发表时间:2020(ICLR2020)
文章要点:这篇文章提出了一个无监督的model-based的学习算法Dynamics-Aware Discovery of Skills (DADS),可以同时发现可预测的行为以及学习他们的dynamics。然后对于新任务,可以直接用zero-shot planning的方法选择最优动作。这个文章的点就是学习skill的方式是无监督的,通过基于互信息的探索策略,来发现skill。
具体的,定义skill空间,表示为\(z\)。然后定义一个基于skill的状态转移函数\(q(s^\prime|s,z)\)。再定义一个将skill转化成具体动作的policy \(\pi(a|s,z)\)。有了这个之后,定义关于skill的互信息

训练的目标就是最大化这个互信息。也就是最大化\(s\)和\(s^\prime\)的熵,并且最小化给定skill \(z\)之后的熵。这个目标函数的思路就是让一个skill的状态转移差异尽可能大,同时在给定skill \(z\)之后,让这个\(s^\prime\)更加确定,也就是能预测(predictable)。
这个目标函数可以写成
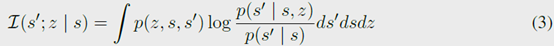
其中\(p\)是真正的状态转移函数,利用变分推断引入前面定义的\(q\)

所以目标就转变成了最大化右边的期望值。然后将训练过程的reward直接设置为
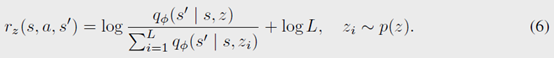
这个分母是对\(p\)的近似

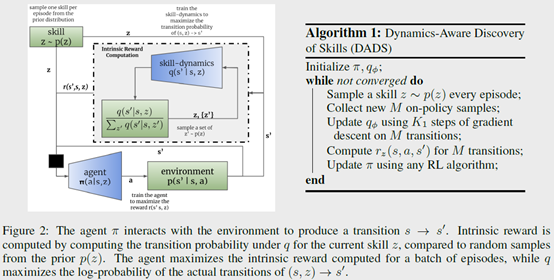
然后整个流程如前图所示,先设定一个\(z\)的先验分布,比如均匀分布。每次先采样一个\(z\),然后用policy \(\pi(a|s,z)\)转换成动作序列到环境里执行得到\(s^\prime\)。根据这个状态转移更新dynamics函数\(q\),然后根据式子(6)计算reward,接着就用强化训练policy \(\pi\)。这个过程就是skill发现的过程,以及学习对应的dynamics以及skill对应action的policy。
有了这个之后,就可以直接用online planning的方式来解具体的任务了,文章里面用的model predictive control,具体流程如下图
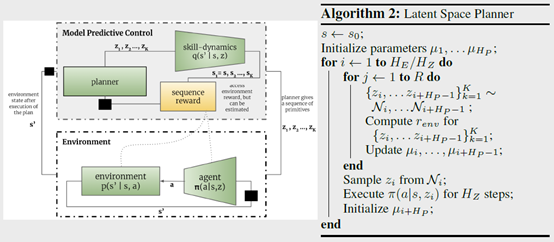
思路就是采样多个\(z\),用\(q\)去做planning得到reward最大的那个\(z\),然后用\(\pi\)把\(z\)转换成动作序列\(a\)去环境里执行,然后重复这个过程。
总结:这个方法就有点像分层强化,先学习skill,并且学习skill到action序列的对应关系。然后就用planning的方法在skill层面进行online planning,最后再转换成具体的action去执行。整个过程是make sense的,具体效果可能还是要看具体任务以及调参了。
疑问:看起来还是挺有道理的,但是这个利用互信息去自己探索skill的方式,到底能不能收敛,还是有点疑问的。
DYNAMICS-AWARE UNSUPERVISED DISCOVERY OF SKILLS
发布时间 2023-05-09 22:48:23作者: initial_h