GPT-3 和 GPT-2差别
1. 效果上,超出 GPT-2 非常多,能生成人类难以区分的新闻文章;
2. 主推 few-shot,相比于 GPT-2 的 zero-shot,具有很强的创新性;
3. 模型结构略微变化,采用 sparse attention 模块;
4. 海量训练语料 45TB(清洗后 570GB),相比于 GPT-2 的 40GB;
5. 海量模型参数,最大模型为 1750 亿,GPT-2 最大为 15 亿参数;
sparse attention
sparse attention 与传统 self-attention(称为 dense attention) 的区别在于:
dense attention:每个 token 之间两两计算 attention,复杂度 O(n²)
sparse attention:每个 token 只与其他 token 的一个子集计算 attention,复杂度 O(n*logn)
具体来说,sparse attention 除了相对距离不超过 k 以及相对距离为 k,2k,3k,... 的 token,其他所有 token 的注意力都设为 0,如下图所示:
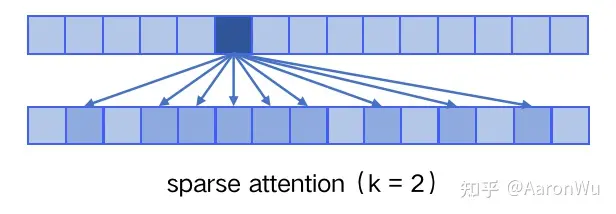
使用 sparse attention 的好处主要有以下两点:
1. 减少注意力层的计算复杂度,节约显存和耗时,从而能够处理更长的输入序列;
2. 具有“局部紧密相关和远程稀疏相关”的特性,对于距离较近的上下文关注更多,对于距离较远的上下文关注较少;
few-shot 相比于 zero-shot 为什么更有效?
在few-shot给的几个样例在新任务时会作为条件输入,相当于模型拥有了该任务更多的先验知识
参考资料
https://zhuanlan.zhihu.com/p/609716668
- Few-Shot Language Learners Models Shotfew-shot language learners models language few-shot learners models zero-shot reasoners language models few-shot difference generation similarity few-shot prototypical revisiting few-shot learning shot zero-shot few-shot one-shot unsupervised multitask language learners font generation few-shot cf-font 样本few-shot思维chatgpt