来自CVPR2022 基于多尺度令牌聚合的分流自注意力
论文地址:[2111.15193] Shunted Self-Attention via Multi-Scale Token Aggregation (arxiv.org)
项目地址:https://github.com/OliverRensu/Shunted-Transformer
一、Introduction
还是经典的ViT的历史遗留问题:ViT中的自注意力计算是针对一个固定的patch大小的token的,每一层内每个token特征的感受野是相似的。这样的约束不可避免地限制了每个自注意力层在捕获多尺度特征方面的能力,从而导致在处理不同尺度的多个对象的图像时的性能下降。为了解决这个问题,作者提出了一个新颖且通用的策略—shunted self-attention(SSA)。SSA 的关键思想是将异构感受野大小注入标记:在计算自注意力矩阵之前,它选择性地合并标记以表示更大的对象特征,同时保持某些标记以保留细粒度特征。这种新颖的合并方案使 self-attention 能够学习不同大小的对象之间的关系,同时降低令牌数量和计算成本。
二、Motivation
1.计算成本高。自注意力机制带来了昂贵的内存消耗成本。
2.ViT生成的特征图为单一尺度的,粗粒度的,这不可避免地限制了模型的性能。
3.之前的Transformer模型在很大程度上忽略了注意层中场景对象的多尺度特性,使它们在涉及不同大小对象的野外场景中变得脆弱。从技术上讲,这种无能归因于它们潜在的注意机制:现有的方法只依赖于一个注意层内令牌的静态接受域和统一的信息粒度,因此无法同时捕获不同尺度的特征。
三、Contribution
1.提出了SSA,将多尺度信息提取的功能集成在一个自注意力层中,SSA自适应地合并大对象上的令牌以提高计算效率,并保留小对象上的令牌来保留更多细节。SSA的多尺度注意机制是通过将多个注意头分成几个组来实现的。每组都考虑了专用的注意力粒度。对于细粒度组,SSA 学习聚合少量标记并保留更多局部细节。对于剩余的粗粒度头部组,SSA 学习聚合大量标记,从而减少计算成本,同时保留捕获大型对象的能力。多粒度组联合学习多粒度信息,使模型能够有效地对多尺度对象进行建模。
2.在此基础上,构建了一种能高效捕获多尺度目标,尤其是微小和远程的孤立目标的分流变压器。
四、Method
SSA块和ViT中传统的自注意块有两个主要区别:1)SSA为每个自注意层引入了一个分流注意机制,以捕获多粒度信息,更好地建模不同大小的对象,特别是小对象;2)通过增加交叉令牌交互,增强了点向前馈层提取局部信息的能力。此外,我们的分流变压器部署了一种新的补丁嵌入方法,用于为第一个注意块获得更好的输入特征映射。
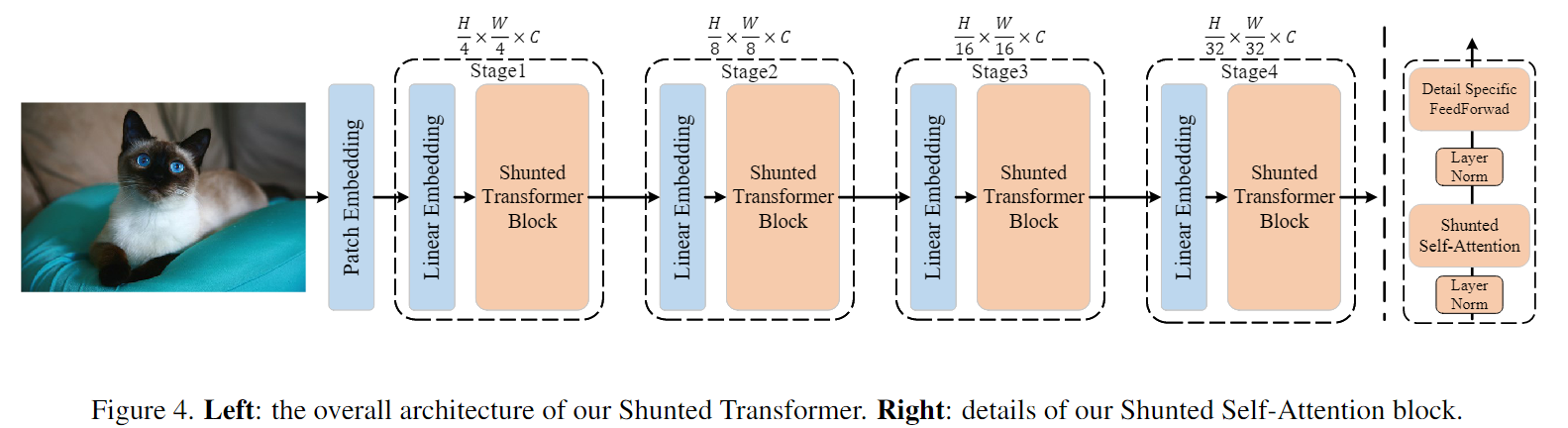
4.1 Shunted Transformer Block
为了降低计算成本,PVT引入了空间减少注意(spatialreduction attention, SRA)来取代原来的多头自注意(multiple -head self-attention, MSA)。然而,SRA倾向于在一个自注意力层中合并太多的令牌,并且只在单个尺度上提供标记特征。这些限制阻碍了模型捕获多尺度目标,特别是小尺度目标的能力。因此,我们通过在一个自注意层中并行学习多粒度引入分流自注意。整体结构后遵循了PVT的层级结构。
4.1.1 Shunted Self-Attention
如图5所示,我们的SSA与PVT的SRA不同之处在于,在同一自注意层的注意头上,K、V的长度不相同。相反,长度在不同的头中变化,以捕获不同粒度的信息。这提供了多尺度令牌聚合(MTA)。具体地,对于由i索引的不同头,K和V被下采样到不同大小,在时间上,下采样操作是由不同大小的卷积完成的,卷积核大小和步长为ri,在一层中有不同的ri,因此,K和V可以关注到不同的尺度,LE(·)是对V值进行深度卷积得到的MTA局部增强分量。与PVT中的SR相比,更多细粒度和低级的细节。
计算成本降低可能取决于 r 的值,因此,我们可以很好地定义模型和 r 以权衡计算成本和模型性能。当 r 变大时,K、V 中的更多令牌合并,K、V 的长度较短,因此计算成本较低,但仍保留捕获大对象的能力。相比之下,当 r 变小时,保留了更多细节,但带来了更多的计算成本。在一个自注意力层中集成各种 r 使其能够捕获多粒度特征。
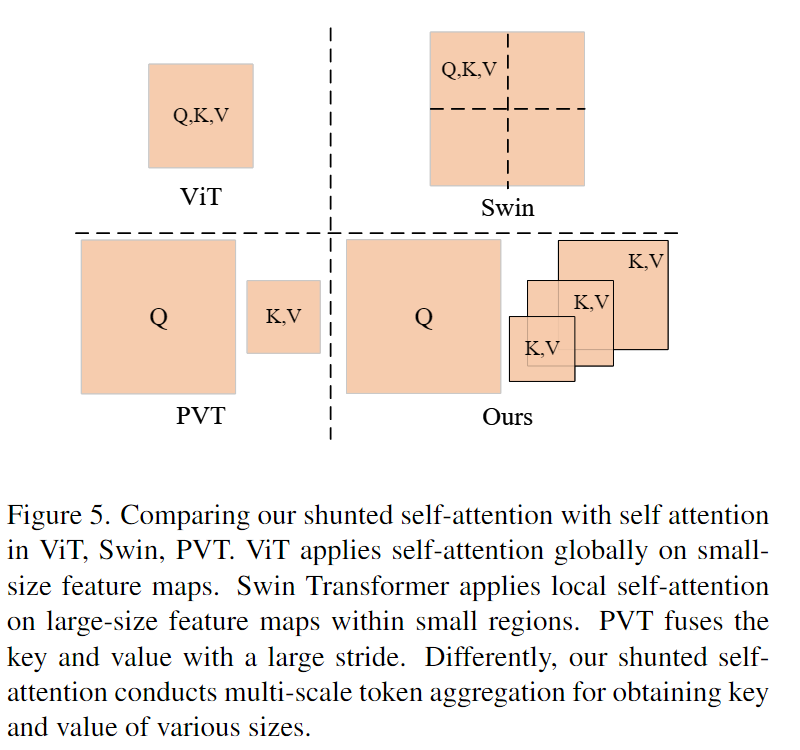

代码部分:原理较为简单,核心是采用了分组的思想,用不同的卷积核和步长进行卷积操作完成下采样这一步,得到两个不同大小的结果,用于获取不同长度的K和V,对V值进行深度卷积得到的MTA局部增强分量与原始的V值相加,得到增强后的的V值,两组k和v分别表示前一半和后一半的head产生的,将q分为两组,然后分别进行两组自注意力的计算得到x1和x2,将x1和x2在维度上进行拼接,得到最终的x。
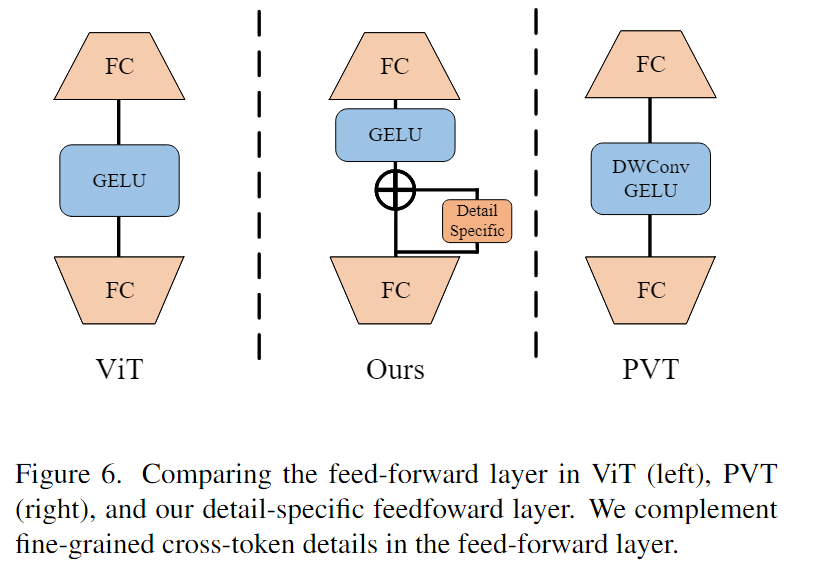
4.1.2 Detail-specific Feedforward Layers
在传统的前馈层中,全连接层是逐点的,不能学习交叉标记信息。在这里,我们的目标是通过指定前馈层的细节来补充本地信息。如图 6 所示,我们通过在前馈层中的两个全连接层之间添加数据特定层来补充前馈层中的局部细节。实践中由深度卷积实现。
 代码:
代码:
4.2. Patch Embedding
ViT直接将输入图像分割成16 × 16个不重叠的补丁。最近的研究发现,在补丁嵌入中使用卷积可以提供更高质量的令牌序列,并帮助Transformer“看到更好”比传统的大步幅非重叠补丁嵌入。因此,一些作品 使用 7 × 7 卷积进行重叠的补丁嵌入。在我们的模型中,我们根据模型大小采用具有不同重叠的卷积层。我们采用步长为 2 和零填充的 7 × 7 卷积层作为补丁嵌入中的第一层,并根据模型大小添加步长为 1 的额外 3 × 3 卷积层。最后,步幅为 2 的非重叠投影层以生成大小为 H/4 × W/4 的输入序列。(CVT等等一系列工作都是用卷积生成token。
五、Conclusion
本文提出了一种新颖的分流自注意力 (SSA) 方案来明确解释多尺度特征。与之前只关注一个注意力层中的静态特征图的工作不同,在一个自注意力层中保持关注多尺度对象的各种尺度特征图。
- Self-Attention Aggregation Multi-Scale Attention Shuntedself-attention aggregation multi-scale attention cross-attention classification multi-scale transformer self-attention self-attention attention self recommendation self-attention sequential stochastic self-attention representation functional attention self-attention local-global interactions transformers self-attention attention笔记self self-attention attention self 4.1 self-attention注意力attention机制