Auto Encoder(自编码器)
- Self Supervised Learning(自监督学习):用没有标注的资料训练模型,发明不需要标注资料上的任务,例如:做填空题、预测下一个token(符号);在BERT和GPT之前,有一种方法就是Auto Encoder
- Auto Encoder(自编码器):也是一种用没有标注的资料训练的模型
Auto Encoder运作方式:
其中包括两个Network,分别是Encoder和Decoder,Encoder把图片转换为一个vector(向量),Encoder就是Dimension reduction(降维),Decoder再把生成的向量转化为图片,要求与原图片越接近越好,所以Decoder的架构像GAN中Generator,(Auto Encoder的概念和Cycle GAN的概念一模一样),有些人把Vector当成Code
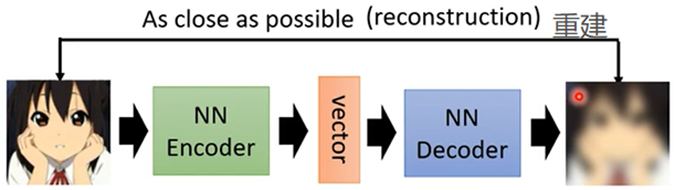
降维的技术还有PCA、t-SNE;
- De-Noising Auto Encoder:输入Encoder的图片加入一些杂讯
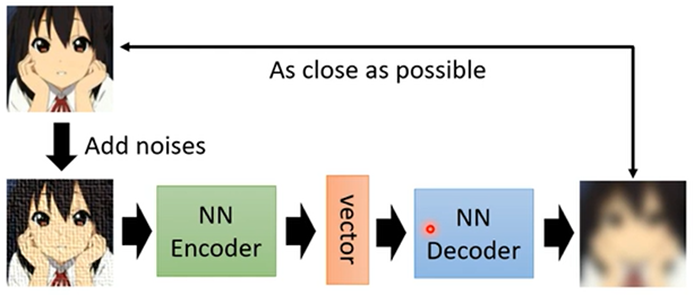
所以BERT的过程就像De-Noising Auto Encoder:输入时遮盖部分内容就是添加杂讯,BERT输出向量就像Encoder,根据输出向量输出结果时就是Decoder:

Feature Disentanglement(功能解开纠缠)
- Feature Disentanglement:把原来纠缠在一起时的东西解开
引入:
- 把图片、一段声音或文章丢进Encoder,得出一个向量,而输入的全部资讯都混杂在这个向量中;现在需要把这些资讯清晰的分开
如:输入一段声音,普通的Auto Encoder输出的向量不知道内容在多少维度、说话人的特征在多少维,所以想办法训练一个模型Auto Encoder,使得出的向量前k维度代表说话的内容、后k维代表说话人的特征,这个过程就是Feature Disentanglement

应用:
- voice Conversion(声音转换)
变声器,在过去,需要A和B两个人所同样的话得到训练资料;在出现Feature Disentanglement之后不需要A和B说同样的话,甚至不需要说同一种语言,都可能转换,只需要训练出Feature Disentanglement,把向量中两个人的声音内容部分保留,交换声音特征,便可以将声音转换

Discrete Latent Representation(离散潜在表征)
引入:
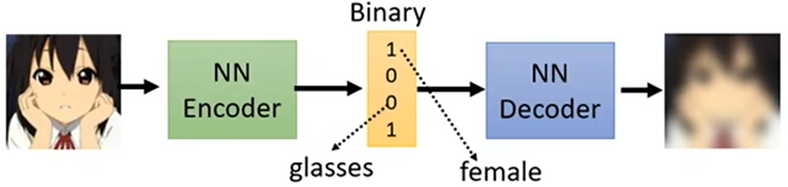
- 输入一张图片,让Encoder输出的向量为二进制向量,任意维代表图片中的特征的有无,如:第一维代表是女生,第三维代表是否戴眼镜
如:Encoder输入一段文字,输出向量,再传入Decoder输出原文章,现在将Encoder输出向量改成输出另一段文字(文章的摘要)
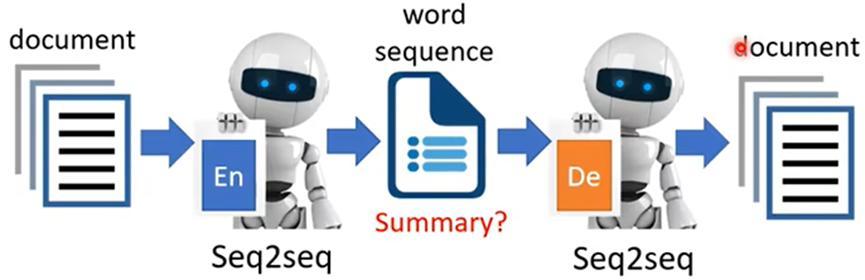
事实证明行不通,因为Encoder输出的文字人看不懂;需要再用GAN的概念加入Discriminator,因为Discriminator看过人写的句子,所以Encoder输出的句子要“骗”过Discriminator,就需要输出人能看懂的句子

注:并且每一个Decoder都是Generator。
Encoder就是一个压缩的过程,Decoder 就是一个解压缩的过程;并且这个压缩是有损压缩