0.前言
1.针对的问题
目前主流的弱监督语义分割方法通常首先训练分类模型,基于类别激活图(CAM)或其变种生成初始伪标签;然后对伪标签进行细化作为监督信息训练一个独立的语义分割网络作为最终模型。其中,分类模型一般基于卷积网络,无法准确感知图像中的全局特征关联,导致初始伪标签通常只覆盖语义物体中最具有判别性的部分,显著影响了最终语义分割的效果。
2.主要贡献
•提出了一个基于端到端转换器的WSSS框架,该框架具有图像级标签。这是为WSSS探索transformer的第一项工作。
•利用Transformer的固有优点,设计了一个Affinity from Attention(AFA)模块。AFA从MHSA中学习可靠的语义亲和度,并使用学习到的亲和度传播伪标签。
•提出了一个高效的像素自适应细化(PAR)模块,该模块融合了局部像素的RGB和位置信息以进行标签细化。
3.方法
利用transformer来生成CAM作为初始伪标签,以避免卷积神经网络的固有缺陷。进一步利用Transformer块的固有亲和力来改进初始伪标签。由于MHSA中的语义亲和力较粗,提出了一个AFA (affinity from Attention)模块,该模块旨在获得可靠的伪亲和力标签,以监督Transformer中MHSA学习到的语义亲和力。然后利用学习到的亲和度通过随机游走传播来修正初始的伪标签,这可以扩散目标区域并抑制错误激活的区域。为获得AFA的高置信度伪亲和标签,并确保传播伪标签的局部一致性,进一步提出一种像素自适应细化模块(PAR)。基于像素自适应卷积,PAR有效地整合了局部像素的RGB和位置信息来细化伪标签,强化了与low-level图像外观的对齐。
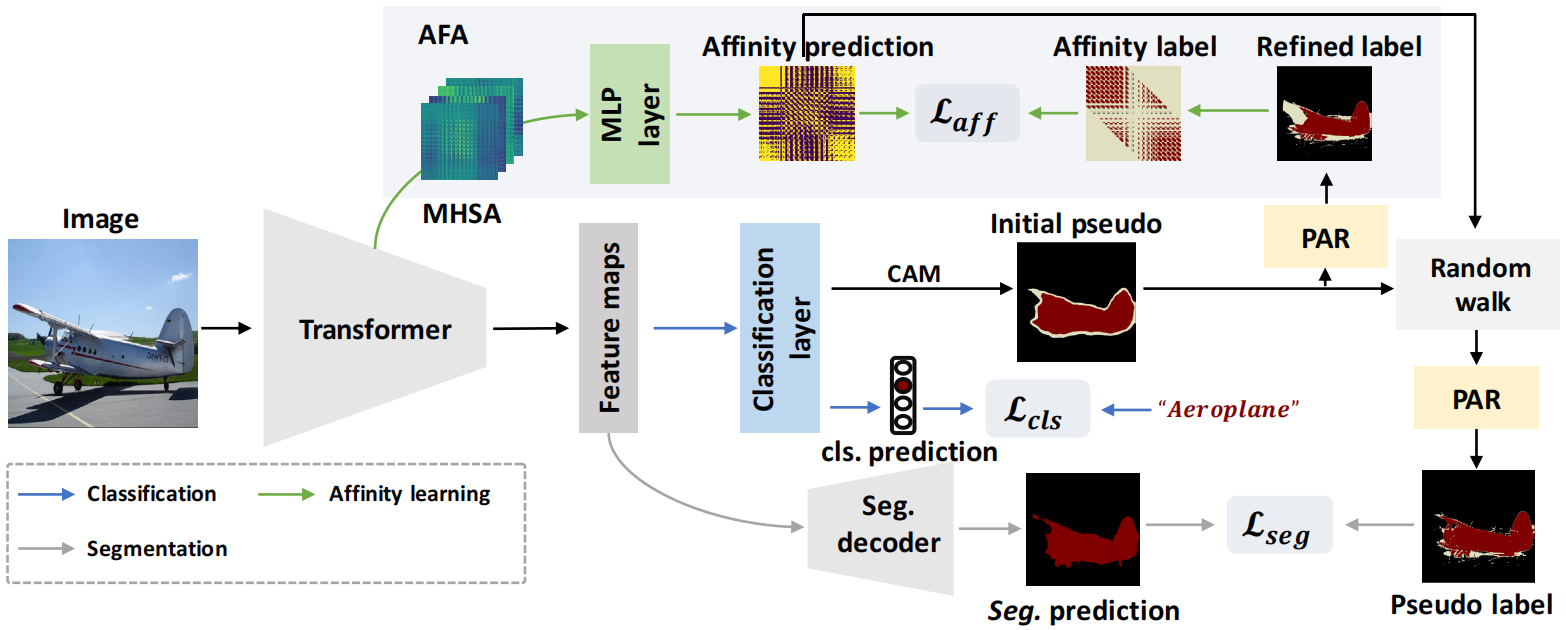
首先将输入图像分割成h × w块,每个块通过flatten和线性投影得到一个token。将这些token输入Transformer得到特征图F∈Rhw×d,使用分类层的权重对特征图F进行加权,使用ReLu函数消除负激活值得到激活映射Mc,Mc通过Min-Max进行归一化,然后使用背景分数β (0 < β < 1)来区分前景和背景区域,得到初始伪标签。
虽然Transformer中的MHSA和语义affinity之间存在一致性,但是由于在训练过程中没有对MHSA施加明确的约束,因此在MHSA中学习到的affinity通常是不准确的,本文通过AFA模块学习准确的affinity信息。假设一个Transformer block中的多头注意力表示为S∈Rhw×hw×n,AFA中直接用多头注意力的线性组合,即使用一个MLP层,生成语义affinity。本质上,自注意力结构是一种像素间有向的建模方式(即自注意力矩阵是不对称的),而语义affinity的关联应当是无向的,因此简单地将其和其转置进行相加来达到这种转换,得到语义affinity预测矩阵A∈Rhw×hw。
为了学习到可靠的affinity矩阵 A, 关键的一步是生成可靠的伪affinity标签对其进行监督。给定CAM M∈Rh×w×C,通过下式得到伪标签Yp:
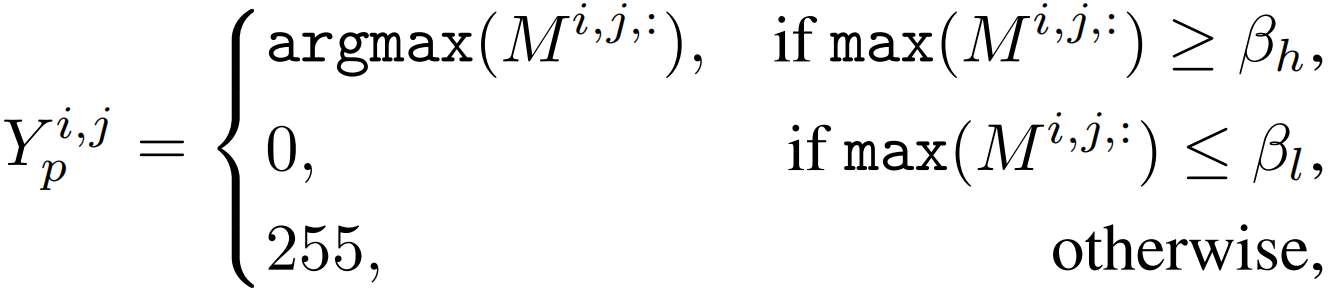
其中0和255分别表示背景类的索引和忽略的区域。Argmax(·)提取具有最大激活值的语义类。Yp通过PAR模块进行细化,然后通过Yp得到伪affinity标签Yaff∈Rhw×hw,具体来说,对于Yp,如果像素(i, j)和(k, l)共享相同的语义,将它们的亲和度设置为正;否则将它们的亲和度设为负。如果从被忽略的区域中采样像素(i, j)或(k, l),它们的亲和度也会被忽略。此外,只考虑像素(i, j)和(k, l)在同一个局部窗口的情况,而忽略了远处像素对的亲和度。通过Yaff来监督预测affinity A,affinity损失Laff如下:
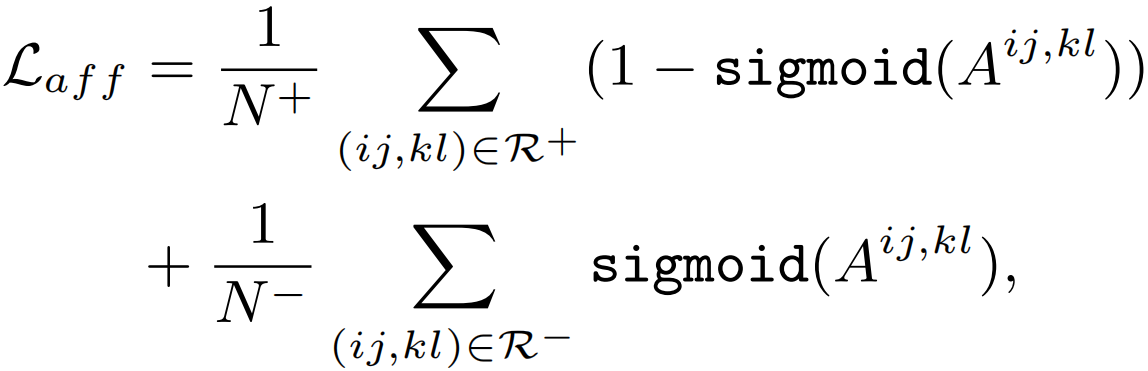
其中R+、R−分别表示Yaff 中正、负样本的集合。N+和N−计算R+和R−的数量,直观地说,该式强制网络从MHSA学习高置信度的语义亲和关系。另一方面,由于亲和预测A是MHSA的线性组合,也有利于自注意的学习,进一步有助于发现整体对象区域。
affinity传播 在得到可靠的affinity矩阵之后,通过随机游走算法对初始伪标签进行修正,首先通过下式得到语义转换矩阵T:
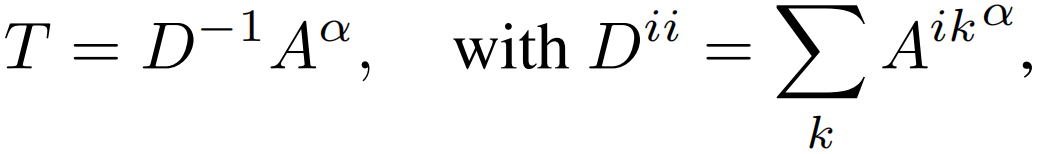
其中,α > 1是一个超参数,可以忽略A中的平凡亲和值,而D是一个对角矩阵,在row-wise归一化A。初始CAM M∈Rh×w×C的随机游走传播如下:
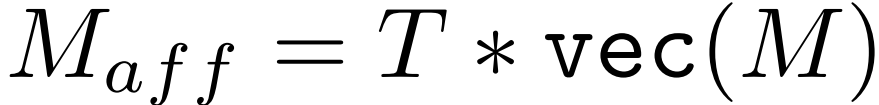
其中vec(·)向量化M,这种传播过程扩散了高亲和力的语义区域,并抑制了错误激活的区域,从而使激活映射更好地与语义边界对齐。
PAR(Pixel-Adaptive Refifinement):初始伪标签通常是粗糙和局部不一致的,即具有相似低级图像外观的相邻像素可能不共享相同的语义。为了保证局部一致性,本文结合RGB和空间信息来定义low-level成对亲和度,并构建像素自适应细化模块(PAR)。
给定输入图像I∈Rh×w×3,对于位置(I, j)和(k, l)的像素,RGB和空间成对项定义为:
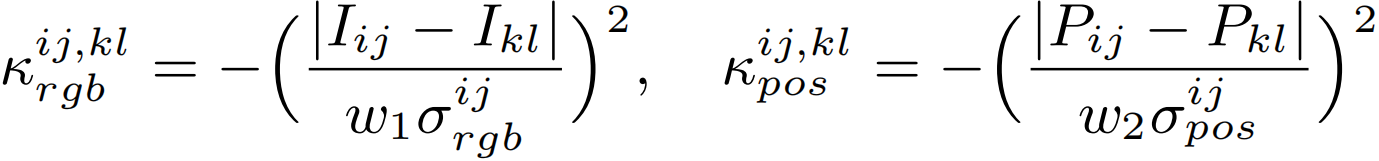
其中,Iij和Pij分别表示像素(i, j)的RGB信息和空间位置。空间位置为XY坐标,σpos 和σ分别表示RGB和位置差的标准差。w1和w2分别控制κrgb和κpos的平滑度。 然后用softmax对κrgb和κpos进行归一化并相加,构建PAR的affinity kernel,即
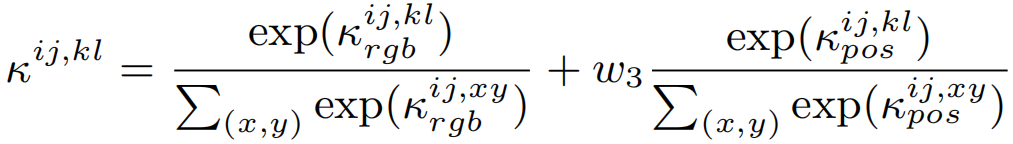
其中(x, y)从(i, j)的邻居集合中采样,即N(i, j),并调整3 位置项的重要性。基于构建的亲和核,细化初始CAM和传播CAM。细化进行多次迭代。对于CAM M∈Rh×w×C,在迭代t中,有
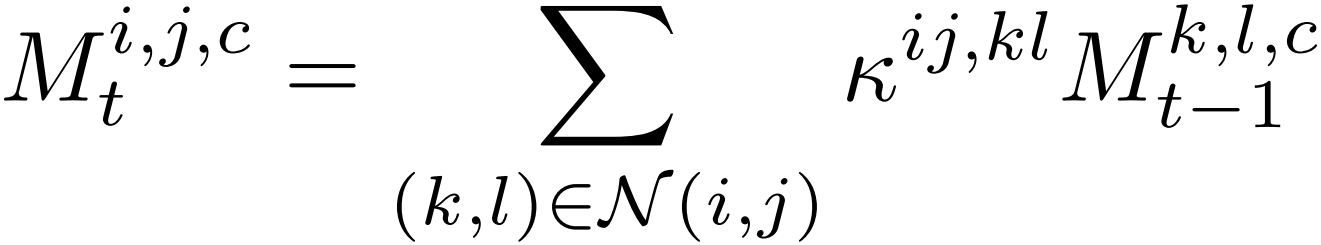
对于相邻像素集N(·),将其定义为具有多重膨胀率的8路邻居。这样的设计保证了训练效率,因为给定像素的扩展邻居可以很容易地使用3×3膨胀卷积提取。
- Weakly-Supervised Segmentation Transformers End-to-End Supervisedweakly-supervised segmentation transformers weakly-supervised action weakly-supervised completeness localization transformers end-to-end end detection language-guided self-supervised segmentation self-supervised transformers lightweight supervised segmentation transformers camouflaged one-stage self-supervised transformers supervised empirical segmentation transformers semantic segvit end-to-end