Deep Isolation Forest for Anomaly Detection
1 INTRODUCTION
IForest的缺点
-
它的与坐标轴平行的隔离方法会导致它在高维/非线性空间中难以检测到异常。
如图1所示。红色为异常节点,蓝色为正常节点。红色被蓝色所包围,这种情况无法被直接用 平行于x 或者 平行于y 的分割方法隔离。虽然这些异常最终可能被多次切割隔离,但与正常数据相比,它导致iTrees的隔离深度无法区分。这些异常的识别失败会导致较高的假阴性。
图1中其余的图为我们的方法构建的投影空间。现有方法中使用的线性划分(垂直/水平或倾斜形式)不能有效地在原始数据空间中隔离这些异常。相比之下,这些异常有可能在新创建的空间中暴露出来。
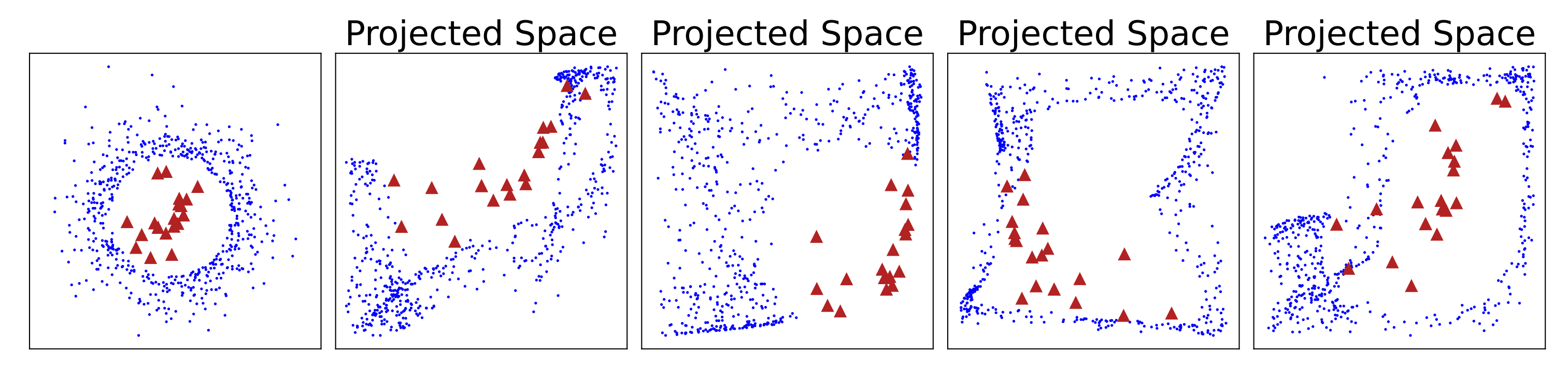
图1.困难异常挑战说明 -
具有较高的假阴性。它对算法本身引入的区域赋予的异常分数过低。
如图2所示,最左边的三个图是三个合成数据集。分数图表示异常分数在整个数据空间中的分布(颜色越深表示异常越高)。每个分数图中的黑色等高线为99百分位线,可以看作是每个异常检测器预测的数据正态性的边界。红色三角形代表可能的异常。
在IForest及其两个扩展的分数图中有一些人为区域,被分配了较低的异常分数。
以IForest为例:第一幅图中,数据集出现位置的上下左右四个区域;第二幅图中左上和右下区域;第三幅图中正弦曲线所在区域
这些区域中的异常可能无法被识别,因为这些异常被分配了与呈现的正常样本相似的低异常分数(它们包含在预测的正常区域中)。因此这个问题会导致假阴性错误。
相比之下,DIF生成的分数图更加准确和平滑,并且与原始数据样本相比,DIF可以成功地为异常分配高异常程度。

图2.算法偏差问题的说明 异常分数异常低是由于IForest固有的算法偏差,即在iTree构建中只允许轴平行分区
IForest引入了许多扩展,如PID、EIF,但是其隔离方法仍然受到线性划分的限制。
贡献点
-
我们引入了一种新的表征提取方案DIF,其关键思想是利用神经网络强大的表示能力将原始数据映射到一组新的数据空间中。在这些新创建的数据空间上执行简单的轴平行分区可以很容易地实现非线性隔离(相当于在原始数据空间中不同大小的子空间上进行非线性分区)。
-
提出了一种新的由无优化深度神经网络产生的随机表征集成方案。这些网络只是随意初始化,不涉及任何优化或训练过程。然后,DIF简单地利用这些表征进行随机轴平行切割。随机表征和基于随机分区的隔离之间独特的协同作用,为整个基于集合的异常估计过程带来了良好的随机性和期望的多样性。
-
此外,在DIF的具体实现中,我们提出了计算效率表征集成方法(Computation-Efficient Representation Ensemble method, CERE)和偏差增强异常评分函数(Deviation-Enhanced Anomaly Scoring function, DEAS)。
CERE可以减少计算开销,保证了良好的可扩展性;DEAS则利用了表征中包含的隐藏定量信息以及定性比较,这些额外的信息可以更准确地评估数据对象的隔离难度,从而产生更好的异常评分功能。
-
DIF提供了一种与数据类型无关的异常检测解决方案。对于不同类型的异常检测,只需要在提取表征的过程中,使用相应的神经网络即可。我们证明了DIF在检测不同类型数据中的异常方面是通用的。
3 PROBLEM STATEMENT AND NOTATIONS
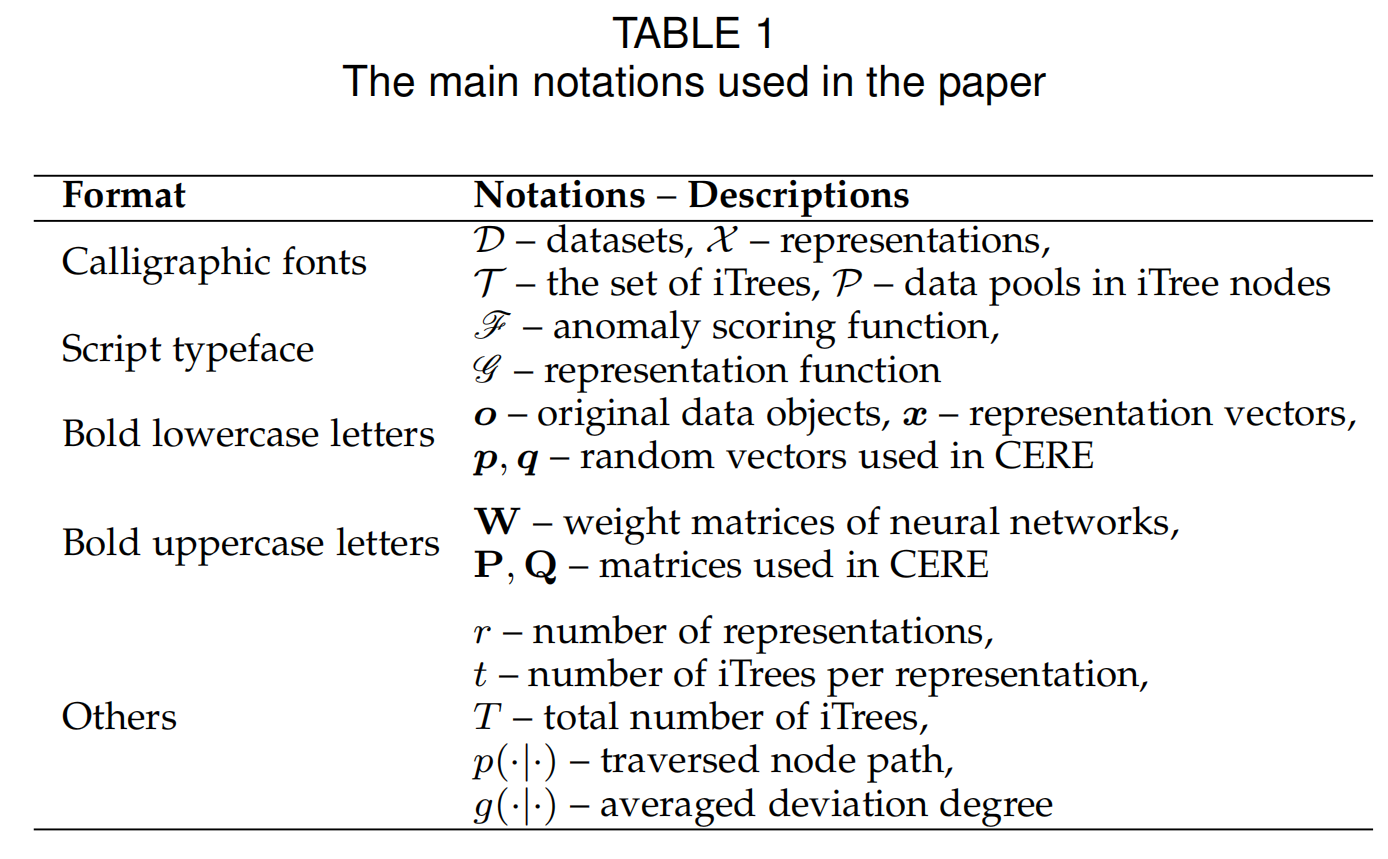
设 \(\mathcal{D}=\{o_1,\cdots,o_N\}\) 是一个有 \(N\) 个数据对象的数据集,异常检测就是给出一个评分函数 \(f:\mathcal{D}\mapsto\mathbb{R}^N\) 对每个数据对象的异常情况进行估计。与许多现有研究只关注单个数据类型不同,我们在这项工作中没有限制数据对象的类型,这意味着它们可以是多维向量、时间序列数据或图形。在整个论文中,我们使用书法字体(calligraphic fonts)表示集合,使用脚本字体( script typeface)表示函数,使用小写粗体字母(bold lowercase letters)表示向量,使用大写粗体字母(bold uppercase letters)表示矩阵。表1总结了主要的符号。
4 PRELIMINARIES: ISOLATION FOREST
\(p(o|\tau)\)表示对象 \(o\) 在树 \(\tau\) 上的遍历路径,\(|p(o|\tau)|\) 表示路径的长度,可以当作是对象 \(o\) 的异常程度(异常通常更容易通过较短的路径长度被隔离)
iForest构建T棵iTrees \(\mathcal{T}=\{\tau_i\}_{i=1}^Y\)
对象 \(o\) 的异常分数通过它的平均遍历路径长度 \(\mathbb{E}_{\tau_i\in \mathcal{T}}(|p(o|\tau)|)\) 计算得到,即 \({\scr{F}}_{\text{iForest}}(o|\mathcal{T})=2^{-\mathbb{E}_{\tau_i\in\mathcal{T}}\frac{|p(o|\tau_i)|}{C(T)}}\),其中 \(C(T)\) 是一个标准化因子。
5 DEEP ISOLATION FOREST
DIF使用深度神经网络构建表征集合,并在新的数据空间上使用简单的轴平行隔离来构建itree。
没有使用包含独立训练的神经网络的深度集合框架,我们使用只需要简单随机初始化的无优化神经网络产生的随机表示的集成。这种新的表示方案使得原始数据空间的分区具有很高的自由度。新投影表示空间中的每个特征都是由多个原始特征之间的非线性相互作用得到,这意味着新空间的轴平行分割可以在原始空间中形成有效的非线性切割。
同时,随机表示和基于随机分区隔离之间独特的协同作用可以促进基于整体集合的异常估计。
5.1 Formulation of DIF
DIF首先通过无优化神经网络生成随机表征集合,定义为
其中 \(r\) 是集合大小,\(\phi_u:\mathcal{D}\mapsto \mathbb{R}^d\) 为将原始数据映射到新的 \(d\) 维空间的网络,\(\theta_u\) 中的网络权值是随机初始化的。
每个表征都需要构建 \(t\) 棵iTree,因此孤立森林 \(\mathcal{T}=\{\tau_i\}^T_{i=1}\) 需要构造 \(T=r \times t\) 棵iTrees
iTree \(\tau_i\) 由具有一组投影数据 \(\mathcal{P}_1\subset X\) 的根节点初始化。第 \(k\) 个节点拥有数据集合 \(\mathcal{P}_k\) ,将其分为两个不相交叶节点,即 \(P_{2k}= \{x|x^{(j_k)} \leq \eta_k,x \in \mathcal{P}_k \}\),\(P_{2k+1}= \{x|x^{(j_k)} >\eta_k,x \in \mathcal{P}_k \}\) 。其中 \(j_k\) 是在新创建的数据空间 \(\{1,\cdots,d\}\) 的所有维度中均匀随机选取,\(x^{(j_k)}\) 为投影数据对象的第 \(j_k\) 个维度,\(\eta_k\) 为 \(\{x^{(j_k)} | x \in \mathcal{P}_k \}\) 范围内随机取的分割值。
构造 \(\mathcal{T}\) 后,通过在森林 \(\mathcal{T}\) 的每个iTree中的隔离难度来评估数据对象 \(o\) 的异常情况。评分函数定义为
其中 \(I(o|\tau_i)\) 表示在iTree \(\tau_i\) 中的隔离难度的函数,\(\Omega\)表示积分函数
5.2 Implementation of DIF
DIF有两个主要组成部分,即随机表示集成函数 \(\scr G\) 和基于隔离的异常评分函数 \(\scr F\)。为了提高表示函数 \(\scr G\) 的时间效率,我们提出了计算效率高的深度表示集成方法( Computation-Efficient deep Representation Ensemble method, CERE),该方法可以在给定的小批量中同时计算所有集成成员。为了进一步提高异常评分的准确性,我们提出了偏差增强异常评分函数(Deviation-Enhanced Anomaly Scoring function, DEAS),利用投影后密集的表征中包含的隐藏定量信息以及定性比较。
5.2.1 CERE: Computation-efficient Deep Representation Ensemble Method
依次将原始数据输入等式1中的 \(r\) 个独立网络会导致相当高的内存和时间开销。为了继承原始iForest的出色的可伸缩性,我们引入了CERE来有效地实现表示集成函数 \({\scr{G}}(\mathcal{D})\).
设 \(W\in \mathbb{R}^{m\times n}\)是一个神经网络层的权矩阵,然后我们使用随机向量 \(p_i\in \mathbb{R}^m\)和 \(q_i \in \mathbb{R}^n\) 通过乘法得到一个秩一矩阵,该矩阵用于推导每个集合成员的完整权矩阵。形式上,基于基础权重矩阵 \(W_0\),生成第 \(i\) 个集成成员的权矩阵 \(W_i\) 为
其中 \(\circ\) 表示哈达玛积
关于神经网络的输入 \(x \in \mathbb{R}^m\) 和 权重 \(W_i\) 的映射过程如下:
给定 \(r\) 组权重向量 \(\{\left< p_i,q_i \right>\}_{i=1}^r\) 和一小批大小为 \(b\) 维度为 \(m\) 的数据 \(\mathcal{X} \in \mathbb{R}^{b\times m}\)。映射结果的计算方式如下:
其中 \(\mathbf{P}_i\) 和 \(\mathbf{Q}_i\) 中的每一行都是重复的 \(\boldsymbol{p}_i\) 和 \(\boldsymbol{q}_i\)。假设 \(\mathbf{1}_b\) 是一个大小为 \(b\),全是1的向量,则\(\mathbf{P}_i=\mathbf{1}_b \boldsymbol{p}_i^{\top}\) and \(\mathbf{Q}_i=\mathbf{1}_b \boldsymbol{q}_i^{\top}\)
在CERE的帮助下,集成过程的时间复杂度类似于单个神经网络的前馈过程,因为所有集成成员可以在给定的小批量中同时计算。
设 \(\Phi\) 为使用Eq.(5)中新定义的前馈步骤的 \(L\) 层神经网络。表征集合由如下公式直接生成
其中 \(\Theta=\{ W_l, \{p_{(l,i)}\}_{i=1}^r,\{q_{(l,i)}\}_{i=1}^r \}_{l=1}^L\)。激活或池化等其他操作以及一些不使用权重矩阵的层则是按顺序处理的。
5.2.2 DEAS: Deviation-enhanced Anomaly Scoring Function
我们利用特征值对分支阈值的偏离程度作为附加权重信息,进一步改进隔离难度的度量。因为新创建的数据空间中的特征值通常分布密集,所以这些偏差程度是隔离难度的重要指标,能够一定程度上反映局部密度。例如,偏差值越小,表明数据对象位于密集区域,因此是难以隔离数据对象。具体地说,设 \(x_u\) 为iTree \(\tau_i\) 中数据对象 \(o\) 的对应表示,\(p(x_u|\tau_i)=\{1,\cdots,K\}\) 是它的遍历路径,我们定义 \(x_u\) 在 \(\tau_i\) 中的平均偏离程度为
因此,我们的偏差增强隔离异常评分函数如下:
其中,第一项是在iForest中用作异常分数的平均深度,第二项是我们引入的基于偏差的异常分数。
5.3 Algorithm of DIF


5.4 Theoretical Analysis
5.4.1 Time Complexity Analysis
设输入数据 \(D\) 为大小为 \(N\times D\) 的表格数据集,\(\phi\) 采用多层感知器网络。所使用的网络 \(\phi\) 包含 \(L\) 层,第 \(l\) 层包含 \(d_l\) 个隐藏单元,表示维数为 \(d\)。我们使用CERE在每个mini-batch中实现包含r个成员的集成。因此整个前馈计算为\(O(r\times N \times(D d_1 + d_l d + \sum_{l=1}^{L-1}d_id_{l+1}))\)。在DIF中只需要前馈步骤,并且隐藏单元的数量和表示维数通常很小。因此,这个过程在数据大小和维度上都是线性的,与原始的ifforest相比,它不会带来太多额外的计算开销。
在iTree构建的后续过程中,给定深度限制 \(J\),在每个iTree的生长过程中,我们最多需要 \(2^{J-1}\) 次划分(步骤(8-11))。对于有 \(n\) 个样本的节点,每次分割在确定所选维度的最大值和最小值以及分配过程中需要 \(O(n)\) 的复杂度。整个过程需要 \(O(2^{J-1} \times n \times r \times t)\) 的复杂度。\(J\) 和 \(n\) 通常使用固定的小值(通常分别为8和256)。因此,总体复杂度与集合大小 \(r\times t\) 成线性关系。对于算法2中的遍历过程,其计算过程与上述过程相似,因此与测试集的大小和集合的大小成线性关系。
综上所述,根据以上分析,DIF的时间复杂度为 \(O(ND(r × t))\)。它在数据大小、维数和集合大小方面具有线性复杂性,这继承了ifforest所期望的可伸缩性。
5.4.2 DIF as a Generalisation of iForest and EIF
没咋看过EIF就不细说了
5.5Discussions
DIF的威力主要取决下述三个部分
5.5.1 Representation Ability of Neural Networks
神经网络具有很强的表示能力,即使对于随机初始化的网络也是如此。如图3所示,新的数据空间是由随机神经网络生成的。这些初始化网络的随机性可以创建高度多样化的数据空间,在这些数据空间上,简单的轴平行切割可以等同于原始数据空间中复杂的切片切割。即使网络根本没有优化,非线性激活函数也可以有效地调整和折叠分割边界,将非线性性嵌入到隔离过程中。
另一方面,针对不同的数据类型已经开发了不同的深度学习架构,因此DIF可以通过插入处理特定数据的神经网络网络来生成表征(例如,多感知器网络、循环网络或图神经网络),从而能够处理不同的数据类型
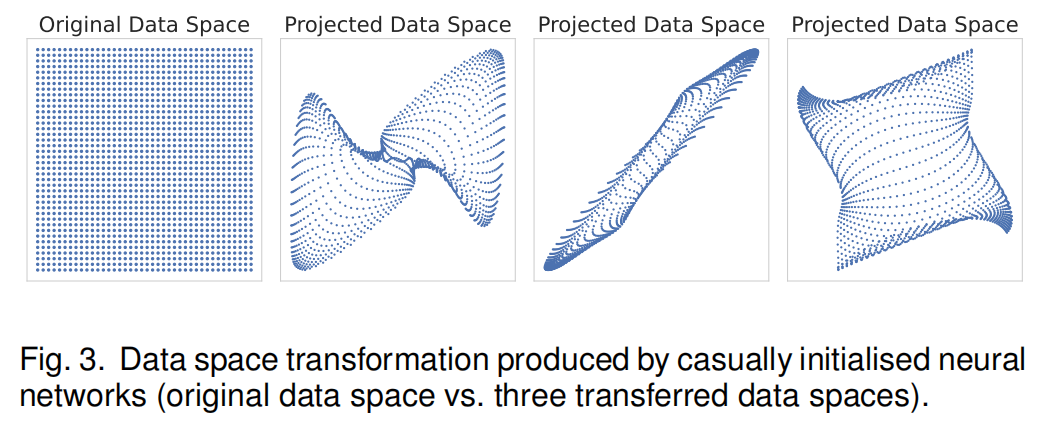
5.5.2 Optimised vs. Casually Initialised Representations
由于以下两个主要原因,DIF使用随意初始化的表示。
- 表征学习网络的损失函数不是通用的。很难设计一种损失函数来拟合具有多种特征的不同数据。
- 下游数据分隔可能受到优化过程的影响很大。这会削弱了基于孤立的异常评分方法所需要的特征表示的随机性和多样性
5.5.3 Synergy between Random Representations and Random Partition-based Isolation
DIF采用了一种新颖的表示方案,即通过无优化神经网络产生的随机表示集合。这些网络的参数可以通过从广泛使用的初始化分布(例如,正态分布或均匀分布)随机抽样来初始化,很容易产生一组具有良好随机性和多样性的特征表示。
给定足够大的随机表征集,我们可以在这些表征集合的某些子集上有效地隔离一些真正困难的异常,从而极大地提高随机数据分区中的隔离能力。例如,如图1所示,在大量新的表示空间中,有一些选择性的新空间使困难异常成为易于隔离的数据对象。
基于隔离的异常检测方法,都是基于异常评分的平均度量,因此,只要异常在某些隔离树中被有效地隔离,它们就会在异常评分中脱颖而出。
DIF利用随机表征和基于随机分区的隔离之间的这种独特协同作用,极大地改进了隔离过程,随后改进了异常评分功能,从而显著提高了基于隔离的异常检测的有效性。我们通过分别用多个替代方案替换随机表示和基于随机分区的隔离,实证地研究了这种协同作用的重要性(见第6.5节)。
6 EXPERIMENTS
6.1Experimental Setup
10个表格数据、4个图像数据、4个时序数据
6.1.1 Datasets
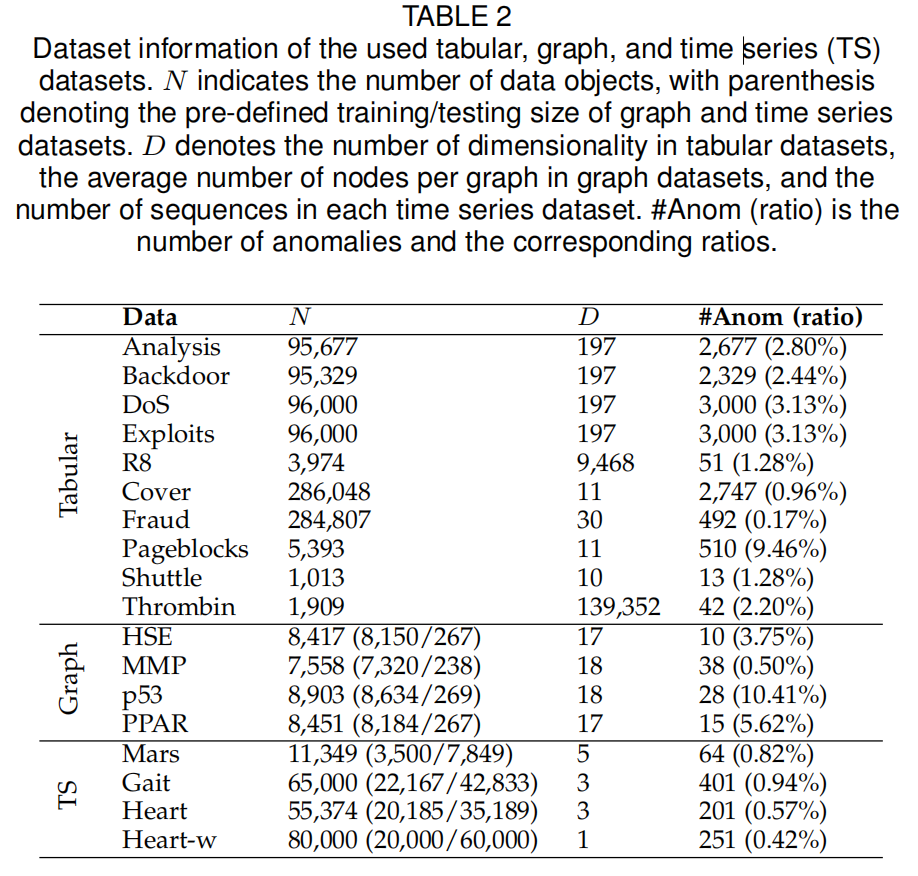
N表示数据对象的数量,括号表示预定义的图和时间序列数据集的训练/测试大小。D表示表格数据集中的维数,表示图数据集中每个图的平均节点数,表示每个时间序列数据集中的序列数。#Anom (ratio)是异常的数量和相应的比率。
6.1.2 Competing Methods
iForest and Its Extensions (IF-based Methods)
iForest、EIF、PID、LeSiNN
Ensemble of Deep Anomaly Detectors.
采用不同的最先进(SOTA)深度异常检测方法作为基础模型,并使用深度集成框架构建了一套基于集成的深度模型作为比较。
-
表格数据:RDP、REPEN、DeepSVDD、基于重建的Autoencoder baseline(简称RECON)。为了保证这些方法的时间效率和公平竞争,我们还采用了DIF中使用的CERE集成方法。
-
图像数据:GLocalKD
-
时序数据:TranAD
上述模型的集成版本被记为eRDP、eREPEN、eDSVDD、eRECON、eGLocalKD和eTranAD。
6.1.3 Parameter Settings and Implementations
DIF使用50个表示(r=50)和每个表示构建6个隔离树(t=6),每个iTree的子采样大小为256 (n=256)。DIF通过使用全连接的多层感知器网络来处理表格数据。所有基于IF的竞争方法都使用300棵树(集成大小与DIF相同)。
由于基于ID的竞争对手不能直接处理非表格数据,我们采用了最新的强大的无监督表示学习模型来产生高质量的向量表示,具体来说,InfoGraph和TS2Vec分别用于图数据和时间序列。InfoGraph使用GIN作为其图编码器架构,而TS2Vec使用带有残差块的扩展CNN模块。他们提出了特定的学习目标来优化生成的表征。为了公平起见,DIF使用相同的GIN和CNN网络结构来分别处理图数据和时间序列,但没有任何优化步骤。
深层异常检测器的训练分为50个epoch,每个epoch30步。REPEN, DSVDD和RECON使用具有1e-3学习率的Adam优化器,每个小批使用64个对象。根据经验,我们发现RDP在使用1e-4时可以显着更好地工作。这些方法的其他参数使用默认设置。
6.1.4 Evaluation Metrics and Computing Infrastructure
评价指标:AUC-ROC、AUC-PR
然后,我们引入了一个称为异常等度指数( Anomaly Isoability Index, AII)的新度量来衡量表征的质量。我们借用三重损失的概念来计算每个表示空间中所有真实异常中有效隔离异常的百分比,即:
其中\(\omega(a|n_i, n_j) = d(a, n_i)−d(n_i, n_j)\)表示欧几里得距离之差,\(a\sim \mathcal{A}\)表示从数据集中真实异常集中提取的任何异常,\(\mathcal{C}\) 是一组随机抽样的正态锚点,\(\mathcal{N}\)是另一组随机正态样本来代表整个正态分布。上述所有数据对象都来自目标表示空间。根据经验,我们使用\(|\mathcal{C}|=20\)和 \(|\mathcal{N}|=1000\)
6.2 Effectiveness in Reducing False Negatives
6.2.1 Tabular Data
与iforest及其三个扩展相比
DIF在很大程度上减少了假阴性,导致检测精度和/或召回率的平均性能显著提高,因此,DIF获得了更优的AUC-PR和AUC-ROC性能。特别是,在平均AUC-PR中,DIF显著优于EIF(61%)、PID(186%)、LeSiNN(56%)、iforest(144%)、eRDP(13%)、eREPEN(77%)、eDSVDD(19%)和eRECON(82%)。对于评价指标AUC-ROC,相较于这些方法,DIF也获得了4% - 11%的改善。
如表3所示,在99%的置信水平上,DIF显著优于基于隔离的方法。除了Fraud的AUC-PR之外,DIF是所有10个数据集上最好的基于隔离的检测器。在Fraud数据集上,基于最近邻的异常测量LeSiNN更有效,这是因为Fraud中的特征由于机密性问题进行过PCA变换,因此在最近邻信息中使用的距离概念可以更好地反映接近关系。
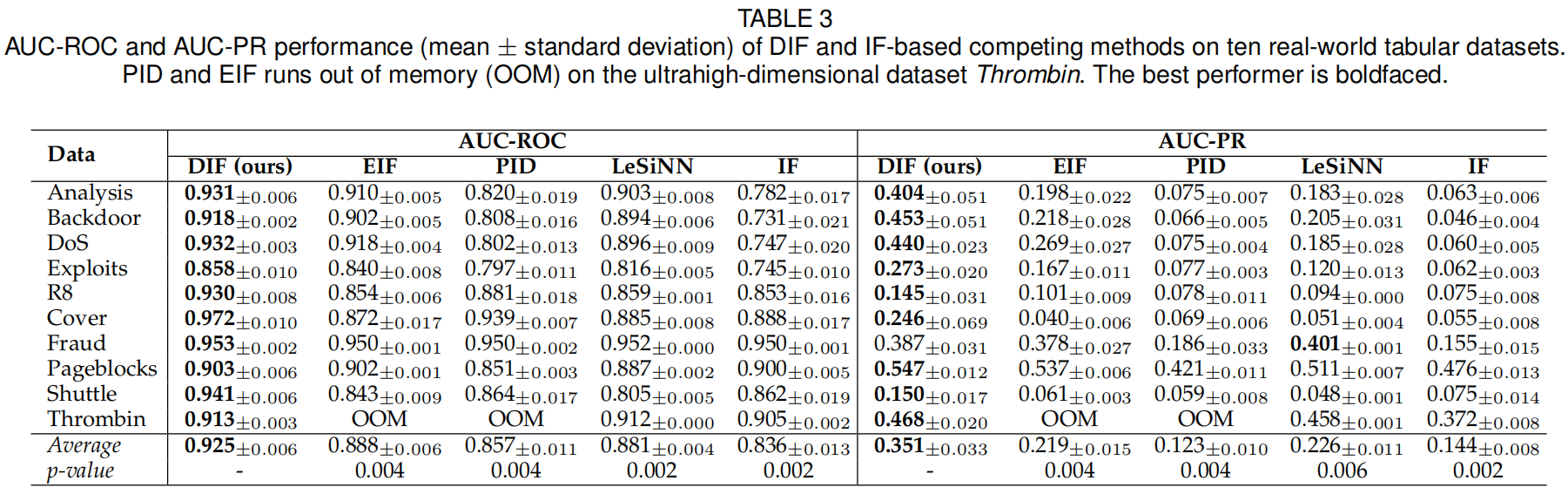
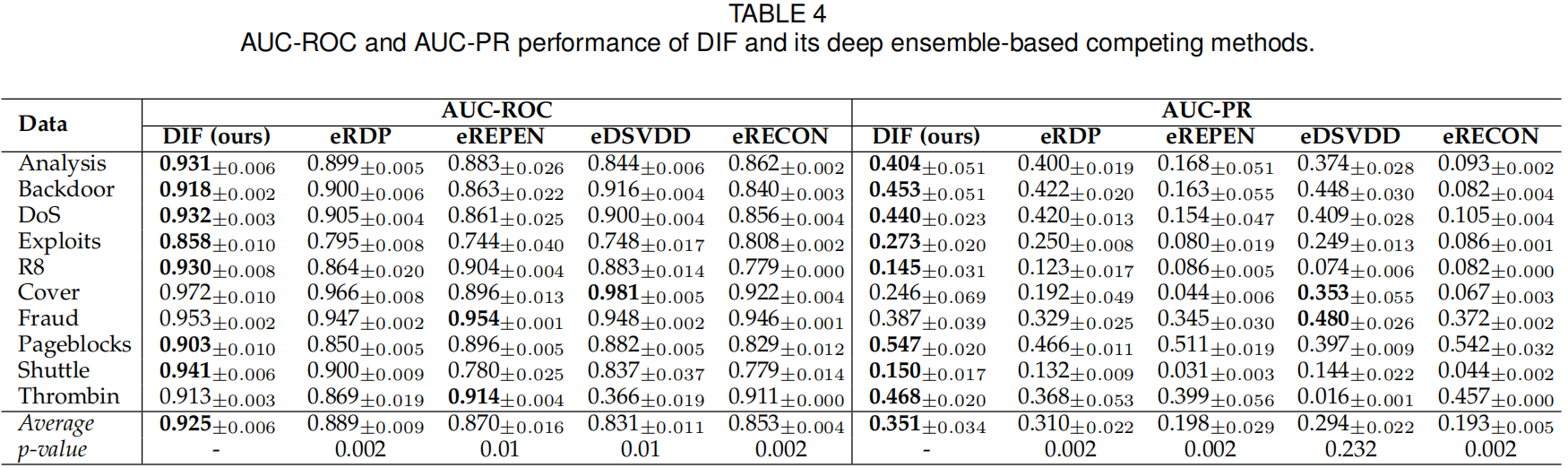
根据表4中的AUC-ROC表现,与基于深度集合的方法相比,DIF在99%置信水平下的表现明显更好。DIF在10个数据集中的7个数据集上的AUC-ROC和AUC-PR都达到了最好的性能,并且在其余3个数据集上得到了非常有竞争力的结果。
DIF在此比较中的优势在于
- 每个集成成员的表示多样性
- 在下游异常评分过程中,随机表示和基于随机分区的隔离的独特协同作用
同时DIF的运行速度更快。
6.2.2 Graph Data and Time Series
DIF分别使用与InfoGraph和TS2Vec中相同的网络结构(GIN和扩展CNN),但没有任何优化步骤。
对图数据和时间序列的检测性能如表5所示,其中选择EIF和LeSiNN作为竞争者,因为它们在表格数据集中的性能优于PID,iForest也作为基线。在图像和时间序列异常检测任务中,DIF在四个数据集中的三个数据上表现最好。

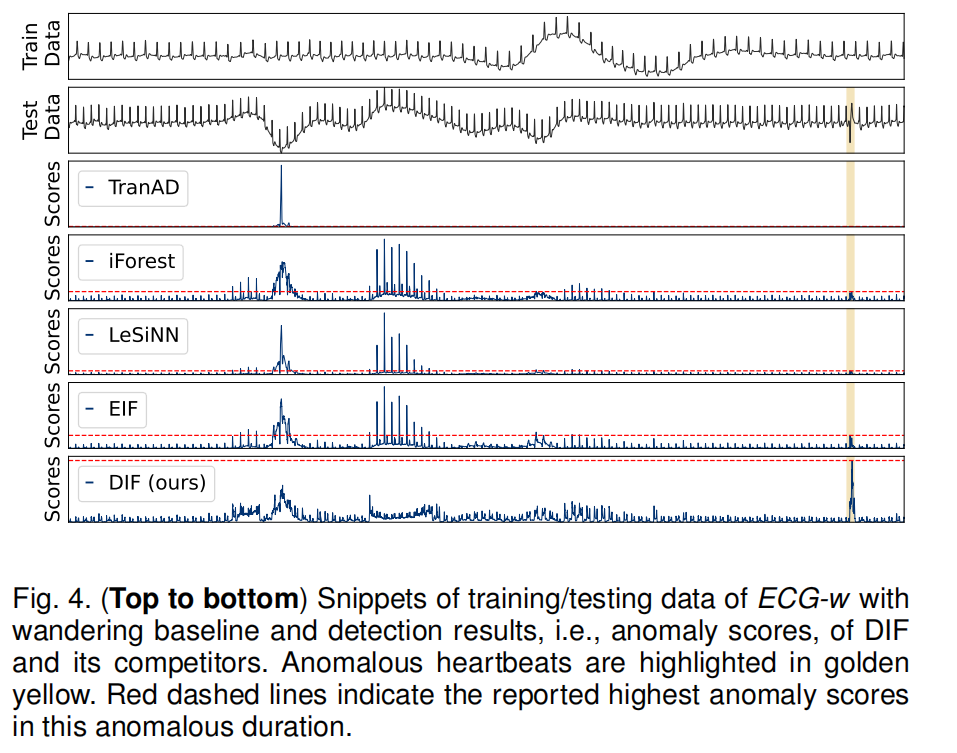
图4显示了ECGw数据以及DIF及其竞争方法的检测结果。我们的方法,成功对异常的心跳分配了更高的异常分数,从而减少了假阴性。
6.3 Scalability to High-dimensional, Large-scale Data
9个数据集包含5000个数据对象,它们的维度范围从16到4096。其他9个数据集有32个特征,大小从最小的1,000到256,000不等。
在使用CPU计算时,与基于深度集成的方法相比,DIF和所有其他基于隔离的方法在维数和数据大小方面都具有良好的可伸缩性。
使用GPU时,由于DIF只需要一个前馈步骤,而不是大量的训练epoch,因此与基于深度集成的DIF相比,它具有出色的时间效率。

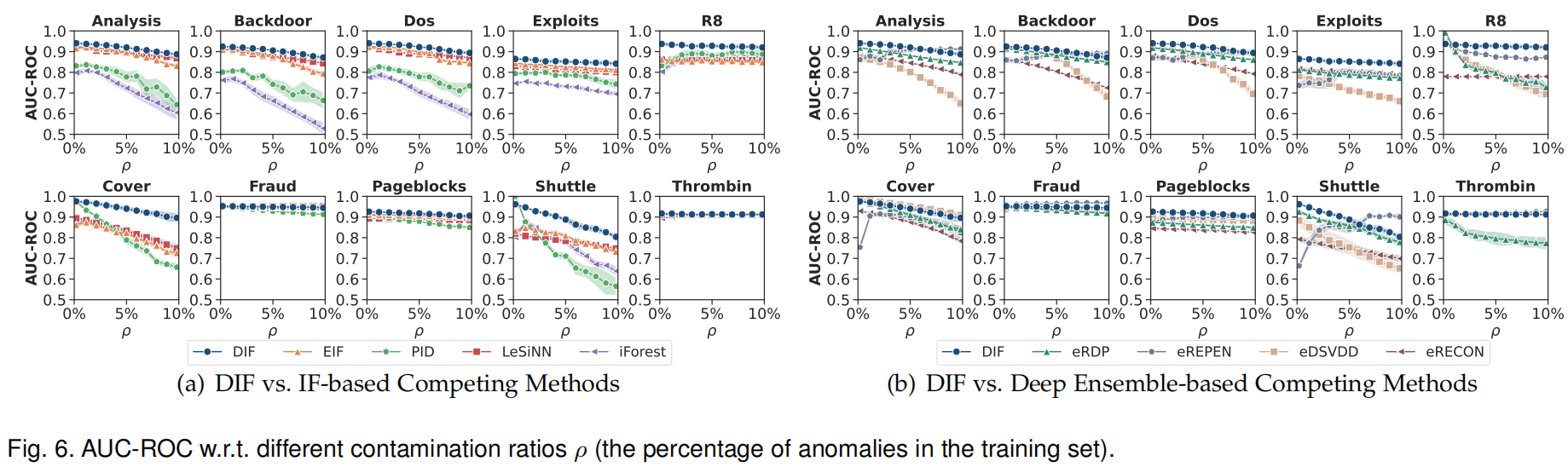
6.4 Robustness w.r.t. Anomaly Contamination
污染比在0%到10%之间
DIF在大多数数据集中具有相对明显的优势和较强的鲁棒性。最近的许多研究已经证明了深度集成在分布外鲁棒性方面的成功,这一定程度上解释了为什么基于深度集成的方法在异常污染方面比基于if的方法具有更好的鲁棒性。
6.5 Significance of the Synergy between Random Representations and Random Partition-based Isolation
6.5.1 Representation Scheme
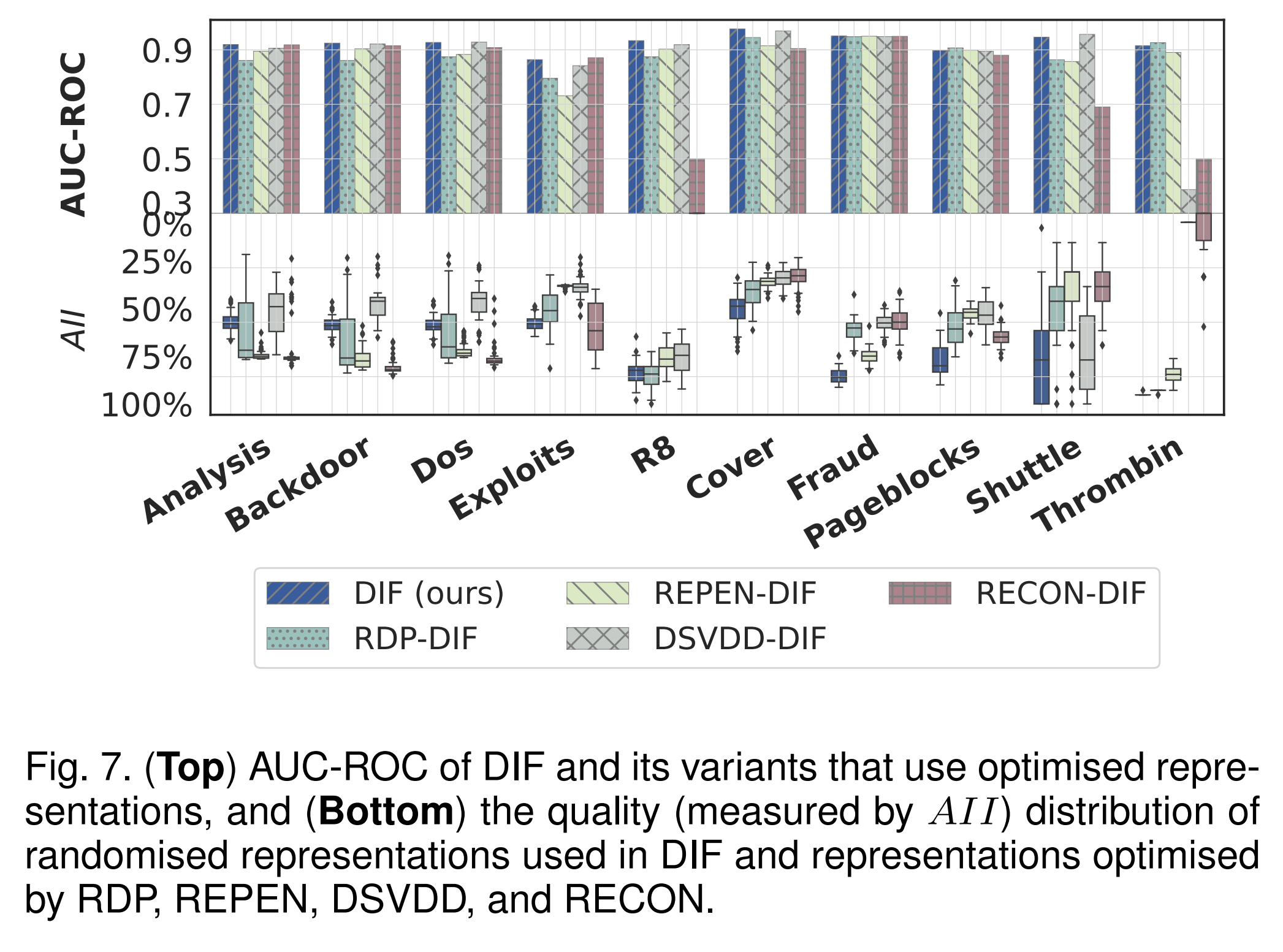
本实验将我们的方案产生的表征与优化的神经网络(RDP、REPEN、DSVDD和基于重构的Autoencoder)产生的表征进行比较,来评估我们的新表示方案的有效性。也就是说,我们用其中一种方法学习到的表征代替随机表征,而DIF的所有其他组成部分都是固定的。这四种变体分别表示为RDP-DIF、REPEN-DIF、DSVDD-DIF和RECON-DIF。
AUC-ROC Results
DIF在5个数据集上优于4种优化的基于表示集成的方法,并在其他5个数据集上显示出非常有竞争力的性能。平均而言,随机表示集合比RDP-DIF、REPEN-DIF、DSVDD-DIF和RECON-DIF分别贡献了5%、5%、7%和15%的AUC-ROC改善。
Quality per Representation
为了进一步分析上述结果背后的机制,我们直接评估由DIF及其变体产生的每个表示的质量。表征质量通过异常等度指数(AII)来衡量。我们使用箱形图来表示集成框架中50种表示产生的表示的质量分布。
结论:
- 我们的表示方案实现了期望的多样性和随机性,同时在每个表示中保持稳定的表达性,与下游基于隔离的异常评分机制有很好的协同作用。这是DIF优越性能背后的主要驱动力。
- 经过优化的表征可以在一些数据集上保持一致的高质量(例如,RECON-DIF在Analysis、Backdoor和DoS上很好地隔离了近80%的真实异常),而表征缺乏多样性降低了该集成框架的有效性。
- 与随机表示相比,优化甚至可能导致某些数据集上更差的表示(例如,R8, Cover, Pageblocks和Thrombin)。这可能是由于他们学习目标中的基本假设在这些数据集中可能不成立(例如,one-class假设)。
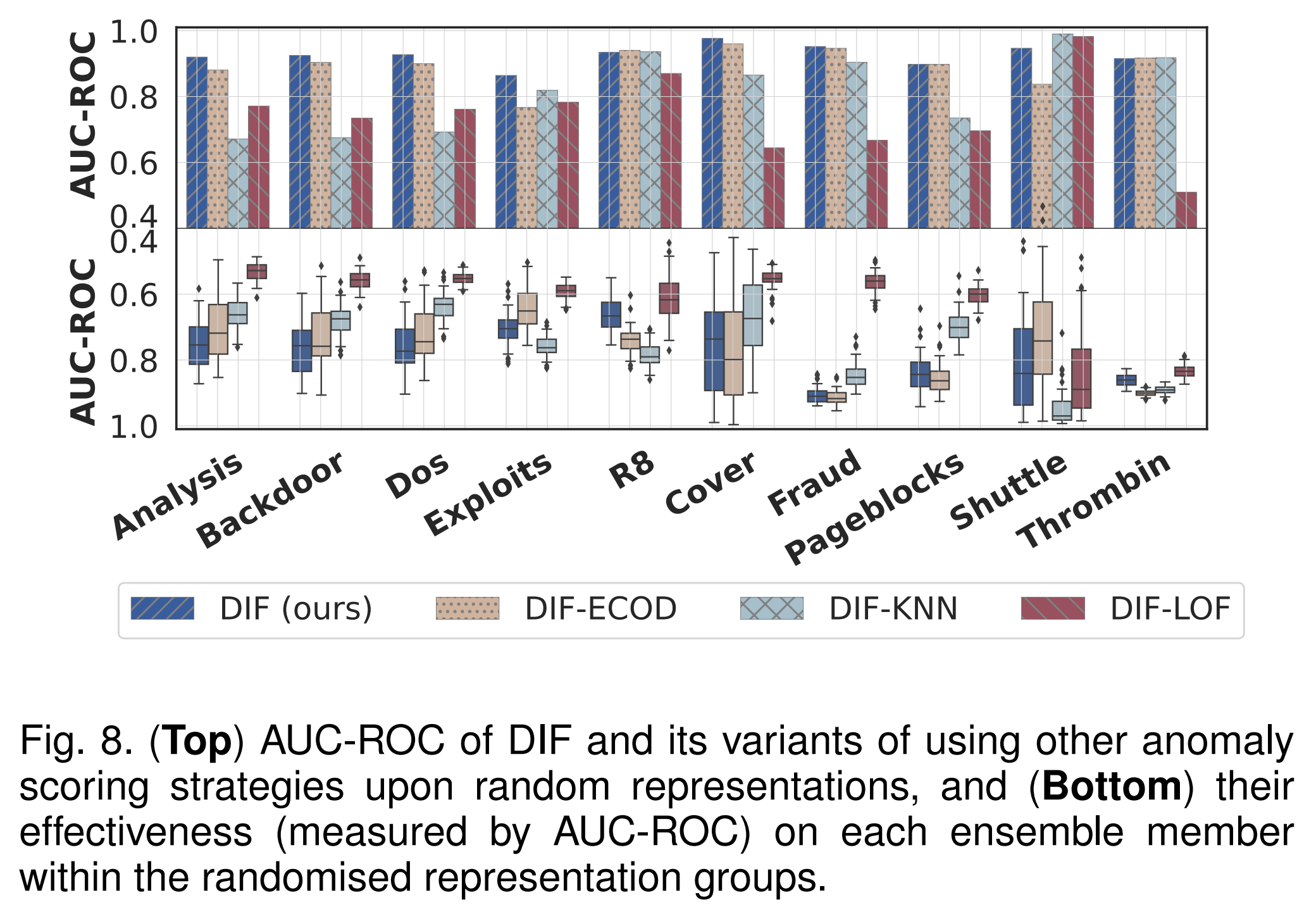
6.5.2 Scoring Strategy
本节通过研究随机表示与其他异常评分方法(包括基于概率的异常评分方法ECOD、基于距离的方法KNN和基于密度的方法LOF)相结合的有效性,来验证随机表征与下游基于集成的异常评分之间的优秀协同作用。
这些方法中的每一种都用来取代基于隔离的评分过程,而所有其他模块都是固定的。这些变体分别表示为DIFECOD、DIF-KNN和DIF-LOF。同样,我们评估他们的AUC-ROC表现和个人评分质量如下。
AUC-ROC Results
DIF在10个数据集中有7个优于这些竞争变体。平均而言,DIF比DIF- ecod、DIF- knn和DIF- lof分别高出3%、13%和25%。
Quality per Anomaly Scoring Result.
每个异常评分结果的质量。我们还研究了由DIF及其变体对每个随机表征产生的单个异常评分结果的质量,如图8(底部)所示。质量也是通过AUC-ROC来评估的。
结论:
- 这些评分方法,可以在Exploits, R8, and Thrombin上,取得比我们的基于隔离的打分策略更好的单个评分结果。然而,与DIF相比,它们只产生较差的效果或稍好的综合结果。这些评分方法无法利用我们的表征提取方案中嵌入的多样性。
- 通过充分利用表征的多样性和随机性,DIF获得了更好的综合性能,例如,在R8上AUC-ROC高于0.9,最大个体值仅达到0.7左右。
- DIF在Shuttle上次于它的变型。这可能是因为使用这些相互竞争的评分方法中使用的先验概念(即概率、距离或密度)可以更容易地识别该数据集中的异常。然而,这些先前的概念可能无法在所有数据集上正常工作。
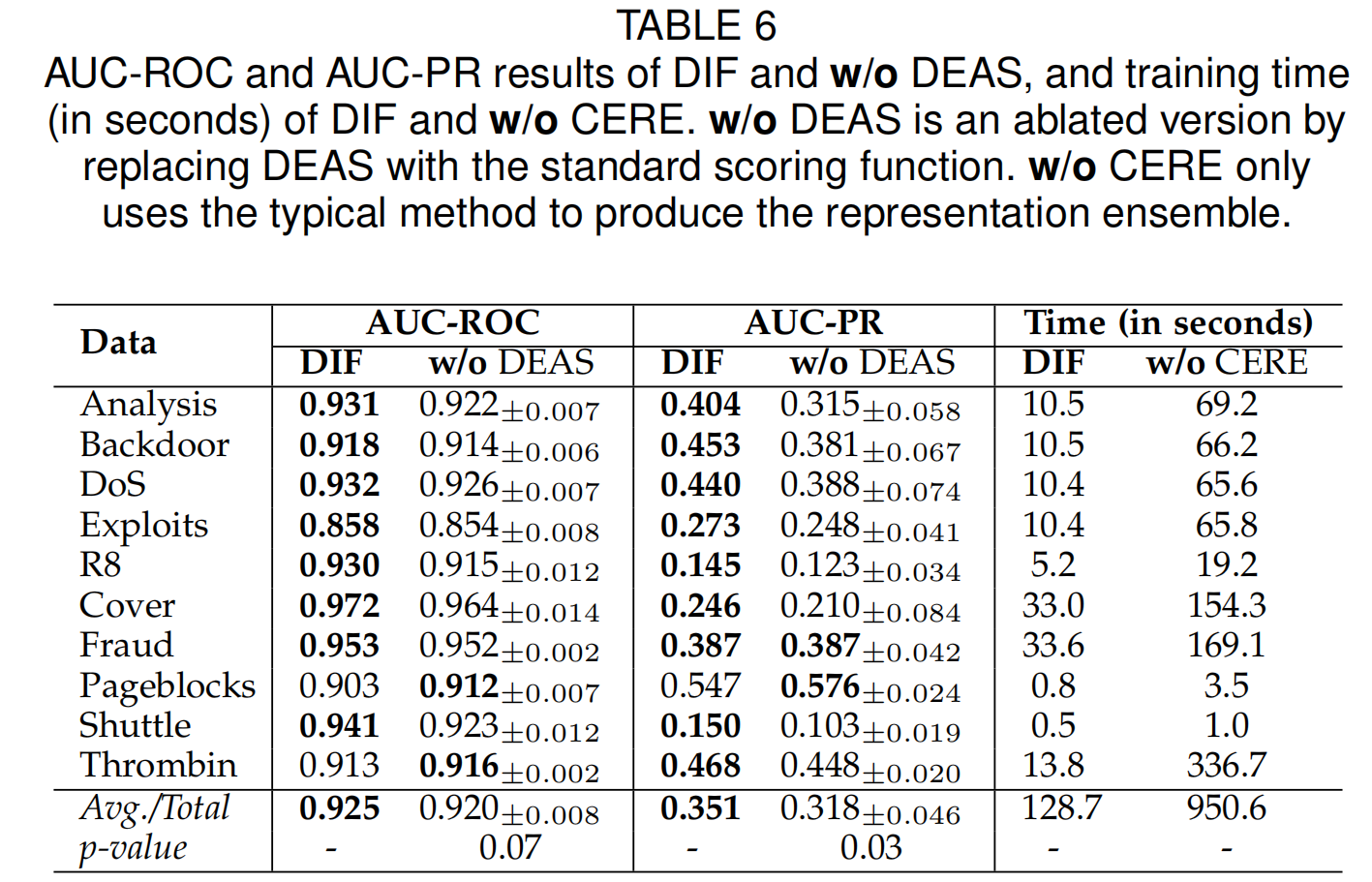
6.6 Ablation Study on CERE and DEAS
采用了两种简化的变体,即 \(\text{w/o\ CERE}\) 用传统的顺序集成过程代替 \(\scr{G}_\text{CERE}\), $ \text{w/o DEAS}$ 用iforest中使用的标准评分函数代替我们的评分函数 \(\scr{F}_\text{DEAS}\)。
在90%的置信区间内,DIF显著优于$ \text{w/o DEAS}\(,并实现了约11% 的AUC-PR改进。此外,在CERE的帮助下,DIF的培训时间大大减少。所有10个数据集的总训练时间仅为无CERE变体的十分之一左右。\)\text{w/o\ CERE}$ 的AUC-ROC/AUC-PR结果与DIF相当
- Isolation Detection Anomaly Forest Deepisolation detection anomaly forest detection机器anomaly reading forest paper deep mean-shifted contrastive detection anomaly distribution detection anomaly论文 detection learning anomaly survey discrimination distribution detection anomaly multi-class detection unified anomaly anomaly forest