单应性(Homography)变换:可以简单的理解为它用来描述物体在世界坐标系和像素坐标系之间的位置映射关系。对应的变换矩阵称为单应性矩阵。
单应性矩阵在 图像校正、图像拼接、相机位姿估计、视觉SLAM等都有应用。
单应性矩阵主要涉及两个函数:
1 findHomography(srcPoints, dstPoints[, method[, ransacReprojThreshold[, mask[, maxIters[, confidence]]]]]) -> H, mask
( M = cv2.getPerspectiveTransform(src,dst) 该函数也可以获取透视变换矩阵)
计算多个二维点对之间的最优单应性矩阵 H(3行x3列) ,使用最小均方误差或者RANSAC方法。函数功能:找到两个平面之间的转换矩阵。
参数说明:
srcpoints: 是源平面中的坐标矩阵,dstpoints: 是目标平面的坐标矩阵,类型是CV_32FC2或者float32型。
method: 是计算单应性矩阵的方法:0 -- 利用所有点的常规方法;RANSAC -- 随机抽样一致性方法;LMEDS -- 最小中指鲁棒算法 ;RHO - PROSAC -- 基于PROSAC的鲁棒算法。
ransacReprojThreshold:将点对视为内点的最大允许重投影错误阈值(仅用于RANSAC和RHO方法),该参数通常设置在1到10的范围内。
mask:可选输出掩码矩阵,通常由鲁棒算法(RANSAC或LMEDS)设置。请注意,输入掩码矩阵是不需要设置的。
maxIters:RANSAC算法的最大迭代次数,默认为2000.
confidence:可信度,取值0-1.
2 warpPerspective(src, H, dsize[, dst[, flags[, borderMode[, borderValue]]]]) -> dst
( dst = cv2.perspectiveTransform(pts,H) 该函数可以根据输入的坐标获取透视变换后的坐标)
通过输入变换矩阵得到透视图片。
参数说明:
src 输入图片;dst 输出图片。
M 输入的透视变换矩阵,大小是3*3
dsize 输出图片的大小
flags 插值方法(INTER_LINEAR或INTER_NEAREST)与可选标志WARP_INVERSE_MAP的组合,将M设置为逆变换(???→???)。
borderMode 边界像素赋值操作(BORDER_CONSTANT or BORDER_REPLICATE),前者是定值,后者是复制周围像素。
borderValue 指定定值具体是那个值,默认是0
单应性矩阵的应用:
1 图像校正
主要时把一个坐标系变换成另外一个坐标系,可以把一张“斜”的图变“正”,把图像投影到一个新的视平面。
利用 getPerspectiveTransform(src,dst) 获取矩阵,需要定义原图四个坐标点,变换后的对应四个坐标点。warpPerspective 进行透视变换。
首先,原图上的四个角的点可以用微信截图来确定roi区域的四个角的坐标点位置,或者用鼠标事件输出四角坐标。
利用鼠标事件获取roi区域的四个角坐标:
# 直接根据鼠标双击获取图像当前位置的像素值
import cv2
import numpy as np
img = cv2.imread('./guanggao2.jpg')
img_hsv = cv2.cvtColor(img,cv2.COLOR_BGR2HSV) #转换到hsv空间
#print(img.shape)
def mouse_event(event,x,y,flags,param):
if event == cv2.EVENT_LBUTTONDBLCLK: #双击左键显示图像的坐标和对应的rgb值
print('img pixel value at(', x, ',', y, '):',img[y, x]) #坐标(x,y)对应的像素值应该是img[y,x]
text = '(' + str(x) + ',' + str(y) + ')' + str(img[y,x])
cv2.putText(img,text,(x,y),cv2.FONT_HERSHEY_SIMPLEX,0.5,(255,0,0),1) #绘制文字
if event == cv2.EVENT_RBUTTONDBLCLK: #双击右键显示图像的坐标和对应的hsv值
print('img_hsv pixel value at(', x, ',', y, '):',img_hsv[y, x]) #坐标(x,y)对应的像素值应该是img_hsv[y,x]
text = '(' + str(x) + ',' + str(y) + ')' + str(img_hsv[y,x])
cv2.putText(img,text,(x,y),cv2.FONT_HERSHEY_SIMPLEX,0.5,(0,0,255),1) #绘制文字
cv2.namedWindow('image',cv2.WINDOW_NORMAL) #定义窗口
#cv2.resizeWindow('image',(800,800))
cv2.setMouseCallback('image',mouse_event) #鼠标回调
while True:
cv2.imshow('image',img)
if cv2.waitKey(1)==ord('q'):
break
cv2.destroyAllWindows()
利用鼠标双击获取roi的左上,左下,右下,右上四个角的坐标点:


源图像的变换坐标有了,然后可以定义对应变换后的坐标,根据变换后的物体位置和宽高可以估计出变换后的坐标,然后进行透视变换:
import cv2 #图像仿射变换--透视变换,即把一个坐标系变换成另外一个坐标系,可以把一张“斜”的图变“正”,把图像投影到一个新的视平面
import numpy as np #getPerspectiveTransform(src,dst)获取矩阵,需要原图四个坐标点,变换后的对应四个坐标点。warpPerspective透视变换
img_book = cv2.imread('./book_cv.jpg')
h,w,c =img_book.shape
src = np.float32([[308,207],[62,424],[304,617],[522,319]]) #用微信截图来确定roi区域的四个角的坐标点位置(或者用鼠标事件输出四角坐标)
dst = np.float32([[300,200],[300,500],[510,500],[510,200]])
# dst = np.float32([[0,0],[0,300],[210,300],[210,0]]) #只保留roi区域,warpPerspective函数中尺寸设置为roi的宽高
M = cv2.getPerspectiveTransform(src,dst) #透视变换矩阵
print(M)
new_book = cv2.warpPerspective(img_book,M,(w,h)) #透视变换 二维平面获得接近三维物体的视觉效果的算法
# new_book = cv2.warpPerspective(img_book,M,(210,300)) #透视变换 变换后的roi区域的宽高,只保留roi区域
cv2.imshow('img_book',img_book)
cv2.imshow('new_book',new_book)
cv2.waitKey(0)
cv2.destroyAllWindows()

也可以只保留变换后的roi区域,其他部分不要:
import cv2 #图像仿射变换--透视变换,即把一个坐标系变换成另外一个坐标系,可以把一张“斜”的图变“正”,把图像投影到一个新的视平面
import numpy as np #getPerspectiveTransform(src,dst)获取矩阵,需要原图四个坐标点,变换后的对应四个坐标点。warpPerspective透视变换
img_book = cv2.imread('./book_cv.jpg')
h,w,c =img_book.shape
src = np.float32([[308,207],[62,424],[304,617],[522,319]]) #用微信截图来确定roi区域的四个角的坐标点位置(或者用鼠标事件输出四角坐标)
# dst = np.float32([[300,200],[300,500],[510,500],[510,200]])
dst = np.float32([[0,0],[0,300],[210,300],[210,0]]) #只保留roi区域,warpPerspective函数中尺寸设置为roi的宽高
M = cv2.getPerspectiveTransform(src,dst) #透视变换矩阵
print(M)
# new_book = cv2.warpPerspective(img_book,M,(w,h)) #透视变换 二维平面获得接近三维物体的视觉效果的算法
new_book = cv2.warpPerspective(img_book,M,(210,300)) #透视变换 变换后的roi区域的宽高,只保留roi区域
cv2.imshow('img_book',img_book)
cv2.imshow('new_book',new_book)
cv2.waitKey(0)
cv2.destroyAllWindows()

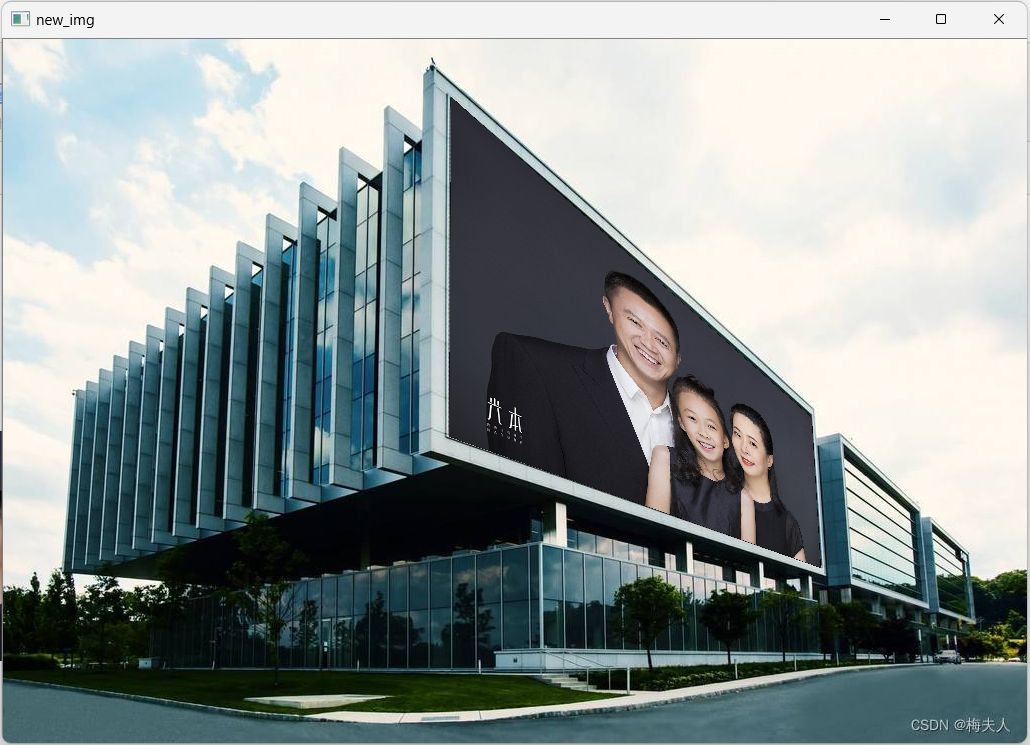
2 更换广告牌的图片
有了前面的透视变换,如果指定区域就可以把该区域的内容替换掉,常用的就是更换广告牌的图片。
先把需要嵌入的图片进行透视变换到有广告牌的图片的对应区域,然后用多边形填充的办法把嵌入区域的像素全部变成0,最后把变换后的图片添加到广告牌的位置即可。
import cv2 #更换广告牌的图片
import numpy as np
img1 = cv2.imread('./mans.jpg')
img2 = cv2.imread('./guanggao2.jpg')
h1,w1,c1 = img1.shape
src = np.float32([[0,0],[0,h1-1],[w1-1,h1-1],[w1-1,0]]) #需要嵌入的原图片的四角坐标(img1) 逆时针坐标
dst = np.float32([[448,58],[446,397],[817,528],[808,378]]) # 待嵌入图片区域的位置坐标(img2)
M = cv2.getPerspectiveTransform(src,dst) #透视变换矩阵
h2,w2,c2 = img2.shape
new_img1 = cv2.warpPerspective(img1,M,(w2,h2)) #透视变换 二维平面获得接近三维物体的视觉效果的算法
# dst = np.array([[174,308],[117,617],[830,544],[832,88]])
dst = dst.astype(int) #多边形的坐标需要整型
cv2.fillConvexPoly(img2,dst,[0,0,0]) # 用多边形填充的办法把嵌入区域的像素全部变成0
new_img = cv2.add(img2,new_img1) #把变换后的图片插入到广告牌的位置
cv2.imshow('img1',img1)
cv2.imshow('new_img1',new_img1)
cv2.imshow('new_img',new_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
对应图片如下:


更换广告牌之后的结果如下:
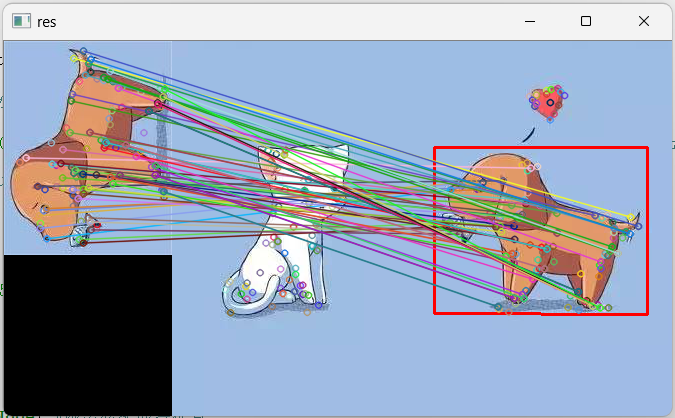
3 图片查找
通过前面介绍的特征匹配和单应性矩阵可以实现图像查找。基本原理是通过特征匹配得到匹配结果(匹配特征点),作为输入,得到单应性矩阵,再经过透视变换就能找到最终图像。与之前的模板匹配比较类似,但是通过特征匹配和透视变换可以更精确。
两幅图片如下:


import cv2
import numpy as np
img1 = cv2.imread('./dog.jpg')
img2 = cv2.imread('./cat_dog.jpg')
img_gray1 = cv2.cvtColor(img1,cv2.COLOR_BGR2GRAY)
img_gray2 = cv2.cvtColor(img2,cv2.COLOR_BGR2GRAY)
#创建特征检测器
sift = cv2.xfeatures2d.SIFT_create()
#计算特征点和描述子
kp1,des1 = sift.detectAndCompute(img_gray1,None)
kp2,des2 = sift.detectAndCompute(img_gray2,None)
#创建特征匹配器
index_params = dict(algorithm=1,trees=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params,search_params)
#对描述子进行特征匹配
matches = flann.knnMatch(des1,des2,k=2) #用的knnmatch匹配
goods = [] #选择两个匹配对象中好一些的保存下来
for (m,n) in matches:
if m.distance < n.distance*0.7:
goods.append(m)
print('goods',len(goods))
#把找到的匹配特征点保存在goods中,注意单应性矩阵要求最少4个点
if len(goods) >= 4:
#把goods中的第一幅图和第二幅图的特征点坐标拿出来(坐标要float32且是三维矩阵类型 reshape(-1,1,2))
src_points = np.float32([kp1[m.queryIdx].pt for m in goods]).reshape(-1,1,2)
des_points = np.float32([kp2[m.trainIdx].pt for m in goods]).reshape(-1,1,2)
print('des_points:',des_points)
#根据匹配上的关键点去计算单应性矩阵
H,mask = cv2.findHomography(src_points,des_points,cv2.RANSAC,5) #参数5表示:允许有5个关键点的误差
#通过单应性矩阵,计算小图(img1)在大图中的对应位置
h,w = img1.shape[:2]
pts = np.float32([[0,0],[0,h-1],[w-1,h-1],[w-1,0]]).reshape(-1,1,2) #img1的四个边框顶点,逆时针(坐标从0开始,因此要w-1,h-1)
#用透视变换函数找到这四个顶点对应的img2的位置,不用warpPerspective,这是对图像的透视变换,用perspectiveTransform()
dst = cv2.perspectiveTransform(pts,H)
print('pts:',pts)
print('dst:',dst)
#在大图中把dst画出来,polylines
cv2.polylines(img2,[np.int32(dst)],True,[0,0,255],2)
else:
print('matches is not enough')
exit()
res = cv2.drawMatchesKnn(img1,kp1,img2,kp2,[goods],None) #画出匹配的特征点
cv2.imshow('res',res)
cv2.waitKey(0)
cv2.destroyAllWindows()
查找结果如下(图比较简单,查找容易,如果干扰比较多的话效果不一定有这么好):
4 图像拼接
把两幅图像拼接在一起,可以做全景图像。
图像拼接思路:1 读取图片,灰度化。 2 计算图片的特征点和描述子。3 匹配特征。4 根据匹配到的特征,计算单应性矩阵。5 对其中一张图片进行透视变换。6 创建一张大图,放入两张图片
两幅待拼接图像如下:


import cv2
import numpy as np
img1 = cv2.imread('./map1.png')
img2 = cv2.imread('./map2.png')
#img1 = cv2.resize(img1,(640,480))
#img2 = cv2.resize(img2,(640,480))
img_gray1 = cv2.cvtColor(img1,cv2.COLOR_BGR2GRAY)
img_gray2 = cv2.cvtColor(img2,cv2.COLOR_BGR2GRAY)
#创建特征检测器
sift = cv2.xfeatures2d.SIFT_create()
#计算特征点和描述子
kp1,des1 = sift.detectAndCompute(img_gray1,None)
kp2,des2 = sift.detectAndCompute(img_gray2,None)
#创建特征匹配器
index_params = dict(algorithm=1,trees=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params,search_params)
#对描述子进行特征匹配
matches = flann.knnMatch(des1,des2,k=2) #用的knnmatch匹配
goods = [] #选择两个匹配对象中好一些的保存下来
for (m,n) in matches:
if m.distance < n.distance*0.7:
goods.append(m)
print('goods',len(goods))
#把找到的匹配特征点保存在goods中,注意单应性矩阵要求最少4个点
if len(goods) >= 4:
#把goods中的第一幅图和第二幅图的特征点坐标拿出来(坐标要float32且是三维矩阵类型 reshape(-1,1,2)) goods是Dmatch对象
src_points = np.float32([kp1[m.queryIdx].pt for m in goods]).reshape(-1,1,2)
des_points = np.float32([kp2[m.trainIdx].pt for m in goods]).reshape(-1,1,2)
# print('des_points:',des_points)
#根据匹配上的关键点去计算单应性矩阵 第一个图对变成第二个图的视角计算出来的单应性矩阵
H,mask = cv2.findHomography(src_points,des_points,cv2.RANSAC,5) #参数5表示:允许有5个关键点的误差
# #利用H矩阵的逆求解视角和img1特征匹配的点的img2图,并且img1没有像素
# warpimg = cv2.warpPerspective(img2,np.linalg.inv(H),(img1.shape[1]+img2.shape[1],img1.shape[0]+img2.shape[0]))
# direct = warpimg.copy()
# direct[0:img1.shape[0],0:img1.shape[1]] = img1 #将左边的img1的部分重新赋值
else:
exit()
#获取原始图像的高宽
h1,w1 = img1.shape[:2]
h2,w2 = img2.shape[:2]
# 获取两幅图的边界坐标
img1_pts = np.float32([[0,0],[0,h1-1],[w1-1,h1-1],[w1-1,0]]).reshape(-1,1,2)
img2_pts = np.float32([[0,0],[0,h2-1],[w2-1,h2-1],[w2-1,0]]).reshape(-1,1,2)
#获取img1的边界坐标变换之后的坐标
img1_transform = cv2.perspectiveTransform(img1_pts,H)
# print('img1_pts',img1_pts)
# print('img1_transform',img1_transform)
#把img2和转换后的边界坐标连接起来
result_pts = np.concatenate((img2_pts,img1_transform),axis=0)
print(result_pts)
#result_pts.min(axis=0) #对行聚合,返回每一列的最小值
[x_min,y_min] = np.int32(result_pts.min(axis=0).ravel()-1)
[x_max,y_max] = np.int32(result_pts.max(axis=0).ravel()+1)
#ret = cv2.drawMatchesKnn(img1,kp1,img2,kp2,[goods],None)
#手动构造平移矩阵
M = np.array([[1,0,-x_min],[0,1,-y_min],[0,0,1]])
result = cv2.warpPerspective(img1,M.dot(H),(x_max-x_min,y_max-y_min)) #对img1进行平移和透视操作
result[-y_min:-y_min+h2,-x_min:-x_min+w2] = img2 #把img2放进来(因为img1变换后的矩阵也平移了,所以img2也要做对应的平移)
#result[0:h2,0:w2] = img2
# cv2.imshow('direct',direct)
# cv2.imshow('warpimg',warpimg)
# cv2.imshow('ret',ret)
cv2.imshow('result',result)
cv2.waitKey(0)
cv2.destroyAllWindows()
拼接结果如下:

- 矩阵 opencv-python opencv python矩阵opencv-python opencv python opencv-python opencv-python opencv python opencv-python opencv python cv2 python opencv-python exception opencv opencv-python opencv python视频 opencv-python python_pip install python opencv-python pyproject building命令 opencv-python特征opencv python opencv-python图像opencv python