Cross-modal Moment Localization in Videos
摘要:在本文中,我们探讨了时间时刻定位问题,即在未经剪辑的视频中定位自然语言查询所描述的视频时刻。这是一项通用但极具挑战性的视觉语言任务,因为它不仅需要对时刻进行定位,还需要对文本时间信息(如 "第一次 "和 "离开")进行多模态理解,以帮助将所需时刻与其他时刻区分开来,尤其是那些具有相似视觉内容的时刻。现有的研究将给定的语言查询视为一个单一的单元,而我们建议将其分解为两个部分:与所需时刻定位相关的线索和与定位无关的线索。这使我们能够在端到端框架内灵活地适应任意查询。在我们提出的模型中,语言-时间注意力网络被用来根据视频中的时间上下文信息来学习单词注意力。因此,我们的模型可以自动选择 "听什么词 "来定位所需的时刻。我们在两个公共基准数据集上对所提出的模型进行了评估: DiDeMo 和 Charades-STA。实验结果验证了该模型优于几种最先进的方法
1 introduction
相比传统视频检测任务,在TALL任务中,查询要复杂很多,包含有多主体,动作还有复杂的时间关系,比如如图 1 所示,句子 "摩天轮首先出现在视野中 "它强调了首次出现,视频中会出现两次,关键在于理解复杂的查询信息,并专注所需要的最关键的词word。
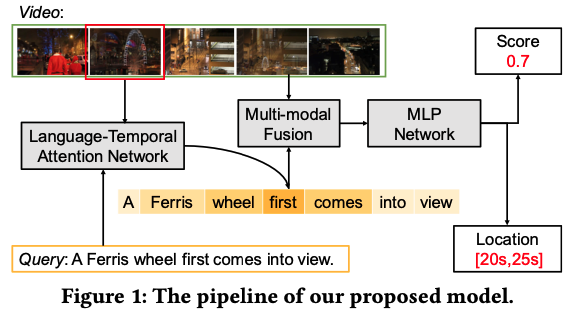
图 1:我们提出的模型的流程。
现有方法如LSTM可能会忽略掉具有时间和语义线索的关键词,比如图1中的第一次,可能LSTM理解到了第一次的语义,但是与摩天轮的实体相比权重不够,也即不够强调,没有抓出关键词,这样可能就会在第一次和第二次之间出错。
首先,我们设计了一个语言-时间注意模块,根据查询文本信息和时刻上下文信息,自适应地重新权衡每个单词的特征,从而得出有效的查询表示。这种查询表征可以识别 "哪些词需要听",并对与时刻定位无关的查询变化具有更强的鲁棒性。然后,我们堆叠了一个多模态处理模块,对查询和时间上下文特征进行联合建模。最终,我们训练一个多层感知(MLP)网络来估计相关性得分和所需时刻的位置。在两个公共数据集上进行的广泛实验证明,我们的模型明显优于最先进的基线模型。
这项工作有三方面的贡献:
- 我们提出了一种跨模式时空时刻定位方法,这种方法能够自适应地编码复杂而重要的语言查询信息,以定位所需的时刻。
- 我们提出了一种语言-时间注意力网络,该网络可联合编码文本查询、本地时刻及其上下文时刻信息,以理解查询描述。据我们所知,这是首个基于查询注意力机制的时态时刻定位网络。
- 我们在 DiDeMo 和 Charades-STA 两个大型数据集上评估了我们提出的模型,以证明其性能的提高。我们还发布了数据1 和代码。
本文接下来的内容安排如下。第 2 节回顾了相关工作。第 3 节和第 4 节分别详细介绍了时矩定位问题和我们提出的 ROLE 模型。第 5 节介绍了实验结果,第 6 节是结论和未来工作。
2 相关工作
2.1 Grounding Referential Expressions
参照表达式的定位任务 [17, 21, 43, 44] 是定位给定参照表达式所描述的图像区域。它通常被表述为图像区域的检索问题。因此,首先要将每幅图像分割成一组区域提案 [2、13、36、45],然后采用不同的策略对每个候选提案与查询表达式进行评分。最后,得分最高的候选方案将被返回作为接地结果。
在计算每个候选方案与给定表达之间的匹配得分方面,人们做了大量的工作。Mao 等人[20]提出了一种联合考虑局部候选特征和整体图像特征的模型来预测每个候选提案的匹配得分。然而,这不足以判断提案是否与表情匹配。随后,Yu 等人[42] 发现,与图像中其他对象进行视觉比较有助于显著提高性能。因此,他们将从图像中其他区域提案中提取的上下文特征整合到了模型中。不过,上述所有方法都是使用递归神经网络(RNN)整体表示表情。也就是说,它们要么预测了参考表达式的分布,要么将表达式编码为向量表示。因此,它们可能无法很好地学习表情中的成分与图像中的实体之间的明确对应关系。最近,一些研究人员尝试将给定的语言表达解析为文本成分,而不是将其视为一个整体,并将这些成分与图像区域端对端对齐。Hu 等人[10]使用三种软注意力图谱将指代表达解析为主语、关系和宾语,并使用模块化神经架构将提取的文本表示与图像区域对齐。同样,Yu 等人[41] 通过软注意力将表达分解为三个模块化组件,分别与主体外观、位置以及与其他对象的关系相关。
尽管这些模型在其专用任务中被证明是强大的,但简单地将它们扩展到时间时刻定位任务中是不合适的。它们可能会忽略视频中的时间信息,但与静态图像相比,时间信息却是最显著的特征。
2.2 Temporal Action Localization
时间动作定位是一项给定一段未经剪辑的长视频,预测特定动作开始和结束时间的任务 [6, 15, 19]。Sun 等人[33]通过将图像标签转移到他们的模型中,解决了从未经时间修剪的网络视频中进行细粒度动作定位的问题。随后,Shou 等人[27] 利用多级 3D ConvNets 对野外未经修剪的长视频进行时间动作定位。Ma 等人[19]在 RNN 学习目标中引入了新的排序损失,以更好地捕捉活动的进展。与此同时,Singh 等人[30] 通过利用演员周围边界框的特征来增强全帧图像特征,从而扩展了双流框架[28]。最近,Gao 等人[8] 引入了一种新颖的时空单元回归网络,通过时空坐标回归联合预测动作建议并细化时空边界。然而,这些动作定位方法仅限于预定义的动作列表。最近,Gao 等人[7] 提出了通过自然语言查询定位活动的方法。他们提出了一种跨模态时序回归定位器,对文本查询和视频时刻进行联合建模。Hendricks 等人[1]设计了一种时刻上下文网络,通过整合本地和全局视频特征来定位视频中的语言查询。虽然这两个模型在各自的任务中表现良好,但它们总是将整个查询编码为一个单一的特征,这可能不足以揭示查询所传达的信息。
2.3 Language Grounding in the Video
视频检索[3, 38]的目的是从给定自然语言查询的候选视频集合中检索视频[22, 35, 37],与此不同,视频中的语言接地是一项将视频中的物体和动作空间接地,或将文本短语与时间视频片段对齐的任务[9, 25, 32]。关于这一问题的研究很少,而且在自然语言词汇方面受到严重限制。Tellex 等人[34]提出了一个模型,利用包含一组固定空间介词的查询来检索家庭监控摄像头中的视频片段。Yu 等人[40]只考虑了四个对象和四个动词,从与句子配对的短视频片段中学习单词的表征。Lin 等人[14]提出了一种模型,通过将描述解析为语义图来定位视频中的物体,然后通过求解线性程序将语义图与视觉概念相匹配。Regneri 等人[24] 提出了一种通用语料库,可将高质量视频与视频中动作的多种自然语言描述相匹配。Bojanowski 等人[4]介绍了一种自动为每个句子提供时间戳的方法,即把视频与其自然语言描述对齐。视频-文本配准任务提供了一段视频和一组有时间顺序的句子,与此不同,我们的模型只输入一个查询。此外,将指令与视频对齐的方法仅限于结构化视频,因为它们通过指令排序来限制对齐。
3 TEMPORAL MOMENT LOCALIZATION
在本节中,我们首先制定时间矩定位的任务。 然后,我们介绍两个最先进的模型,它们是我们工作的基本组成部分。
为了表述问题,需要提前声明一些符号。 特别是,我们使用粗体大写字母(例如 X)和粗体小写字母(例如 x)分别表示矩阵和向量。 我们使用非粗体字母(例如 D)表示标量,使用数学书法(例如 C)表示集合,使用希腊字母(例如 λ)表示参数。 如果没有明确说明,所有向量都是列形式。
3.1 Problem Formulation
最近,在较长且未修剪的视频中的活动或对象定位方面取得了巨大进展,旨在定位与预定义语言词汇相对应的时间活动时刻或对象。 然而,当我们试图定位某个特定时刻时,例如描述为“橙猫先攻击别人的尾巴”,简单的动作、对象或属性关键字不足以唯一地识别这样的黄金时刻。 一个简单的解决方案是使用自然语言短语进行查询。 受此启发,提出了带有语言查询的视频中的时刻定位任务。 它的目的是在给定自然语言描述时从视频中找到特定的时间段(即时刻)[1, 7]。 这些时刻与本地化视频的开始和结束时间点相关。
这些模型通常在时刻检索设置中工作:给定视频 V = {f1, f2,... , fN },其中 fi 表示第 i 个视频帧,以及具有开始时间 τs 和结束时间 τe 的语言查询 Q,即期望时刻的开始时间和结束时间。 然后将视频分割成一组候选时刻 C = {c1, c2,..., cM } 通过滑动窗口策略 [1, 7],每个候选 ci 都分配有一个时间边界框 [ts , te ]。 因此,模型只需要估计每个候选时刻和查询的相关性得分。
图 2 显示了瞬时矩定位的示例。 视频中,一只橘猫看着黑猫的尾巴,跳起来攻击黑猫的尾巴,然后摔倒。 在这里,我们给出一个语言查询“橙色猫首先攻击其他人的尾巴”,并期望时刻定位模型返回相应时刻(在绿色边界框中)的开始时间(6s)和结束时间(10s)。

图 2:在未修剪的视频中通过语言查询进行时间矩本地化。
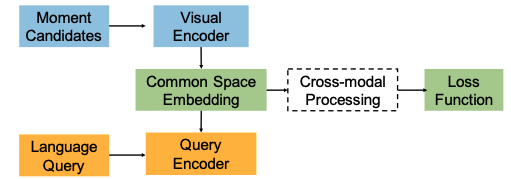
图3:现有时间定位方法的统一框架。 虚线是CTRL模型的独特模块。
3.2 Moment Localization Model
为了很好地匹配查询和候选时刻,一种直观的方法是将候选时刻的视觉特征和查询的文本特征映射到公共空间,然后最小化每个正时刻-查询对的距离。 受这种直觉的启发,提出了两种最先进的方法。 第一个是联合视频语言模型,命名为Moment Context Network(MCN)[1],其中鼓励查询和视频的特征在共享嵌入空间中接近。 类似地,提出了一种跨模态定位模型,称为跨模态时间回归定位器(CTRL)[7],如图3所示。
这两种模型有几个不同点。 1)上下文信息。 两个模型都将当前时刻及其上下文时刻的视觉特征连接成单个向量,然后将其线性变换为最终的视觉特征。 为了构建矩上下文,MCN 采用整组候选矩,而 CTRL 采用邻居前上下文矩和后上下文矩。 2) 查询编码器。 MCN将LSTM网络的最后输出视为查询特征; 同时,CTRL采用离线Skip-Thoughts特征来表示查询。 3)跨模式处理。 CTRL利用多模态融合方法融合公共空间中的query和moment特征; 而MCN直接计算公共空间中矩和查询特征之间的距离。
虽然与基线相比表现良好,但这些模型从整体上处理查询,并忽略了传达重要时空线索的关键字的有效性。 我们注意到,根据所需时刻的独特性,一个查询中的单词对估计的贡献不同。 例如,如果目标时刻是关于所有人中的“一个穿红外套的女孩”,则单词“女孩”和“红色”应该对相关性估计贡献最大。 如果同一个女孩出现多次,并且给定的查询变为“红衣女孩第一次出现”,则上下文信息“第一次”应该成为定位所需时刻的关键贡献者。 因此,将注意力机制与时刻检索模式相结合,逐字读取查询并根据时间上下文信息细化其注意力是自然而直观的
4 ROLE模型
在本节中,我们详细介绍我们的跨模态矩定位网络(ROLE),它由语言时态注意力网络、多模态处理和 MLP 模块组成。 特别是,给定一个候选时刻 ci 和一个语言查询 Q,我们首先使用注意力网络根据时刻上下文自适应地重新权衡有用单词的权重分数。 此后,我们利用多模态处理模块来融合查询和矩表示。 进行 MLP 来计算相关性得分,衡量 ci 和 Q 之间的兼容性以及时刻位置。
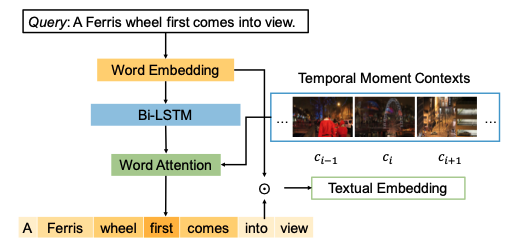
图 4:语言-时间注意力网络的图示。
4.1 语言-时间注意力网络
注意力网络如图4,对于一个给定的请求\(Q\)我们表示成T个单词的序列\(\{w_t\}^T_{t=1}\),我们通过 Glove 将每个单词 \(w_t\) 投影到嵌入向量 \(e_t\) 中,此后,采用双向 LSTM 对整个查询进行编码,以序列 \(\{e_t\}^T_{t=1}\) 作为输入,并在每个时间 t 输出前向隐藏状态 \(h^{fw}_t\) 和后向隐藏状态 \(h^{bw}_t\)。然后,我们将 \(h^{fw}_t\) 和 \(h^{bw}_t\) 连接成 \(h_t\) ,其中包含单词 \(w_t\) 以及 \(w_t\) 之前和之后的上下文单词的信息。 它可以用以下等式表示:
为了获得给定查询的表示,一种直接的方法是平均池化所有单词表示 \(h_t\) 。 虽然上述解决方案似乎合理且合理,但缺点是查询中的所有单词对查询嵌入的贡献相同,而忽略了它们特定于场景的置信度。 如前所述,单独使用此类表示可能无法区分所需时刻与具有相似视觉特征的时刻。为了解决这些问题,我们将时间时刻上下文输入到我们的注意力模型中,该模型能够分配具有更高重要性分数的更有用的单词。 因此,给定 \(H ={ht}t=1\),输入矩 \(c_i\),及其时间矩上下文 \(c_j (j \in \{i−n,...,i−1,i+1,...,i+n\})\),\(n\)是时刻上下文的邻居大小, 我们将注意力模型制定如下,
其中\(x_{c_j}\)是每个候选时刻的特征向量,\(\beta\)是一个超参数, \(W_q\) 和\(W_c\)分别代表本文和时间的嵌入矩阵 \(b\)是一个偏移向量,\(f\)是ReLU函数。
在建立查询中每个单词的注意嵌入之后,我们可以将查询的表示构造为:
4.2 loss function
目前通过4.1 得到了文本嵌入向量\(q\)和滑动窗口分割的当前和相邻时刻的时空视频嵌入向量\(x_{c_j}\),因此,我们可以通过使用连接运算符来导出当前查询时刻对的跨模式表示,如下所示:
其中\(\oplus\)表示向量串联运算符,所以\(x_{c,q}\)是能够跨文本模态和视觉模态编码信息。