论文精读:ST2Vec 道路网络中的时空轨迹相似性学习
《ST2Vec: Spatio-Temporal Trajectory Similarity Learning in Road Networks》
论文链接:https://doi.org/10.48550/arXiv.2112.09339
一、摘要
轨迹相似性计算用来评估两个轨迹之间的相似性,现有方法强调的是空间相似性而非时间相似性,使得在时间感知分析中不是最佳选择。作者提出的 ST2Vec,是一种基于轨迹表示学习的架构,它考虑了轨迹对之间细粒度的空间和时间相关性,用于道路网络的时空相似性学习,也是首个用于时空轨迹相似性分析的深度学习方案。
ST2Vec 三个阶段:(i) 训练数据准备,选择有代表性的训练样本;(ii) 时空建模,编码轨迹的时空特征,设计通用时空建模模块(TMM);(iii) 时空共注融合(STCF),开发统一融合(UF)方法,帮助生成统一的时空轨迹嵌入,捕捉轨迹之间的时空相似性关系。
此外,ST2Vec 利用课程学习进行模型优化,以提高收敛性和有效性。
课程学习(Curriculum Learning,CL)是一种训练策略,模仿人类的学习过程,主张让模型从容易的样本开始学习,并逐渐进阶到复杂的样本和知识。
二、引言
- 轨迹相似性学习的应用
GPS轨迹T表示为离散时空点的时序序列,即\(\begin{aligned}T=\langle(g_1,t_1),(g_2,t_2),...,(g_n,t_n)\rangle\end{aligned}\) ,g 表示观测到的地理位置,t表示时间。轨迹相似性计算在共享乘车、交通分析、社交推荐等方面广泛应用。例如(i)为司机分配潜在的共享乘车伙伴;(ii)交通管理部门通过汇总相似轨迹和计算道路的出行频率来预测交通拥堵情况;(iii)社交应用程序识别具有相似生活轨迹的用户来进行好友推荐。 - 轨迹相似性学习的相关研究
(1)手工距离测量方法:基于自由空间的测量方法(DTW、LCSS、Hausdorff和ERP)、基于路网的测量方法(TP、DITA、LCRS和 NetERP)。
缺点:计算成本较高,限制了基于相似性的下游轨迹分析的可扩展性。
思想:依赖于点式匹配计算,即需要扫描两条轨迹上的所有点对来计算相似性得分,二次时间复杂度\(O(\hat{n}^{2})\),其中\(\hat{n}\)是平均轨迹长度。
(2)神经网络方法:通过神经网络获得轨迹表征(嵌入),通过轨迹嵌入之间的相似性关系反映GPS轨迹之间的相似性关系。
优点:复杂度低,O(d),速度快。
思想:在给定一对轨迹的情况下,将轨迹映射到 d 维向量,根据轨迹的嵌入向量计算轨迹之间的相似性。
(3)现有方法局限性:忽略时空轨迹的时间维度,时间感知场景中效率低下。 - 举例说明“为什么要考虑时空相似性--共享乘车”
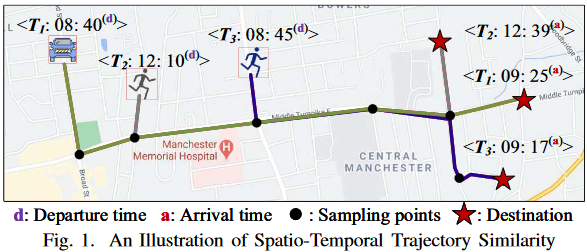
情境:\(T_1\)表示一名司机计划的行程,\(T_2\)和\(T_3\)属于两个寻找搭车机会的人。
空间角度:推荐\(T_2\),但和\(T_2\)的出发时间相差很大,推荐结果无用。
时空角度:推荐\(T_3\)。
结论:在交通规划和监控等时间感知应用中,考虑空间和时间相似性非常重要。 - 轨迹时空相似性研究的三个挑战及应对方法
挑战一:如何捕捉轨迹之间的时间相关性?
思想:生成面向时间的嵌入保留轨迹之间的时间相似性关系。思路是将轨迹的时间序列$T^{(t)}=\langle t_{1},t_{2},...,t_{n}\rangle $输入RNN模型,以捕捉时间序列信息。
特殊性:轨迹的空间位置是离散的,可以通过特定的测量方法来评估空间关系,而时间信息表现出很强的连续性和周期性。
应对方法:时序建模模块(TMM),灵活、通用,可以与任何现有的空间轨迹相似性学习方案相结合,实现时空相似性学习。 - 挑战二:如何融合时空轨迹嵌入,实现统一的时空相似性学习?
特殊性:不同的用户可能会赋予空间和时间相似性不同的权重,以适应不同的应用。(eg:区域函数估计等应用可能会高度重视轨迹的空间方面,共享乘车等应用可能会高度重视时间方面)因此,一种可取的融合方法必须能够自适应地学习不同的空间和时间权重,并且不影响模型的收敛性,尤其是在同时考虑时间和空间维度来生成轨迹嵌入的情况下。
应对方法:时空共关注融合模块(STCF),采用统一的融合方法将独立的空间和时间信息融合在一起获得统一的嵌入。
挑战三: 如何优化模型以提高有效性和效率?
特殊性:目标的有效性(相似性查询质量)和效率(模型收敛速度)。
应对方法:新的三元组采样策略,然后利用课程倾斜训练模型。为了避免时空建模造成的参数过多,在STCF中提供两种不同的融合方法。
三、相关概念
道路网络和轨迹
- 定义 1:道路网络
有向图\(G=(L,E)\),\(L\)是道路顶点集,\(E\subseteq L\times L\)是道路段的边集。具体来说,顶点$l_i=(x_i,y_i)\in $表示道路交叉口或道路终点, \(x_i\) 和 \(y_i\) 分别表示 \(l_i\) 的经度和纬度。边\(e_{l_i,l_j}\in E\)表示从 \(l_i\) 到 \(l_j\) 的有向路段。 - GPS 轨迹\[,n 表示 T 的长度。每个采样点表示为一个 2 维(位置、时间)元组,即$(g_i,t_i),i\in[1,n]$。其中,$g$表示由经度和纬度组成的观测地理位置,$t$表示相应的时间。 \]
- 定义 2:路网中的轨迹
本文的目标是受道路网络限制的轨迹相似性学习,因此使用地图匹配程序将轨迹点 \(g\) 与顶点 \(l\) 对齐。具体来说,假定轨迹点位于 \(G\) 中的顶点上。处理位于边上的轨迹点非常简单:如果点 \(g\) 位于边 \(e\) 上,通过引入一个新顶点 \(l_g\) 将 \(e\) 分割成两条子边。因此,每个原始轨迹 \(T\) 都被转换成 \(G\) 中从起点顶点到终点顶点的有向路径,定义如下。
给定道路网络\(G = (L,E)\),轨迹 \(T\) 是 \(G\) 中\(\textit{m(}m\leq n)\) 个顶点的有向序列,即$T=\langle(l_1,t_1),(l_2,t_2),...,(l_m,t_m)\rangle \(,其中\)l_{i}\in L\(是一个顶点,\)t_i\(是相应的时间。 给定一个轨迹\)T\(,用\)T(s)\(和\)T(t)\(分别表示空间和时间方面,即**空间轨迹**\)T^{(s)}=\langle l_1,l_2,...,l_m\rangle $,时间轨迹 $T^{(t)}=\langle t_1,t_2,...,t_m\rangle \(。\)T(s)\(和\)T(t)$在每一步都是同步对应的。
时空相似性与学习目标
在给定轨迹\(T_i\)和\(T_j\)的情况下,将时空轨迹相似性函数\(\mathcal{D}(T_i,T_j)\)定义为空间和时间相似性的加权线性组合。(首次将线性组合法用于时空轨迹相似性)
\(\mathcal{D}_S\)和\(\mathcal{D}_T\)分别表示空间和时间相似性,\(\lambda\in[0,1]\)控制着空间和时间相似性的相对权重。
四、问题描述
问题目标
对于任意一对轨迹\(T_i\)和\(T_j\),时空轨迹相似性学习的目标是学习一个神经网络驱动函数\(\mathcal{G}(\cdot,\cdot)\)使得\(\mathcal{G}\left(v_{T_i},v_{T_j}\right)\)最大程度地接近\(\mathcal{D}\left(T_{i},T_{j}\right)\)
其中,\(\mathcal{M}\)是神经网络的模型参数,\(\mathcal{D}\)是时空轨迹相似性函数,\(v_{T_i},v_{T_j}\)是\(T_{i},T_{j}\)的时空嵌入。
传统方法与ST2Vec方法
-
方法一
将时间轴分割成离散的时间区间,使用滑动窗口方法将轨迹分配到不同的时间区间,使用现有的空间相似性学习方法对每个时间区间进行相似性计算。
特点:①以空间为导向,粒度较粗。②时间是连续无界的,很难确定合适的窗口长度,无论选择哪种长度时空相似性计算不准确的情况不可避免。③依赖于离散时间和轨迹处理,会产生额外的处理成本。 -
方法二
将轨迹的时间序列馈送给 RNN,就像将轨迹的位置序列馈送给 RNN 一样。然后,将得到的时间向量与空间向量相结合,实现时空相似性学习。
特点:更合理但很幼稚。时间相关性比空间相关性更复杂,因为时间是连续的,而相关性可能是周期性的。 -
ST2Vec方法

step1 Training Data Construction
利用相似和不相似的锚轨迹对来构建输入相似性三元组
step2 ST2Vec Representation Learning同时考虑空间和时间维度,学习嵌入轨迹,将轨迹映射到低维空间(如虚线矩形所示)。
step3 ST2Vec Similarity Learning学习轨迹嵌入的过程一直持续到嵌入向量上评估的轨迹相似性(用浅蓝色和浅黄色立方体表示)接近公式 1 计算出的地面实况相似性(用蓝色和黄色立方体表示)为止。
为了生成面向时空相似性的嵌入(带红色边缘的绿色矩形),必须捕捉轨迹中的时间和空间信息,并以统一的方式融合这些信息。为实现这一目标,STVec 包含三个主要模块,即时间建模模块(TMM)、空间建模模块(SMM)和时空协同融合模块(STCF)。
五、ST2Vec 方法
时间建模模块(TMM)
捕捉一对时间轨迹之间的相关性,普通的序列模型RNN、LSTM等无法处理时间的周期性和非周期性时间模式。作者将时间嵌入与时序嵌入相结合,构建轨迹感知时序建模模块,同时引入注意力函数增强对时间不规则性的表示(不同时间点具有不同的重要性,eg上下班高峰期与深夜)
-
时间嵌入
\[t^{\prime}[i]=\begin{cases}\omega_it+\varphi_i,&\mathrm{~if~}i=0\\\cos\left(\omega_it+\varphi_i\right),&\mathrm{~if~}1\leq i\leq q&\end{cases}\quad(3) \]\(t^{\prime}[i]\)表示\(t^{\prime}\)的第\(i\)个元素,\(\omega\)和\(\varphi\)是可学习参数,\(cos(-,-)\)是周期激活函数,捕捉周期性行为。线性项表示时间的推移,用于捕捉输入中与时间相关的非周期性模式。实现时间轨迹\(T^{(t)}\)嵌入到时间向量序列中,即$\langle t_1,{t_2},...,t_m\rangle\rightarrow\langle t_1{\prime},t_2,...,t_m^{\prime}\rangle $
-
时序嵌入
如果暂时不关注时空共关注融合模块,将每个时间点嵌入轨迹后,就可以将$\langle t_1{\prime},t_2,...,t_m^{\prime}\rangle \(送入 LSTM 以建立其时间依赖性模型。LSTM 的递归步骤如下。在每一步 i,一个 LSTM 单元将当前输入向量\)x_i\(和上一步的状态\) h_{i-1} $作为输入,并输出当前一步的状态向量 \(h_i\)。\[h_i=\operatorname{LSTM}\left(t_i^{\prime},h_{i-1},i_i,f_i,o_i,m_i\right),\quad\quad(4) \]其中,\(i_i,~f_i,~o_i,~\mathrm{and~}~s_i\)分别代表输入门、遗忘门、输出门和存储单元。在 LSTM 层中,\(t_i^{\prime}\)是学习到的时间嵌入,与原始时间\(t_i\)相对应。LSTM 单元利用上一步的嵌入时间、隐藏状态和单元状态计算新的隐藏状态并更新单元状态。最终,将最后一个隐藏状态\(h_t\)视为深度时间轨迹表示。
-
去耦合注意力
轨迹中的不同时间点在计算中具有不同的权重。用注意力机制计算同一轨迹中时间点之间的注意力得分,捕捉轨迹点之间的相关性。\[\tilde{h}_i^{(p)}=\sum_{k=1}^i\mathrm{att}\left(h_i^{(p)},h_k^{(p)}\right)\cdot h_k^{(p)}\quad\quad(5) \]\(\tilde{h}_i^{(p)}\)表示改进后的状态表示。
\[\mathrm{att}\left(h_i^{(p)},h_k^{(p)}\right)=\frac{\alpha_{i,k}}{\sum_{k^{\prime}=1}^i\exp\left(\alpha_{i,k^{\prime}}\right)}\quad\quad(6) \]\(\alpha_{i,k}=w_1^\top\cdot\tanh\left(W_1\cdot h_k^{(p)}+W_2\cdot h_i^{(p)}\right)\) ,作者还使用最后一步的隐藏表示来编码完整的时序轨迹。
空间建模模块(SMM)
给定空间轨迹$T^{(s)}=\langle l_1,l_2,...,l_m\rangle \((\)l_i\(表示\)G\(中的顶点),目标是**将\)T^{(s)}\(嵌入低维空间中的向量\)v_{T(s)}$,以捕捉其受道路网络约束的空间信息。**
- 位置嵌入
background是在道路网络中移动的物体的轨迹受到道路网络拓扑结构的限制。因此,如果两个空间上接近的采样点在道路网络中连接不好,它们之间的距离仍然可能很大。利用 Node2Vec方法,捕捉道路网络中相邻位置的共生关系。
具体来说,给定一个顶点\(l_i\),Node2Vec 来近似其邻域中顶点的空间条件概率,即\(l_i\to n_i\)的映射,\(l_i,n_i\)分别表示原始位置和嵌入位置。那么,共享相似邻域的位置往往具有相似的嵌入。接下来,逐步将嵌入位置输入到 GNN获得局部平滑的位置嵌入。给定道路网络 G 和位置\(l_i \in G\)的低维表示\(n_i\),GCN 函数定义如下。
其中,\(l_i^{\prime}\)是顶点/位置表示,\(\sigma\)是非线性激活函数,\(c_ij\)是邻接权重,\(W_s\in\mathcal{R}^{d\times d}\)是\(G\)中所有顶点共享的可学习矩阵,\(||\)表示连接操作,\(\mathcal{N}_{i}\)是\(n_i\)在\(G\)中的邻接顶点集合。最终得到每个空间轨迹的细粒度表示,即$\langle l_1,l_2,...,l_m\rangle\rightarrow\langle l_1{\prime},l_2,...,l_m^{\prime}\rangle $。
-
空间序列嵌入和空间注意力
同时间序列嵌入和注意力模块
时空协同融合模块(STCF)
STCF使用两种融合策略:
-
分离融合(SF)
先用两个独立的 LSTM 模型生成轨迹的空间和时间嵌入,然后将两种嵌入合并。给定轨迹 T 及其初始时间嵌入\((t_{1}',t_{2}',...,t_{m}')\)和初始空间嵌入\((l_1^{\prime},l_2^{\prime},...,l_m^{\prime})\),基于单独融合的时空轨迹嵌入定义为:\[v_T=LSTM_t(t_1^{\prime},t_2^{\prime},...,t_m^{\prime})+LSTM_s(l_1^{\prime},l_2^{\prime},...,l_m^{\prime})\quad(8) \]方法简单有效,但需要两个 LSTM 模型分别捕捉时间信息和空间信息,参数数量增加一倍。
-
统一融合(SF)

给定一条轨迹,计算初始时间序列嵌入\(\tau^{(t)}=\langle t_{1}^{\prime},t_{2}^{\prime},...,t_{m}^{\prime}\rangle\)以及它的初始空间序列嵌入$\tau^{(s)}=\langle l_{1}{\prime},l_{2},...,l_{m}^{\prime}\rangle \(。用一个共同关注融合模块,通过相互作用来增强它们。 **step1 通过矩阵\)W_F$对时间和空间特征进行转换**\[z_\tau^1=W_F\tau^{(t)},\quad z_\tau^2=W_F\tau^{(s)}\quad\quad(9) \]step2 计算两个特征之间的相互作用
其中,$W_{Q}^{\prime}\mathrm{~and~}W_{K}^{\prime}$是与$W_F$形状相同的矩阵,$\tau^{(\hat{t})}\mathrm{~and~}\tau^{(\hat{s})}$是$\tau^{(t)}\mathrm{~and~}\tau^{({s})}$的增强表示。
**
step3 将增强的初始时空序列嵌入输入相同的单一 LSTM 架构,以实现统一的时空轨迹嵌入**。
统一融合方式的形式定义:
训练和模型优化
- 数据选择
在给定轨迹数据集的情况下,随机选择一条轨迹作为锚点\(T_a\),并抽取一条相似(或不相似)的轨迹作为其正向\(T_p\)(或负向 \(T_n\))轨迹。这样一个锚、一个正轨迹和一个负轨迹的三元组构成了一个相似性三元组\((T_a,T_p,T_n)\)。 - 训练过程
将考虑时间和空间因素的轨迹嵌入三元组,即\(f_\theta^{(t,s)}:(T_a^{(t,s)},T_p^{(t,s)},T_n^{(t,s)})\to(v_a^{(t,s)},v_p^{(t,s)},v_n^{(t,s)})\)。\(f_{\theta}^{(t,s)}\)提供了\(\mathcal{G}\)的功能,时空相似度可以通过基于\(\|v_a-v_p\|_2\mathrm{~and~}\|v_a-v_n\|_2\) 的\(L_2\)准则计算。
地面真实相似度\(\mathcal{D}_{a,p}\)归一化为$\mathcal{D}{a,p}^{\prime}=\exp(-\alpha\cdot \mathcal{D}) \in [0,1] \(.\)\alpha$是控制相似度值大小的可调参数。 - 损失函数:定义时空感知损失函数用于测量相似性三元组的加权平方误差之和。
这种设计将空间相似性和时间相似性合并为一个统一的度量,ST2Vec 可以根据不同的偏好调整不同的空间和时间权重,而无需考虑 λ 的大小。
- 优化
使用由易到难的训练样本,对于轨迹锚\(T_a\)及其 k 个相似(不相似)的轨迹锚,得到 k 个训练三元组。对这些三元组进行排序,先是容易的(即最不相似的),然后是困难的(最相似的)。然后,从易到难输入这些三元组。
复杂度分析
计算路网中一对轨迹之间的相似性,基于成对计算方法的时间复杂度为\(O((E+L\lg L)\cdot m^2)\),其中\(O(E+L\lg L)\)是寻找两个顶点之间最短路径的成本,\(m\) 是平均轨迹长度。因此,传统方法无法有效地应用于聚类等下游任务,因为这些任务必须计算所有轨迹对之间的距离。相比之下,ST2Vec 计算轨迹相似性的时间复杂度为 \(O(d)\),其中 \(d\) 为常数维。因此,对于大规模轨迹数据分析来说,ST2Vec 更为高效。由于\(v_{T_i}\mathrm{~and~}v_{T_j}\)都是低维向量,因此一旦 \(\mathcal{G}\) 训练有素,就能在线性时间内计算轨迹间的时空相似性。
实验
实验设置
- 数据集:
T-Drive:2008.2.2-2.8中国北京的1500万个出租车轨迹点
Rome:超过30天的罗马出租车367,052个轨迹点
Xi'an:滴滴公司在一个较弱时间段内出租车的806,482个轨迹点 - 预处理:
所有轨迹与OpenStreetMap中相应的道路网络进行映射匹配(GPS数据→有时间顺序的顶点序列)
从城市地区获取数据并删除采样点少于10个的轨迹数据 - 评估指标和地面实况
验证方法:top-k相似性
指标:HR@10、HR@50、R10@50(越接近去,模型越有效)
top-k相似性搜索的真实结果使用传统的基于非倾斜的距离度量(包括TP、DITA、LCRS、NetERP)
评估相似性学习效果的基本思路:将基于倾斜的方法返回的前 k 个结果与非学习方法产生的前 k 个结果进行比较HR@k:top-k命中率,捕捉top-k结果与相应地面实况结果之间的重叠程度
R k@t:top-k地面实况的top-t召回率,捕捉top-k地面实况在相应top-t结果中的比例。 - 基准
NEUTRAJ、Traj2SimVec、T3S、GTS
dUI上述4中方法进行时间控制的扩展得到3类12条baselines
①窗口引导基线(\(*^{w}\)):将轨迹分布在离散的时隙中,并在每个时隙中执行 top-k 相似性查询,结果是 \(\text{NEUTRAJ}^w,\text{ Traj}2\text{SimVec}^w,\text{ TЗ}\mathrm{S}^w,\mathrm{~and~}\mathrm{GTS}^w\)。
LSTM 引导基线(\(*^{l}\)):将时间轨迹直接输入 LSTM 模型,得到 \(\text{NEUTRAJ}^l,\text{ Traj}2\text{SimVec}^l,\text{ TЗ}\mathrm{S}^l,\mathrm{~and~}\mathrm{GTS}^l\)。
③TMM 引导基线(\(*^{t}\)):将我们的时空轨迹嵌入模块(即 TMM)集成到baselines中,得出\(\text{NEUTRAJ}^t,\text{ Traj}2\text{SimVec}^t,\text{ TЗ}\mathrm{S}^t,\mathrm{~and~}\mathrm{GTS}^t\)。
模型有效性研究
表1、2、3分别是ST2Vec和12个baselines在三个数据集上的结果。
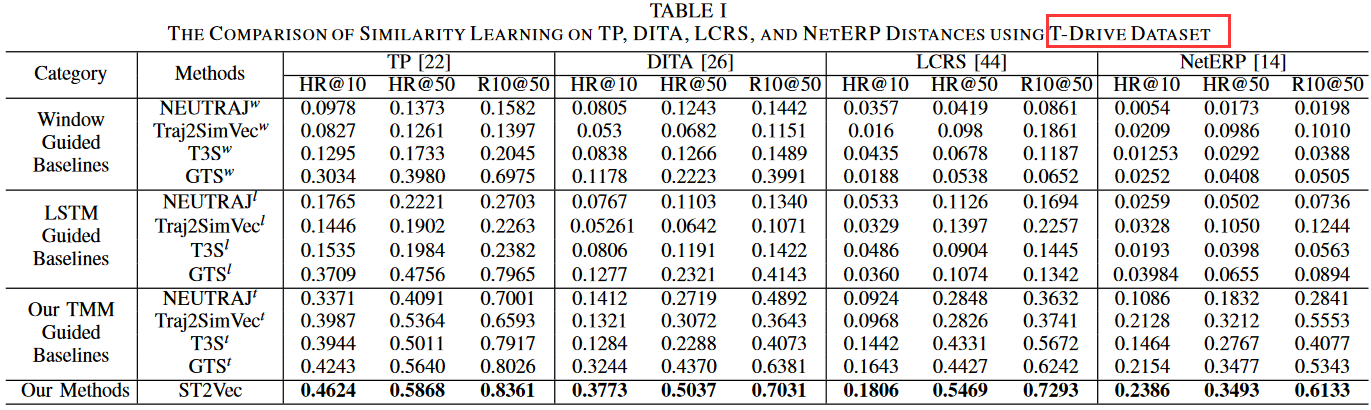

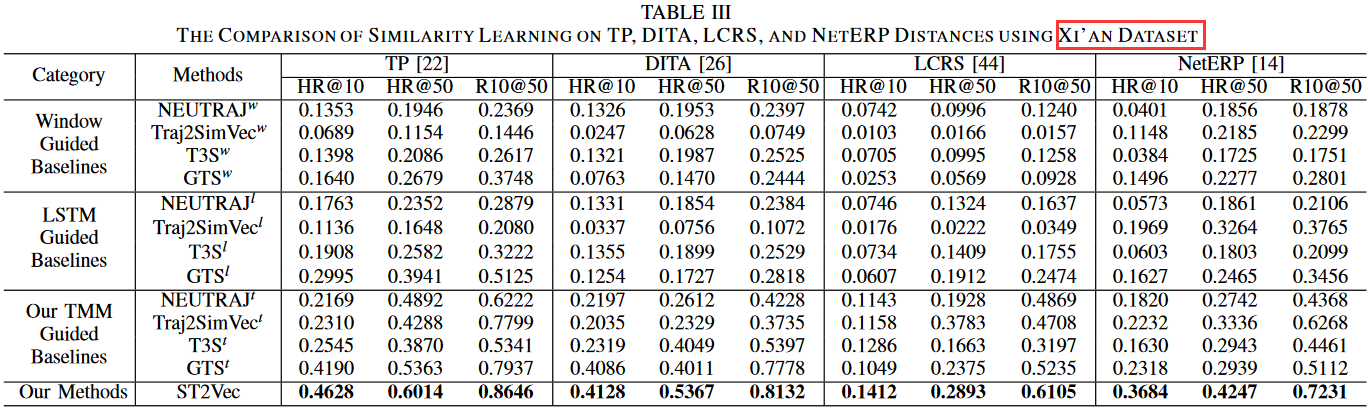
结论1:TMM 引导的基线方法明显优于窗口引导和 LSTM 引导的基线方法,表明所提出的时空轨迹嵌入模块是有效的。原因是基于窗口和 LTSM 的方法忽略了时间的连续性和周期性模式,限制了其有效性。
结论2:在同一类别中,GTS 和 ST2Vec 在所有指标上都优于其他方法。原因是 GTS 和 ST2Vec 在空间相关性建模中考虑了路网拓扑结构,而其他方法只能捕捉自由空间中的序列特征,无法嵌入路网的结构依赖性。
结论3:在所有距离测量和所有数据集上,ST2Vec 的准确度都大大高于 GTS。原因是GTS是基于 POI 的轨迹相似性计算,而忽略了相邻 POI 之间的实际旅行路径。ST2Vec 是为细粒度轨迹相似性学习而设计的,它同时考虑了相邻样本位置之间的位置和移动路径。
模型高效性研究
从离线模型训练(以秒/epoch为单位,表示为训练)和在线计算(以秒/4 千条轨迹为单位,表示为计算)两个方面研究模型的效率。图 4 显示了 T-Drive 和 Rome 的结果。请注意,由于性能差异很大,Y 轴的刻度是对数。
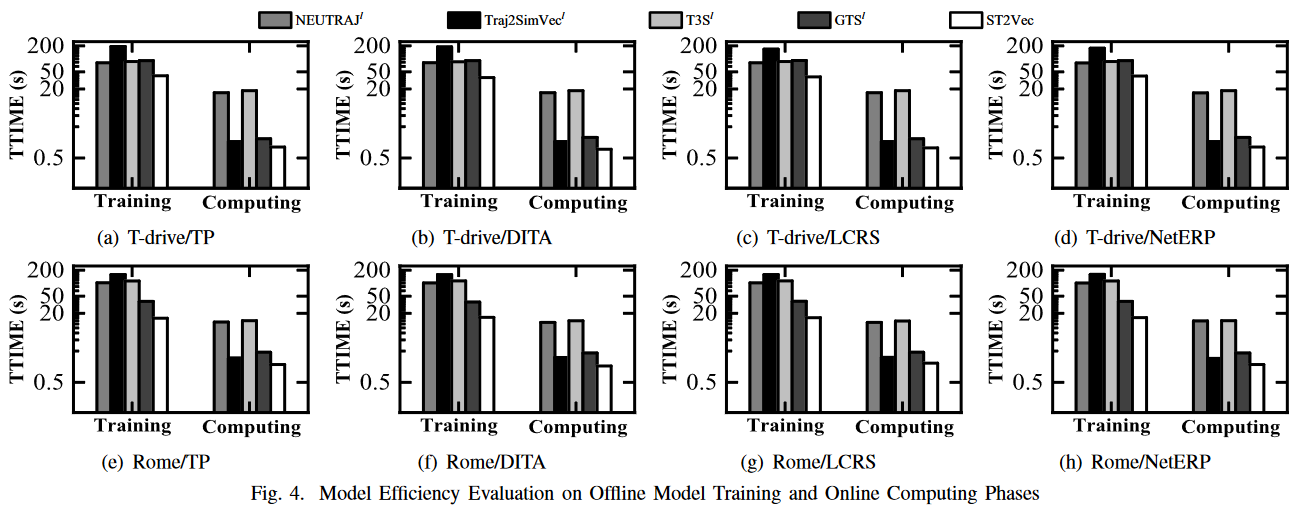
只将 ST2Vec 与 LSTM 引导的基线进行比较,因为它们的性能优于窗口引导的基线,而且 TMM 引导的基线基本上是基于我们的 TMM 模块。可以看出,ST2Vec 在训练和计算方面都有很好的表现。以 T-drive 的结果为例。在训练阶段,ST2Vec 在 40 秒内完成每个 epoch,运行速度比 NEUTRAJ、T3S 和 GTS 快 2 倍,比 Traj2SimVec 快 5 倍。在相似性计算(即测试)方面,计算每种方法在测试数据上的总运行时间。在这里,ST2Vec 也表现出卓越的性能(即在 1 秒内),比 NEUTRAJ 和 T3S 快 20 倍,比 Traj2Sim 和 GTS 快 2 倍。
模型可扩展性研究
当轨迹数量从 10k 到 200k 变化时模型具有可扩展性。原因:运行时间随着轨迹数量的增加而增加。与现有方法相比,ST2Vec 的性能有了大幅提升。与四种基线方法相比,ST2Vec 的性能受基数增加的影响较小。
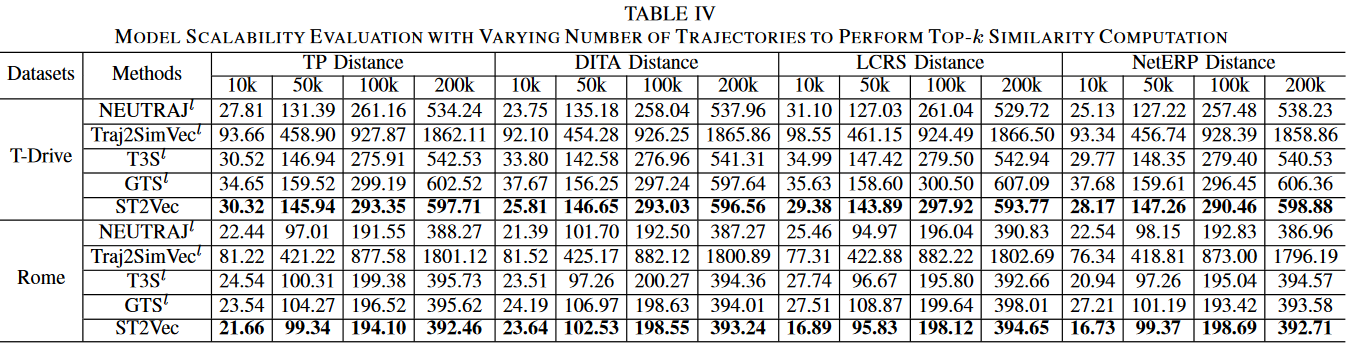
参数敏感性研究
考虑了训练数据大小、为每个轨迹构建的三元组数量 N 和时空权重 \(\lambda\) 对模型性能的影响。
1.对训练数据大小的敏感性:训练轨迹数量对 ST2Vec 性能的影响。图 5 显示了当训练数据量从 10k 到 200k 时,四种测量方法的相似性学习性能)。可以看出,ST2Vec 表现稳定。
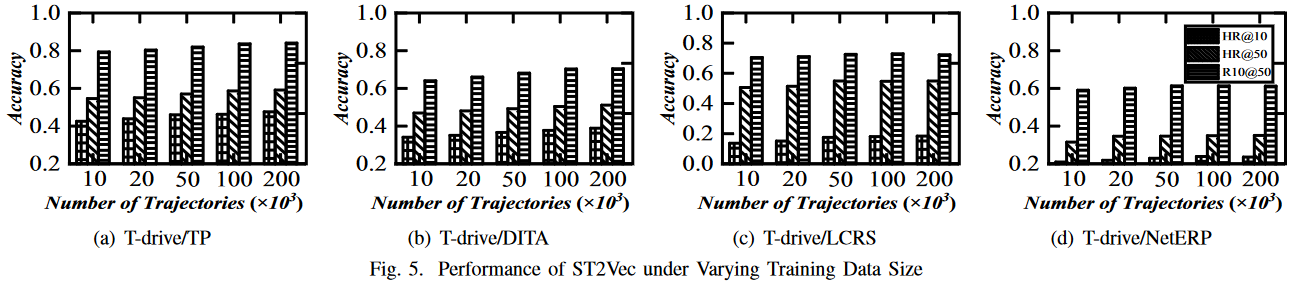
2.对\(N\)的敏感性:从 T-Drive 中随机抽取 10k 条轨迹,对于每条轨迹,我们分别取其 1、3、6、15 和 30 条最相似/不相似的轨迹来构建相似性三元组。图 6 显示了使用四种距离度量的结果。可以看出,HR@10、HR@50 和 R10@50 都略有增加,这证明 ST2Vec 即使在训练样本有限的情况下也能取得良好的性能。
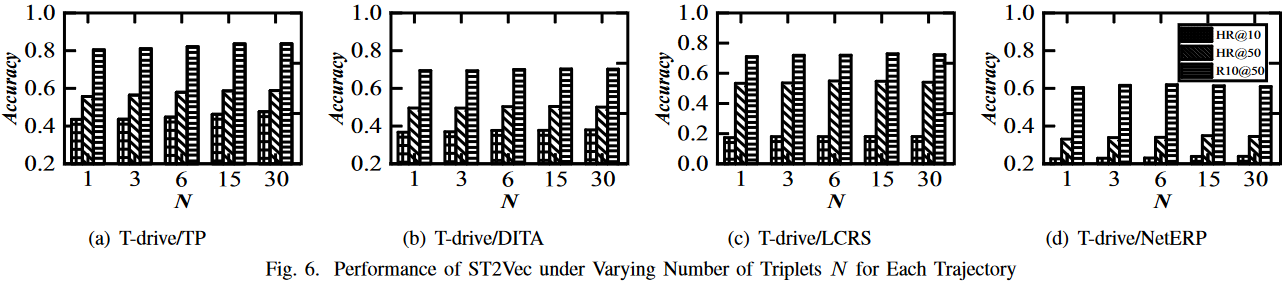
3.对 \(\lambda\) 的敏感性:当 \(\lambda=1\) 时,只考虑空间域;当 \(\lambda= 0\) 时,类似计算只考虑时间域。图 7 显示,在不同的 \(\lambda\) 设置下,HR@10、HR@50 和 R10@50 的性能都很稳定,表明 ST2Vec 在不同的 \(\lambda\) 偏好下都能很好地工作。
消融实验
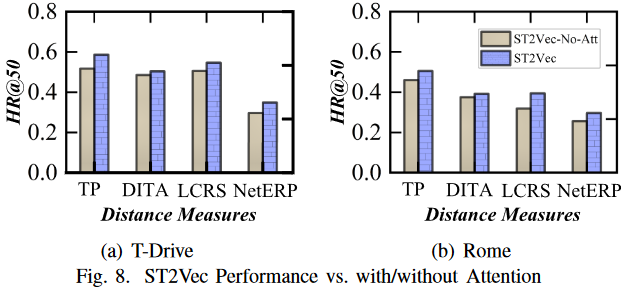
1.有无注意力的ST2Vec对比:ST2Vec 去除无注意力后得到模型ST2VecNo-Att。T-Drive 的 HR@50 结果如图 8 所示,表明空间和时间注意力机制是有效的。以 TP 为例,与 ST2Vec-No-Att 相比,ST2Vec 将 HR@50 从 0.51 提高到 0.58。
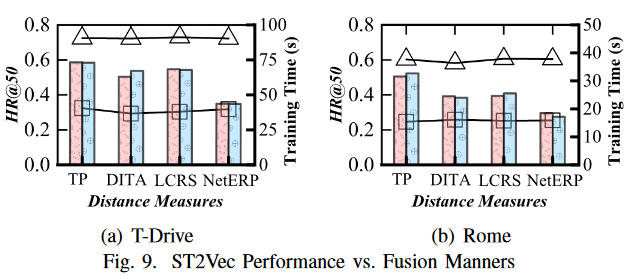
2.ST2Vec 与融合方法的性能对比:使用单独融合(SF)和统一融合(UF)来训练 ST2Vec。图 9 显示,使用统一融合的 ST2Vec 与使用单独融合的效果相似。不过,ST2Vec-UF 比 ST2VecSF 实现了更快的模型收敛,因为 SF 具有两个独立的 LSM 模型,导致需要调整的参数数量是 UF 的两倍。
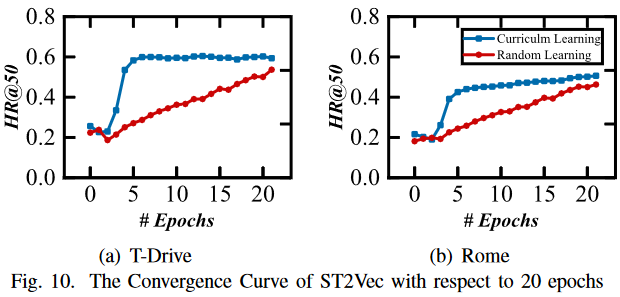
3.ST2Vec 性能的课程/随机学习的对比:为了评估课程学习对模型性能的影响,考虑了所有四种距离。图 10 显示,与随机批量学习相比,课程学习指导下的学习过程收敛更快,计算质量更高(即 HR@50)。
效率加速研究
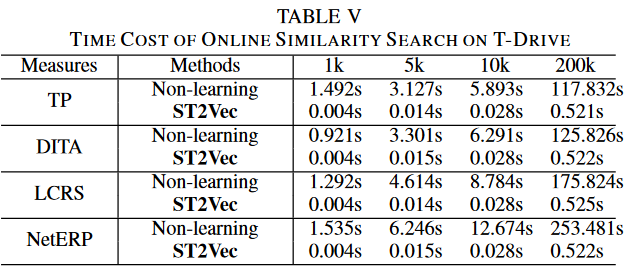
比较使用基于 ST2Vec 的方法和传统的基于配对的方法计算相似性。表 V 是对不同数据量的每个查询轨迹进行前 50 个时空相似性搜索的平均时间成本,比较了 ST2Vec 和非学习方法的查询效率。可以看出,ST2Vec 比基于非学习的方法提高了 200-400 倍的速度。
案例研究
使用 T-Drive 进行轨迹顶-k 查询和聚类,直观地检验 ST2Vec 的能力。

查询方面:随机选择一条轨迹作为查询轨迹。然后根据 TP 绘制它的前 2 个地面实况轨迹,以及 ST2Vec 返回的前 2 个相似轨迹。图 11 左侧绘制了不同的轨迹,显示 ST2Vec 返回的轨迹与地面实况轨迹非常吻合。
聚类方面:使用 DBSCAN 聚类来探索 ST2Vec 在将参数 minPts 固定为 10 时的有效性。也使用了 TP比较地面实况距离和基于嵌入距离的聚类结果。如图 11 右侧所示,随着 $\epsilon $ 的增长,两种结果中的聚类数量呈现出相似的趋势,这意味着 ST2Vec 也能很好地进行聚类分析。
总结
作者提出的 ST2Vec 是一种基于表示学习的架构,用于道路网络中的时空相似性学习,同时支持一系列轨迹测量。使用三个真实数据集进行的广泛实验证实,ST2Vec 能够比最先进的方法提高有效性、效率和可扩展性。此外,基于相似性的 top-k 查询和聚类案例研究也证明了 ST2Vec 在下游分析方面的潜力。