背景
GPT-3 虽然在各大 NLP 任务以及文本生成的能力上令人惊艳,但是他仍然还是会生成一些带有偏见的,不真实的,有害的造成负面社会影响的信息,而且很多时候,他并不按人类喜欢的表达方式去说话。在这个背景下,OpenAI 提出了一个概念“Alignment”,意思是模型输出与人类真实意图对齐,符合人类偏好。因此,为了让模型输出与用户意图更加 “align”,就有了 InstructGPT 这个工作
技术方案
有监督微调(SFT) + 强化学习训练(RLHF)
SFT(Supervised Fine-Tuning)

RLHF(Reinforcement Learning from Human Feedback)
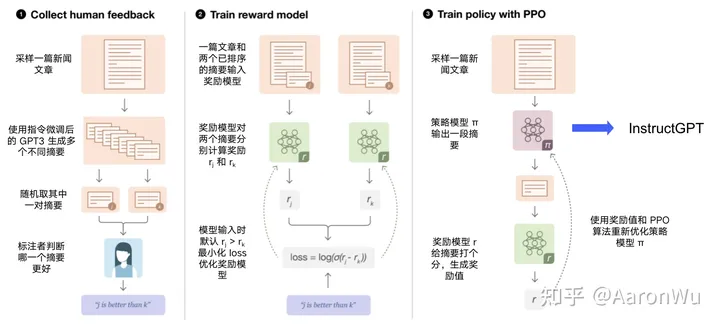
主要分为三步:
1. 收集人类反馈:使用初始化模型对一个样本生成多个不同摘要,人工对多个摘要按效果进行排序,得到一批排好序的摘要样本;
2. 训练奖励模型:使用第1步得到的样本集,训练一个模型,该模型输入为一篇文章和对应的一个摘要,模型输出为该摘要的得分;
3. 训练策略模型:使用初始化的策略模型生成一篇文章的摘要,然后使用奖励模型对该摘要打分,再使用打分值借助 PPO 算法重新优化策略模型;
reward model
奖励模型的架构和GPT-3相同,只不过把最后一层换成投影层输出score,损失函数如下,和learning2rank的思路相似:

其中w排在l前面,其实就是最大化正序对score的差值
- InstructGPT instructions Training language feedbackinstructgpt instructions training language instructions training language feedback instruction instructgpt tkinstruct prompt probabilistic algorithm language training vision-language pre-training embodiedgpt embodied language-image pre-training grounded language 模态language-image pre-training referring instructgpt feedback instructgpt chatgpt