轮廓系数(Silhouette Coefficient Index)
轮廓系数(Silhouette Coefficient Index)是一种聚类评估指标,用于评估数据聚类的效果。其取值范围在[-1, 1]之间,指标值越大表示聚类结果聚类效果越好。
具体来说,轮廓系数既要考虑聚类结果的紧密性,又要考虑聚类结果之间的分离度。如果一个数据点与自己所属的簇内的其他数据点的距离很小,但是与其他簇中的数据点的距离很大,就表示这个数据点所在的簇内紧密度高,簇间分离度大,那么该数据点的轮廓系数就会越大。
总体来讲,轮廓系数是更加全面的评估指标,因为它不仅考虑到了簇内的紧密度,还考虑了簇间的分离度。所以,在评估聚类效果时,尤其是对于需要分析簇内分布紧密而簇间分布分散的数据,轮廓系数是一个比较好的评估指标。
silhouette_score是一种聚类算法效果评估指标,用于评估聚类结果的紧密度和分离度。其取值范围为[-1,1],分别表示聚类结果差、不确定和良好。silhouette_score 越接近1,表示聚类结果越好,silhouette_score 越接近-1,表示分类结果较差,不过也可以出现接近0的情况,这说明分类结果不明显。
虽然silhouette_score值越接近1越好,但并不是说得到一个越高的silhouette_score就认为结果一定更好。具体来说,还需结合实际场景需求、数据特点、聚类算法等多方面因素做出综合判断。
1.1 原理
对于聚类结果的轮廓系数,它实际上是样本轮廓系数的平均值。这也就是说聚类样本中的每个样本点对应都有一个轮廓系数值,而总的轮廓系数则是所有样本点轮廓系数的平均值。
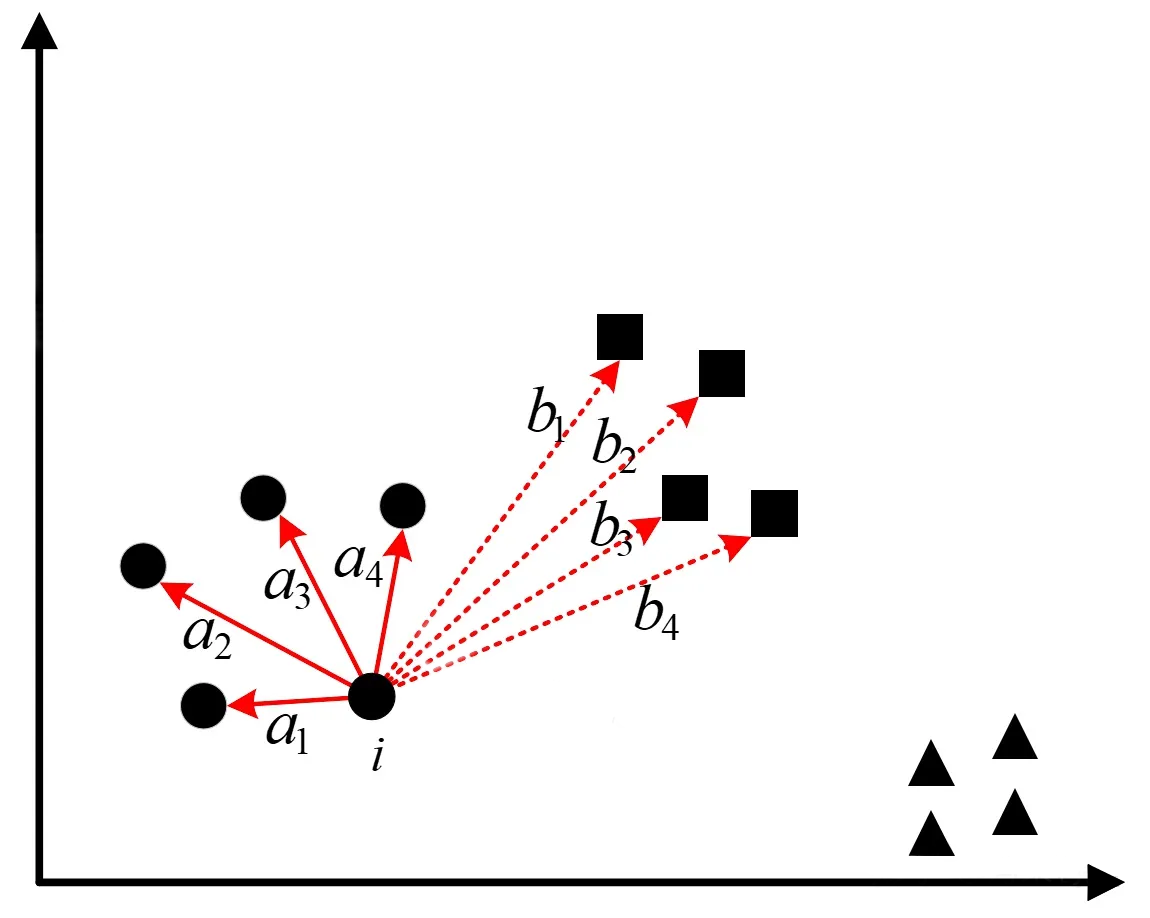
数据样本中一共包含有3个簇结构,对于最左边这个簇中(圆形)的样本点\(i\)来说,距离其最近的簇为中间(方形)这个簇。现在定义样本\(i\)到簇中每个样本距离的均值为\(a(i)\),到最近簇中每个样本距离的均值为\(b(i)\),即此时根据上图所示的结果有:
对于同一个簇中的每个样本点来说,距离自己最近的簇可能并不是同一个;同时,在寻找距离当前样本点最近的簇结构时,计算的是当前样本点到各个簇中心的最短距离,而不是计算当前样本点所在簇的簇中心到其它每个簇中心的最短距离。
此时,样本\(i\)的轮廓系数\(s(i)\)定义为:
当\(a(i)\)越小而\(b(i)\)越大时,此时对应的情况是样本\(i\)所在的簇中所有样本点之间距离都比较近(簇内距离较小),样本\(i\)所在的簇距离其最近簇的距离较远(因为此时样本\(i\)所在的簇中簇内距离较小,所以样本\(i\)到其它簇的距离可以近似地看做样本\(i\)所在簇到其它簇之间的距离),所以\(s(i)\)此时也就越接近于1,即聚类效果越好。
当\(b(i)\)越小而\(a(i)\)越大时,此时对应的情况是样本\(i\)所在的簇中所有样本点之间距离都比较远(簇内距离较大),样本\(i\)所在的簇距离其最近簇的距离较近,所以\(s(i)\)此时也就越接近于-1,即聚类效果越差。
轮廓系数是通过对每个数据点计算这个点和它所在簇内其他数据点的相似度以及该点与其他簇内数据点的相似度,综合计算得出的。计算方法如下:
-
对于一个数据点 \(i\),先计算它和簇内其他数据点的平均距离 \(a_i\)(簇内相似度)。
-
然后计算该点与不包含该点所在簇的其他簇内数据点的平均距离 \(b_i\)(簇间相似度),选取其中距离最小的那个作为 \(i\) 的簇间平均距离。
-
最后,计算数据点 \(i\) 的轮廓系数 \(s_i = \frac{b_i - a_i}{\max(a_i, b_i)}\)。
将所有数据点的轮廓系数取平均值,即得到聚类算法的整体轮廓系数。
需要注意的是,若某个数据点所在簇的数据点数量小于等于1,则该点的轮廓系数为0。
每个样本点都有一个轮廓系数值
1.2 代码
import numpy as np
from sklearn.cluster import KMeans
from sklearn.datasets import load_iris
from sklearn.metrics import silhouette_score, silhouette_samples
def test_silhouette_score():
x, y = load_iris(return_X_y=True)
model = KMeans(n_clusters=3)
model.fit(x)
y_pred = model.predict(x)
# 计算轮廓分数: 所有样本点的轮廓系数的平均值
score_mean = silhouette_score(x, y_pred)
# 计算所有样本点的轮廓系数
score_all = silhouette_samples(x, y_pred)
print(f"轮廓系数 by sklearn: {score_mean}")
if __name__ == '__main__':
test_silhouette_score()
上面的代码执行的结果是:score_mean是所有的轮廓系数分数的平均值,score_all是所有的轮廓系数分数
silhouette_score是用来计算所有样本轮廓系数平均值
silhouette_samples是用来计算聚类模型中每个样本的轮廓系数