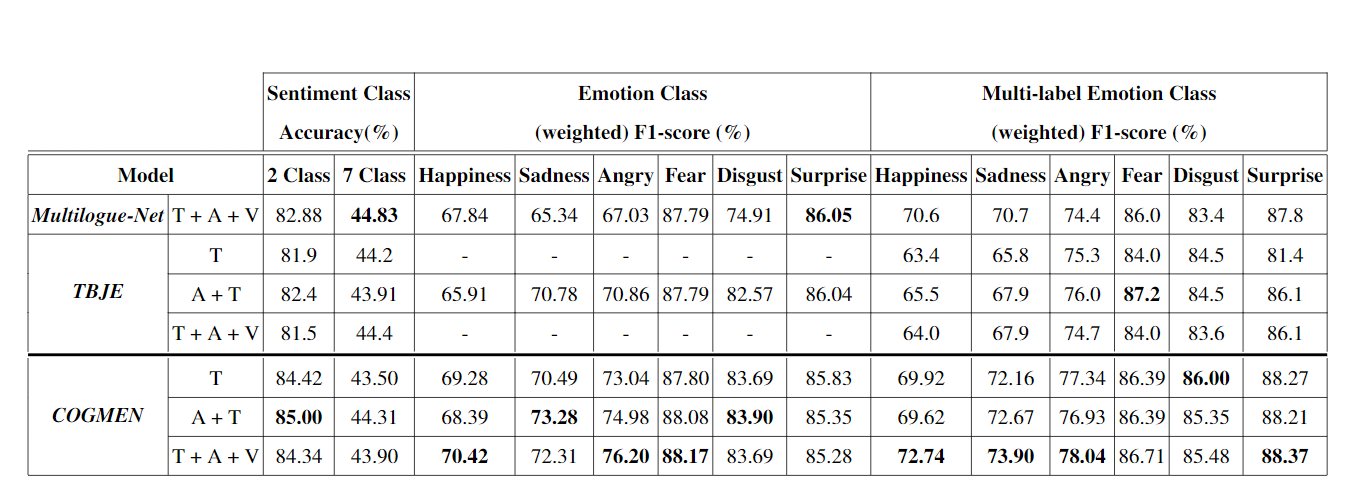
MOSEI -
COGMEN在大多数情况下优于基线模型
-
对于二元情绪分类,COGMEN优于之前A+T的最高准确率为85%的基线;对于七元情绪,也显示了相当的性能。
-
所有的多模态方法在添加视觉模态时往往表现不佳,可能是因为视觉模态中存在噪声,以及与其他模态缺乏对齐。相比之下,COGMEN可以捕获各种模式之间的丰富关系,并在添加可视模式的同时显示性能提升
3.2 模型分析
本地和全局信息的影响**
- 用IEMOCAP (4-way)设置创建了一个子数据集,控制对话中的语句数量:
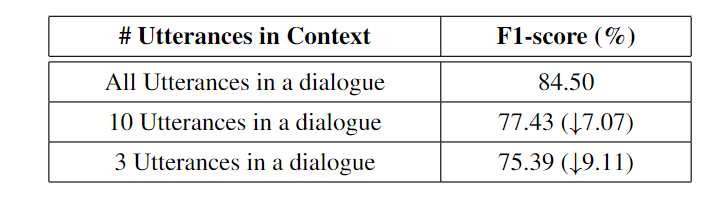
表面了上下文信息的重要性,当语句数量增加时,模型的性能也会提高 - 去掉GNN模块,直接将上下文提取的特征传递给情感分类器来测试局部信息假设
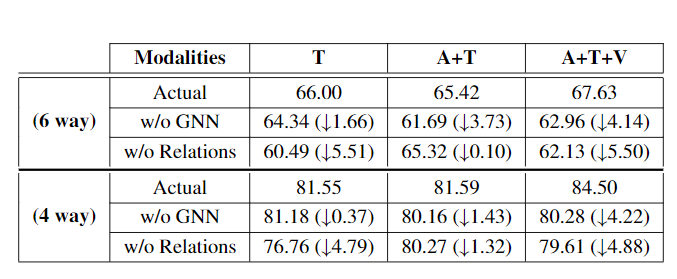
当GNN组件从架构中移除时,各种模式的性能下降,更明确了全局信息的重要性
GNN层的影响
可视化GNN组件之前和之后的特征,清楚地显示了添加GNN层后情绪簇的更好形成,
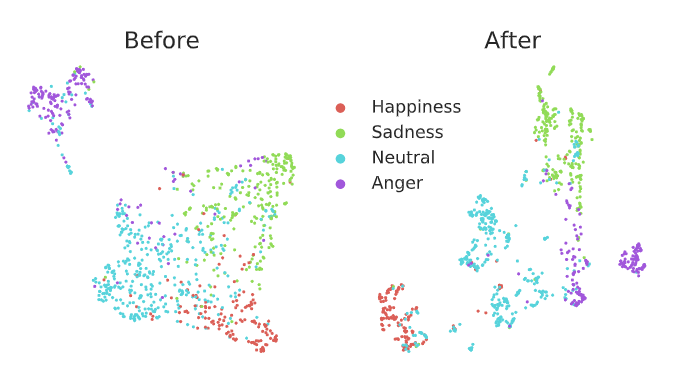
说明捕捉语句中的局部依赖关系对更好地表现情绪识别的重要性
关系类型的影响
在graph formation这一步保持关系不变,将会导致性能下降。说明显式关系的形成有助于捕获对话中出现的局部依赖关系。
模态数量量的影响
COGMEN作为一种相当通用的体系结构,相对于SOTA单模态体系结构,它仍然提供了更好的(对于IEMOCAP (4-way))或类似的性能。通过其他模式添加更多的信息有助于提高性能

语句的影响
通过一次掩盖一个语句并计算F1-score来推断训练后的模型对对话的影响,验证语句的影响及其在对话预测中的重要性

在前4种语句中,情绪状态为中性时,掩蔽语句的效果明显较小。相比之下,用情绪变化掩盖语句(9,10,11)完全降低了对话的f1得分,这表明该架构捕捉到了语句中情绪的影响
3.3 误差分析
- 模型在区分相似的情绪方面存在不足
- 模型有倾向错误地将其他情绪标签归类为中性
- 例子中情绪发生变化的情况下与不变的情况相比性能较差
4 结论和不足
结论
- 提出了一种使用GNN进行多模态情感识别的新方法
- 并提出COGMEN:基于上下文化GNN的多模态情感识别
- COGMEN在多模态情感识别方面优于现有的最先进的方法(即IEMOCAP(4-way)的f1分数提高了7.7%)
- 通过对COGMEN的综合分析和烧蚀研究,展示了不同模块的重要性
不足
- 难以区分相似情绪
- 情绪发生变化的情况下与不变的情况相比性能较差
- 在离线工作(已经获取了全部对话,之后的对话对预测仍有影响)比在线工作(对话进行预测时,只能看到之前的对话)中表现更好,在线实时工作时性能改进值得探索