一、选题背景
随着互联网的发展,数据分析岗位在各行各业中的需求越来越大。拉勾网作为国内知名的招聘网站,其上的数据分析岗位信息具有很高的参考价值。通过对拉勾网上的数据分析岗位进行数据分析,可以了解当前数据分析岗位的市场情况,为求职者提供有价值的参考信息,同时也可以为企业和招聘方提供人才需求和供给的分析依据。预期目标是通过对拉勾网上的数据分析岗位数据进行分析,揭示数据分析岗位的市场需求、薪资水平、技能要求等方面的特点,为企业和个人提供有针对性的建议。
二、主题式网络爬虫设计方案
1、名称:拉勾网—数据分析岗位爬取+数据分析可视化
2、爬取的数据内容:职位id,岗位名称,公司全称,公司简称,公司规模,融资阶段,公司标签,工作城市,工作地区,学历要求,薪资范围,工作经验,岗位描述,岗位福利
3、爬虫设计方案概述:实现思路:本次案例主要使用Python的requests库发送请求,获取拉勾网的数据分析师岗位页面的HTML内容,使用Python的BeautifulSoup库解析HTML内容,提取出需要的信息后保存到本地文件中,随后用pandas库进行数据分析和可视化
技术难点:
网站爬虫的反爬机制,超过一定次数后会限制访问
对爬取的信息进行数据可视化
三、主题式页面结构特征分析
1.主题页面的结构与特征分析

2.html页面解析



<div class="list_item_top">职位名称
<span class="add">工作地点
<div class="li_b_l">学历要求和薪资
<span class="money">
</div><div class="li_b_r"“>公司特点
<div class="company_name">公司名称
<div class="industry">公司人数
3.节点(标签)查找方法与遍历方法
查找方法:find
遍历方法:for
四、网络爬虫程序设计
爬取内容
1 # 导入包 2 import requests 3 import json 4 import csv 5 import time 6 7 8 def get_lagou_data(url): 9 # 构建请求头 10 headers = { 11 'origin': 'https://www.lagou.com', 12 'referer': 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88/p-city_0?', 13 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36', 14 'cookie': 'user_trace_token=20210502113751-6e94202a-add9-4490-a573-962f1266be77; __lg_stoken__=67a7d1c84b86ed537c54e3d69977afad92d05cf285b726ae40509062a087e14b6a64f94fb5ae629a24b2062432407a1f3ab94acbc65df49ce63d5e4fcf6d5c7b009691ec2cf2; JSESSIONID=ABAAABAABEIABCI0E4D2CDFFC692EEF09DC3C1487ADD5A8; WEBTJ-ID=2021052%E4%B8%8A%E5%8D%8811:37:54113754-1792b276d6b551-08fbf0bfc4784e-113a6054-1024000-1792b276d6c928; X_HTTP_TOKEN=02cc1cc330da72df576629916129e561f3ad981774; PRE_UTM=; PRE_HOST=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Fjobs%2Flist%5F%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590%25E5%25B8%2588%2Fp-city%5F0%3F; PRE_SITE=; LGUID=20210502113756-6daf6df0-2de5-42d2-828e-8cb2feef29bd; LGSID=20210502113756-2910c4b4-69f0-458b-aac5-e1bf59fee8e1; sajssdk_2015_cross_new_user=1; sensorsdata2015session=%7B%7D; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%221792b27744f8eb-04cbd992f837b9-113a6054-1024000-1792b2774503c1%22%2C%22first_id%22%3A%22%22%2C%22props%22%3A%7B%22%24os%22%3A%22MacOS%22%2C%22%24browser%22%3A%22Chrome%22%2C%22%24browser_version%22%3A%2290.0.4430.93%22%7D%2C%22%24device_id%22%3A%221792b27744f8eb-04cbd992f837b9-113a6054-1024000-1792b2774503c1%22%7D; _ga=GA1.2.2141774430.1619926677; _gat=1; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1619926677; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1619926677; LGRID=20210502113756-9a924450-7598-418b-b731-33046e64120c; _gid=GA1.2.1480471771.1619926677; SEARCH_ID=ab911c2ad61c47f2a94993729604d904' 15 } 16 17 # 用data进行分页爬取 18 for i in range(1, 31): 19 data = { 20 'first': 'true', 21 'pn': i, 22 'kd': '数据分析师' 23 } 24 25 # 请求网页 26 response = requests.post(url=url, headers=headers, data=data, timeout=3) 27 print(response.text) 28 time.sleep(3) # 休息一下 29 30 # json.loads 用于解码 JSON 数据。该函数返回 Python字段的数据类型 31 response = json.loads(response.content) 32 33 # 获取15条数据 34 result_15 = response['content']['positionResult']['result'] 35 36 # 获取每条招聘岗位里面的详细信息 37 for i in result_15: 38 position_id = i['positionId'] # 职位Id 39 position_name = i['positionName'] # 职位名称 40 company_full_name = i['companyFullName'] # 公司全称 41 company_short_name = i['companyShortName'] # 公司简称 42 company_size = i['companySize'] # 公司规模 43 finance_stage = i['financeStage'] # 融资阶段 44 company_label_list = i['companyLabelList'] # 公司标签 45 first_type = i['firstType'] # 第一类型 46 second_type = i['secondType'] # 第二类型 47 third_type = i['thirdType'] # 第三类型 48 position_labels = i['positionLables'] # 职位标签 49 industry_labels = i['industryLables'] # 行业标签 50 create_time = i['createTime'] # 创建时间 51 format_create_time = i['formatCreateTime'] # 格式化创建时间 52 city = i['city'] # 城市 53 district = i['district'] # 地区 54 salary = i['salary'] # 薪水 55 salary_month = i['salaryMonth'] # 工资月份 56 work_year = i['workYear'] # 工作年限 57 job_nature = i['jobNature'] # 工作性质 58 education = i['education'] # 教育背景 59 position_advantage = i['positionAdvantage'] # 岗位优势 60 hi_tags = i['hitags'] # 福利标签 61 62 # 存储数据, 先在当前文件下创建一个叫‘lagou_datas.csv’的文件 63 # 'a' 追加写入,;encoding设置编码格式,防止乱码 ;newline是为了解决写入时新增行与行之间的一个空白行问题 64 with open('./lagou_datas.csv', 'a', encoding='utf_8_sig', newline='') as f: 65 # 写入数据 66 csv_write = csv.writer(f) 67 # 按照以下行顺序写入,是一个列表 68 csv_write.writerow([position_id, position_name, company_full_name, company_short_name, company_size, 69 finance_stage, company_label_list, first_type, second_type, third_type, position_labels, 70 industry_labels, create_time, format_create_time, city, district, salary, salary_month, 71 work_year, job_nature, education, position_advantage, hi_tags]) 72 time.sleep(3) # 休息一下 73 74 75 # 主程序 76 if __name__ == '__main__': 77 # Ajax的URL 78 url = "https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false" 79 80 # 传入URL,调用函数 81 get_lagou_data(url)
2。数据清洗
1 #导入包 2 import pandas as pd 3 import numpy as np 4 import seaborn as sns 5 from pyecharts import Pie 6 from pyecharts import options as opts 7 import matplotlib.pyplot as plt 8 #导入数据 9 path = "C:/data/lagou.csv" 10 df = pd.read_csv(path) 11 # 取出我们进行后续分析所需的字段 12 columns = ["positionName", "companyShortName", "city", "companySize", "education", "financeStage", 13 "industryField", "salary", "workYear", "hitags", "companyLabelList", "job_detail"] 14 df = df[columns].drop_duplicates() #去重 15 # 数据分析相应的岗位数量 16 cond_1 = df["positionName"].str.contains("数据分析") # 职位名中含有数据分析字眼的 17 cond_2 = ~df["positionName"].str.contains("实习") # 剔除掉带实习字眼的 18 df = df[cond_1 & cond_2] 19 df.drop(["positionName"], axis=1, inplace=True) 20 df.reset_index(drop=True, inplace=True)
3、对各城市对数据分析岗位的需求量生成柱状图

1 fig, ax = plt.subplots(figsize=(12,8)) 2 sns.countplot(y="city",order= df["city"].value_counts().index,data=df,color='#3c7f99') 3 plt.box(False) 4 fig.text(x=0.04, y=0.90, s=' 各城市数据分析岗位的需求量 ', 5 fontsize=32, weight='bold', color='white', backgroundcolor='#c5b783') 6 plt.tick_params(axis='both', which='major', labelsize=16) 7 ax.xaxis.grid(which='both', linewidth=0.5, color='#3c7f99') 8 plt.xlabel('') 9 plt.ylabel('')
不同领域对数据分析岗的需求量生成柱形图

1 industry_index = df["industryField"].value_counts()[:10].index 2 industry =df.loc[df["industryField"].isin(industry_index),"industryField"] 3 fig, ax = plt.subplots(figsize=(12,8)) 4 sns.countplot(y=industry.values,order = industry_index,color='#3c7f99') 5 plt.box(False) 6 fig.text(x=0, y=0.90, s=' 细分领域数据分析岗位的需求量(取前十) ', 7 fontsize=32, weight='bold', color='white', backgroundcolor='#c5b783') 8 plt.tick_params(axis='both', which='major', labelsize=16) 9 ax.xaxis.grid(which='both', linewidth=0.5, color='#3c7f99') 10 plt.xlabel('') 11 plt.ylabel('')
各城市薪资水平生成柱状图

1 fig,ax = plt.subplots(figsize=(12,8)) 2 city_order = df.groupby("city")["salary"].mean()\ 3 .sort_values()\ 4 .index.tolist() 5 sns.barplot(x="city", y="salary", order=city_order, data=df, ci=95,palette="RdBu_r") 6 fig.text(x=0.04, y=0.90, s=' 各城市的薪资水平对比 ', 7 fontsize=32, weight='bold', color='white', backgroundcolor='#3c7f99') 8 plt.tick_params(axis="both",labelsize=16,) 9 ax.yaxis.grid(which='both', linewidth=0.5, color='black') 10 ax.set_yticklabels([" ","5k","10k","15k","20k"]) 11 plt.box(False) 12 plt.xlabel('') 13 plt.ylabel('')
一线城市薪资对比图

1 fig,ax = plt.subplots(figsize=(12,8)) 2 fig.text(x=0.04, y=0.90, s=' 一线城市的薪资分布对比 ', 3 fontsize=32, weight='bold', color='white', backgroundcolor='#c5b783') 4 sns.kdeplot(df[df["city"]=='北京']["salary"],shade=True,label="北京") 5 sns.kdeplot(df[df["city"]=='上海']["salary"],shade=True,label="上海") 6 sns.kdeplot(df[df["city"]=='广州']["salary"],shade=True,label="广州") 7 sns.kdeplot(df[df["city"]=='深圳']["salary"],shade=True,label="深圳") 8 plt.tick_params(axis='both', which='major', labelsize=16) 9 plt.box(False) 10 plt.xticks(np.arange(0,61,10), [str(i)+"k" for i in range(0,61,10)]) 11 plt.yticks([]) 12 plt.legend(fontsize = 'xx-large',fancybox=None)
根据不同技能的薪资水平对比绘制箱型图

1 py_rate = df["Python/R"].value_counts(normalize=True).loc[1] 2 sql_rate = df["SQL"].value_counts(normalize=True).loc[1] 3 tableau_rate = df["Tableau"].value_counts(normalize=True).loc[1] 4 excel_rate = df["Excel"].value_counts(normalize=True).loc[1] 5 print("职位技能需求:") 6 print("Python/R:",py_rate) 7 print("SQL:",sql_rate) 8 print("Excel:",excel_rate) 9 print("Tableau:",tableau_rate) 10 def get_level(x): 11 if x["Python/R"] == 1: 12 x["skill"] = "Python/R" 13 elif x["SQL"] == 1: 14 x["skill"] = "SQL" 15 elif x["Excel"] == 1: 16 x["skill"] = "Excel" 17 else: 18 x["skill"] = "其他" 19 return x 20 df = df.apply(get_level,axis=1) 21 fig,ax = plt.subplots(figsize=(12,8)) 22 fig.text(x=0.02, y=0.90, s=' 不同技能的薪资水平对比 ', 23 fontsize=32, weight='bold', color='white', backgroundcolor='#c5b783') 24 sns.boxplot(y="skill",x="salary",data=df.loc[df.skill!="其他"],palette="husl",order=["Python/R","SQL","Excel"]) 25 plt.tick_params(axis="both",labelsize=16) 26 ax.xaxis.grid(which='both', linewidth=0.75) 27 plt.xticks(np.arange(0,61,10), [str(i)+"k" for i in range(0,61,10)]) 28 plt.box(False) 29 plt.xlabel('工资', fontsize=18) 30 plt.ylabel('技能', fontsize=18)
根据不同规模公司的用人需求差异绘制散点图

1 company_size_map = { 2 "2000人以上": 6, 3 "500-2000人": 5, 4 "150-500人": 4, 5 "50-150人": 3, 6 "15-50人": 2, 7 "少于15人": 1 8 } 9 workYear_map = { 10 "5-10年": 5, 11 "3-5年": 4, 12 "1-3年": 3, 13 "1年以下": 2, 14 "应届毕业生": 1 15 } 16 df["company_size"] = df["companySize"].map(company_size_map) 17 df["work_year"] = df["workYear"].map(workYear_map) 18 df = df.sort_values(by="company_size",ascending=True) 19 df_plot = df.loc[~df.work_year.isna()] 20 color_map = { 21 5:"#ff0000", 22 4:"#ffa500", 23 3:"#c5b783", 24 2:"#3c7f99", 25 1:"#0000cd" 26 } 27 df_plot["color"] = df_plot.work_year.map(color_map) 28 df_plot.reset_index(drop=True,inplace=True) 29 def seed_scale_plot(): 30 seeds=np.arange(5)+1 31 y=np.zeros(len(seeds),dtype=int) 32 s=seeds*100 33 colors=['#ff0000', '#ffa500', '#c5b783', '#3c7f99', '#0000cd'][::-1] 34 fig,ax=plt.subplots(figsize=(12,1)) 35 plt.scatter(seeds,y,s=s,c=colors,alpha=0.3) 36 plt.scatter(seeds,y,c=colors) 37 plt.box(False) 38 plt.grid(False) 39 plt.xticks(ticks=seeds,labels=list(workYear_map.keys())[::-1],fontsize=14) 40 plt.yticks(np.arange(1),labels=[' 经验:'],fontsize=16) 41 fig, ax = plt.subplots(figsize=(12, 8)) 42 fig.text(x=0.03, y=0.92, s=' 不同规模公司的用人需求差异 ', fontsize=32, 43 weight='bold', color='white', backgroundcolor='#3c7f99') 44 plt.scatter(df_plot.salary, df_plot["companySize"], s=df_plot["work_year"]*100 ,alpha=0.35,c=df_plot["color"]) 45 plt.scatter(df_plot.salary, df_plot["companySize"], c=df_plot["color"].values.tolist()) 46 plt.tick_params(axis='both', which='both', length=0) 47 plt.tick_params(axis='both', which='major', labelsize=16) 48 ax.xaxis.grid(which='both', linewidth=0.75) 49 plt.xticks(np.arange(0,61,10), [str(i)+"k" for i in range(0,61,10)]) 50 plt.xlabel('工资', fontsize=18) 51 plt.box(False) 52 seed_scale_plot()
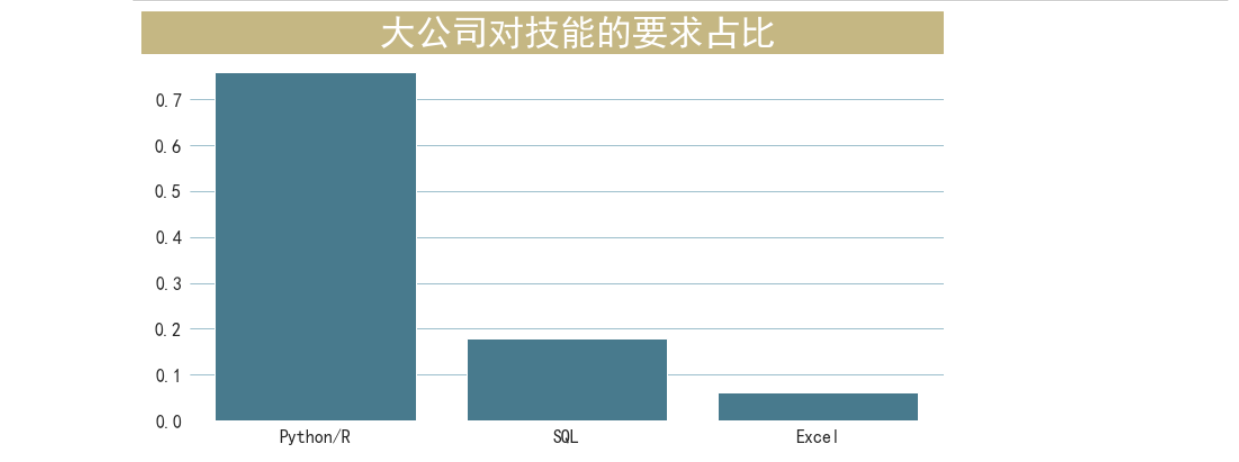
根据大公司对技能的要求占比生成柱形图
df_skill = df.loc[(df["companySize"]=="2000人以上")&(df.skill!="其他")]["skill"].value_counts(normalize=True) df_skill fig, ax = plt.subplots(figsize=(12, 6)) sns.barplot(x=df_skill.index,y=df_skill.values, color='#3c7f99') plt.box(False) fig.text(x=0.08, y=0.9, s=' 大公司对技能的要求占比 ', fontsize=32, weight='bold', color='white', backgroundcolor='#c5b783') plt.tick_params(axis='both', which='major', labelsize=16) ax.yaxis.grid(which='both', linewidth=0.5, color='#3c7f99')
爬虫课程设计全部代码如下:
1 # 导入包 2 import requests 3 import json 4 import csv 5 import time 6 # 定义获取拉勾网数据的函数 7 def get_lagou_data(url): 8 # 构建请求头 9 headers = { 10 'origin': 'https://www.lagou.com', 11 'referer': 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%8C/p-city_0?', 12 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36', 13 14 'cookie': 'user_trace_token=20210502113751-6e94202a-add9-4490-a573-962f1266be77; __lg_stoken__=67a7d1c84b86ed537c54e3d69977afad92d05cf285b726ae40509062a087e14b6a64f94fb5ae629a24b2062432407a1f3ab94acbc65df49ce63d5e4fcf6d5c7b009691ec2cf2; JSESSIONID=ABAAABAABEIABCI0E4D2CDFFC692EEF09DC3C1487ADD5A8; WEBTJ-ID=2021052%E4%B8%8A%E5%8D%8811:37:54113754-1792b276d6b551-08fbf0fcbf4784-113a6054-1024000-1792b276d6c928; X_HTTP_TOKEN=02cc1cc330da72df576629916129e561f3ad981774; PRE_UTM=; PRE_HOST=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Fjobs%2Flist_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%8C%2Fp-city_0%3F; PRE_SITE=; LGUID=20210502113756-6daf6df0-2de5-42d2-828e-8cb2feef29bd; LGSID=20210502113756-2910c4b4-69f0-458b-aac5-e1bf59fee8e1; sajssdk_2015_cross_new_user=1; sensorsdata2015session=%7B%7D; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%221792b27744f8eb-04cbd992f837b9-113a6054-1024000-1792b2774603c1%22%2C%22first_id%22%3A%22%22%2C%22props%22%3A%7B%22%24os%22%3A%22MacOS%22%2C%22%24browser%22%3A%22Chrome%22%2C%22%24browser_version%22%3A%2290.0.4430.93%22%7D%2C%22%24device_id%22%3A%221792b27744f8eb-04cbd992f837b9-113a6054-1024000-1792b2774603c1%22%7D; _ga=GA1.2.2141774430.1619926677; _gat=1; Hm_lvt_4233e74dff0aebd50a3d81c6ccf756e6=1619926677; Hm_lpvt_4233e74dff0aebd50a3d81c6ccf756e6=1619926677; LGRID=20210502113756-9a924450-7598-418b-b731-33046e64120c; _gid=GA1.2.1480471771.1619926677; SEARCH_ID=ab911c2ad61c47f2a94993729604d904' 14 } 15 16 # 用data进行分页爬取 17 for i in range(1, 31): 18 data = { 19 'first': 'true', 20 'pn': i, 21 'kd': '数据分析师' 22 } 23 24 # 请求网页 25 response = requests.post(url=url, headers=headers, data=data, timeout=3) 26 print(response.text) 27 time.sleep(3) # 休息一下 28 29 # json.loads 用于解码 JSON 数据。该函数返回 Python字段的数据类型 30 response = json.loads(response.content) 31 # 获取15条数据 32 result_15 = response['content']['positionResult']['result'] 33 # 获取每条招聘岗位里面的详细信息 34 for i in result_15: 35 position_id = i['positionId'] # 职位Id 36 position_name = i['positionName'] # 职位名称 37 company_full_name = i['companyFullName'] # 公司全称 38 company_short_name = i['companyShortName'] # 公司简称 39 company_size = i['companySize'] # 公司规模 40 finance_stage = i['financeStage'] # 融资阶段 41 company_label_list = i['companyLabelList'] # 公司标签 42 first_type = i['firstType'] # 第一类型 43 second_type = i['secondType'] # 第二类型 44 third_type = i['thirdType'] # 第三类型 45 position_labels = i['positionLables'] # 职位标签 46 industry_labels = i['industryLables'] # 行业标签 47 create_time = i['createTime'] # 创建时间 48 format_create_time = i['formatCreateTime'] # 格式化创建时间 49 city = i['city'] # 城市 50 district = i['district'] # 地区 51 salary = i['salary'] # 工资待遇 52 salary_month = i['salaryMonth'] # 工资月份 53 work_year = i['workYear'] # 工作年限 54 job_nature = i['jobNature'] # 工作性质 55 education = i['education'] # 教育背景 56 position_advantage = i['positionAdvantage'] # 岗位优势 57 hi_tags = i['hitags'] # 福利标签 58 # 存储数据, 先在当前文件下创建一个叫‘lagou_datas.csv’的文件 59 # 'a' 追加写入,;encoding设置编码格式,防止乱码 ;newline是为了解决写入时新增行与行之间的一个空白行问题 60 with open('./lagou_datas.csv', 'a', encoding='utf_8_sig', newline='') as f: 61 # 写入数据 62 csv_write = csv.writer(f) 63 # 按照以下行顺序写入,是一个列表 64 csv_write.writerow([position_id, position_name, company_full_name, company_short_name, company_size, 65 finance_stage, company_label_list, first_type, second_type, third_type, position_labels, 66 industry_labels, create_time, format_create_time, city, district, salary, salary_month, 67 work_year, job_nature, education, position_advantage, hi_tags]) 68 time.sleep(3) # 休息一下 69 # 主程序 70 if __name__ == '__main__': 71 # Ajax的URL 72 url = "https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false" 73 74 # 传入URL,调用函数 75 get_lagou_data(url) 76 #导入包 77 import pandas as pd 78 import numpy as np 79 import seaborn as sns 80 from pyecharts import Pie 81 from pyecharts import options as opts 82 import matplotlib.pyplot as plt 83 #导入数据 84 path = "C:/data/lago_data.csv" 85 df = pd.read_csv(path) 86 # 取出我们进行后续分析所需的字段 87 columns = ["positionName", "companyShortName", "city", "companySize", "education", "financeStage", 88 "industryField", "salary", "workYear", "hitags", "companyLabelList", "job_detail"] 89 df = df[columns].drop_duplicates() #去重 90 #数据清洗 91 # 数据分析相应的岗位数量 92 cond_1 = df["positionName"].str.contains("数据分析") # 职位名中含有数据分析字眼的 93 cond_2 = ~df["positionName"].str.contains("实习") # 剔除掉带实习字眼的 94 len(df[cond_1 & cond_2]["positionName"]) 95 # 使用条件 cond_1 和 cond_2 对数据框 df 进行筛选,只保留满足条件的行 96 df = df[cond_1 & cond_2] 97 98 # 删除名为 "positionName" 的列,axis=1 表示按列操作 99 df.drop(["positionName"], axis=1, inplace=True) 100 101 # 重置索引,drop=True 表示删除原来的索引,inplace=True 表示在原数据框上进行修改 102 df.reset_index(drop=True, inplace=True) 103 df["job_detail"] = df["job_detail"].str.lower().fillna("") #将字符串小写化,并将缺失值赋值为空字符串 104 105 df["Python/R"] = df["job_detail"].map(lambda x:1 if ('python' in x) or ('r' in x) else 0) 106 df["SQL"] = df["job_detail"].map(lambda x:1 if ('sql' in x) or ('hive' in x) else 0) 107 df["Tableau"] = df["job_detail"].map(lambda x:1 if 'tableau' in x else 0) 108 df["Excel"] = df["job_detail"].map(lambda x:1 if 'excel' in x else 0) 109 def clean_industry(industry): 110 # 将传入的行业字符串按逗号分割成列表 111 industry = industry.split(",") 112 # 如果列表的第一个元素是"移动互联网"且列表长度大于1,则返回第二个元素 113 if industry[0]=="移动互联网" and len(industry)>1: 114 return industry[1] 115 # 否则返回第一个元素 116 else: 117 return industry[0] 118 # 使用map函数将df中的industryField列应用clean_industry函数进行清洗 119 df["industryField"] = df.industryField.map(clean_industry) 120 #数据分析 121 # 创建一个12x8英寸的画布 122 fig, ax = plt.subplots(figsize=(12, 8)) 123 # 绘制一个柱状图,展示各城市数据分析岗位的需求量 124 # y轴表示城市名称,order参数按照城市需求量降序排列 125 # data参数指定数据来源为df,颜色设置为'#3c7f99' 126 sns.countplot(y="city", order=df["city"].value_counts().index, data=df, color='#3c7f99') 127 # 关闭箱线图显示 128 plt.box(False) 129 # 在画布上添加文本,设置字体大小、粗细、颜色和背景色 130 fig.text(x=0.04, y=0.90, s=' 各城市数据分析岗位的需求量 ', 131 fontsize=32, weight='bold', color='white', backgroundcolor='#c5b783') 132 # 设置刻度参数,主刻度字体大小为16 133 plt.tick_params(axis='both', which='major', labelsize=16) 134 # 设置x轴和y轴的网格线,宽度为0.5,颜色为'#3c7f99' 135 ax.xaxis.grid(which='both', linewidth=0.5, color='#3c7f99') 136 # 隐藏x轴和y轴的标签 137 plt.xlabel('') 138 plt.ylabel('') 139 # 计算行业字段的频次,并取前10个行业作为索引 140 industry_index = df["industryField"].value_counts()[:10].index 141 # 根据行业字段筛选出对应的数据 142 industry = df.loc[df["industryField"].isin(industry_index), "industryField"] 143 # 创建一个画布和坐标轴 144 fig, ax = plt.subplots(figsize=(12, 8)) 145 # 绘制一个柱状图,展示各行业的岗位数量 146 sns.countplot(y=industry.values, order=industry_index, color='#3c7f99') 147 # 关闭箱线图显示 148 plt.box(False) 149 # 在画布上添加文本,设置字体大小、粗细、颜色和背景色 150 fig.text(x=0, y=0.90, s=' 细分领域数据分析岗位的需求量(取前十) ', 151 fontsize=32, weight='bold', color='white', backgroundcolor='#c5b783') 152 # 设置刻度参数,主刻度字体大小为16 153 plt.tick_params(axis='both', which='major', labelsize=16) 154 # 设置x轴和y轴的网格线,宽度为0.5,颜色为'#3c7f99' 155 ax.xaxis.grid(which='both', linewidth=0.5, color='#3c7f99') 156 # 隐藏x轴和y轴的标签 157 plt.xlabel('') 158 plt.ylabel('') 159 # 创建一个12x8英寸的画布 160 fig, ax = plt.subplots(figsize=(12, 8)) 161 # 计算每个城市的薪资平均值,并按降序排序,将城市名称转换为列表 162 city_order = df.groupby("city")["salary"].mean() \n .sort_values() \n .index.tolist() 163 # 绘制柱状图,横坐标为城市名称,纵坐标为薪资,按照城市顺序排列,置信区间为95%,颜色为RdBu_r调色板 164 sns.barplot(x="city", y="salary", order=city_order, data=df, ci=95, palette="RdBu_r") 165 # 在画布上添加文本,设置字体大小、粗细、颜色和背景色 166 fig.text(x=0.04, y=0.90, s=' 各城市的薪资水平对比 ', 167 fontsize=32, weight='bold', color='white', backgroundcolor='#3c7f99') 168 # 设置刻度参数,主刻度字体大小为16 169 plt.tick_params(axis="both", labelsize=16) 170 # 设置y轴网格线,宽度为0.5,颜色为黑色 171 ax.yaxis.grid(which='both', linewidth=0.5, color='black') 172 # 设置y轴刻度标签,只显示数字部分 173 ax.set_yticklabels([" ", "5k", "10k", "15k", "20k"]) 174 # 关闭箱线图显示 175 plt.box(False) 176 # 隐藏x轴和y轴的标签 177 plt.xlabel('') 178 plt.ylabel('') 179 # 创建一个12x8英寸的画布 180 fig, ax = plt.subplots(figsize=(12, 8)) 181 # 在画布上添加文本,设置字体大小、粗细、颜色和背景色 182 fig.text(x=0.04, y=0.90, s=' 一线城市的薪资分布对比 ', 183 fontsize=32, weight='bold', color='white', backgroundcolor='#c5b783') 184 # 绘制北京的薪资密度曲线 185 sns.kdeplot(df[df["city"]=='北京']["salary"],shade=True,label="北京") 186 # 绘制上海的薪资密度曲线 187 sns.kdeplot(df[df["city"]=='上海']["salary"],shade=True,label="上海") 188 # 绘制广州的薪资密度曲线 189 sns.kdeplot(df[df["city"]=='广州']["salary"],shade=True,label="广州") 190 # 绘制深圳的薪资密度曲线 191 sns.kdeplot(df[df["city"]=='深圳']["salary"],shade=True,label="深圳") 192 # 设置刻度参数,主刻度字体大小为16 193 plt.tick_params(axis='both', which='major', labelsize=16) 194 # 关闭箱线图显示 195 plt.box(False) 196 # 设置x轴刻度标签,从0到60,步长为10,并添加千位分隔符 197 plt.xticks(np.arange(0,61,10), [str(i)+"k" for i in range(0,61,10)]) 198 # 隐藏y轴刻度标签 199 plt.yticks([]) 200 # 设置图例,字体大小为xx-large 201 plt.legend(fontsize = 'xx-large',fancybox=None) 202 # 计算Python/R技能的占比 203 py_rate = df["Python/R"].value_counts(normalize=True).loc[1] 204 # 计算SQL技能的占比 205 sql_rate = df["SQL"].value_counts(normalize=True).loc[1] 206 # 计算Tableau技能的占比 207 tableau_rate = df["Tableau"].value_counts(normalize=True).loc[1] 208 # 计算Excel技能的占比 209 excel_rate = df["Excel"].value_counts(normalize=True).loc[1] 210 # 打印职位技能需求 211 print("职位技能需求:") 212 print("Python/R:", py_rate) 213 print("SQL:", sql_rate) 214 print("Excel:", excel_rate) 215 print("Tableau:", tableau_rate) 216 # 定义一个函数,根据技能等级为数据框添加技能列 217 def get_level(x): 218 if x["Python/R"] == 1: 219 x["skill"] = "Python/R" 220 elif x["SQL"] == 1: 221 x["skill"] = "SQL" 222 elif x["Excel"] == 1: 223 x["skill"] = "Excel" 224 else: 225 x["skill"] = "其他" 226 return x 227 # 应用函数,为数据框添加技能列 228 df = df.apply(get_level, axis=1) 229 # 创建一个画布和坐标轴 230 fig, ax = plt.subplots(figsize=(12, 8)) 231 # 在画布上添加文本,设置标题、字体大小、粗细、颜色和背景色 232 fig.text(x=0.02, y=0.90, s=' 不同技能的薪资水平对比 ', 233 fontsize=32, weight='bold', color='white', backgroundcolor='#c5b783') 234 # 绘制箱线图,展示不同技能的薪资水平 235 sns.boxplot(y="skill", x="salary", data=df.loc[df.skill != "其他"], palette="husl", order=["Python/R", "SQL", "Excel"]) 236 # 设置刻度参数,主刻度字体大小为16 237 plt.tick_params(axis="both", labelsize=16) 238 # 设置坐标轴网格线宽度 239 ax.xaxis.grid(which='both', linewidth=0.75) 240 # 设置x轴刻度标签,从0到60,步长为10,并添加千位分隔符 241 plt.xticks(np.arange(0, 61, 10), [str(i) + "k" for i in range(0, 61, 10)]) 242 # 关闭箱线图的边框 243 plt.box(False) 244 # 设置x轴和y轴的标签,字体大小为18 245 plt.xlabel('工资', fontsize=18) 246 plt.ylabel('技能', fontsize=18) 247 # 定义公司规模映射字典 248 company_size_map = { 249 "2000人以上": 6, 250 "500-2000人": 5, 251 "150-500人": 4, 252 "50-150人": 3, 253 "15-50人": 2, 254 "少于15人": 1 255 } 256 # 定义工作年限映射字典 257 workYear_map = { 258 "5-10年": 5, 259 "3-5年": 4, 260 "1-3年": 3, 261 "1年以下": 2, 262 "应届毕业生": 1 263 } 264 # 将公司规模和工作年限映射到对应的数值 265 df["company_size"] = df["companySize"].map(company_size_map) 266 df["work_year"] = df["workYear"].map(workYear_map) 267 # 根据公司规模对数据进行排序 268 df = df.sort_values(by="company_size", ascending=True) 269 # 筛选出有工作年限的数据 270 df_plot = df.loc[~df.work_year.isna()] 271 # 定义颜色映射字典 272 color_map = { 273 5: "#ff0000", 274 4: "#ffa500", 275 3: "#c5b783", 276 2: "#3c7f99", 277 1: "#0000cd" 278 } 279 # 将工作年限映射到对应的颜色 280 df_plot["color"] = df_plot.work_year.map(color_map) 281 # 重置索引 282 df_plot.reset_index(drop=True, inplace=True) 283 # 定义绘图函数 284 def seed_scale_plot(): 285 seeds = np.arange(5) + 1 286 y = np.zeros(len(seeds), dtype=int) 287 s = seeds * 100 288 colors = ['#ff0000', '#ffa500', '#c5b783', '#3c7f99', '#0000cd'][::-1] 289 fig, ax = plt.subplots(figsize=(12, 1)) 290 plt.scatter(seeds, y, s=s, c=colors, alpha=0.3) 291 plt.scatter(seeds, y, c=colors) 292 plt.box(False) 293 plt.grid(False) 294 plt.xticks(ticks=seeds, labels=list(workYear_map.keys())[::-1], fontsize=14) 295 plt.yticks(np.arange(1), labels=[' 经验:'], fontsize=16) 296 # 绘制散点图 297 fig, ax = plt.subplots(figsize=(12, 8)) 298 fig.text(x=0.03, y=0.92, s=' 不同规模公司的用人需求差异 ', fontsize=32, 299 weight='bold', color='white', backgroundcolor='#3c7f99') 300 plt.scatter(df_plot.salary, df_plot["companySize"], s=df_plot["work_year"] * 100, alpha=0.35, c=df_plot["color"]) 301 362 plt.scatter(df_plot.salary, df_plot["companySize"], c=df_plot["color"].values.tolist()) 302 plt.tick_params(axis='both', which='both', length=0) 303 plt.tick_params(axis='both', which='major', labelsize=16) 304 ax.xaxis.grid(which='both', linewidth=0.75) 305 plt.xticks(np.arange(0, 61, 10), [str(i) + "k" for i in range(0, 61, 10)]) 306 plt.xlabel('工资', fontsize=18) 307 plt.box(False) 308 # 调用绘图函数 309 seed_scale_plot() 310 # 从数据框df中筛选出公司规模为"2000人以上"且技能不为"其他"的行,并获取这些行中的技能列的值计数(去重后),并进行归一化处理 311 df_skill = df.loc[(df["companySize"]=="2000人以上")&(df.skill!="其他")]["skill"].value_counts(normalize=True) 312 # 绘制条形图,展示技能占比情况 313 fig, ax = plt.subplots(figsize=(12, 6)) 314 sns.barplot(x=df_skill.index,y=df_skill.values, color='#3c7f99') 315 # 关闭箱线图边框 316 plt.box(False) 317 # 在图表上方添加标题和背景色 318 fig.text(x=0.08, y=0.9, s=' 大公司对技能的要求占比 ', 319 fontsize=32, weight='bold', color='white', backgroundcolor='#c5b783') 320 # 设置坐标轴刻度标签的字体大小 321 plt.tick_params(axis='both', which='major', labelsize=16) 322 # 设置y轴网格线 323 ax.yaxis.grid(which='both', linewidth=0.5, color='#3c7f99')
总结
通过对拉勾网数据分析师岗位的分析,我们可以看出数据分析师岗位需求量较大,且有逐年上升的趋势,这说明数据分析在企业中的地位越来越重要,对于求职者来说,具备数据分析能力将有助于提高就业竞争力,并且数据分析师岗位的薪资水平较高,且同样呈现逐年上升的趋势。这表明数据分析行业的发展势头良好,从事这一行业的人员可以获得较高的回报,但是数据分析师岗位对于工作经验和技能要求较高。大部分岗位要求具备3-5年以上的工作经验,以及熟练掌握Excel、SQL、Python等技能。这对于刚刚步入职场的应届生来说,无疑增加了求职的难度。
在完成此设计过程中,我掌握了Python爬虫的基本技巧,如请求库、解析库的使用,以及如何应对反爬机制等。学会了如何使用Python进行数据处理和分析,如数据清洗、数据筛选、数据统计等了解了数据可视化的基本原理和方法。