准备开一个【每周一读】栏目,分享任何有意思的文章,不定时更新。
原文?:https://towardsdatascience.com/real-time-llm-hallucination-detection-9a68bb292698
原文作者:Iulia Brezeanu
1 什么是LLM Hallucination
在阅读文章前,我问了ChatGPT一个问题:什么是LLM Hallucination?它是这么回答我的:
LLM Hallucination 是指语言模型偏离现实或引入不真实信息的现象。LLM 是指大型语言模型,如 GPT 系列模型。
在生成文本的过程中,LLM 偶尔会生成与事实不符或不合逻辑的内容,即所谓的“幻觉”(hallucination)。这可能是由于模型在学习文本数据时所接触到的信息中存在错误、歧义或不一致性,导致模型生成的文本不符合真实世界的逻辑或事实。
这种现象可能表现为生成的文本包含:
虚假信息: 模型生成的内容与真实情况不符,包括事实错误或者未经证实的信息。
逻辑错误: 文本中的论点、事件顺序或因果关系出现不合理的情况,与常识相悖。
不连贯的内容: 模型生成的文本可能在逻辑上不连贯或缺乏统一性。
原文作者lulia也问了ChatGPT一个问题:Who is Evelyn Hartwell?
ChatGPT给了几个不同的答案,而实际上Evelyn Hartwell不属于回答中的任何一个身份,“她”根本不存在——这就是hallucination了。
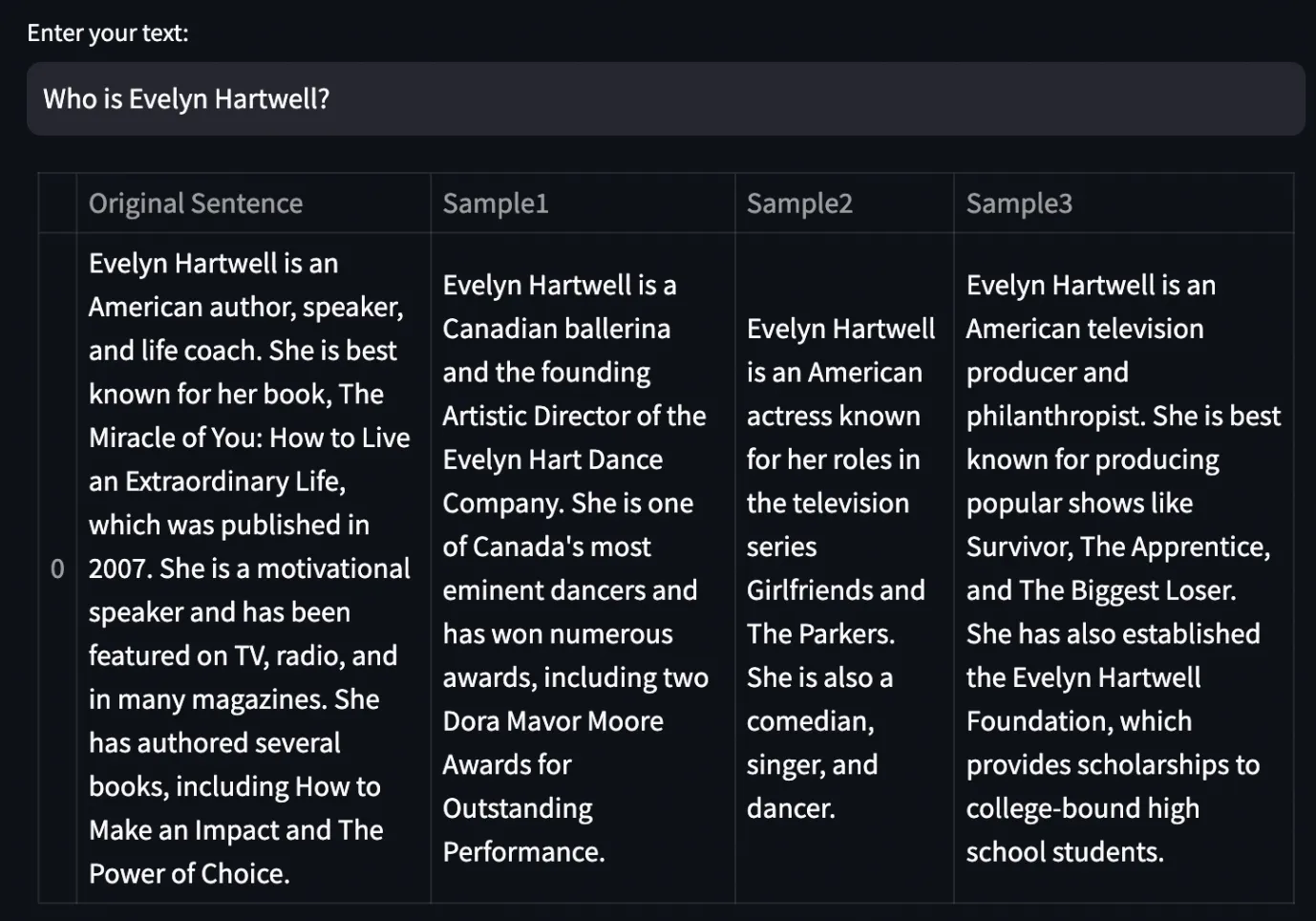
可是,我们怎么分辨何时模型输出的是真实准确的答案,何时是在胡言乱语呢?难道每一次我们都需要手动检查一下吗?
2 如何检测“幻觉”
在语言模型中,有一个用于调节生成文本多样性的参数temperature,取值范围在 0 到 1 之间,较高的值会增加模型输出的多样性,而较低的值会减少多样性,使得生成的文本更加可控。
lulia设置了一个较高的值0.7,期待模型每次输出不一样的文本。如果不存在“幻觉”,那么输出间的差异应该只是语义上而不是事实上的,即生成文本在句子结构、表达方式等方面存在多样性,但事实内容基本一致。
SelfCheckGPT也这么想:如果模型对同一prompt的输出相互矛盾,很可能是幻觉;如果输出相互依赖,那么信息很可能是真实的。这种基于样本的幻觉检测机制不需要任何外部知识,只需要LLM的文本输出(原始输出和样本输出),因此也被称为zero-resource黑盒评估。
评估输出间相似性的方法很简单,我们为LLM对同一prompt的文本输出生成embedding,然后利用pairwise_cos_sim函数计算所有句子对的平均余弦相似度。余弦值越接近1,就说明向量越接近,相似度越高。
from sentence_transformers.util import pairwise_cos_sim
from sentence_transformers import SentenceTransformer
def get_cos_sim(output,sampled_passages):
model = SentenceTransformer('all-MiniLM-L6-v2')
sentence_embeddings = model.encode(output).reshape(1, -1)
sample1_embeddings = model.encode(sampled_passages[0]).reshape(1, -1)
sample2_embeddings = model.encode(sampled_passages[1]).reshape(1, -1)
sample3_embeddings = model.encode(sampled_passages[2]).reshape(1, -1)
cos_sim_with_sample1 = pairwise_cos_sim(
sentence_embeddings, sample1_embeddings
)
cos_sim_with_sample2 = pairwise_cos_sim(
sentence_embeddings, sample2_embeddings
)
cos_sim_with_sample3 = pairwise_cos_sim(
sentence_embeddings, sample3_embeddings
)
cos_sim_mean = (cos_sim_with_sample1 + cos_sim_with_sample2 + cos_sim_with_sample3) / 3
cos_sim_mean = cos_sim_mean.item()
return round(cos_sim_mean,2)lulia做了两个小实验,对于“幻觉”输出的余弦相似度均值是0.52,而有效输出的均值是0.93。此外,余弦相似度的计算过程耗时很短(0.21秒)。看来这个方法很有效!
3 SelfCheckGPT中的一些检测方法
3.1 BERTScore
BERTScore也基于成对余弦相似度的想法。
常见的自然语言生成评估方法,如BLEU计算候选句与参考句之间的n-gram重叠数来衡量机器翻译的质量,却忽视了同义词汇和句子成分多样性的影响。单词的含义更有可能是由它的上下文决定的:在不同语境下,同一个单词表达的意思可能也会不同,比如“苹果”电脑/吃“苹果”,两处“苹果”的含义完全不同;不同单词也可能会表达同样的意思,比如“喜欢”学习/“享受”学习,词汇不同但语义接近。
因此,BERTScore用基于上下文的embedding来计算余弦相似度,与静态embedding不同,它考虑了单词的上下文。生成上下文embedding的默认tokenizer是RobertaTokenizer。
def get_bertscore(output, sampled_passages):
# spacy sentence tokenization
sentences = [sent.text.strip() for sent in nlp(output).sents]
selfcheck_bertscore = SelfCheckBERTScore(rescale_with_baseline=True)
sent_scores_bertscore = selfcheck_bertscore.predict(
sentences = sentences, # list of sentences
sampled_passages = sampled_passages, # list of sampled passages
)
df = pd.DataFrame({
'Sentence Number': range(1, len(sent_scores_bertscore) + 1),
'Hallucination Score': sent_scores_bertscore
})
return df我们没有将完整的原始输出作为参数传递,而是将其分成单独的句子。这个步骤很重要,因为selfcheck_bertscore.predict函数会计算原始回复中每个句子与样本中每个句子之间的BERTScore。
['Evelyn Hartwell is an American author, speaker, and life coach.',
'She is best known for her book, The Miracle of You: How to Live an Extraordinary Life, which was published in 2007.',
'She is a motivational speaker and has been featured on TV, radio, and in many magazines.',
'She has authored several books, including How to Make an Impact and The Power of Choice.']首先创建一个数组,其行数等于原始输出中的句子数,列数等于样本数。
array([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])用于计算BERTScore的是17层的RoBERTa large模型,对于原始输出中的每一个句子[r1, r2, r3, r4],都分别计算它和样本1中每个句子[c1, c2]的F1 BERTScore。

我们通过基线张量b来进行基线缩放,这让BERTScore可读性更强。基线张量是使用 Common Crawl 单语数据集中的一百万个随机配对句子计算得到的,对每个配对句子计算 BERTScore并取平均值。随机配对句子之间的语义重叠很少,因此这个基线代表着一个下限。
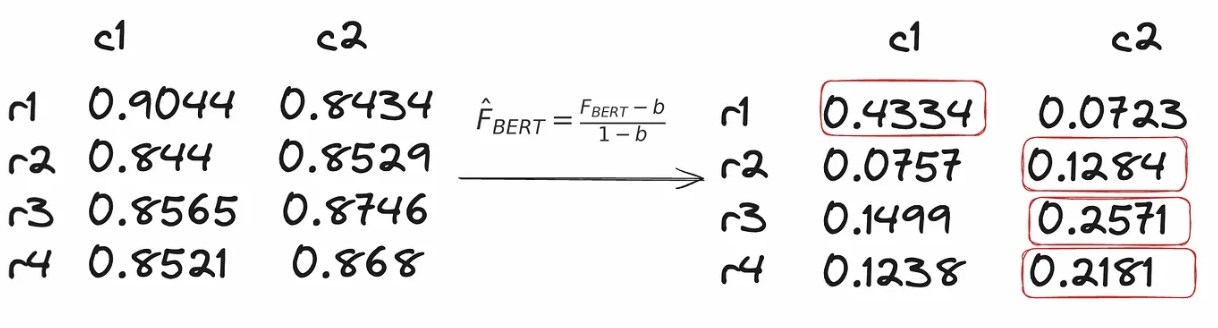
我们保留原始回复中每个句子与每个抽取样本中最相似句子的 BERTScore,也就是取最大的分数。这种方法利用样本之间的一致性来判断信息的可信度。如果某个信息在多个样本中反复出现,就更有可能是真实的,而只出现在一个样本中的信息可能更有可能是LLM“幻觉”。
对样本2和样本3重复上述步骤,得到的数组如下:
array([[0.43343216, 0.34562832, 0.65371764],
[0.12838356, 0.28202596, 0.2576825 ],
[0.2571277 , 0.48610589, 0.2253703 ],
[0.21805632, 0.34698656, 0.28309497]])我们计算每行的平均值,这是原始回复中每个句子与后续样本之间的相似度分数;每个句子的幻觉分数则通过1 - 上述值来获得。
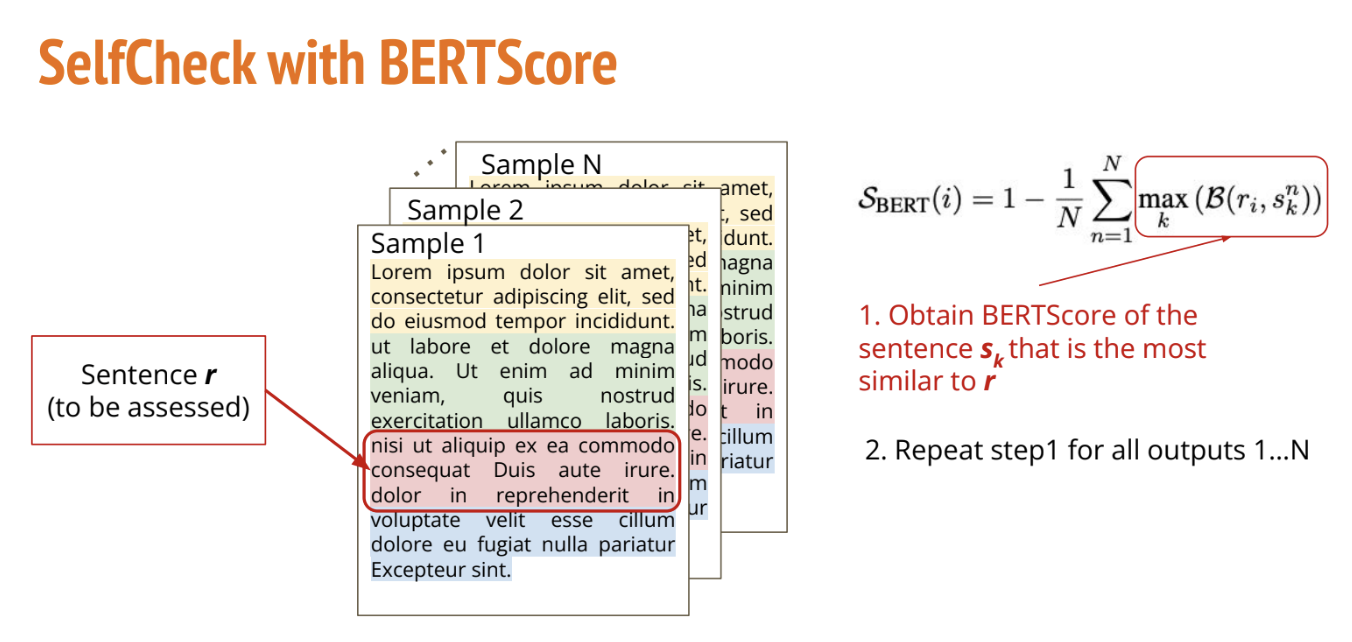
实验发现,有效输出的幻觉分数很低([0.0265, 0.3829, 0.5329]),而编造输出的幻觉分数很高([0.5224, 0.7773, 0.6771, 0.7173])。但是,计算BERTScore的过程非常耗时(13.09秒),并不利于实时幻觉检测。
3.2 NLI
自然语言推理(Natural Language Inference,NLI)是指根据自然语言文本之间的逻辑关系和语义关联性,进行理解和推理的过程。通常包括三种基本关系:
-
蕴含关系(Entailment): 如果一个文本(称为前提)包含了另一个文本(称为假设)的信息,则可以说前提蕴含了假设,前提为真时假设也必然为真。例如,“猫在跳舞”蕴含了“有动物在活动”。
-
矛盾关系(Contradiction): 如果两个文本之间的信息互相矛盾,即它们之间存在逻辑上的不一致性,那么可以说它们是矛盾的。例如,“猫在睡觉”和“猫在玩耍”是矛盾的。
-
中立关系(Neutral): 如果两个文本之间既不蕴含也不矛盾,那么它们可能是中立的,即彼此之间没有明显的逻辑联系。例如,“猫喜欢睡觉”和“狗喜欢玩耍”是中立的。
SelfCheckGPT利用在MNLI数据集上微调的DeBERTa-v3-large模型来执行NLI任务。NLI分类器的输入通常是“前提-假设”对,我们的方法则是“样本输出-原始输出句子”对,并且仅考虑“蕴涵”和“矛盾”类别logits(分别表示为ze和zc),用P_contradict = exp(zc)/(exp(ze) + exp(zc))的均值来计算原始输出中每个句子ri的NLI分数。
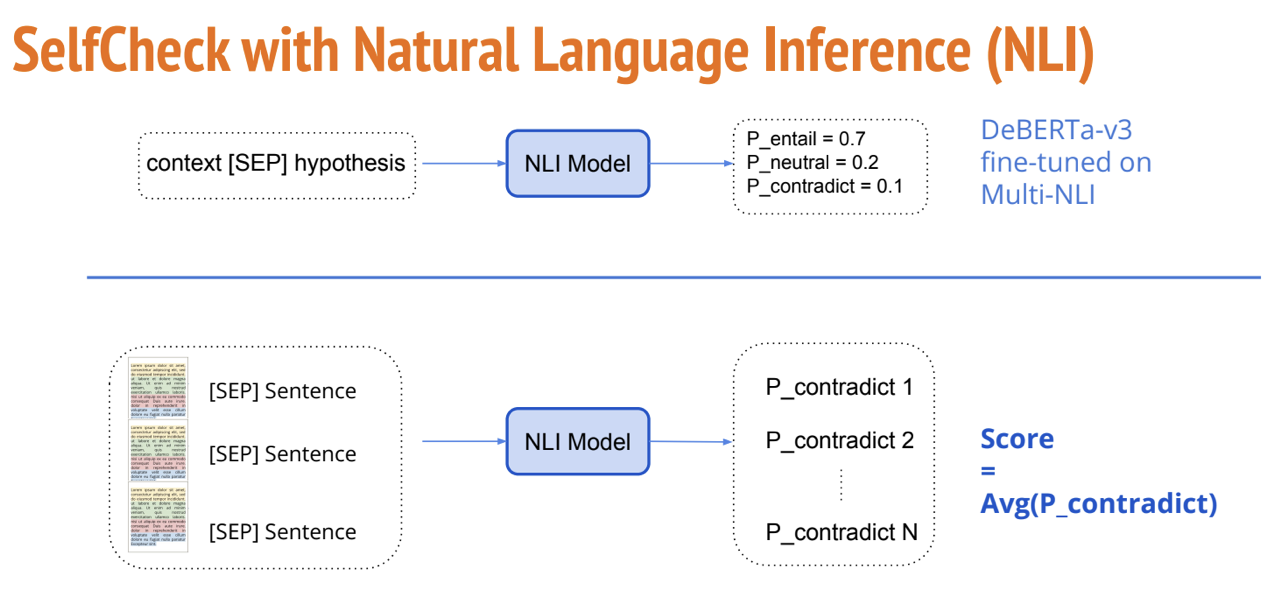
我们首先计算原始输出中第一句r1的NLI分数:
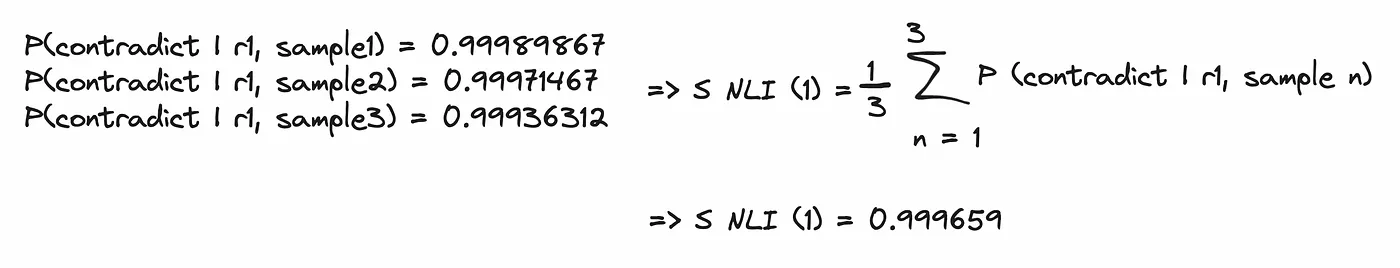
重复上述步骤,为原始输出中的四个句子都计算NLI分数,得到的结果是[0.9997, 0.9994, 0.9930, 0.9859],这是一个极高的NLI矛盾分数!而有效输出的NLI矛盾分数为[0.0009, 0.0206, 0.2385]。可见这个方法也很有效,但同样耗时(12.27秒)。
3.3 Prompt
较新的方法已经不再用公式去计算一个分数,而是用LLM本身来评估生成的文本。我们直接把原始输出中的句子和样本输出一起发送到gpt-3.5-turbo模型,它将决定原始输出与其他三个样本输出间的一致性。模型的输出会被映射成不同的分数:{Yes: 1.0, No: 0.0, N/A: 0.5},反映了原句与样本的相似程度。
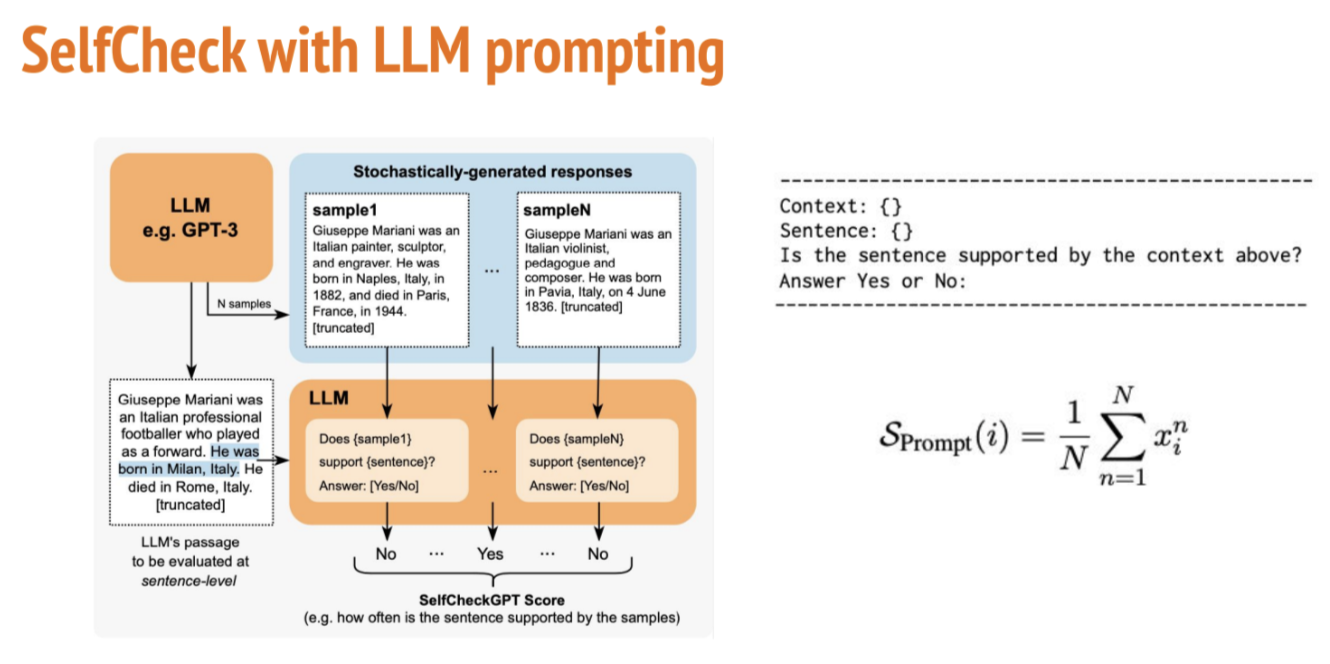
实验得出,Evelyn Hartwel幻觉输出的LLM自相似性分数为0,而有效输出的得分为0.95。这个方法有效且耗时很短(0.63秒),似乎是我们案例的最佳解决方案。而SelfCheckGPT原文也这么认为,Prompt的表现明显优于所有其他方法,NLI是表现第二好的方法。
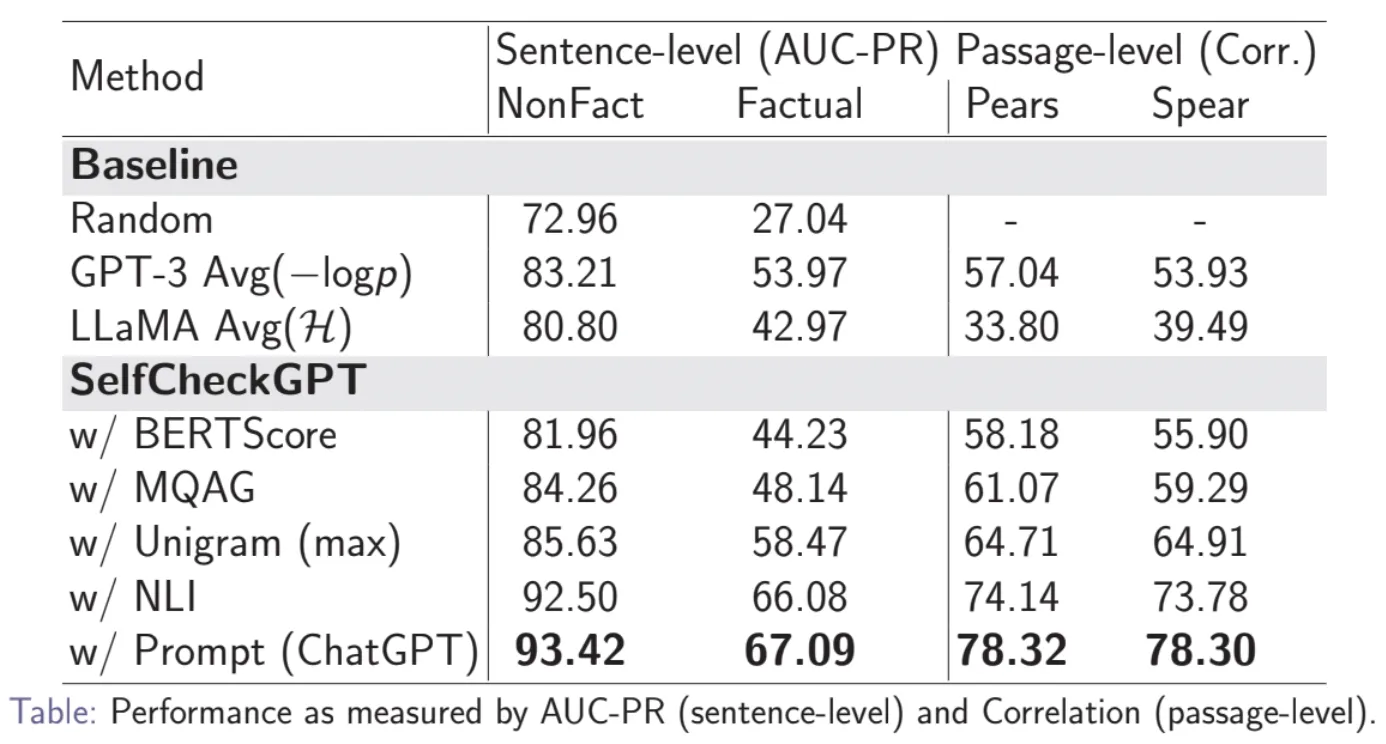
AUC-PR指“精确率-召回率”曲线下的区域面积,是评估分类模型的指标。AUC-PR数值越高,表示分类器在各种召回率水平下的平均精确率越高,即分类器性能越好。
4 数据和标注
评估数据集是用WikiBio数据集和GPT-3生成的维基百科风格的文章。为避免模糊概念,从前20%的最长文章中随机抽取238个文章主题,提示GPT-3以维基百科风格为每个概念生成第一段内容。
接下来,在句子层面为这些生成的文章进行事实性手动注释,每个句子被标记为“重大不准确”、“轻微不准确”或“准确”。总共对1908个句子进行了注释,其中约40%严重不准确,33%轻微不准确,27%准确。
有201个句子被两位不同的注释者标注过。为了获取单一标签,如果注释者达成一致,那么采用一致标签;如果注释者存在分歧,那么选择最差情况的标签,比如{重大不准确, 轻微不准确}会被映射为重大不准确。
5 实时幻觉检测
最后,我们构建一个用于实时幻觉检测的Streamlit小程序。如前所述,最好的方法是让另一个LLM成为评估者,用自相似性分数作为评估指标。
首先,聊天机器人生成对Prompt的原始回应以及另外三个抽样回应。
def generate_3_samples(prompt):
sampled_passages = []
for i in range(1,4):
completion = client.completions.create(
model="text-davinci-003",
prompt = prompt,
max_tokens = 200,
temperature=0.7
)
globals()[f'sample_{i}'] = completion.choices[0].text.lstrip('\n')
sampled_passages.append(globals()[f'sample_{i}'])
return sampled_passagesdef get_output_and_samples(prompt):
completion = client.completions.create(
model="text-davinci-003",
prompt = prompt,
max_tokens = 100,
temperature=0.7,
)
output = completion.choices[0].text
sampled_passages = generate_3_samples(prompt)
return output, sampled_passages然后,所有这些回应都被输入到一个更强大的LLM中,该模型会给出原始回应与样本之间的相似性分数,较低的分数表示幻觉的风险较高。
def llm_evaluate(sentences,sampled_passages):
prompt = f"""You will be provided with a text passage \
and your task is to rate the consistency of that text to \
that of the provided context. Your answer must be only \
a number between 0.0 and 1.0 rounded to the nearest two \
decimal places where 0.0 represents no consistency and \
1.0 represents perfect consistency and similarity. \n\n \
Text passage: {sentences}. \n\n \
Context: {sampled_passages[0]} \n\n \
{sampled_passages[1]} \n\n \
{sampled_passages[2]}."""
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": ""},
{"role": "user", "content": prompt}
]
)
return completion.choices[0].message.content我们使用0.5的阈值来决定是显示生成的输出还是一个免责声明。
# Streamlit app layout
st.title('Anti-Hallucination Chatbot')
# Text input
user_input = st.text_input("Enter your text:")
if user_input:
prompt = user_input
output, sampled_passages = get_output_and_samples(prompt)
# LLM score
self_similarity_score = llm_evaluate(output,sampled_passages)
# Display the output
st.write("**LLM output:**")
if float(self_similarity_score) > 0.5:
st.write(output)
else:
st.write("I'm sorry, but I don't have the specific information required to answer your question accurately. ")现在,我们能够可视化最终结果。

6 总结
LLM幻觉检测是一个长期讨论的问题。令人兴奋的是,我们现在可以用LLM来评估其它LLM的输出,即对同一提示生成多个响应并比较其一致性。还有更多工作要做,但与其依赖人工评估或手动制定规则,让模型自己捕捉不一致性似乎是一个不错的方向。
p.s. 读完文章后我有一处疑问,原文中的prompt方法是把原始输出的每个句子拿来和每个样本输出单独比较一致性,再在N个样本的结果上取均值;但代码部分似乎把整个原始输出以及三个样本输出一起拿来比较一致性了。我的猜测是为了方便演示,以及限制了原始输出最大token数为100,相当于只有一个句子。我已在原文评论区留言,如果作者回复我再来更新~
感谢阅读,欢迎大家在评论区留言讨论哦!