背景
GPT1采用了pre-train + fine-tuning训练方式,也就是说为了适应不同的训练任务,模型还是需要在特定任务的数据集上微调,仍然存在较多人工干预的成本。GPT-2 想彻底解决这个问题,通过 zero-shot,在迁移到其他任务上的时候不需要额外的标注数据,也不需要额外的模型训练。
训练数据改造
在 GPT-1 中,下游任务需要对不同任务的输入序列进行改造,在序列中加入了开始符、分隔符和结束符之类的特殊标识符,但是在 zero-shot 前提下,我们无法根据不同的下游任务去添加这些标识符,因为不进行额外的微调训练,模型在预测的时候根本不认识这些特殊标记。所以在 zero-shot 的设定下,不同任务的输入序列应该与训练时见到的文本长得一样,也就是以自然语言的形式去作为输入,例如下面两个任务的输入序列是这样改造的:
机器翻译任务:translate to french, { english text }, { french text }
阅读理解任务:answer the question, { document }, { question }, { answer }
模型结构
在模型结构方面,整个 GPT-2 的模型框架与 GPT-1 相同,只是做了几个地方的调整,这些调整更多的是被当作训练时的 trick,而不作为 GPT-2 的创新,具体为以下几点:
1. 后置层归一化( post-norm )改为前置层归一化( pre-norm );
2. 在模型最后一个自注意力层之后,额外增加一个层归一化;
3. 调整参数的初始化方式,按残差层个数进行缩放,缩放比例为 1 : � ;
4. 输入序列的最大长度从 512 扩充到 1024;
post-norm 和 pre-norm差别
两者的主要区别在于,post-norm 将 transformer 中每一个 block 的层归一化放在了残差层之后,而 pre-norm 将层归一化放在了每个 block 的输入位置,如下图所示:
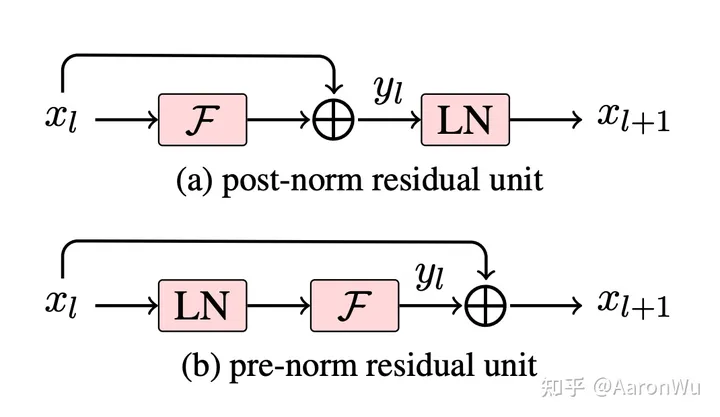
GPT-2 进行上述模型调整的主要原因在于,随着模型层数不断增加,梯度消失和梯度爆炸的风险越来越大,这些调整能够减少预训练过程中各层之间的方差变化,使梯度更加稳定。(参考https://zhuanlan.zhihu.com/p/640784855)
最终 GPT-2 提供了四种规模的模型:

参考资料
https://zhuanlan.zhihu.com/p/609716668
- Unsupervised Multitask Language Learners Modelsunsupervised multitask language learners few-shot language learners models language few-shot learners models foundation efficient language models udalm unsupervised adaptation language reasoning language towards models language controlling guidance models zero-shot reasoners language models evaluation holistic language models language programming prompting models