Nuscenes主要在波士顿和新加坡进行,用于采集的车辆装备了1个旋转雷达(spinning LIDAR),5个远程雷达传感器(long range RADAR sensor)和6个相机(camera)
一、数据集结构:(借用https://zhuanlan.zhihu.com/p/463537059生图)

从左到右四列分别是Vehicle(采集数据所用的交通工具)、Extraction(所采集的对象)、Annotation(标注)和Taxonomy(分类)。
从上到下各行表示各种级别的对象,以Extraction为例,一个scene表示从日志中提取的20秒长的连续帧序列(A scene is a 20s long sequence of consecutive frames extracted from a log.)而一个sample表示一个2Hz的带注释的关键帧(A sample is an annotated keyframe at 2 Hz.)也就是从一个scene中提取出的一帧。而sample_data则更进一步的表示在某时刻(timestamp)的传感器数据,例如图片,点云或者Radar等等。每一个sample_data都与某个sample相联系,如果其is_key_frame值为True,那么它对应的时间戳应当与它所对应的关键帧非常接近,它的数据也会与该关键帧时刻的数据较为接近(我的个人理解)。
由此可以发现,一个上一级的对象可以包含多个下一级的对象,或者说表示更加广义层面的信息。例如一个scene中可以有多个sample(scene的一个属性为nbr_samples=number of samples)。又比如sample和sample_data的关系,sample只是表示某个采样的时刻,而sample_data则表示该时刻具体传感器采样得到了什么数据,在一个sample对应的关键帧附近,多次采集了各时间戳的sample_data。关于这一点可以看我所画的下面这张图。
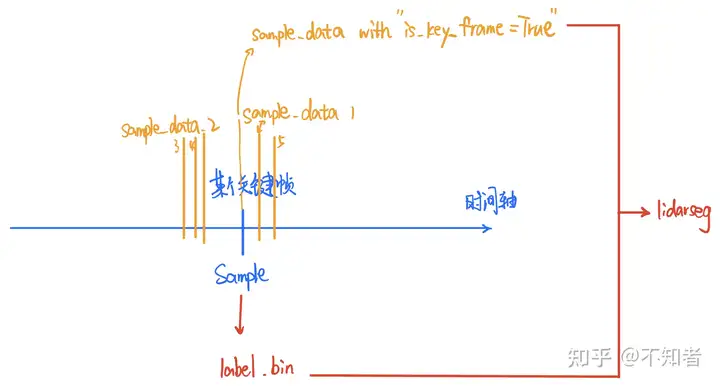
sample与sample_data, 以及lidarseg
接下来对图表中的每个部分作相应的解(fan)释(yi)。不同于官网文档的排序,这里我会按照每一行从左到右的顺序。
第一级
log:采集数据的相关日志,包含车辆信息、所采集的数据(类型?)、采集地点等信息。
scene:采集场景
instance:对象注释实例,包含对象类别、注释数量、初次和末次注释的token
category:对象分类集合,包含human、vehicle等共有23类。子类以human.pedestrain.adult的形式表示。
第二级
map:地图数据,自上而下获得。包含map_category、filename:存储map_mask掩码数据的bin file地址。
sample:一个2Hz的带注释的关键帧,也就是从一个scene中提取出的一帧。包含时间戳、对应的scene_token、下一个sample和上一个sample的token。
lidarseg:标注信息和点云之间的映射关系。filename为对应的bin file的名称,该bin文件以numpy arrays的形式存储了nuScenes-lidarseg labels 标签。sample_data_token为某个sample data的token key,该sample data为对应的bin标签文件所标注的、且is_key_frame值为True的sample_data数据。
第三级
calibrated_sensor:一个特定传感器在一个特定车辆上的矫正参数。包含translation、rotation、camera_intrinsic(内在相机校准)。
sample_data:某时刻(timestamp)的传感器数据,例如图片,点云或者Radar等等。包含ego_pose_token(指向某一ego pose)、calibrated_sensor_token(指向特定的calibrated sensor block)、数据存储路径、时间戳、is_key_frame值等。
sample_annotation:样本标注。包含所对应的sample token、instance token、attribute token、visibility token、bounding box 中心点坐标以及长宽高、lidar points数量、下一个和上一个标注。
attribute:一些关于样本的可能会改变的性质,描述了物体本身的一些状态,比如行驶、停下等,包含三个key,Example: a vehicle being parked/stopped/moving, and whether or not a bicycle has a rider.
第四级
sensor:传感器。包含频道(channel)、modality({camera,lidar,radar})
ego_pose:采集所用的车辆在特定时间戳的pose。基于激光雷达地图的定位算法给出(见nuScenes论文)。包含坐标系原点和四元坐标(需要读论文了解具体含义)、时间戳。
visibility:可见性评估,0-40%,40%-60%,60%-80%以及80%-100%。
二、实例分析
Scenes:
下载得到一个mini版的nuScenes数据集,可以看到里面有若干个scene
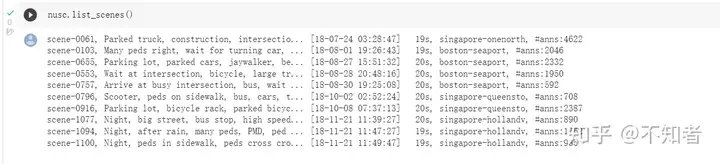

以第一个sample为例。使用nusc.get(类别,token)获取sample

可以看到一个sample包含了。。。data中包含了这一sample由各种传感器收集到的数据,


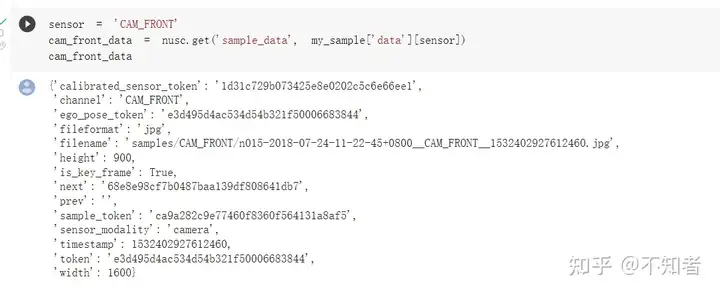
通过对特定的token使用nusc.get()命令,我们就可以得到对应的数据。例如对data中的CAM_FRONT使用,如下图。
我们也可以在这里 对上面获得的数据使用nusc.render_sample_data(数据的token),来看其可视化结果(含标注)。
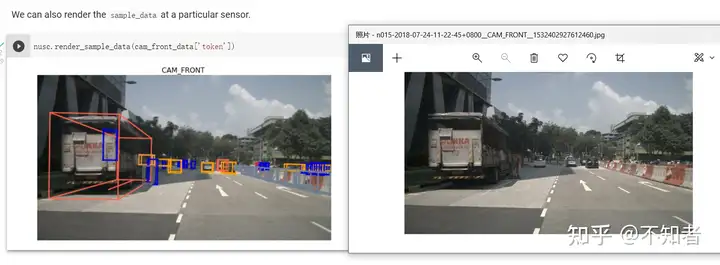
右图为根据cam_from_data中的filename路径找到的文件,可以发现render会自动添加检测框
一个sample中可能标注多个对象,此时可以通过nusc.render_annotation(annotation's token)来可视化特定标注。
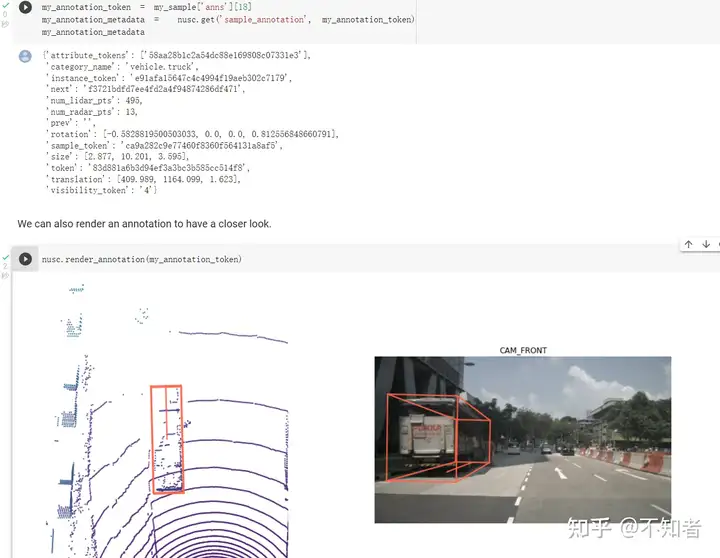
instance
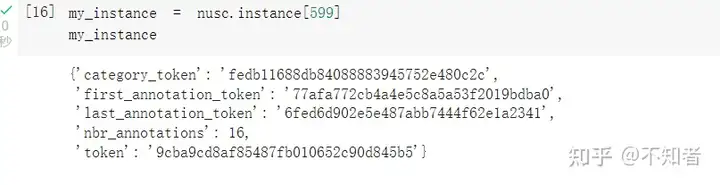
上面我们探索了一下scene。而从另一方面来说,另外一个第一级对象instance代表了一个个特定的需要被检测的目标,我们可以简单的使用nusc.instance[index]来获取某个instance。
对这样的某个目标,可能有多个标注来标记他,对应一段时间内不同的时间戳。例如下面的案例中,从卡车进入范围到远离,一共标注了16次。我们可以通过简单的调用nusc.render_instance来可视化这个目标,个人理解是会选择中间的某一帧标注进行可视化。如下图。
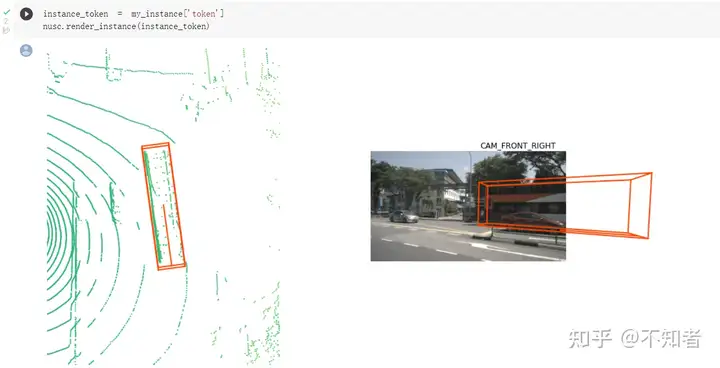
直接调用render _instance()
也可以调用特定帧的标注,例如最开始和最后的,来看不同时刻的标注情况。
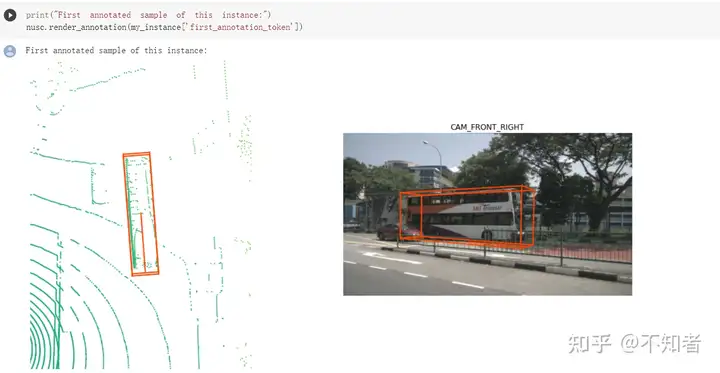
调用render_annotation()获得第一帧的标注

最后一帧的标注