一、前言
(1).知识点:我觉得用到的最多的就是HashMap,包括的HashMap的基本用法还有比如怎么排序的问题,都是比较陌生的点,需要课外的补充学习。
(2).难度:难度本身还可以,难度降低的原因主要是类图以及类的设计方面老师在上课时整体分析了一遍,还有一个难点是HashMap的使用,由于是比较是陌生的知识点,但是这又是很好的数据结构,运用好了真的很方便,所以在管理系统-1上面会显得花时间更多,是一个逐渐适应的过程,后面会用了大概之后,就会显得轻松一点,难度比较起来就简单了,三次作业总体难度还可以,完成大部分还是可以的。由于第三次成绩管理系统作业的个人原因,没能完成,稍稍有点可惜。
二、设计与分析
(1).成绩管理系统-1
1.总体分析:
第一次的成绩系统是迭代的开始,最开始的类设计和框架的建立都是比较重要的,对于后续迭代来说是有很大影响的,成绩管理系统,其实就是对学生成绩的信息处理,对于输入的学生课程等信息处理,最后输出学生的总平均成绩、每个课程的总平均成绩、每个班级的总平均成绩,所以应该来说可以分成几个大块,第一是对信息的处理,HashMap的作用就开始体现了,将学生课程班级都做成HashMap的结构,根据某个key就可以找到相应的信息,第二个就是对成绩的计算,在成绩管理系统-1中,计算的方面还是比较简单的,只有两种成绩,考试方式的成绩就用加权计算,比例也是规定好的,最后一个就是对成绩的排序和输出,整体的流程就这么个大概。
说说它和点菜系统的区别吧,成绩管理系统与点菜系统很明显的一个不同的就是点菜系统是每输入一行,就会处理一行,然后输出,而成绩管理系统要课程信息和每一次的选课信息进行存储和处理,最后再将处理过后的信息统一输出,当然这是代码内部逻辑的不同。
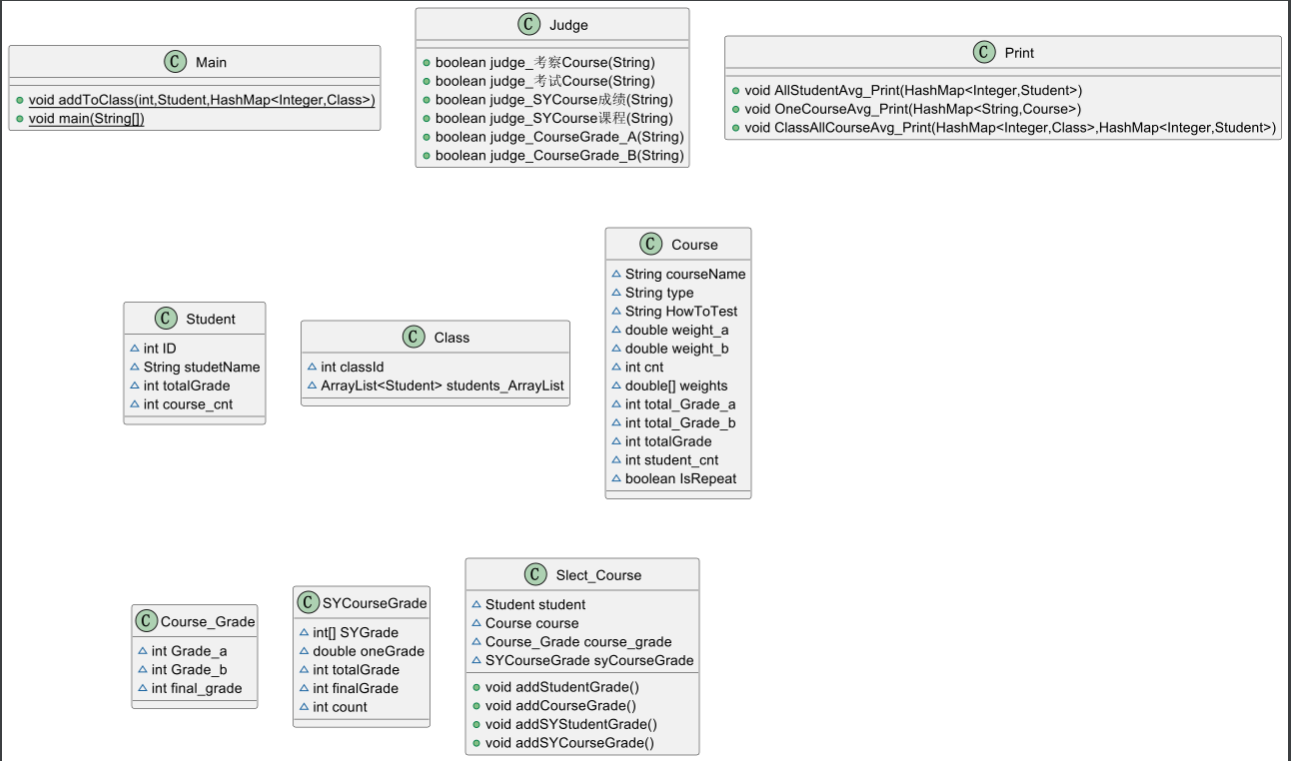
2.我的类图:
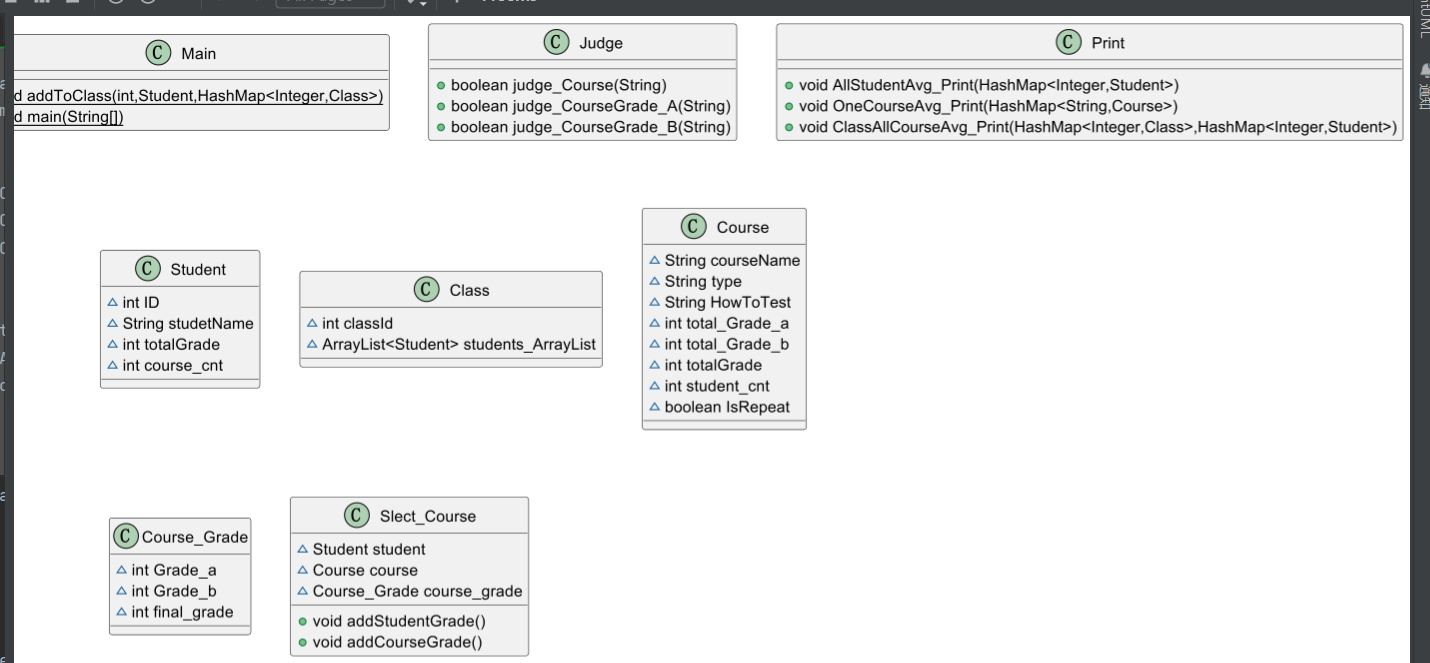
类图分析:总共是有七个类,main类中另外加了一个将学生添加到班级中的static方法,主要避免代码重复太多,简化了一个方法出来;然后就是Judge类,作用是判断各种的语句输入是否符合格式,不符合格式输出“wrong format”,不在主main方法中写太多没必要的代码;下一个是Print类,跟Judge类类似,用于打印输出最后的成绩信息,遍历Map;其他的类就是正常的类,有Student学生类,Class班级类,Course课程类,Course_Grade课程成绩类,Slect_Course选课类,正常的属性就不说了,主要是另外加的属性,学生类中的加了一个course_cnt属性,就是用来计数的,记下每个学生选课课程数,因为每个学生是可以选多种不同的课的,用总成绩和来除这个计数的就可以得出平均成绩,还有一个TotalGrade属性就是该学生的总课程成绩和(还没有平均);同理,在课程类中也有这两个属性,另外还有total_Grade_a和total_Grade_b,这两个呢,分别是平时成绩和期末成绩的和,因为在本次大作业里,考试课的成绩输出是要求输出平时成绩和期末成绩的平均分的;下一个是课程成绩类,只有三个属性,平时成绩(Grade_a)、期末成绩(Grade_b)、总成绩(final_grade);最后就是选课类,选课类可以说是所有类中的核心类了,它可以处理每一次的选课的信息,意味着每一次的选课信息都可以在这得到处理,而不用各种复杂的类关系相互耦合,导致类复杂度很高,我的方法主要是有对成绩的处理,所以该类的两个方法是对成绩的相加,将每一次选课的成绩加到相应的类中,学生成绩,课程成绩...
3.我的圈复杂度分析:
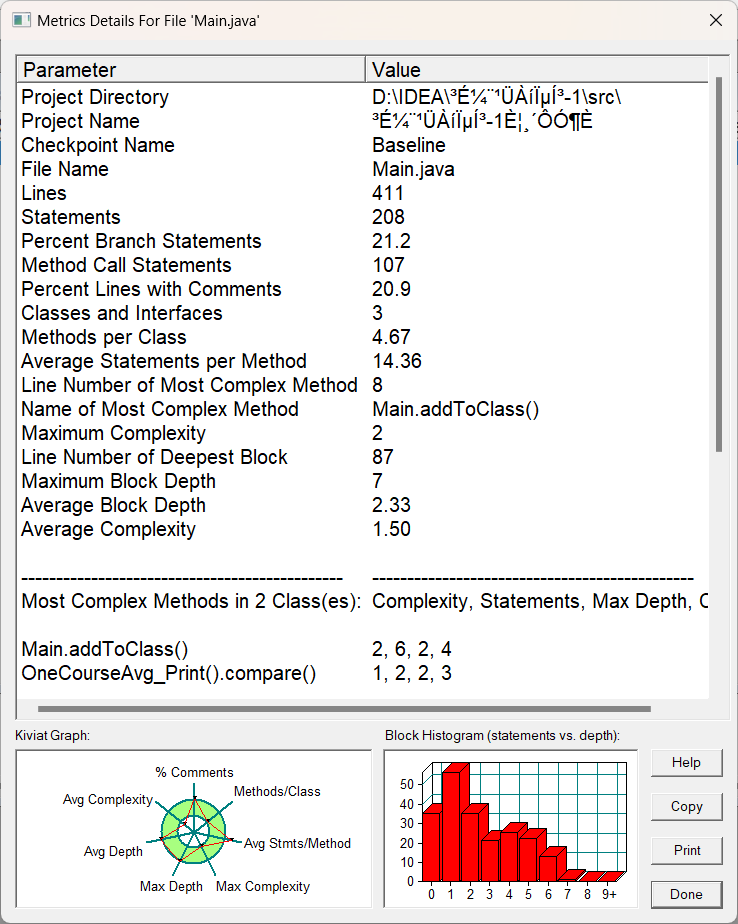
圈复杂度分析:首先看左下角的雷达图,整体的红线还是在绿色的圈里面的,说明类的设计还算可以,类的结构是可以的(老师设计的结构还是要多多学习的),Average Statements per Method: 平均每个类的方法行数是14.36,方法体还是有点超的,主要应该是那边的Judge类,每个的判断都严格的重复了流程,其实只是正则表达式的不同罢了,还能接受吧,再看Methods per Class:平均每个类里面四个方法,也还能接受,这次的类设计比较成功,其他的都还好,类设计真的是非常决定代码复杂度和代码量的东西,类设计的能力太可贵了。(只能到这了,圈复杂度的图真的不是很看的懂,感觉也没有一个指标,就是比较好的数据应该是怎样的,我只知道雷达图不超出绿圈就是比较好的类设计了)。
4.小总结:
第一次的成绩管理系统刚拿到题目还是比较懵逼的,会觉得无从下手,然后尝试了自己做类图分析,后面没想到老师会带着我们分析一遍,对比一下会发现,我自己的设计大多数关联关系,组合关系,每个类之间都会或多或少有耦合,不过学到的一个宝贵的经验就是当两个类之间相互关联时,可以提出第三个类,再同时关联另外两个类,如本次大作业的选课类,也比如上课讲的实际问题案例,汽车的控制器类,关联其他的相互关联的类,来减少类之间的耦合。当然,按给好的类图去写代码也碰到很多问题,主要还是选课类的理解偏差,选课类其实可以有两种理解,一种可以是理解为选课系统,里面包含了每次选课的信息,这样这个类的作用可以是拿到每次选课的内容;另一种理解是每次选课,记录的是每次选课的信息,而不是所有选课信息的汇总,这种理解的话,选课类就作为中间类的感觉,通过它将成绩信息处理后“加工”到其他类的属性里实现处理。正是开始的尝试都是走前面的一种理解,多次碰壁,始终碰到各种各样问题,后面换了理解,才有幸做完大部分测试点。
(2).成绩管理系统-2
1.总体分析:
成绩管理系统-2的迭代是添加了实验课的概念,实验课的成绩个数并不固定,单门实验课的总成绩等于各个成绩总和求平均,与考试课考察课的成绩计算方法还是有点区别的,原本的设计应该是成绩A类和成绩B类作为成绩类的子类继承,后面我删掉了子类,就只做了一个成绩类,实际效果是差不多,但是合理性方面还是不太对的,因此这个实验课的成绩处理我新建了一个实验课成绩类,按理说是同样继承成绩类,又是一种计算成绩的方法,更为合理。同样的与上一次,也需要错误的判断,是否符合格式要求等,其余并没有什么更新。
2.我的类图:
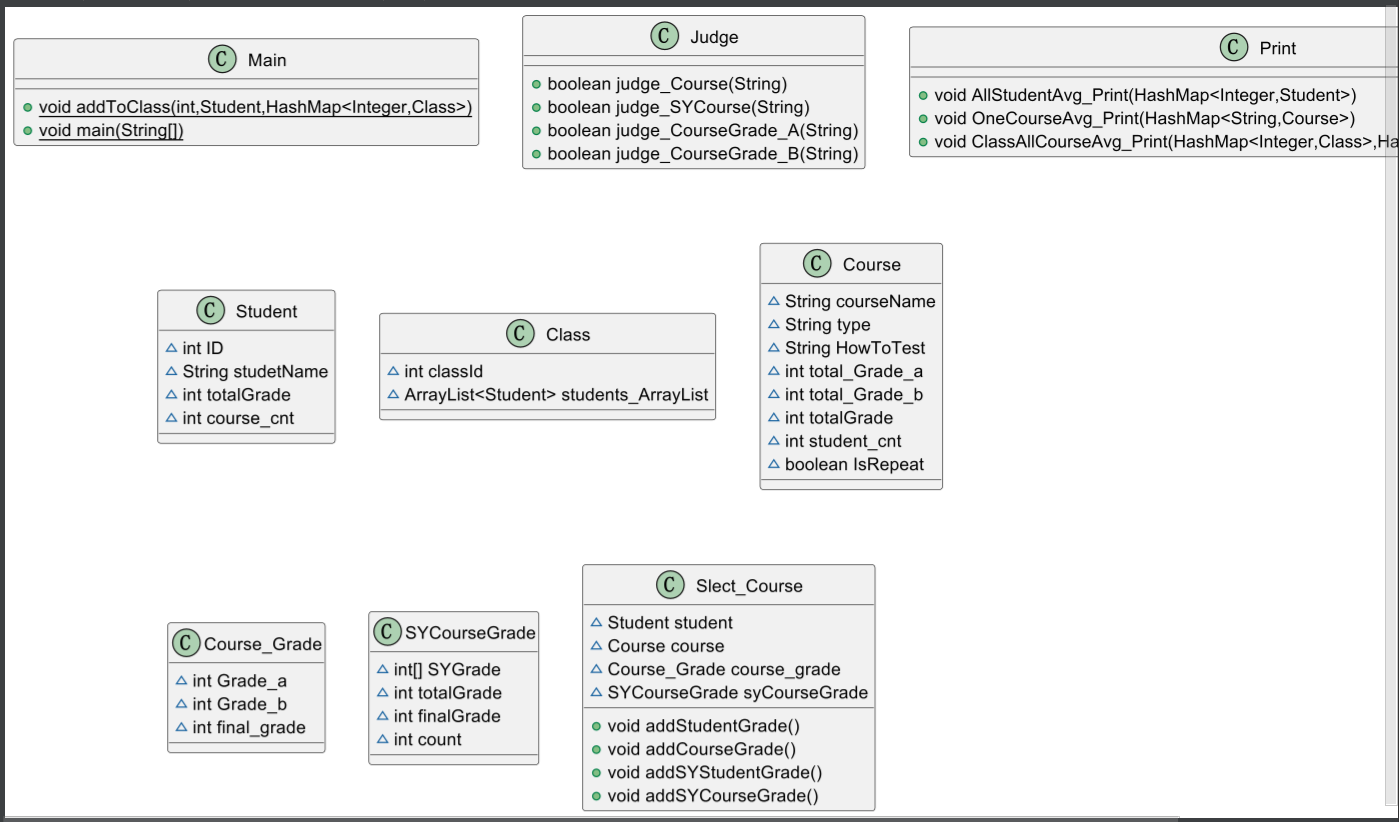
类图分析:在上述分析中已经提到了,新建了一个实验课成绩的类,就是计算成绩的功能,因此选课类同样要添加一个实验课成绩类的属性,用来将一门课程的成绩添加到总成绩中,最后计算平均成绩,当然Judge类中还要加入实验课的语句的输入是否满足格式,其他的类与成绩管理系统-1一样。
3.我的圈复杂度分析:
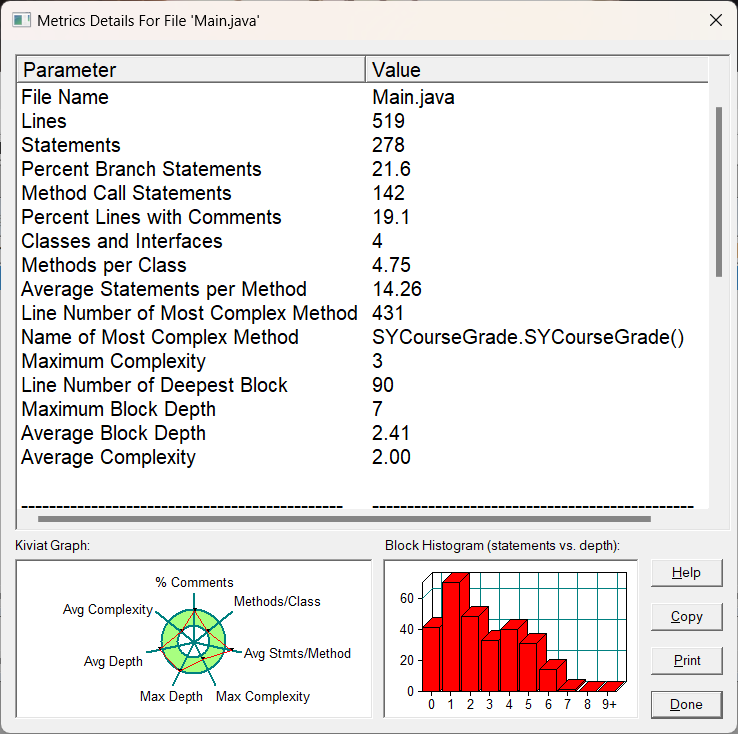
圈复杂度图分析:如图左下角的雷达图还是并没有超出绿色圆圈,主要原因还是本次迭代并没有很多的概念添加,类的结构还是那样,不会有什么大的变化,再看最后一行的平均复杂度是2.0,应该来说代码结构还是可以接受的,每个方法体的语句平均是14.26,比较一般,好的方法应该是足够简洁,因为每个方法分工明确,完成的任务职责是清晰明了的,其他数据如图就不做分析了。
4.小总结:
这次迭代有了第一次作业的经验,相比之下没什么困难了,没花多久时间就拿下了大部分的测试点,主要就是处理实验课成绩的计算,以及错误判断比较花点时间,其他都还好。
(3).成绩管理系统-3
1.总体分析:
成绩管理系统-3的迭代说句心里话感觉是没有创新的,就像迭代2一样,又是改变了计算成绩的方法,之前的成绩要么是有固定的占比,要么是总和的平均,只是这次又改成了自己输入加权平均,比例由输入来得到,再计算成绩,可是这样一改,整个输入输出就有大的变化,工作量大,像是在重新写一遍题目一样,这样子迭代的意义在哪里,又或者说是我没有理解到真正的意义在哪里。
2.我的类图:
类图分析:与上一次的类图没有区别,只是某些地方的属性和方法需要修改添加,比如多了一个占比的概念,如果不将它作为类来设计的话,肯定是作为属性的,可是作为属性来说又有些许不合理,因为考察类型的课是不存在占比这一说法的,而考试类型和实验类型的课是有的,像我放在课程类里,作为输入时添加到HashMap中,是一种偷懒的做法,存在不合理,但是却能解决问题,不得不想,一个问题的实际解决可以是多种多样的,也想到一句经常听过看过的话“程序能跑就行,有bug也不要紧”(不谈是否合理而言,只是解决当前问题),回到上述问题,其实可以联想到之前点菜系列的甜辣度的概念,当时也是作为了属性加到菜品的类中,也是不合理但能解决问题,当时的解决方法是设计一个甜辣度的类,里面有上下限的属性,通过关联关系来设计,才是比较合理的。
3.我的圈复杂度分析:
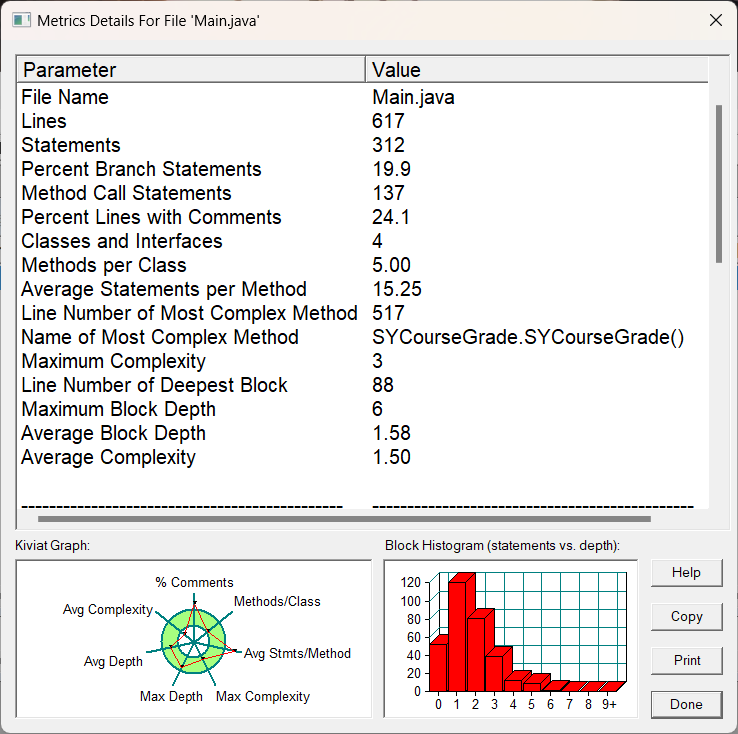
圈复杂度图分析:雷达图可以说明了很多问题,类设计开始出现了问题,超出了部分绿圈,正是上面类设计的偷懒导致的,数据会说明一切问题,数据不会说谎的。像其他的复杂度数据变化倒是不大,但也都有所增加,类的设计还是不能偷懒,是一个关键的过程,决定着代码的质量,像“程序能跑就行,有bug也没事”这种话,糊弄着听听就行了,真要想写出有质量的程序,还是得脚踏实地,一步一步走。
4.小总结:
这一次呢,说遗憾应该是对我来说不为过的,多种因素在,临近期末,为了复习并没有提前着手这次大作业,留在了考完考试的后一天,最后一天,最后一晚当卡在正则表达式的那一个小时里,感觉什么都来不及了,望着那一行行的 wrong format 发着呆,却没有什么办法,正则表达式的知识实在太陌生,即使听过了网课知识点,运用到实践中,总感觉这东西很好用,却怎么这么难写出来对应实例的正则表达式,随着倒计时的慢慢结束,我知道,我的大作业之旅落幕了,却是这样的烂尾收尾,我甚至想,如果延长一天到周日结束该多好,周日一天都没什么事,就一天就好,可惜没那么多如果,下次再注意吧。还有要把正则表达式弄会。
三、踩坑分析
踩坑1:
关于HashMap的排序问题:
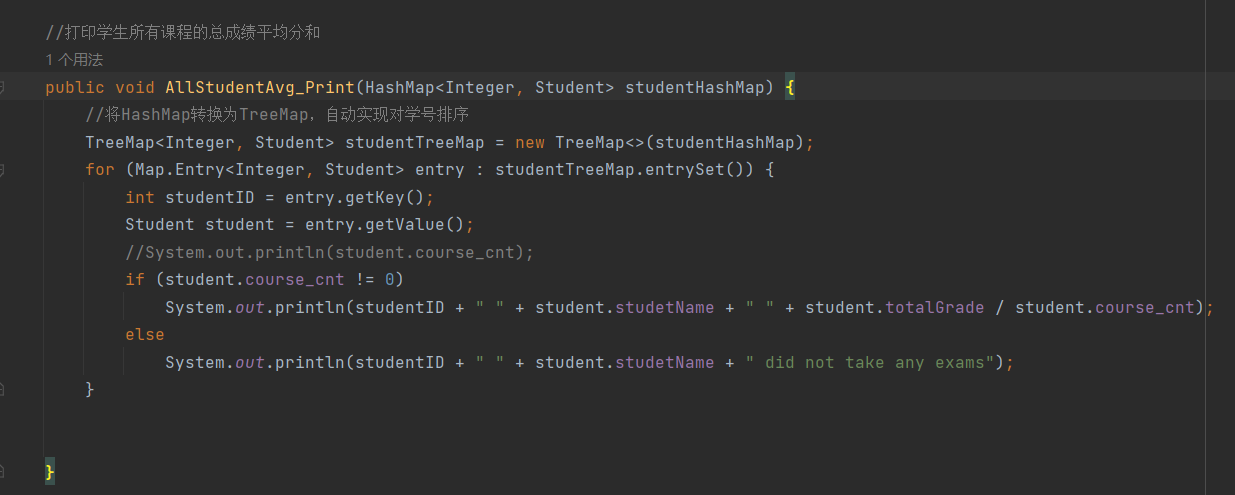
如上图,当需要对学生的成绩的时候是要对Students的Map进行按学号排序的,而且是按升序顺序,因此就可以采用将HasMap转化成TreeMap来排序,高效便捷,而不用自己去写一套排序规则,挺好的一个方法,利用已有的数据结构TreeMap,解决问题。
踩坑2:
同样是排序问题,只是不同的排序

上图方法,是在打印每个课程的总成绩平均分,与打印学生成绩信息有点不同,课程成绩需要对课程名称按字母表顺序排序,TreeMap是做不到的,那这边用到的就是通过将HashMap转化为ArrayList再实现Comparable接口,重写compare的方法,来实现对不同需求的排序,如图是对两个Map相互排序,那么括号内参数就是两个HasMap<String,Course>,排序完后再打印输出即可。
踩坑3:
重复成绩信息的处理

有这么一个测试点,当输入重复的成绩信息,应该忽略后面的信息,保留最开始的信息,刚开始我的处理是通过直接countinue处理,发现是不行的,所以想到每个课程的课程成绩都是独一无二的,想到在课程类里面加入一个boolean属性,判断到完全一样的成绩信息时候,将这个boolean值赋值为true即可,再判断这个boolean,是true再countinue,停止本次的输入,这样就可以处理重复的成绩信息了。
四、主要困难及改进意见
主要困难:
1.第一不得不提的当然就是正则表达式这东西,说起来奇妙,网课的东西听也听了,就是很难写出实例的正则表达式,只能说能力不够,继续加强吧。
2.代码实现能力。比如明知是用HashMap解决问题,却没有能力很快的去实现,知识点相对薄弱,还有排序方面的算法,ArrayList的排序和Map的排序,多种多样,HashMap还可以转化成TreeMap进行排序,也可以转换成ArrayList排序……
改进意见:
1.还是要多拓展自己的知识面,语法基础知识不能忽视;
2.代码不能停,争取每天都敲点代码;
五、总结
整体而言来说,这次成绩管理系统的系列比起菜单好太多了,起码开头没有很难,但是最后一次的作业是所有大作业里分最低的,还是挺难受的,算是留下了一个不好的结局,烂尾的感觉…聊聊大作业收获,这三次大作业让我深深体会到HashMap的好处,在合适的时候用上合适的数据结构,是一件事半功倍的事情,可见一方面知识面广的重要性,另一方面,应该有意识意识到在怎么样的场景下用怎么样的数据结构,用怎样的方法技巧,这次是有提示用HashMap,如果没有提示,也应该做到想到用合适的数据结构去实现。至此,所有的大作业就结束了,起码这个学期不用了,说来奇妙,从最开始的很害怕,听到要发大作业了的时候,心中全是忐忑,很担心发了我还是写不来,一点都不想看到大作业,因为很困难完成它,再到如果再摆烂下去就挂科的边缘了,下定决心一定要做下来某次的大作业,再到不容易的完成,那是一次自我意识的升级,再就不害怕大作业,不过是一点点小问题,克服了心里的障碍,会认识到其实大作业也没什么,只要多想想多敲敲,“船到桥头自然直,车到山前必有路”,我相信,在以后的碰到问题的时候,想到这个学期的大作业经历,也不会想着放弃,而是坚持一下,挑战一下自己,总会过去的。