Chubby
在谷歌“三驾马车”中3个系统都是单Master系统,这个Master是系统的单点,一旦Master故障集群就无法提供服务。使用Backup Master,通过监控机制进行切换。但是:
- 如何实现Backup Master和Master完全同步?
- 监控程序也是单点,如何确定是Master宕机还是监控程序到Master的网络断了?后者可能导致集群中出现两个Master
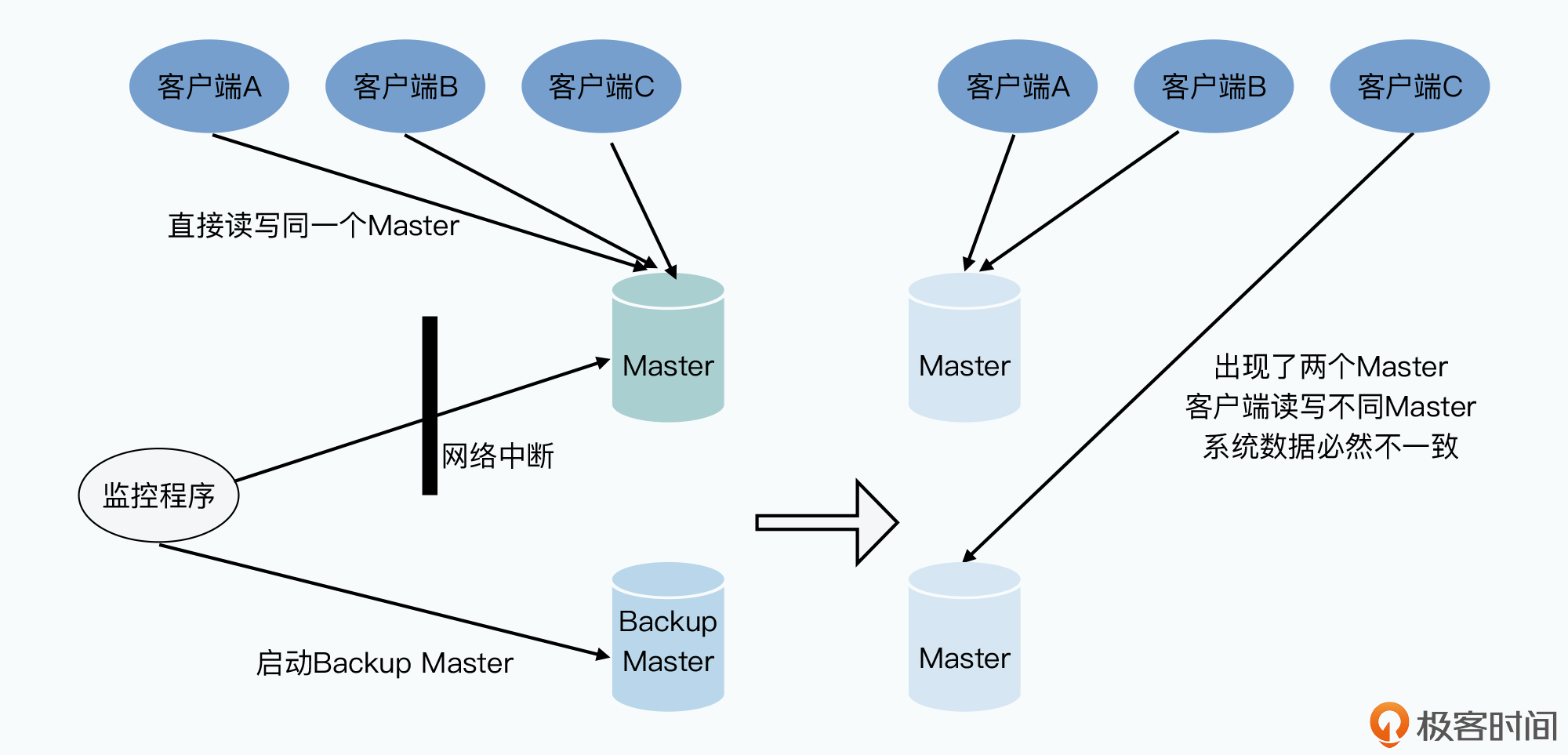
问题本质是分布式共识,Chubby是个粗粒度的分布式锁方案。
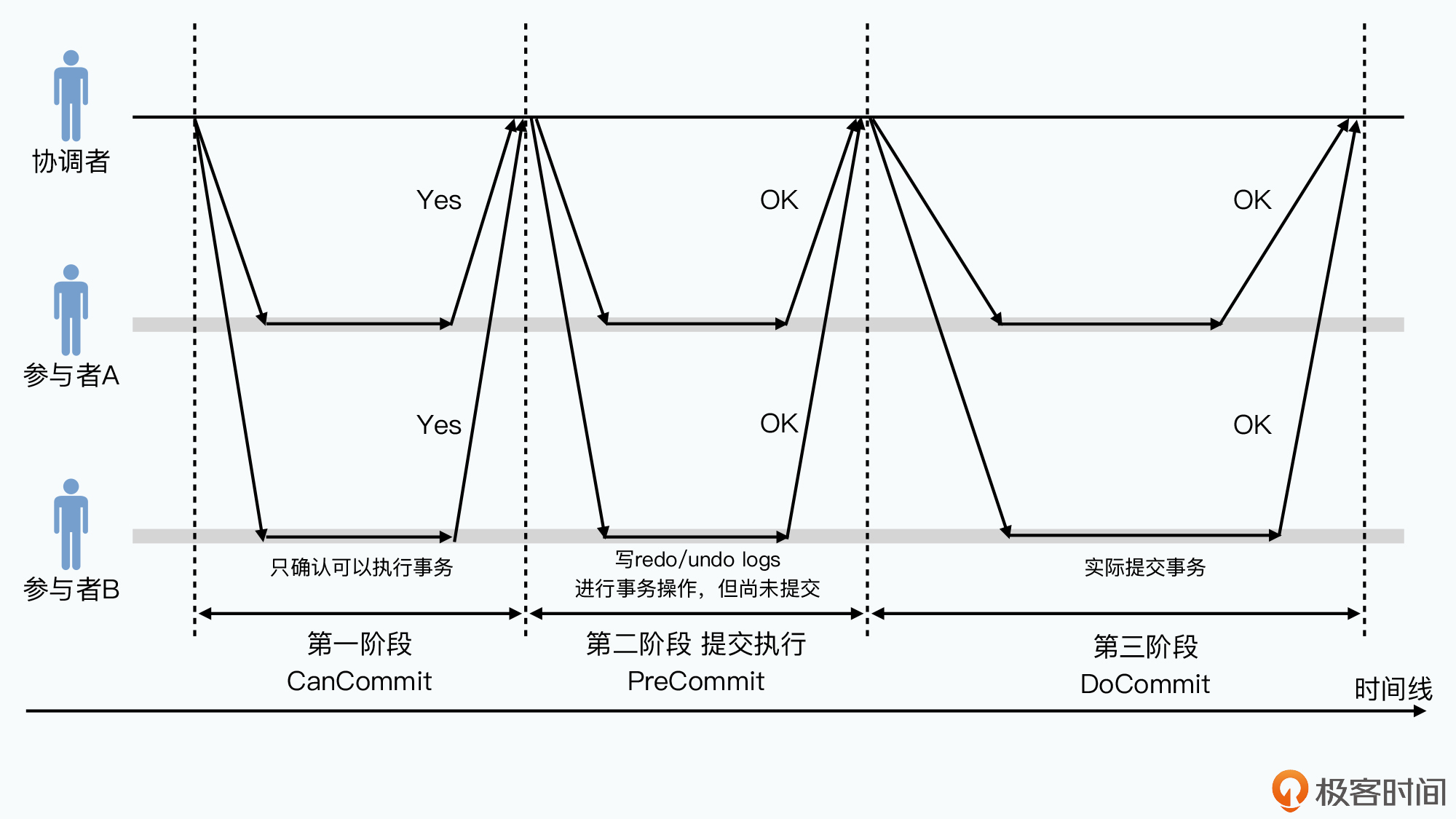
两阶段提交
GFS 的 Master 是一个有同步复制的 Backup Master 的。Bigtable 中 SSTable 只要预写日志WAL写入成功就称为在Master上数据写入成功,但GFS中可能因为在Backup Master里写入数据会因为故障问题失败,这时同步复制失败。Backup Master 和 Master 同步复制就是分布式事务。
2阶段提交(2PC)就是将数据写入拆分为提交请求和提交执行:
- 提交请求
协调者将事务发送所有参与者,参与者判断自己能否成功执行,可以则返回成功,不可以则返回失败。
如果可以要先把要进行的事务预写日志方式写下。这与Bigtable中写入日志就意味数据写入成功不同,这里没有参与者真正生效,且写入的日志包括 redo logs 和 undo logs - 提交执行
如果有参与者返回失败,则事务失败,协调者通知参与者回滚事务。所有参与者返回成功,协调者则再次发起请求告知所有参与者完成哪个事务。事务完成后参与者反馈给协调者,协调者接收所有完成成功的消息后整个事务成功结束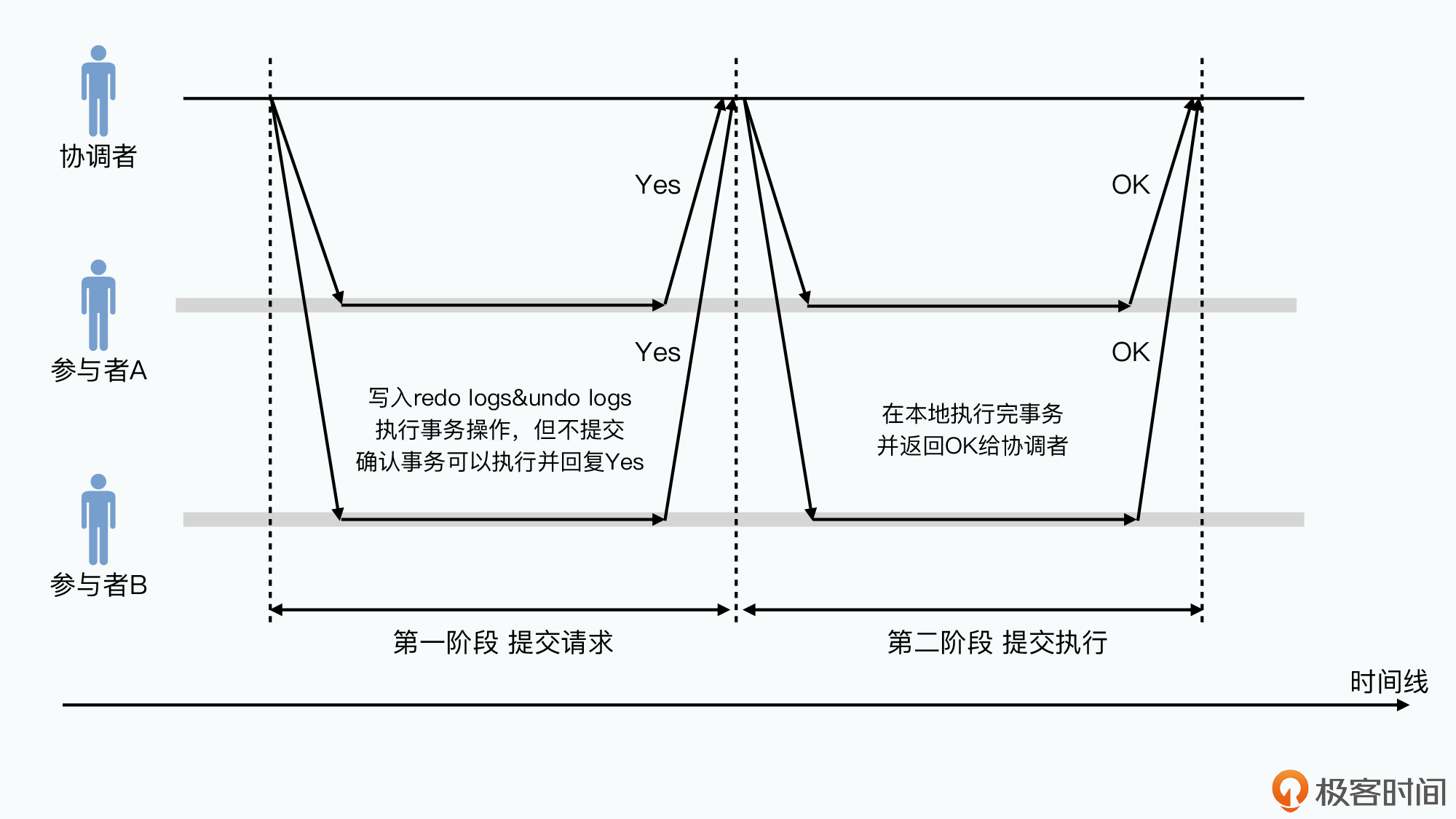
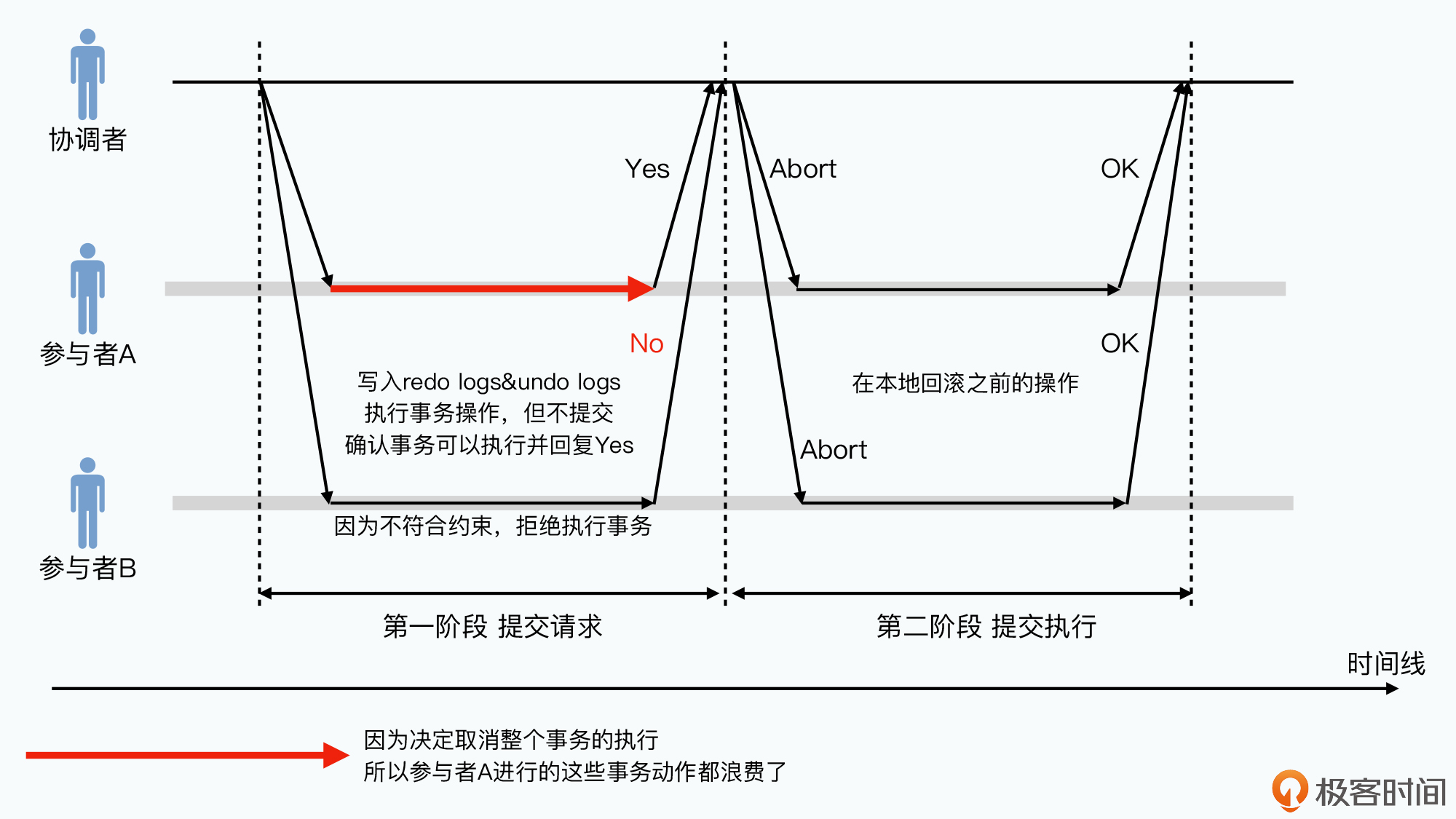
在2PC过程中如果出现硬件或网络故障:
- 参与者发生故障,其无法知道协调者到底想要继续还是回滚。这种情况下参与者在硬件腹胀解决后,会一直等待协调者 给下一步指令
- 协调者之前收到了参与者的答应执行事务响应,协调者会一直尝试重新联系参与者。若一直没响应,协调者在等一段时间后会放弃整个事务,事务回滚。
这意味着硬件故障时,可能有一个参与者已完成事务,但零个可能很长时间后硬件和网络恢复后才完成。若二者是 Master 和 Backup Master,这段时间内二者间数据不一致。此时协调者作为对外沟通的窗口,可以阻塞或拒绝服务
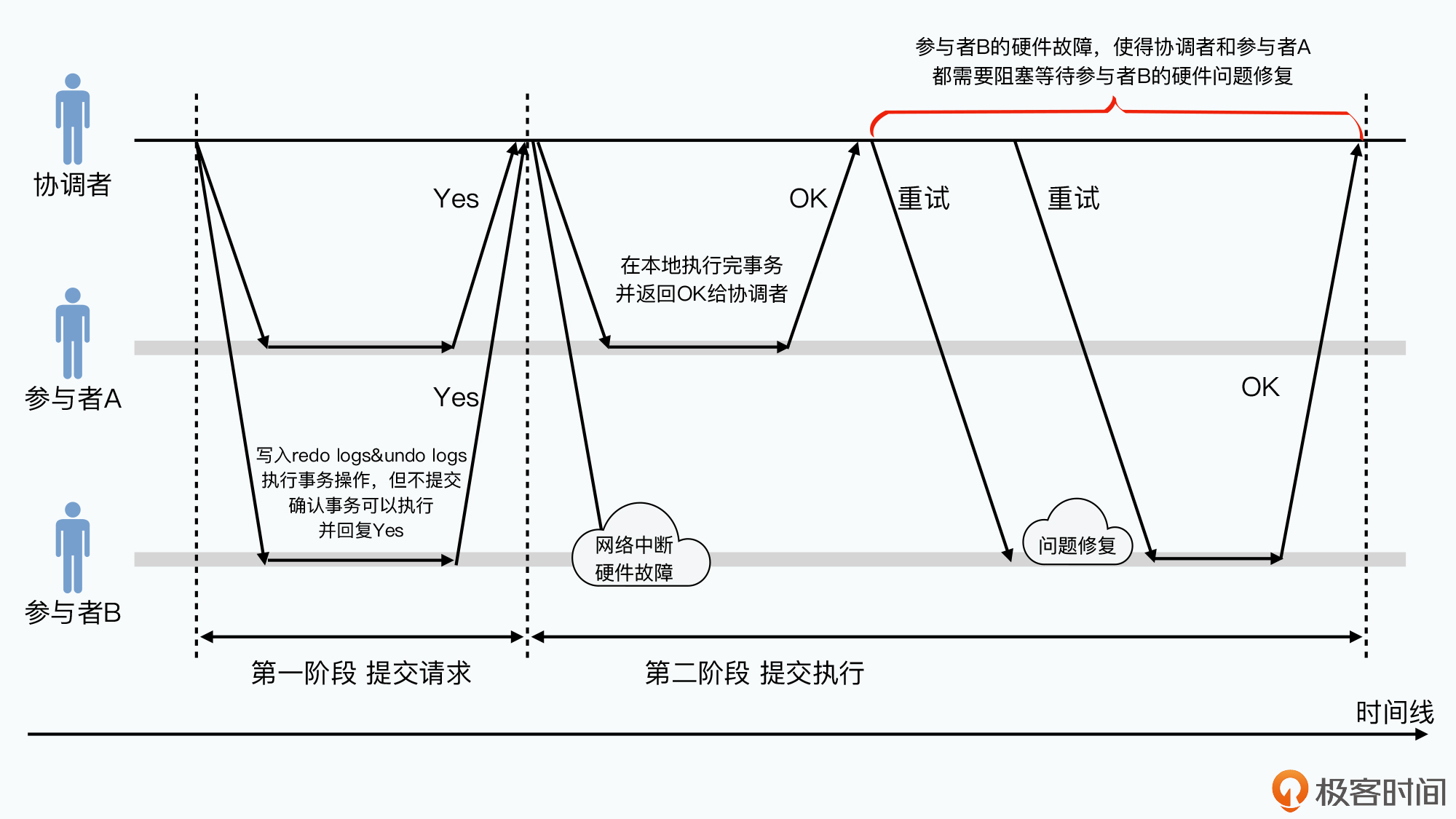
这实现了CAP种的CP
三阶段提交
将提交请求阶段拆分为两步。
- CanCommit请求,协调者询问参与者能否执行,但不写日志
- PreCommit请求,当所有参与者返回成功时,再发送一个预提交请求,所有参与者写下 redo logs 和 undo logs
这两个请求阶段,参与者可以放弃事务,整个事务回滚。网络超时也会导致回滚。将提交拆分为两个动作,缩短了参与者发生同时阻塞的时间。大部分不能执行的事务在CanCommit阶段就放弃,无需写日志和回滚。 - Commit阶段,相比之下,如果参与者等待协调者超时了,那么参与者不会一直等待,而是将已答应的事务提交
提升了可用性,出现网络延时阻塞情况下,整个事务仍能执行。
一个特殊情况下,3PC比2PC更糟糕:
- 所有参与者在CanCommit阶段答应执行事务
- 在PreCommit阶段,协调者发送PreCommit信息给所有参与者。参与者A挂了,没执行事务;参与者B与协调者间网络中断,等待一段时间后,参与者B决定执行事务
- 这时参与者B的状态与其他参与者不同,即所谓“脑裂”
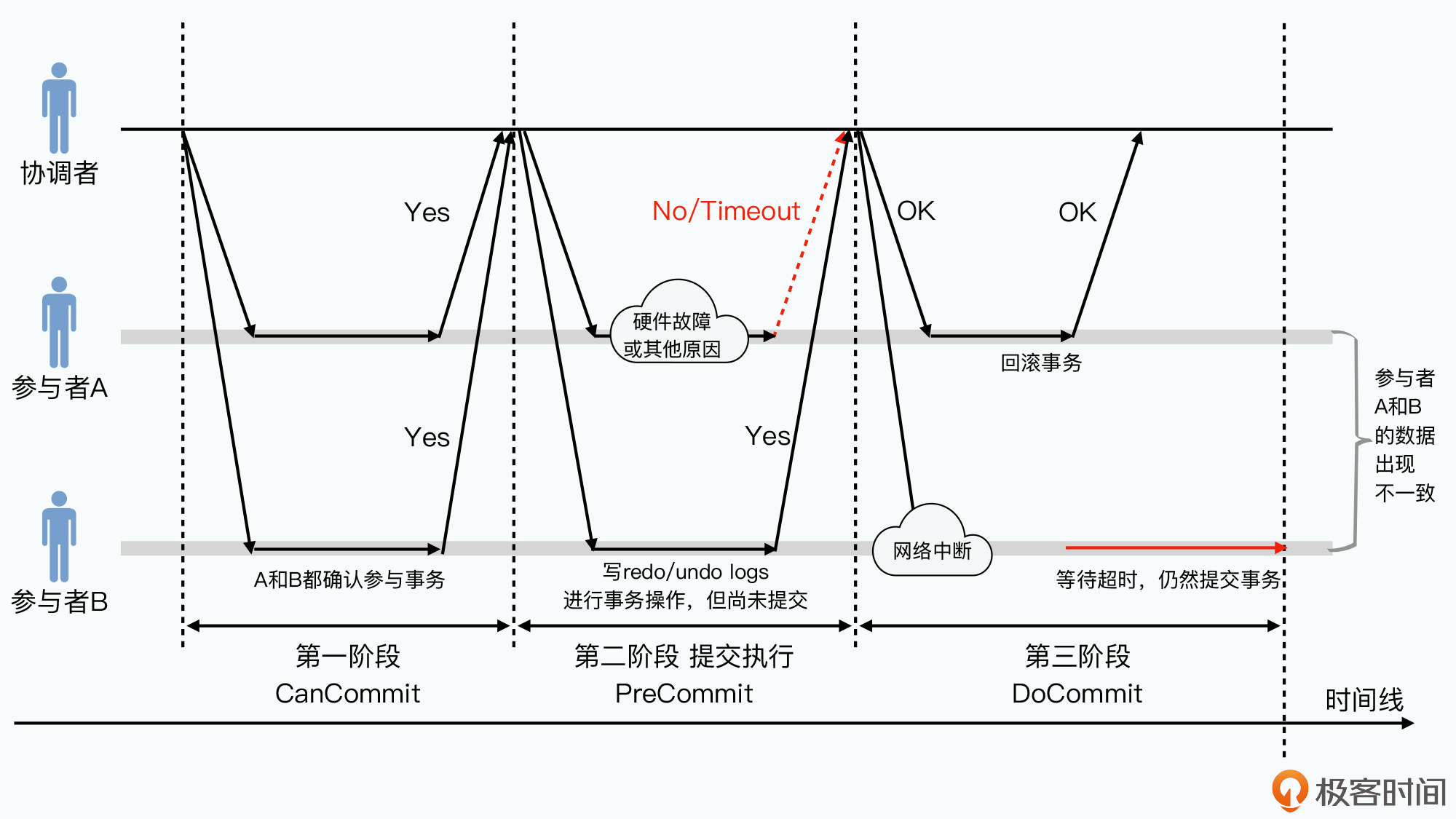
3PC在网络分区时仍尝试执行事务,为了减少网络分区下出现数据不一致,选择了拆分提交请求。
3PC实现了AP
2PC和3PC问题不在AC间的取舍,而是都充满了“单点故障”,特别是协调者。
数据库的隔离性
分布式事务存在“单点问题”,作为单点的协调者故障,系统无法运行。且同步阻塞对系统性能影响很大。
数据库的ACID特性分为一下4种:
- 未提交读 Read Uncommitted
事务间不隔离,事务执行过程中,读取的数据来自一个可能回滚的事务,可能读到脏数据 - 提交读 Read Committed
事务只读取已提交事务,但事务执行过程中其他事务更新数据,事务中多次读取一个数据会得到不同结果。
幻读:一个事务中两次读操作得到不同结果 - 可重复读 Repeatble Read
事务执行时只会读取开始前已提交的数据,执行期间提交的数据无法看见。有“一物两卖”的问题 - 串行化 Serializable
所有事务虽然提交时可以并行,但在外部看来是按确定顺序一个一个执行的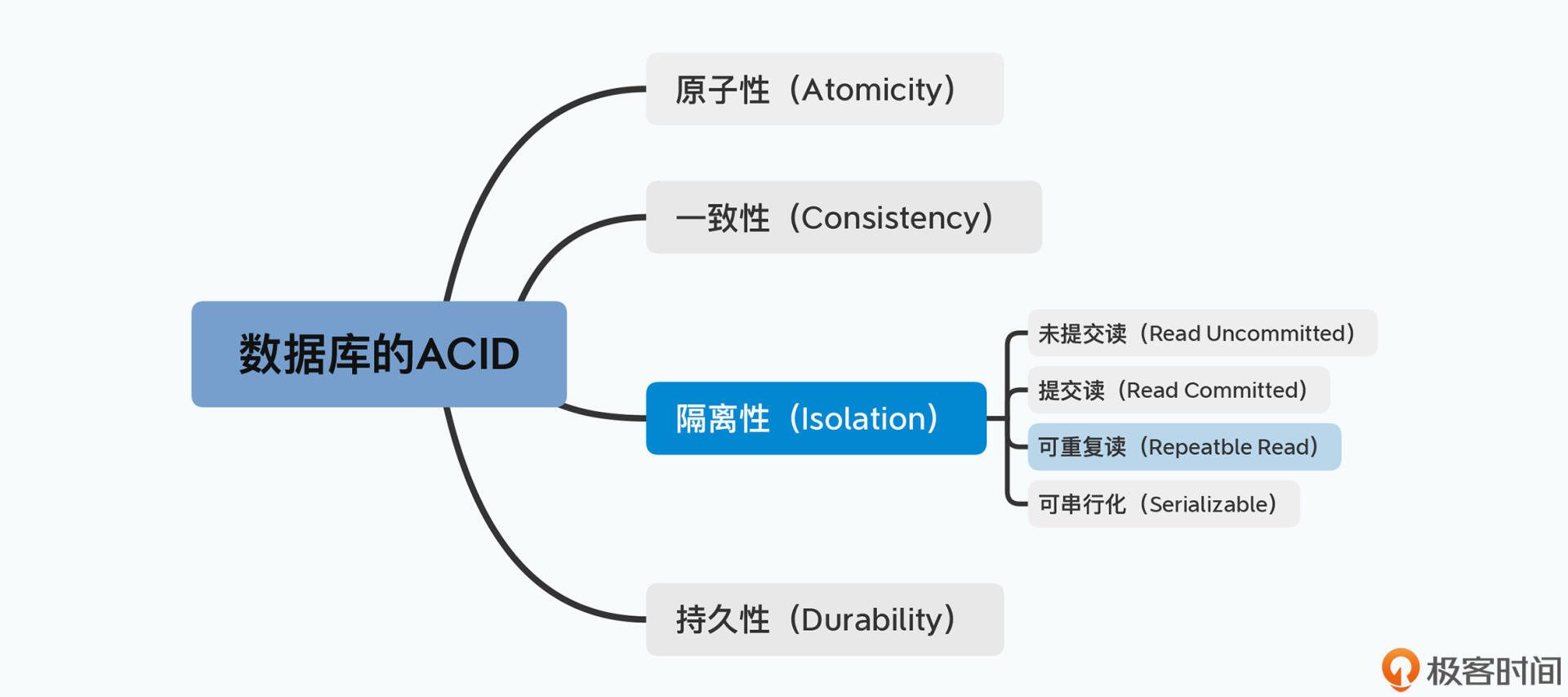
线性一致性
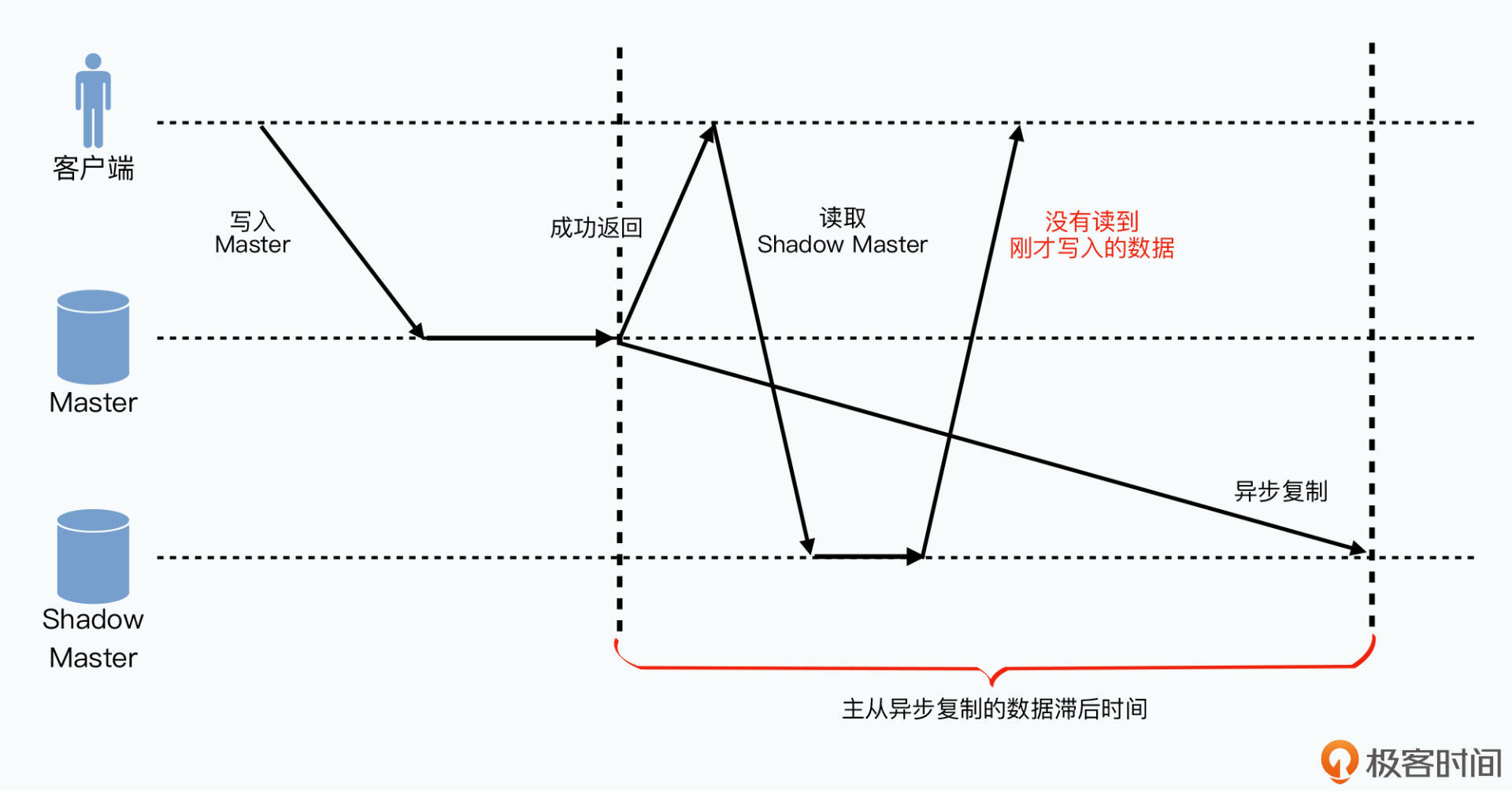
GFS中Master的主备同步无需使用2PC,因为其没有隔离性的要求。主备同步中写日志可看作一个个事件将状态的状态改变。主备同步靠可用就是在两个状态机间做同步复制,也就是状态机复制问题。这里解决的不是隔离性里的“可串行化”问题,而是分布式共识中“可线性化”问题:任何一个客户端写入数据后,之后一定能读取到刚写入的数据。
分布式系统中实现可线性化有一定难度,如Master和Shadow Master间的异步同步数据:
- client写数据到Master
- Master崩溃
- 刚才的数据没来及同步到Shadow Master
- 客户端从Shadow Master读数据,没读到
多协调者
通过提供多个协调者避免单点故障。但是可能造成操作顺序错乱。例如协调者A要删除参与者CD上的目录 /data/bigdata,协调者B要将目录改名。因为是分布式网络环境,可能造成再不同节点上执行事务的顺序不同。
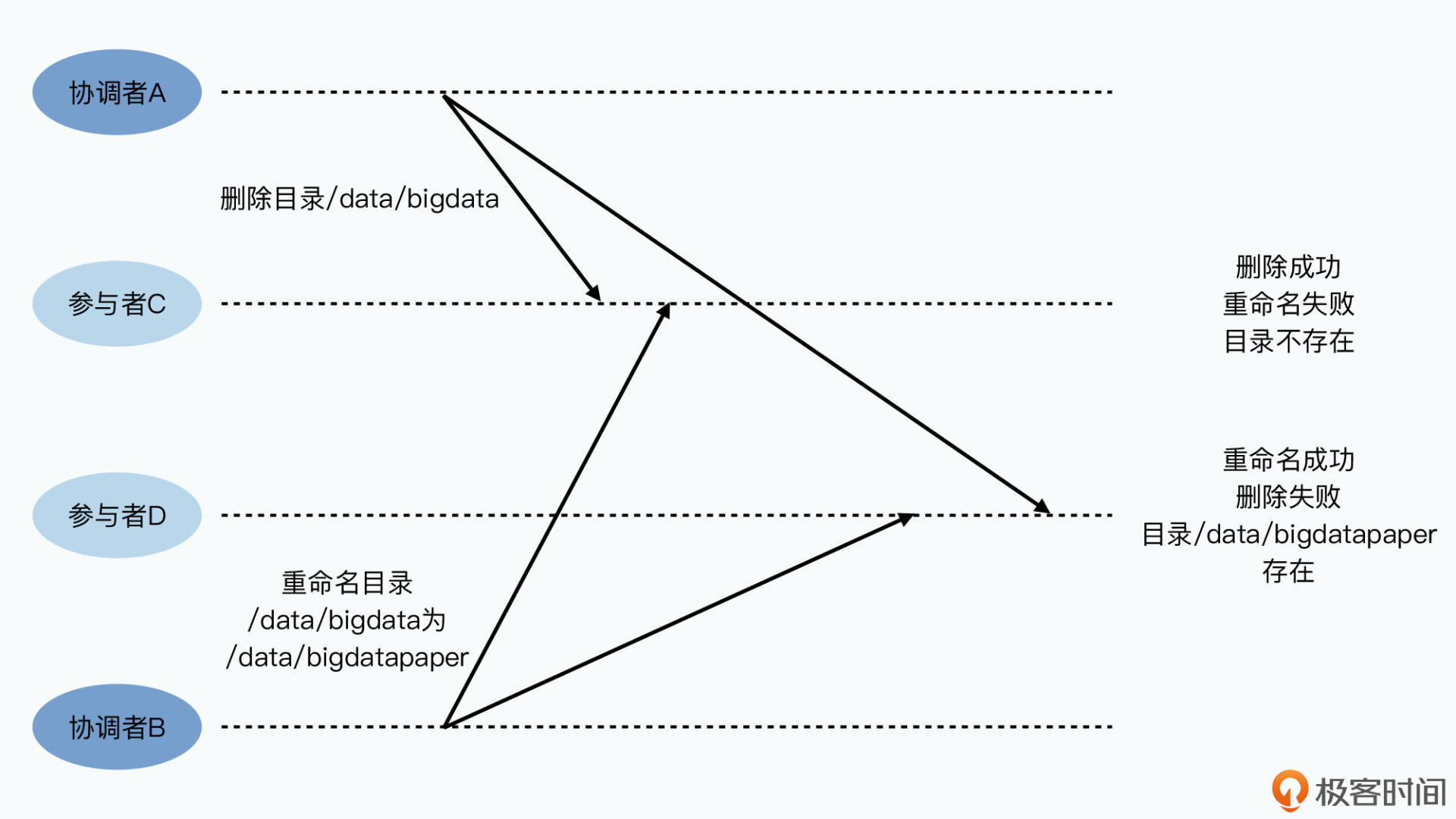
原因在于多个协调者间无法协调,达成在两个操作顺序上的共识
Paxos 算法
为了实现高可用,在写入数据时能够向一组服务器发请求而非一个。这组机器中每一台最终写入并执行日志的顺序一样。
- 提案(Proposal):每个要写入的操作
- 提案者(Proposer):接收外部请求并尝试写入数据的节点
- 异步协调:提案者接受请求后进行协调,获得多数通过的请求才会被选择
- 接受者(Acceptor)
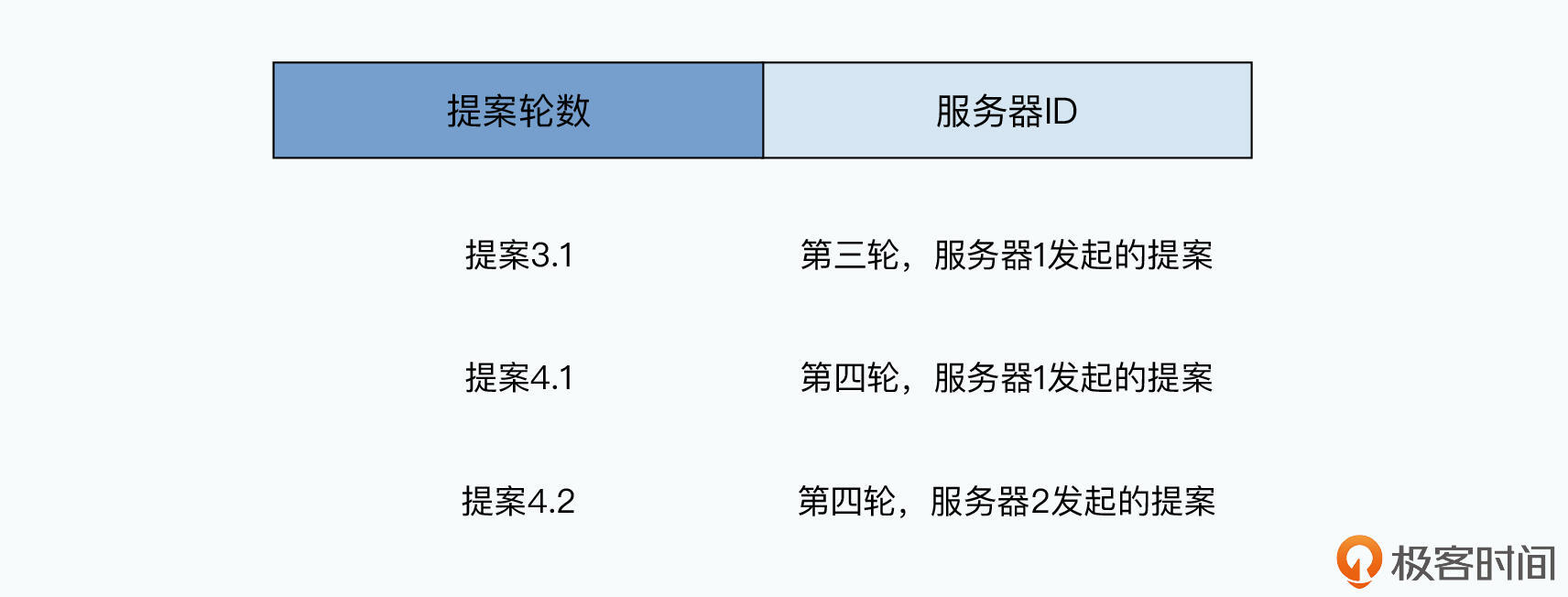
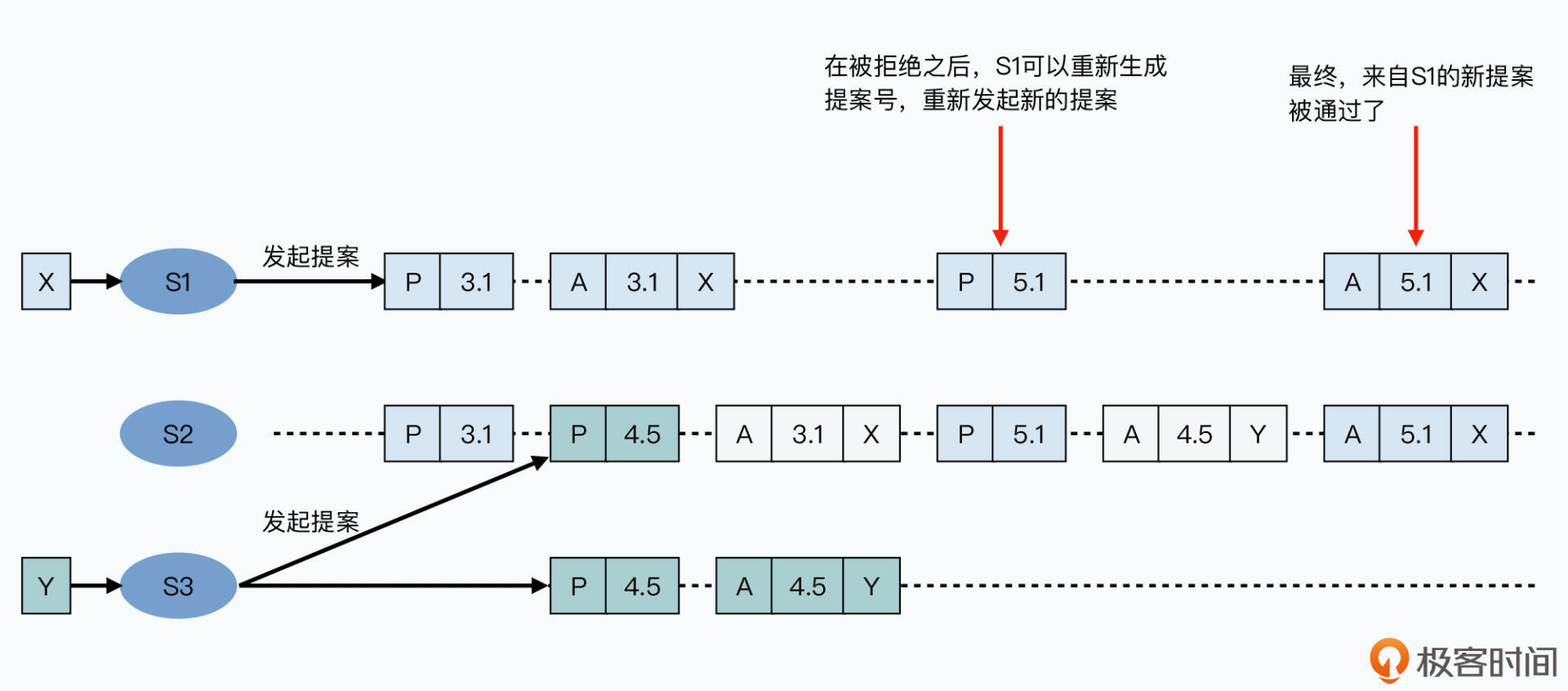
提案编号
每个提案都有一个编号,高位时提案过程中轮数(Round),低位时服务器编号。每个节点都记录自己看到或用过的最大轮数。
某节点要发起新提案,用它最大轮数加上1作为新提案轮数,并将自己的服务器编号拼接上去,作为提案号发出去。这个提案号必须存在磁盘上,避免宕机后不知道最新提案号是多少。
- 不存在相同提案号
- 提案号能排序,分出先后
Prepare 阶段
提案者接收请求后发起提案,提案包括提案号和请求内容。这个提案广播给所有接受者,被称为Prepare请求。所有Acceptor接收提案后返回一个响应,响应包含:
- 所有接受者一旦收到Prepare请求后就承诺之后的提案号永不比那个小
- 若接受者之前已接收其他提案,那么将其存储,并将Prepare请求的提案号和其他提案的内容返回;若没接收过,返回NULL
这里接受者没真正接受请求,本质是提案者查询所有接受者是否接受了别的提案
Accept 阶段
提案者收到过半响应后进入第二阶段,再发一个广播:
- Prepare请求中就有的提案号
- 提案的值,有两种情况
- 如果之前接受者已接受过值,这里的值就是所有接受者返回的值中提案号最大的那个,即遵循已做出的决策
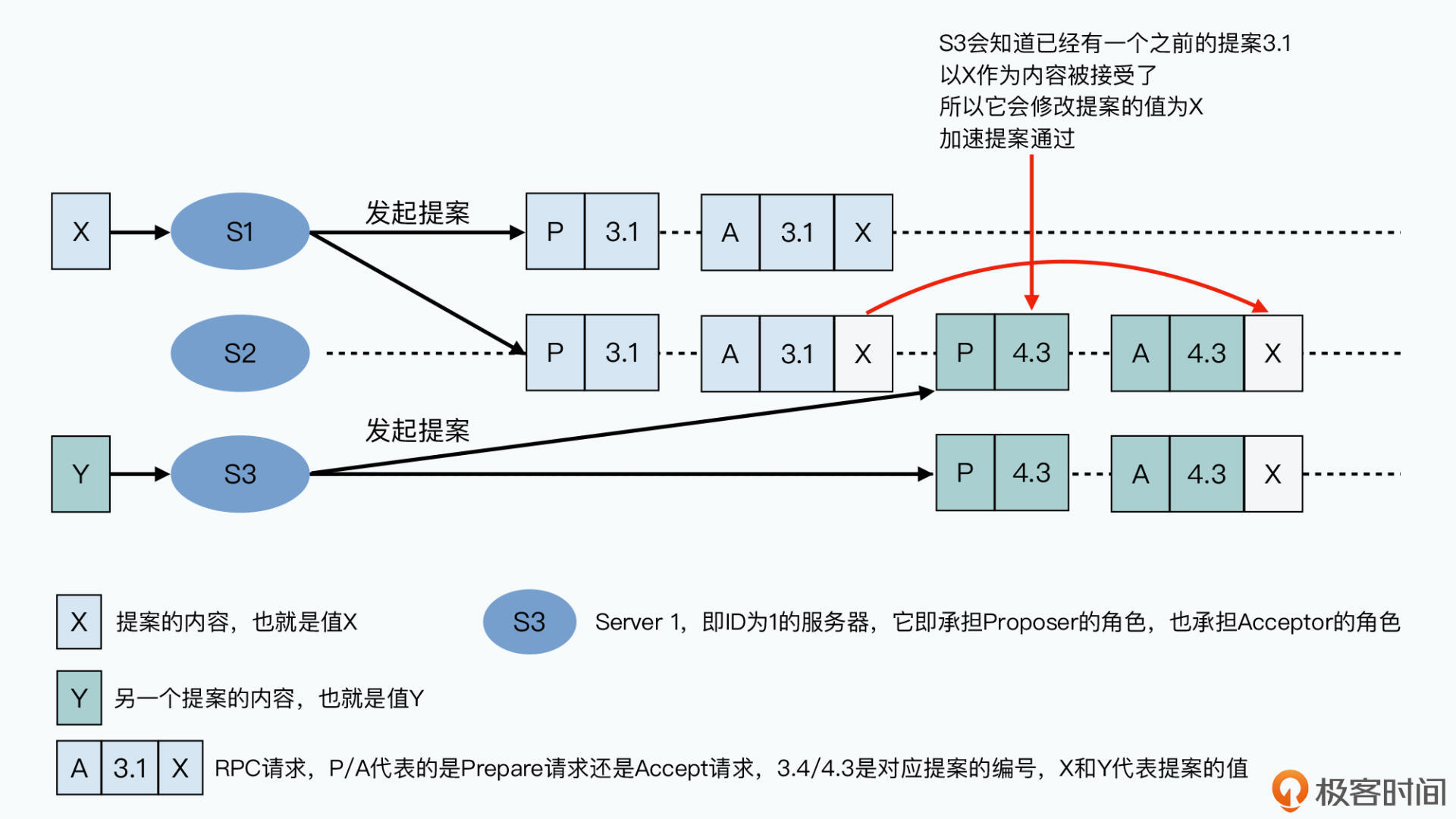
- 如果所有接受者返回的都是NULL,这个请求中提案者就放上自己的值。接受者可选择接受还是拒绝这个提案的值
- 若没有其他并发提案,接受这个值。一旦提案者收到过半接受者同意,那么这个提交值就被选定
- 若某个接受者刚才已答应某个新的提案者,则不接受更早时候的请求,会拒绝
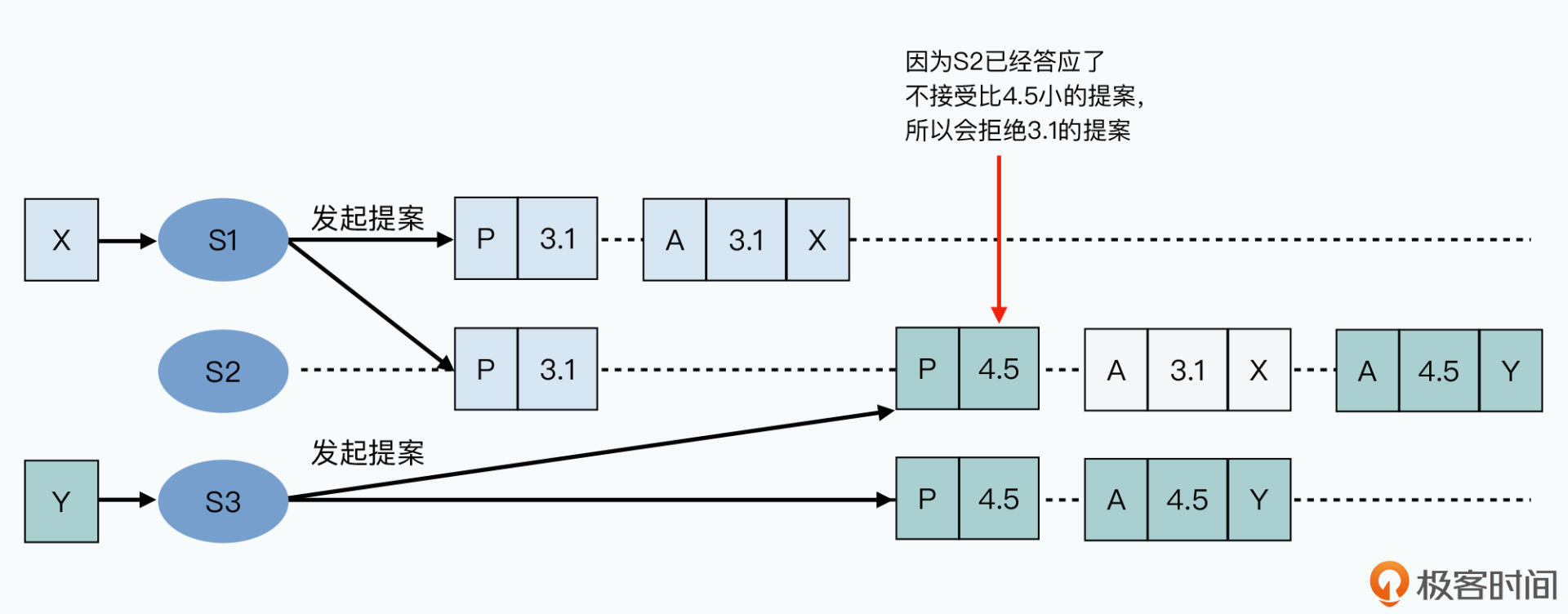
- 无论拒绝还是接受,接受者都返回最新的提案号
- 如果之前接受者已接受过值,这里的值就是所有接受者返回的值中提案号最大的那个,即遵循已做出的决策
提案者等至少一半接受者返回响应,有人拒绝则放弃当前提案重新再来:生成新提案号、发起Prepare、Accept请求。超过一般人接受时,提案通过。
下图为有接受者拒绝,重新生成提案号,重新发出请求
可线性化和共识算法
Paxos算法确保所有节点对当前接受哪一个提案达成大多数共识。通过Paoxs算法能确保所有服务器上写入日志的顺序是一样的,但是并不关心顺序。Paxos算法的问题是开销太大,无论是否达成共识都要两轮RPC调用,且所有的数据写入都要在所有接受者节点上写一遍。
原始Paxos算法性能不好,简单的写入一条日志,可能要解决多个Proposer间的竞争问题,可能有好几轮RPC调用。可以使用一次提交一组日志的方法进行优化。性能问题的根本原因在于,一个节点就需要承接所有数据请求。在可用性上不存在单点瓶颈,但在性能上存在。
通过 Chubby 转移可用性和“共识”问题
对于GFS和Bigtable这样的单Master系统,保障系统高可用采用:
- 同步复制
但是2PC也有单点故障 - 对Master监控,即使进行故障切换
如何判断是Master宕机还是网络问题?
Chubby的思路就是不在每个操作、每个日志写入时进行“共识”,而是确认哪一个是Master。
系统的可用性与容错机制被抽离了出来,数据同步只要通过2PC进行提交,单点故障则通过Paxos算法让一致性模块达成共识,确认哪个是Master。其他节点通过这个一致性模块获取哪个是最新Master。
Chubby系统中,它针对Paxos进行了封装,对外接口成了一个锁。Chubby变成了一个分布式锁而非一个Paxos一致性模块。哪一台机器持有锁,他就是Master。
Chubby是一个粗粒度锁,即外部客户端占用时间较长。如,Master只要不出故障就可以一直占有;但不会通过它做很大细粒度工作,如数据库的写入事务。
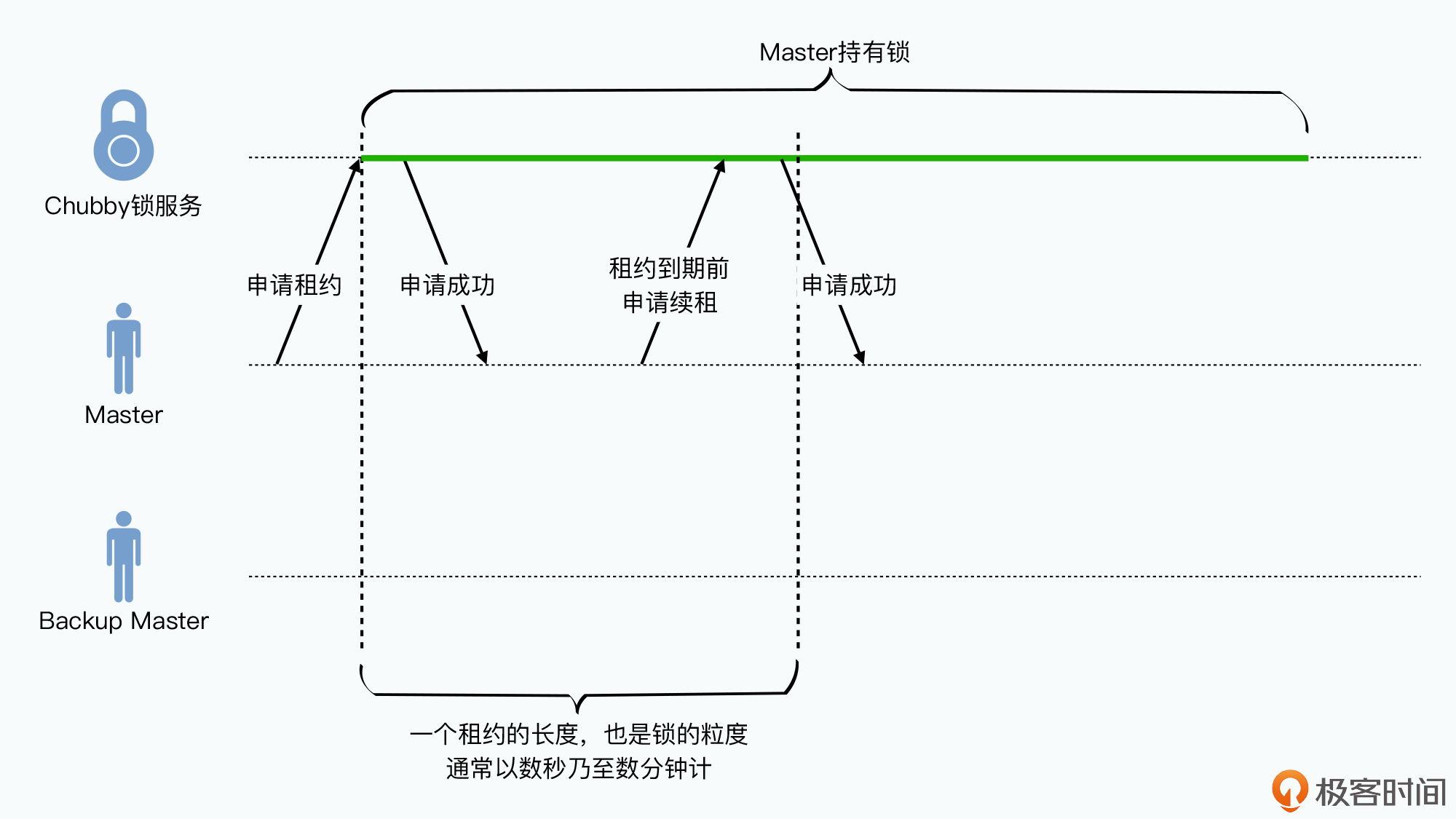
Master的切换频率很低,不然Paxos的性能也无法支持。在Bigtable中Chubby用于存储变化很少但丢失后会导致不一致的元数据:
- Master高可用切换
- 存储引导位置 Bootstrap Location
- Tablet 和 Tablet Server 间的分配关系
- Bigtable 里表的 Schema
Chubby并不是提供一个底层Paxos算法库,让GFS、Bigtable等基于Paxos实现数据库事务,而是将自己变为分布式锁,解决GFS、Bigtable的元数据一致性问题,以及容错场景下灾难恢复问题。
Chubby 系统架构
Chubby 通过“共识”算法确认一个Master节点,其作为系统中唯一的提案者,所有写入操作都会发到这个Master节点。只有一个提案者使得不会在两个Proposer间竞争提案,避免了多轮协商。如果Master当即,会通过共识算法再选一个;如果因为网络问题导致两个Master,也会通过共识算法确定一个Master。Master的生命周期被称为租期(lease),在到期前会进行续租,如果Master崩溃,在到期后会选举新的Master。
Paxos不需要一个单一的Master节点,但为了效率使用单一Master简化系统。Chubby可以看作3层系统:
- 底层是Paxos协议实现的同步日志复制的状态机复制系统
- 上一层是通过状态机实现的数据库。谷歌直接采用了BerkeleyDB,Chubby通过Paxos在多个BerkeleyDB李实现数据库的同步复制
- 最上层是锁服务
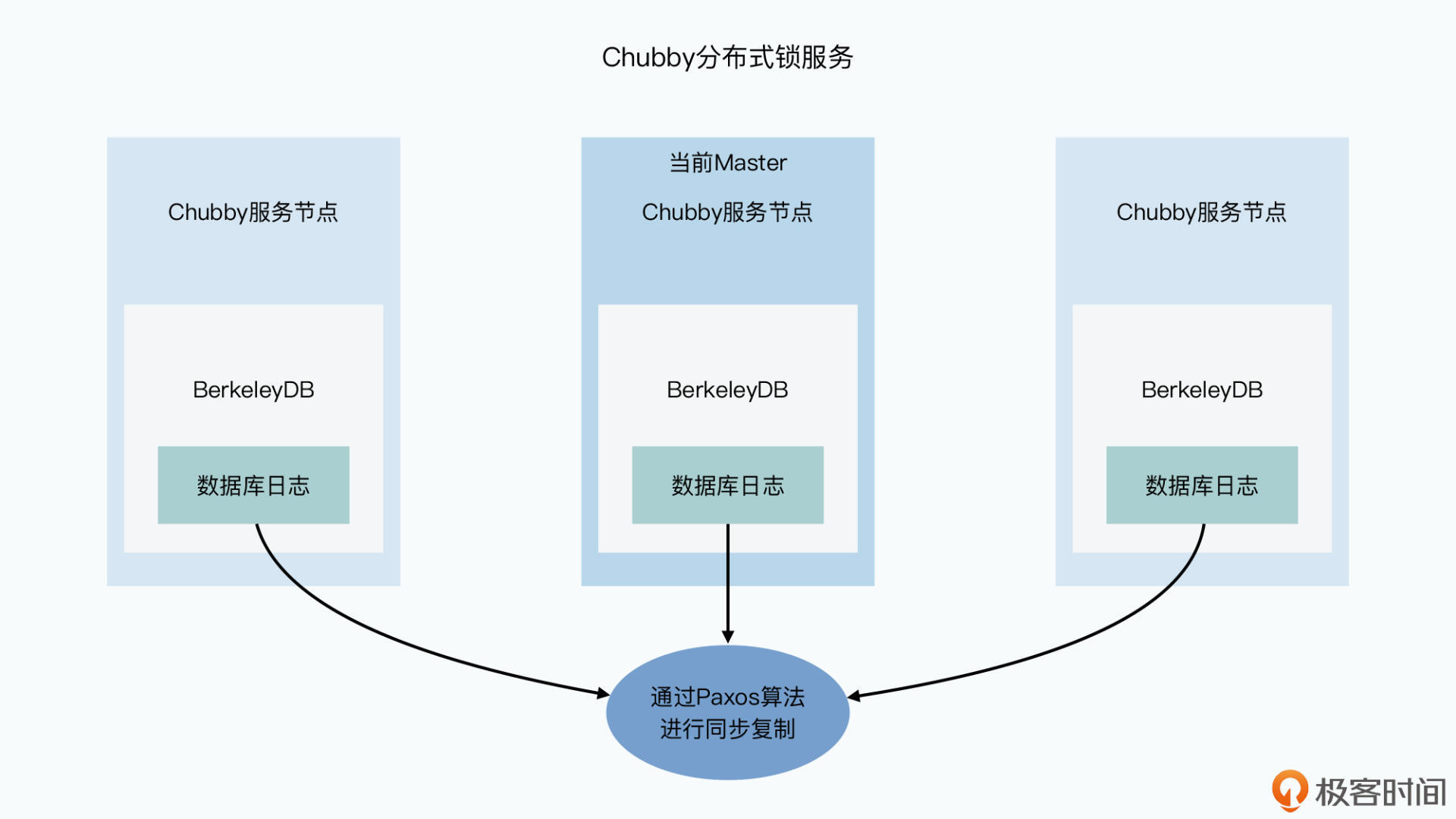
以上是服务器端,Chubby 还提供了客户端。客户端通过DNS获得所有服务端节点,访问任意一个节点得到Master位置,读写请求都访问Master。对于写请求,Master作为提案者,在所有Chubby节点上通过Paxos算法同步复制;对于读请求,Master直接返回本地请求,所有节点的数据都是有共识的。
Chubby 对外的接口
Chubby底层是BerkeleyDB这种KV数据库,对外接口类似Unix文件系统接口。每个目录或文件都称为节点(node),外部应用使用的锁就是锁在这个节点上。获得锁的客户端就可以向对应目录或文件中写数据。判断哪个是真正的Master,就看哪个获得了某个特定的文件锁。
定义 /gfs/master 这个命名空间,用于存放Master信息。这样Master通过RPC锁住这个文件,向里写下IP或其他元数据。其他客户端无法获得锁也无法修改Master。其它节点可以读它,查询到哪个是Master的客户端。Chubby 中节点分为永久和临时两类节点。
- 永久:客户端显示调用API才能删除,如Bigtable中Chubby存放的引导位置信息
- 临时:一旦和客户端的session断开,就自动消失,Bigtable中 Tablet Server 的注册
为了减少Chubby的负载,防止客户端不断轮询获取各个目录和文件的变更。Chubby实现了事件通知机制。是设计模式中典型的观察者模式。客户端注册对哪些事件感兴趣,如特定目录和文件的变更删除,一旦事件发生,Chubby就推送相应事件信息给这些客户端。

Chubby 作为分布式锁的挑战
客户端获取的锁是有时效的,为了避免拿到锁的客户端因故障或延迟导致下线。例如:
- 客户端A获取了Chubby的锁
- 一段时间后A仍有锁,向Bigtable写入请求。存在网络拥堵,用了很长时间才到
- 写请求还没到达,A的租约到期,另一个客户端B获得对应的锁,然后B向其中写入数据
- X的请求到达节点,但Bigtable不知道谁拥有锁,认为已经通过应用层面实现了对资源的保护。A的写入请求会覆盖B的。
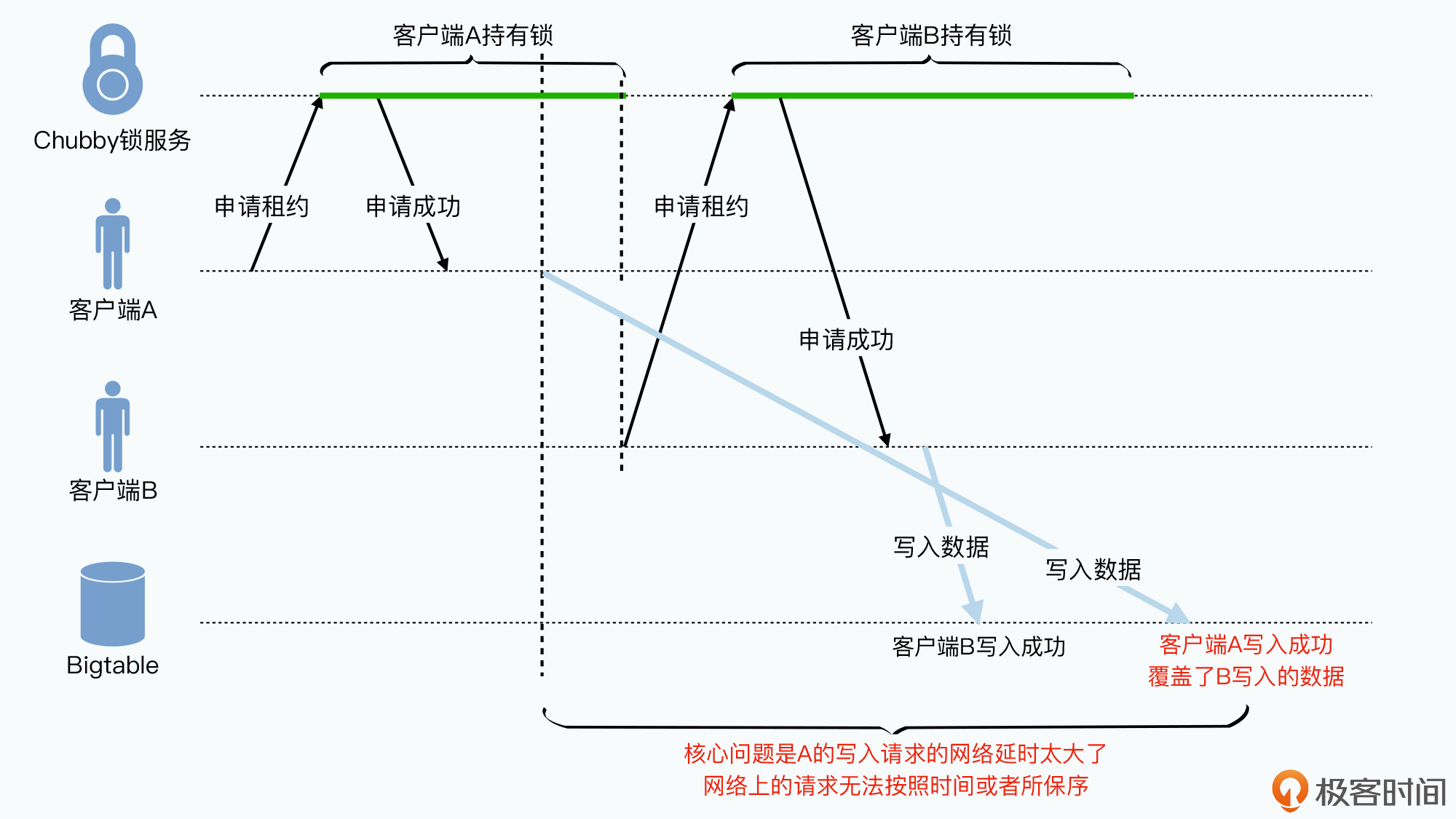
解决方案:
- 锁延迟(lock-delay)
客户端的租期到期后,如果不是客户端主动释放,Chubby让客户端再持有一段时间再释放。
客户端主动释放会明确告诉Chubby不会再向其中写数据,没有主动释放则可能有请求在网络上。
等一段时间还没有请求来,则Chubby释放锁 - 锁序列器(lock-sequencer)
本质是乐观锁。客户端获取Chubby锁时拿到对应的锁序号,发送请求时要带上这个序号,当Chubby将锁给别的客户端时锁序号会增大,对应的业务服务,如Bigtable,也会记录每次请求的锁序列号,通过序列号确定是否有之前的尝试覆盖新数据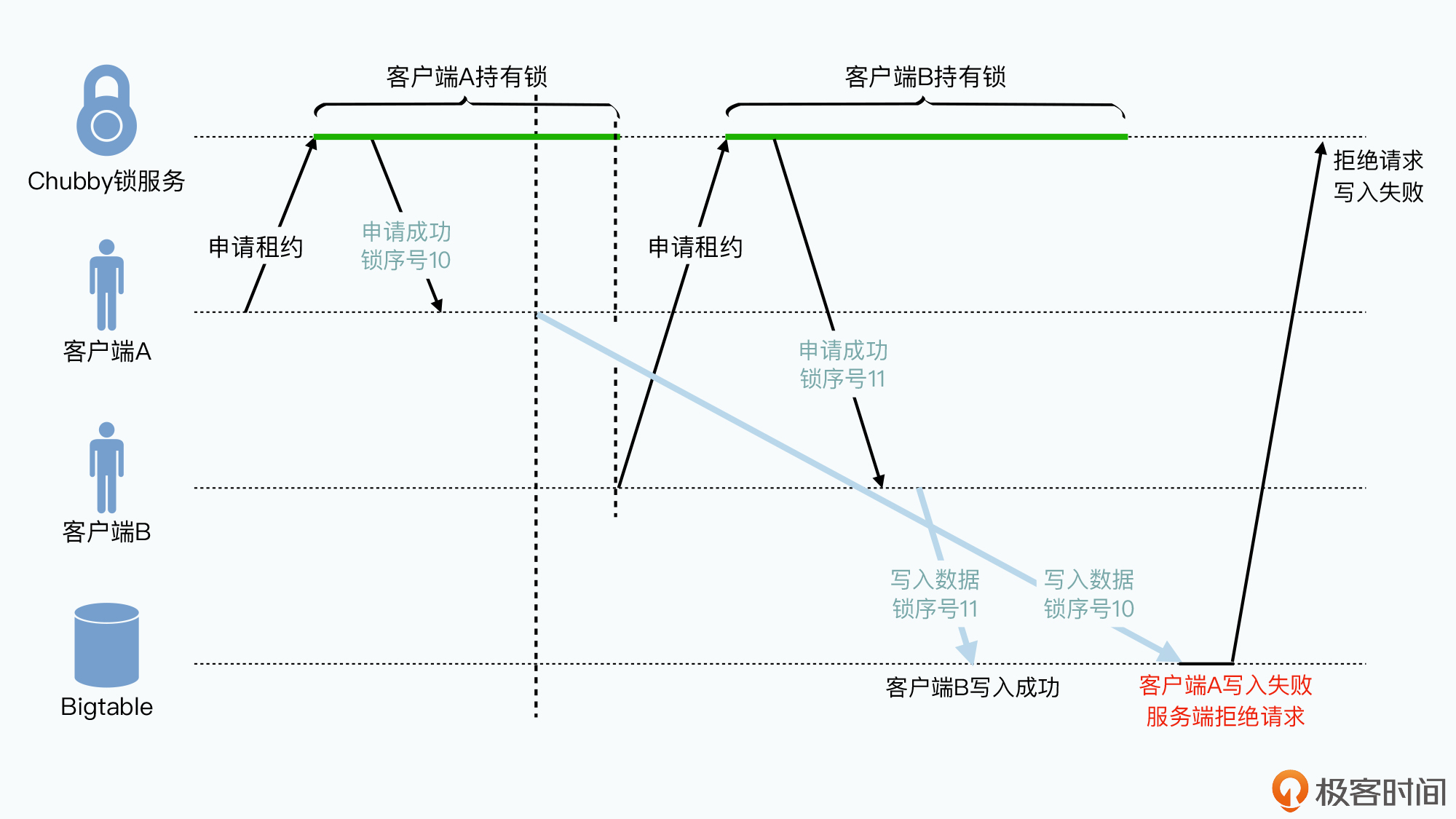
Chubby 每个锁,除了文件、目录本身,及ACL权限这种元数据外,还有4个编号:
- 实例编号(instance number):当“节点”创建时自增
- 文件内容编号(content generation number):当文件内容被写入时自增
- 锁编号(lock generation number):当锁从 Free 转为 Held 时自增
- ACL编号(ACL generation number):当这个节点的权限ACL信息更新时自增