Wild Patterns: Ten Years After the Rise of Adversarial Machine Learning reading
- 攻击目标
- 安全破坏
- 完整性破坏: 逃避检测,而不影响正常的系统运行
- 可用性破坏: 使得合法用户不能正常使用系统
- 隐私性破坏: 通过逆向工程获得系统,用户和数据的相关信息
- 攻击的针对性: 针对特定的样本集,还是任意样本并引发分类错误
- 错误的针对性: 造成针对性的错误(比如针对地将?分类成?)和普遍的错误(把?不分类成?)
- 安全破坏
此论文关于对抗机器学习样本的综述
introduction
关于对抗机器学习的一些误解:
- 对抗机器学习早于深度学习对抗样本
主要有以下三方面发展
- 机器学习攻击:下毒和逃避(training and testing)
- 提出一些对抗对抗攻击的系统评估方法
- 设计一些抵抗对抗攻击的机制
我们研究了过去十年或更早的对抗机器学习,从早期的安全非深度学习算法到最近更多关注到的深度学习的安全属性。我们的目标是将这些明显不同的工作路线联系起来,同时也强调与学习算法的安全评估有关的常见误解。
我们的讲述可描述为三个比喻,
- 了解对手: 对对手进行威胁建模
- 主动攻击: 了解对手的攻击手段
- 保护自己: 如何使用不同保护机制保护自己
Arms Race and Security by Design
道高一尺,魔高一丈。我们用垃圾邮件进行军备竞赛的举例。
第一阶段,防守方通过规则过滤和文本分类进行垃圾邮件检测,攻击方则通过词汇替换,比如讲一些可疑词汇拼写错误,并且加入一些好词汇
第二阶段,攻击方使用图片进行垃圾邮件传播,防守方开始使用ocr等技术
第三阶段,攻击方对图片增加扰动,防守方使用低级视觉特征进行防护。
所有个阶段可以用下图概括
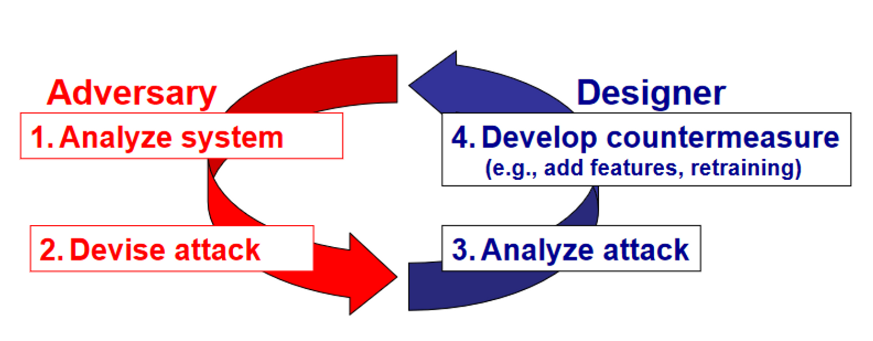
此所谓道高一尺魔高一丈。
但被动式的防御不能解决一些为见过的攻击方式。因此需要防守方对攻击进行更多的模拟,并且提出针对此攻击的防御。那么,攻击方一般怎样攻击呢,请看下面一个章节
Know Your Adversary: Modelling Threats
“If you know the enemy and know yourself, you need not fear the result of a hundred battles.” — Sun Tzu, The Art of War, 500 BC
在攻击方时,对抗样本分为训练投毒和测试逃避。然后防御方利用时,又叫对抗性训练和测试样本。它包括 定义攻击者的目标,对目标系统的了解 ,以及操纵输入数据的能力,随后定义一个与最佳攻击策略相对应的优化问题。
-
攻击目标
- 安全破坏
- 完整性破坏: 逃避检测,而不影响正常的系统运行
- 可用性破坏: 使得合法用户不能正常使用系统
- 隐私性破坏: 通过逆向工程获得系统,用户和数据的相关信息
- 攻击的针对性: 针对特定的样本集,还是任意样本并引发分类错误
- 错误的针对性: 造成针对性的错误(比如针对地将?分类成?)和普遍的错误(把?不分类成?)
- 安全破坏
-
攻击者对目标系统的了解程度
包括四个层次知识: 训练数据 特征集(理解这个很玄学) 学习算法和目标函数 网络参数
- 白盒模型: 知道所有信息,可以作为对抗攻击下的系统可能产生的性能下降的上界
- 灰盒模型: 经典地,知道特征集和学习算法的种类(线性,网络架构),但是既不知道训练数据也不知道模型参数。但是可以拥有相同源的不同数据,并根据目标模型的反馈生成替代模型。这种情况下,攻击者在替代模型中进行攻击并将攻击转移到目标模型上。
- 黑盒模型: 啥都不知道,但知道一点。比如模型的反馈和特征的种类。比如动物分类模型输入的特征是图片像素,并且知道哪些改变可以引起模型中特征的改变。可以看原论文关于恶意代码检测的举例。可以使用代理分类器完成这一攻击。尽管在最小化查询次数的同时学习一个代理模型的问题可以被视为一个主动学习问题,但据我们所知,成熟的主动学习算法还没有与最近提出的这些方法进行过比较(机翻的,我的理解是,主动学习算法还没在对抗攻击下测试,有空看看原文的引用)。
-
攻击者的能力
主要体现在攻击者对输入数据的修改能力上
- 攻击影响: 因果性: 可以操纵训练和测试数据,探索性: 只操作测试数据。又分别叫做投毒和逃避攻击
- 数据操作限制: 攻击者对数据的修改操作要限制在一个范围内。拿恶意代码举例,攻击者必须要修改一个恶意代码来逃避静态检测,同时也要维持恶意代码的功能。有时特征也会约束输入,比如某个特征依据某个操作码进行递增,那么攻击者需要在编写的代码里注意这一点
-
攻击策略
使得攻击者在已有的知识和一系列攻击样本的基础上,使得攻击效果最大化。
-
安全评估策略
我们不仅要评估算法在不同知识假设下的性能,同时也要观察算法对不同攻击强度的鲁棒性。例如,这可以通过增加用于制作规避攻击的扰动量,或增加注入训练数据的中毒攻击点的数量来实现。
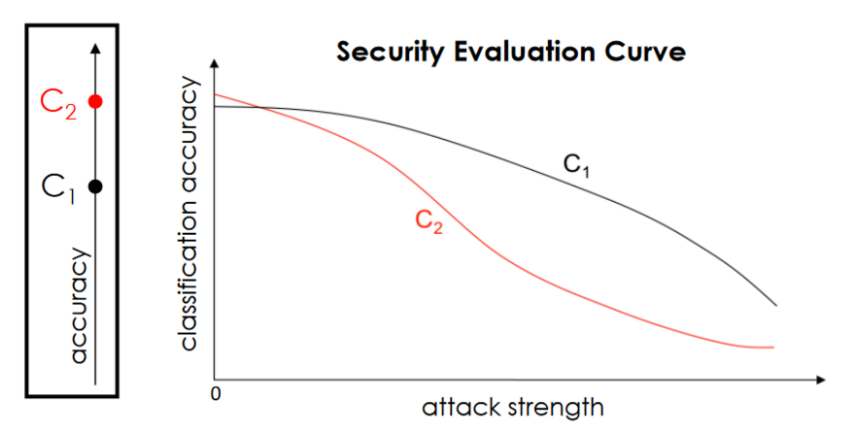
比如上图,在最开始我们可能倾向于C_2, 但是依照攻击强度,我们会更倾向于C_1。
- 针对机器学习的攻击总结
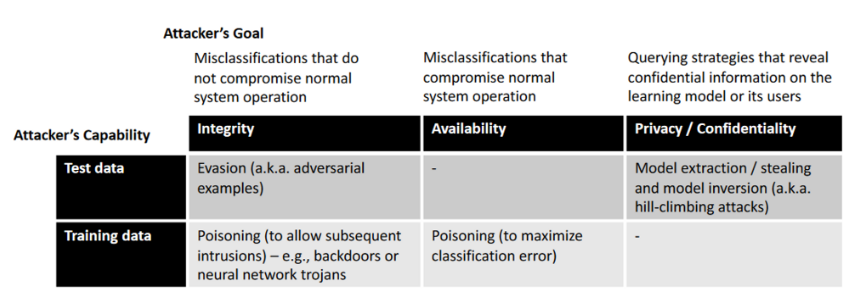
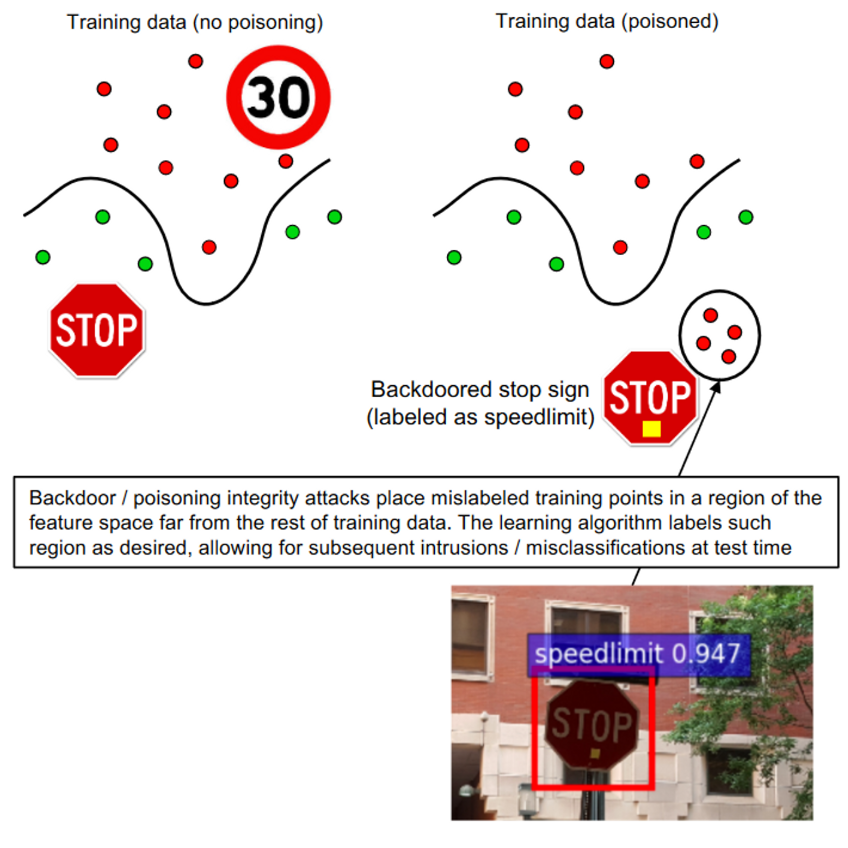
我们在上图中提供了基于上述威胁模型的针对机器学习算法的主要攻击的简化分类方法。最常见的攻击包括规避和中毒可用性攻击。最近,针对深度网络的不同种类的中毒完整性攻击(操纵训练数据或训练模型以导致特定的错误分类,也叫后门和木马攻击。这些攻击恶意地操纵预先训练好的网络模型,以创造特定的后门漏洞。然后,被破坏的模型被公开发布,以有利于它们在专有系统中的采用(例如,通过微调或其他转移学习技术)。当这种情况发生时,攻击者可以使用被错误分类为所需的特定输入样本来激活后门,比如下图。当知识有限时,如在灰盒和黑盒的情况下,可以发动隐私或保密攻击,以获得关于目标分类器或其用户的进一步知识。
Be Proactive: Simulating Attacks
“To know your enemy, you must become your enemy.” —Sun Tzu, The Art of War, 500 BC
逃避攻击
逃避攻击指在于操作输入数据来逃避分类器在测试时的检测。逃避攻击可以被分为通用错误攻击和特例错误攻击。
- 通用攻击的目标是,使得对抗样本能够让原本的例子分类到最近的类别中(原本是 \(k\) ,分类到特征空间最近的 \(l\))
- 特列错误攻击指在使得对抗样本能够被分类成 \(k\)同时远离最近的 \(l\).
同时该攻击受到约束
第一个约束体现在dense or sparse evasion attacks上。使用L2或者L8范式时,多个异常值的影响小,异常值体现在整个输入数据但是很轻微。使用L1时,只有几个异常值影响就会很大,所以异常值体现在局部。
第二个约束举例来讲。图片的输入为0~255,或者被其他因素制约。
剩下有一些论文综述性质的描述,可以看看原论文。有个强调的点是,对抗样本被误解为必须小范围被扰动。但是在评估模型性能时,应该攻击增强攻击强度,观察模型的性能。
投毒攻击
中毒攻击旨在通过在训练数据中注入一小部分中毒样本来增加测试时的错误分类样本数量。同理,投毒攻击也分为通用错误攻击和特例错误攻击。
- 通用错误的目标是增大为污染数据的损失
- 特例错误的目标是使得未污染目标倾向于分为某类,使得分为此类的损失最小化。
值得一提的是,针对机器学习的中毒攻击不应视为理论上的讨论。社会上发生过许多的投毒攻击。感兴趣可以读读原文提到的新闻链接。比如医药企业向训练数据中投入假阳数据,或者在公共数据集中投入毒,ImagNet或者联邦学习就是很好的例子。
Protect Yourself: Security Measures for Learning Algorithms
“What is the rule? The rule is protect yourself at all times.” —from the movie Million dollar baby, 2004
如何对过去的攻击作出反应并防止未来的攻击。
被动防御
被动防御的目的是对抗过去的攻击。需要以下几点要求
- 即时检测到新型攻击
- 经常将分类器重新训练
- 根据训练数据和真实标签验证分类器决策的一致性
其中,检测新型攻击可以使用协同方法(collaborative approaches)和蜜罐(honeypots)。
协同方法指的是多个实体或组织之间的合作,共同应对网络安全威胁和攻击。这些实体可以是不同的组织、安全团队、研究机构或个人,他们通过共享信息、资源和经验,相互合作来检测、防御和对抗网络攻击。协同方法的目标是通过集体智慧和资源的整合,提高整个生态系统对安全威胁的识别和响应能力。
蜜罐是一种安全机制,旨在吸引和诱捕攻击者,并在受控的环境中收集攻击行为的信息。蜜罐通常被部署在网络中,被设计成看似易受攻击的目标,以吸引攻击者对其进行攻击。当攻击者尝试入侵或攻击蜜罐时,安全团队可以获得有关攻击者的信息,如攻击技术、工具、漏洞利用等。这些信息对于分析和理解攻击者行为、发现新的安全威胁和改进防御措施非常有价值。
此外模型经常更新应对新收集的攻击。最后模型的正确性应由专家判断
主动防御
主动防御的目的是防止未来的攻击。迄今为止提出的主要防御措施可以根据设计安全和隐蔽性安全的范式进行分类。
针对白盒攻击的安全设计防御措施
-
针对逃避攻击
- 利用博弈论学习不变的变换。(这个没看懂,可以看看相关的引用)
- 鲁棒性优化,使用调整loss,一个有趣的领域是添加正则项los
- 异常检测,许多机器学习算法基于的稳定性假设的一个简单推论(根据该假设,训练和测试数据来自同一分布),而基于拒绝的防御策略旨在克服这个问题。
- 模型集成
值得注意的是,涉及对攻击样本和拒绝机制进行再训练的防御措施通过本质上反击盲点(blind spot)攻击来实现对逃避的安全。这在对抗坏样本和好样本之间是一个取舍。
针对于深度学习算法,在深度卷积网络的情况下,大部分问题来自于从输入空间到深度空间的学习映射(即特征表示)违反了学习算法的平滑性假设:在输入空间很近的样本在深度空间可能很远。对于足够高的对抗性输入扰动,深度空间中的对抗性样本与其他类的训练样本变得无法区分。因此,这个漏洞只能通过重新训练或重新设计网络的更深层(而不仅仅是最后一层)来修补。
tips:添加噪声的余量很重要
-
针对投毒攻击
要在训练期间破坏学习算法,攻击必须表现出与其他训练数据所显示的不同特征(否则根本不会有任何影响)。因此中毒攻击可以被视为异常值,并使用数据消毒(即攻击检测和清除)来对抗。
针对黑盒攻击的逐一安全防御措施
主要是防止向攻击者透露信息。
一些例子包括: (i)随机收集训练数据(在不同的时间和地点收集);(ii)使用难以逆向设计的分类器(如分类器集合);(iii)拒绝访问实际的分类器或训练数据;以及(iv)随机化分类器的输出,给攻击者不完美的反馈。值得注意的是,逐个安全的防御措施可能并不总是有用的。梯度掩蔽已经被提出来,以隐藏用于制作对抗性例子的梯度方向,但是已经被证明,它可以很容易地被代理学习者规避。
Conclusions and Future Work
本文中,我们对与机器学习、模式识别和深度神经网络的安全性相关的工作进行了全面的概述,目的是提供一个更清晰的历史图景,以及如何评估和改善其安全性以抵御对抗性攻击的有用指南。在这项工作的最后,我们讨论了一些未来的研究路径,这是因为机器学习最初是为封闭世界的问题而开发的,在这些问题中,一个理性的代理人可能的 "自然状态 "和 "行动 "是完全已知的。用唐纳德-拉姆斯菲尔德(Donald Rumsfeld)的一次著名演讲的话来说,人们可以说机器学习可以处理已知的未知问题。不幸的是,对抗性机器学习经常处理未知的未知问题。当学习系统被部署在开放世界的对抗性环境中时,它们可能会错误地分类(以高置信度)从未见过的、与已知训练数不相同的输入。我们知道,在许多安全问题中,未知的未知因素是真正的威胁(例如,计算机安全中的零日攻击)。尽管它们可以用本工作中描述的主动方法来缓解,但它们仍然是对抗性机器学习的主要开放问题,因为对攻击的建模依赖于已知的未知因素,而未知的未知因素是不可预测的。
我们坚信,应该探索新的研究路径来解决这个基本问题,对形式验证和可认证防御进行补充。机器学习算法应该能够使用强大的异常或新奇检测方法来检测未知的未知因素,在需要时可能会要求人类干预。开发解释、可视化和解读机器学习系统运行的实用方法,也可以帮助系统设计者调查这类系统在训练数据无法统计的情况下的行为,并决定是否相信他们在这类未知的未知事物上的决定。这些未来的研究路径位于对抗性机器学习领域和新兴的鲁棒性人工智能和机器学习的可解释性领域的交汇处[124, 125]。我们相信,这些方向将有助于我们的社会对现代数据驱动的机器学习技术的潜力和局限性有一个更清醒的认识。
这篇文章虽然是2018年的,但对于对抗训练的基础补充是非常有益的。其中特别是英语的写作,徐徐道来,非常易懂,建议看看原文。
- Adversarial Patterns Learning Machine readingadversarial patterns learning machine patterns machine pretty state adversarial resistant learning towards reinforcement adversarial learning through learning机器machine clustering algorithm learning machine collaboration differential learning machine learning project machine eecs learning machine bigdataaiml-ml-models bigdataaiml learning machine python in