SRE和系统运维的最大区别,我认为SRE得在系统运维的基础上研究业务,研究系统架构、产品架构,SRE面向的是用户稳定性。
大型互联网系统,模块多、依赖关系和运行环境复杂,如果不了解系统架构,在出现问题时基本就是抓瞎的,不知道服务的功能,不知道到故障后对用户的影响,不知道出了问题后查哪些指标,不知道服务依赖了哪些第三方资源,不知道服务间是怎么调度的,等等都会让SRE局限在系统外的狭窄空间,只能被动的接受安排,很难对产品稳定性提出建设性的意见。
所以要保障好服务的SLA,一定得深入理解系统架构、产品架构,而不仅仅停留在基础资源iass层。
一、背景痛点
所有这些iass层以上的应用信息,如果不依赖工具能力,被工程师记的到处都是,而且无法做到及时的更新,甚至都做不到共享,SRE和研发各记各的,时间长了,加上人员流动,慢慢就变成口口相传,每次花大量时间沟通对称和争论,所以这是一个很重要但很难管理的工作,其实这些应用信息还有很多别的重要作用。
其次,SRE要做一个操作,需要凭记忆思考打开N个系统,例如先查wiki找信息,再到域名管理系统找域名,再到LB系统上找负载均衡,再找到git工程地址,再到部署系统查看变更记录,再到群里广播喊人等等......效率何其低下。
第三,SRE管理了大量服务,经常遇到不符合运维标准的系统被扔过来,各种个性化工作台、CI/CD、监控系统等,前期没找SRE参与,后面变成烂摊子找SRE救火,如果把运维当成一个服务来看,需要运维服务是要走准入申请的,理论上只有符合标准的服务SRE才做接管。
PS:先上一个SMDB系统图
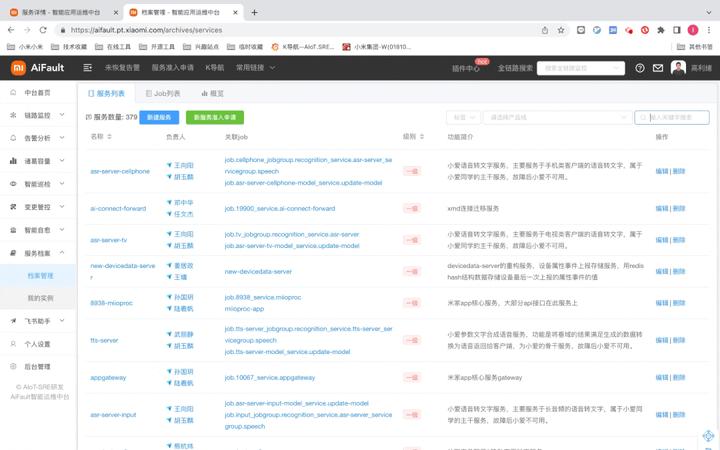
二、思考设计
那么就引出了今天的话题,如何用新的体系和工具帮助SRE完成用户稳定性的目标?传统的运维管理都是从CMDB(Configuration Management Database)做起的,机器、设备、LB等作为基础的管理单元,运维围绕iass层,无业务状态,显然不能满足新形态下SRE的业务目标,那么从应用运维的视角,我们应该怎么考虑呢?
展开思考,SRE是应用运维,其运维对象是业务的一个个服务,一般服务的上层对应着LB、域名等接入层资源,下层跑在服务器、公有云等基础设施上,还会用到数据库、存储等资源,服务之间有各种各样的调用,我们平时要对服务进行可用性、时延、容量等指标的监控,对服务进行迭代上线、变更管控,对服务制定、执行故障预案,想到这里思路就越发清晰了,SRE的运维动作都是面向服务的,所以是不是我们应该有一套以服务作为最小管理单元的工具?所有的业务运维以服务的维度展开,所有的信息、操作围绕着服务做排列组合整理呢?
是的,我给他命名叫是SMDB(Service Management Database),我们内部也叫服务档案,以服务作为最小管理单元开展业务,同时作为应用运维的第一入口,从此大多数的工作都以SMDB为基础展开,最初一个功能导读如下。
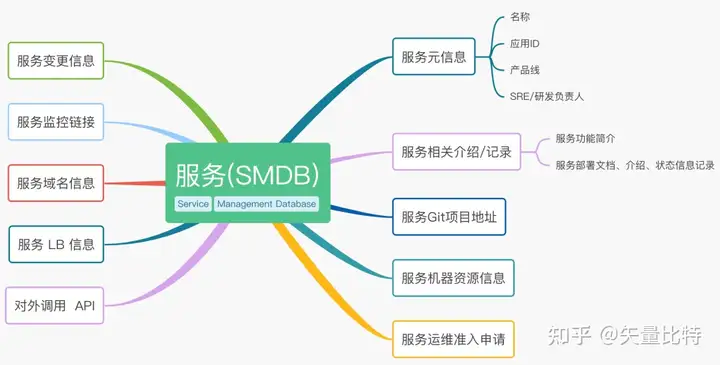
-)服务的定义和设计&SMDB定位
我认为服务是完成特定功能的一组或几组程序,服务的起点就是部署系统里的job,或者对应容器里的应用(咱们统称job),但服务是job的再次上层抽象,也就是说1个服务可以由1个或多个job构成,来解决特定的问题,但至少要有1个job,有点像进程和线程的关系,为了理清逻辑关系,画了一张示意图如下。
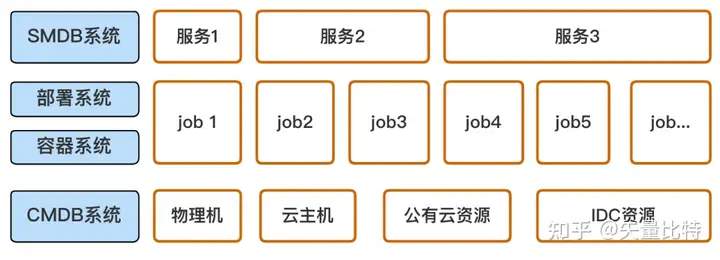
如上图,底层的资产用CMDB系统统筹管理,再往上就是研发写的程序,这些程序通过部署系统以1个个job的形式部署到机器资源上,一般物理机用传统的部署系统管理,遇到容器相关就用K8S等编排工具管理,再往上就到了服务应用层,我们要用SMDB系统将服务信息管理起来。
-)以服务为中心的信息编排
信息的编排和使用围绕服务,以服务为中心编排设计所有信息,结合全局搜索,可以迅速找到应用层的所有信息。
结合markdown的记录,可以快速知道服务是做什么用的、相关介绍,以及找到对应负责人、最近上线情况、资源情况,监控情况等,把分散到wiki等各个系统的信息,整合到一起,并尽最大可能做好和各系统的超链接联动,统一登录。-)信息自动采集更新(自动更新+手动刷新)
为了保证信息的新鲜度,在设计的时候,要将能用系统采集的信息全部通过系统采集,并设置好自动更新,尽最大可能降低人工信息填写,这是一个原则,因为服务众多,如果依赖手工维护,那么这份信息就会变的越来越没有用。
像研发SRE人员、域名信息、上线变更信息、机器资源分布、git地址、容器规格等全部为自动更新。
自动更新是有周期的,不可能做成实时更新,成本太大,所以从产品设计的角度一定要有手动刷新的按钮,比如说某个服务,要看一下实时信息,点击刷新即可。
-)服务的运维准入申请
设计好表单,有新服务要运维,研发直接填写申请单,系统审批通过后,生成对应的服务档案。表单要设计服务等级,不同等级的服务对应着不同的SLA,在申请阶段就要说清楚。
-)为更上层的应用提供基础信息
SMDB建好后,相当于拥有了一套丰富的应用层知识库,很多的更上层的应用比如链路监控、故障诊断、容量管理、智能巡检等都可以直接通过API调用,通过SMDB把更上层的应用和服务关联起来,进而关联到底层的iass层信息,如果用好可以极大的提升运维效率。
三、技术实现
当然,为了最终实现一站式闭环运维,工具还是研发到我们的「AiFault智能运维中台」上,设计后发现,SMDB其实变成了AiFault的一个信息底座,从最底层贯穿应用到所有的插件中,并且可以通过应用ID将服务信息在运维全场景中贯穿打通。
然后就是选人环节,这个插件最后也是由我和我们的全栈工程师王墉同学一起协作研发的,设计后AiFault的功能架构如下。
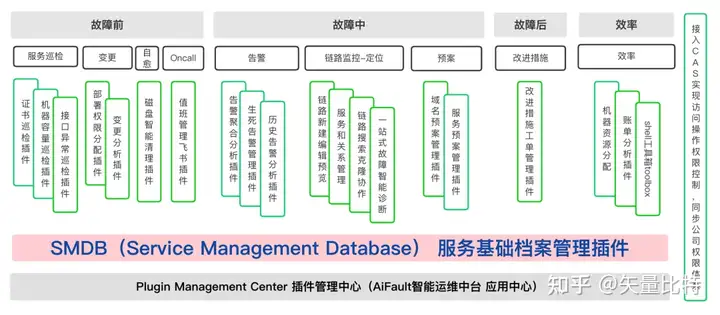

SMDB的位置如上图所示,非常的清晰,解决的问题也很具体。
四、场景演示
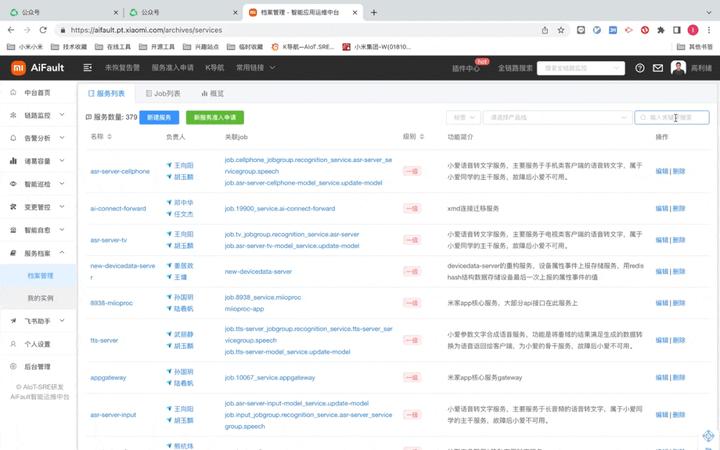
-)服务找人
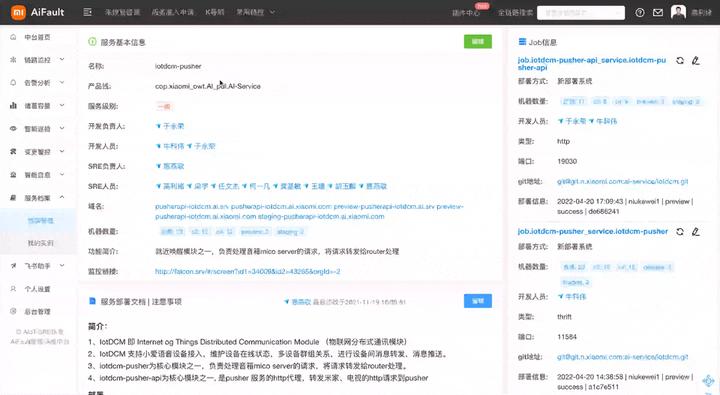
-)服务学习
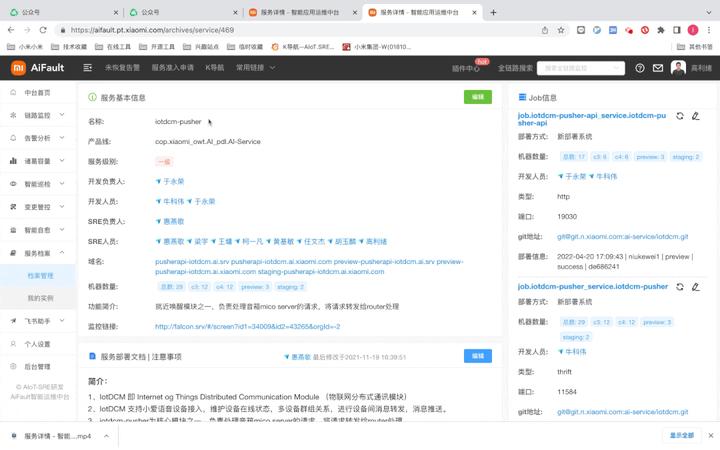
-)域名切换
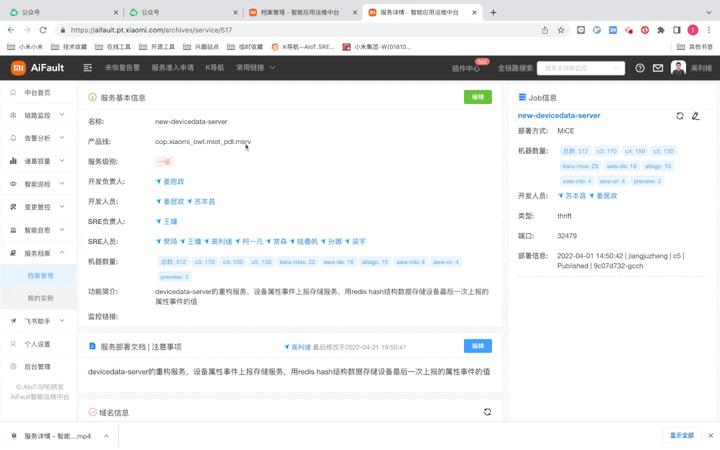
-)CI/CD和变更查询
-)运维准入
历史原因,准入用的还不是很好,但相信运维以后一定可以做成标准化服务的。
还有很多很多别的快捷场景就不一一演示了,SRE的工作效率得到了质的提升,也为将来的批量化运维打下了基础,希望对你有所启发,下一篇博客见!!
特别感谢AIoT SRE团队所有的小伙伴们,大家团结而有趣,不甘于平庸、不随波逐流,敢于突破和创新,一起做了很多从0到1有意义的项目,为同行贡献了大量最佳实践!!