从 Pyspark UDF 调用另一个自定义 Python 函数
Python 编码的 PySpark UDF 提供了调用其他Python 函数的能力,无论它们是内置函数还是来自外部库的用户定义函数。通过使用户能够利用现有的 Python 代码,此功能提高了 UDF 的模块化和可重用性。在分布式 PySpark 环境中,用户可以轻松实现特定领域的逻辑、执行具有挑战性的计算或使用尖端算法。用户可以通过从 PySpark UDF 调用 Python 函数来充分利用 Python 庞大的库和功能生态系统的全部潜力。
调用步骤
1.导入对应模块
首先,从“pyspark.sql.functions” 模块导入“udf” ,该模块提供了处理 Spark DataFrame 的工具。
from pyspark.sql.functions import udf
2.启动spark会话
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
3.创建DF数据
data = [("Marry", 25), ("Sunny", 30), ("Ram", 35)]
df = spark.createDataFrame(data, ["name", "age"])
4.定义自定义 Python 函数
将字符串转换为大写字符串的函数。
def to_uppercase(string):
return string.upper()
5.创建 PySpark UDF
创建自定义 Python 函数后,使用 “pyspark.sql.functions” 模块中的 UDF 函数构造 PySpark UDF。 “udf()” 函数应接收自定义 Python 函数作为参数。自定义函数注册为 UDF,以便它可以应用于 DataFrame 列。
to_uppercase_udf = udf(to_uppercase)
6.将 UDF 应用到 DataFrame
创建 PySpark UDF 后,使用 “withColumn()” 函数将其应用到 DataFrame 列。在 DataFrame 中,此方法添加新列或删除现有列。DataFrame 的每一行都会调用 UDF 一次,将自定义 Python 函数应用于指定列并生成所需的结果。
df = df.withColumn("name_uppercase", to_uppercase_udf(df["name"]))
7.显示结果
df.show()
根据以上步骤写几个pyspark UDF调用python自定义函数的示例
示例1:将 DataFrame 列转换为大写
# 导入模块
from pyspark.sql import SparkSession
from pyspark.sql.functions import udf
# 自定义函数
def to_uppercase(string):
return string.upper()
# 创建sparksession
spark = SparkSession.builder.appName("pyspark_UDF").master("local[*]").getOrCreate()
sc = spark.sparkContext
# 创建DF
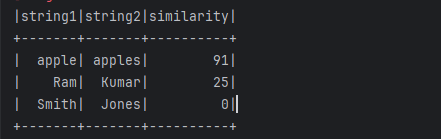
data = [["Marry", 25], ["Sunny", 20], ["Ram", 30]]
df = spark.createDataFrame(data, ["name", "age"])
# 创建pyspark UDF
to_uppercase_udf = udf(to_uppercase)
# 将UDF应用于“name”列
df = df.withColumn("name_uppercase", to_uppercase_udf(df["name"]))
df.show()
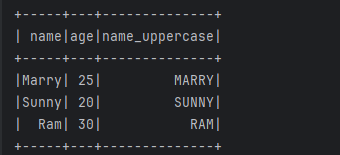
示例2:调用组合多个 DataFrame 列的自定义 Python 函数将两列数据进行拼接
在此示例中,我们将创建一个包含 2 列的数据框 - ' first_name ' 和 ' last_name '。然后创建一个 Python 自定义函数“ combine_columns ”,它将“first_name”和“last_name”作为参数,并返回一个列,将它们组合在一起以创建“ full_name”。
from pyspark.sql import SparkSession
from pyspark.sql.functions import udf
def combine_columns(coll, col2):
return coll + " " + col2
spark = SparkSession.builder.appName("pyspark UDF").master("local[*]").getOrCreate()
sc = spark.sparkContext
data = [("John", "Doe"), ("Ram", "Kumar"), ("Smith", "Jones")]
df = spark.createDataFrame(data, ["first_name", "last_name"])
combine_columns_udf = udf(combine_columns)
df = df.withColumn("full_name", combine_columns_udf(df["first_name"], df["last_name"]))
df.show()
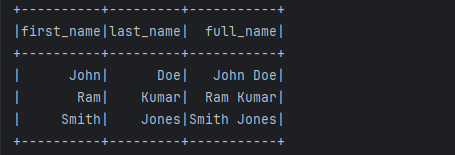
示例3:使用外部库从 PySpark UDF 调用自定义 Python 函数
对于更复杂的计算,PySpark 使我们能够在定制函数中使用外部 Python 库。假设我们希望使用模糊匹配库 “fuzzywuzzy” 和名为 “calculate_similarity” 的自定义 Python 方法来比较两个文本之间的相似度。
在此示例中,我们从Python 中的 fuzzywuzzy 库导入“fuzz”模块,并使用“ fuzz.ratio() ”函数来确定两个文本之间的相似程度。我们创建了独特的 Python 方法“ calculate_similarity() ”来使用输入字符串调用 “fuzz.ratio()” 算法。使用 “udf()” 函数,我们构建一个名为 “similarity_udf” 的 UDF 并定义输入和输出类型。最后,我们使用 “withColumn()” 方法将 UDF 应用于“string1”和“string2”列,并显示具有相似率的结果 DataFrame。
from pyspark.sql import SparkSession
from pyspark.sql.functions import udf
from pyspark.sql.types import IntegerType
from fuzzywuzzy import fuzz
def calculate_similarity(str1, str2):
return fuzz.ratio(str1, str2)
spark = SparkSession.builder.appName("pyspark UDF").master("local[*]").getOrCreate()
sc = spark.sparkContext
data = [("apple", "apples"), ("Ram", "Kumar"), ("Smith", "Jones")]
df = spark.createDataFrame(data, ["string1", "string2"])
calculate_similarity_udf = udf(calculate_similarity)
df = df.withColumn("similarity", calculate_similarity_udf(df["string1"], df["string2"]))
df.show()