Spanner
Megastore 存在各种缺点:跨实体组事务需要昂贵的两阶段事务,所有跨数据中心的数据写入都通过Paxos算法,使得单个实体组只能支持每秒几次的事务。
Spanner 是一个全新设计的新系统,而不是Megastore或Bigtable上的修修补补。两个主题:
- 解决了Megastore中哪些不足
- 数据库事务,特别是跨数据中心事务中和“时间”有关概念
Megastore 能否全球部署?
“Spanner 是为百万级别服务器、上百个数据中心、万亿级数据量打造的分布式数据库”如果将Megastore部署成一个全球式百万级分布式数据库,存在一个主要问题:网络时延。Megastore中每个数据中心都是一个Paxos集群的完全副本,每次数据写入都要有网络请求到所有数据中心。城际的写事务可能要30~50毫秒,洲际的写事务可能要100~200毫秒,甚至更长时间。
为了容错需要数据在多个数据中心同步复制;为了避免过大的网络延时,不能把数据放在太多的数据中心里。最佳策略:让数据副本尽量放在离会读写它的用户近的数据中心。
Spanner 整体架构
一个部署好的Spanner数据库被称为“宇宙”(Universe),其中会有很多个区域(Zone)。每个Zone中都有一套类似Bigtable这样的分布式数据库系统,可看成内网中一套类似Bigtable的部署。很多个类Bigtable部署共同组成一个Spanner宇宙。
Spanner复制数据就是复制到不同“Zone”里,一个数据中心有多个“Zone”,就是多套不同类Bigtable部署。同一个数据中心里的不同Zone是物理隔离的,不能直接互相访问。服务器分三类:
- Zonemaster,把数据分配给Spanserver
- Spanserver,把数据提供给客户端
- Location Proxy,让客户端定位哪个Spanserver可提供自己想要的数据
Zonemaster 与 Bigtable 类似,都是通过Master管理数据分区,通过 server 提供在线服务,数据在哪个分区不是从Master查询,而是独立剥离出来,避免Master成为系统性能瓶颈
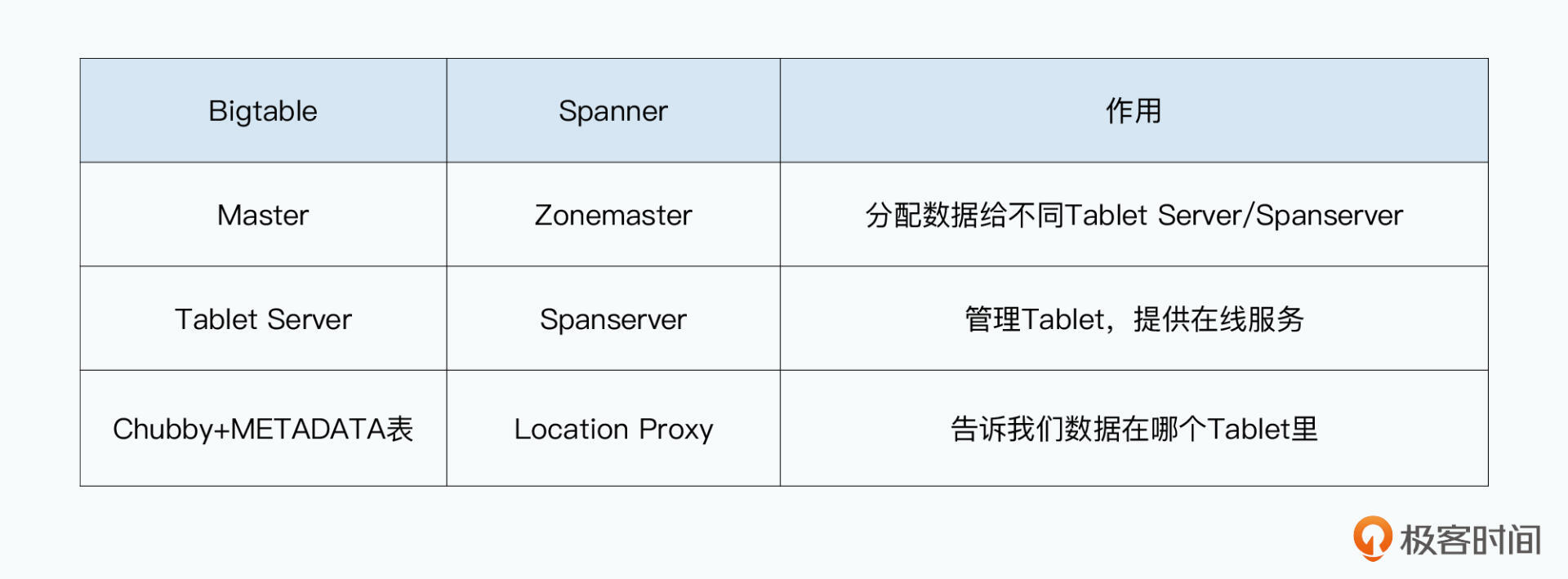
一个Zone中只有一个Zonemaster,但会有多个Location Proxy,成百上千个 Spanserver。每个Spanserver和Bigtable的Tablet server类似,负责管理几百个Tablet。
在Zone之上,整个Spanner宇宙里,还有两个:
- Universemaster:宇宙的Master,只是提供一系列的控制台信息,例如Zone的各种状态信息
- Placement Driver:调度数据,把数据分配到不同Zone中,这个分配策略是使用数据库的应用程序就可以定义的
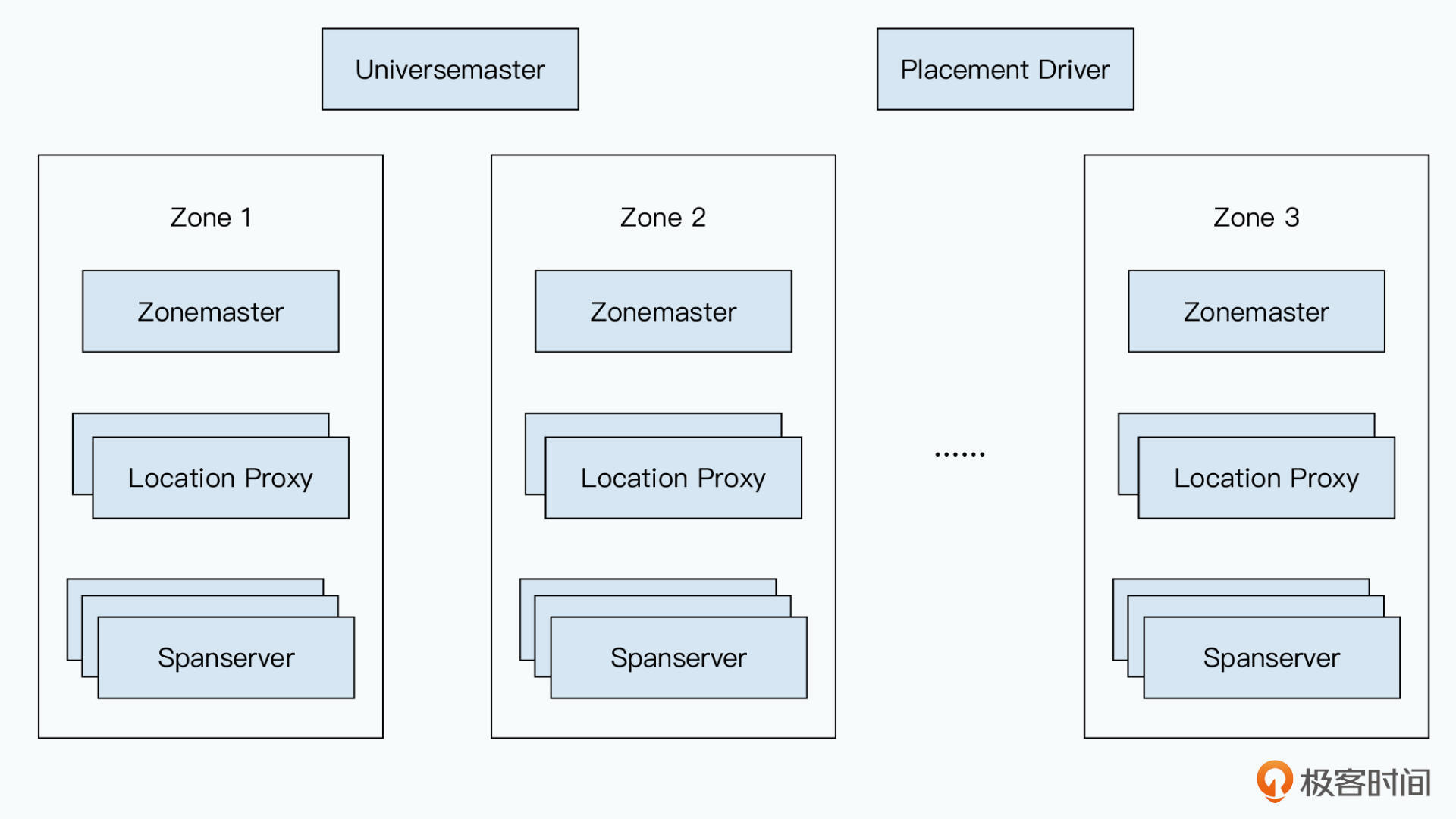
它支持的一些控制策略:
- 指定哪些数据中心该包括哪些数据
为让开发者能够决定数据在不同Zone的分布 - 申明要求数据距离用户有多远
为了控制用户读取时延,动态根据用户的访问时延调度数据应放在哪些Zone中 - 申明不同数据副本间距离有多远
为了控制用户写入时延,例如上海用户写入的数据没必要复制到欧洲一份 - 申明需要维护多少副本
为了控制系统的可用性和读操作性能,副本越多可用性越高、越能低时延的读到数据。
第一个策略在Megastore上可通过程序员手动“分库分表”实现,将数据拆分到多个Megastore里即可。更好的做法是让Spanner自己调度,用户无需关心底层细节。
Spanserver 实现
架构
Spanner的底层数据存储是一个B树及对应的预写日志(WAL)。SSTable采用LSM树,类似KV数据库;Spanner 更像一个关系数据库。Megastor利用Bigtable上每列的时间戳实现MVCC下的隔离性,但是数据库的“版本”应该在整条数据上而非某列数据,数据库事务针对的应该是整条数据记录。否则在更新数据时,要先读出所有列的数据再重新用一个版本写回去。
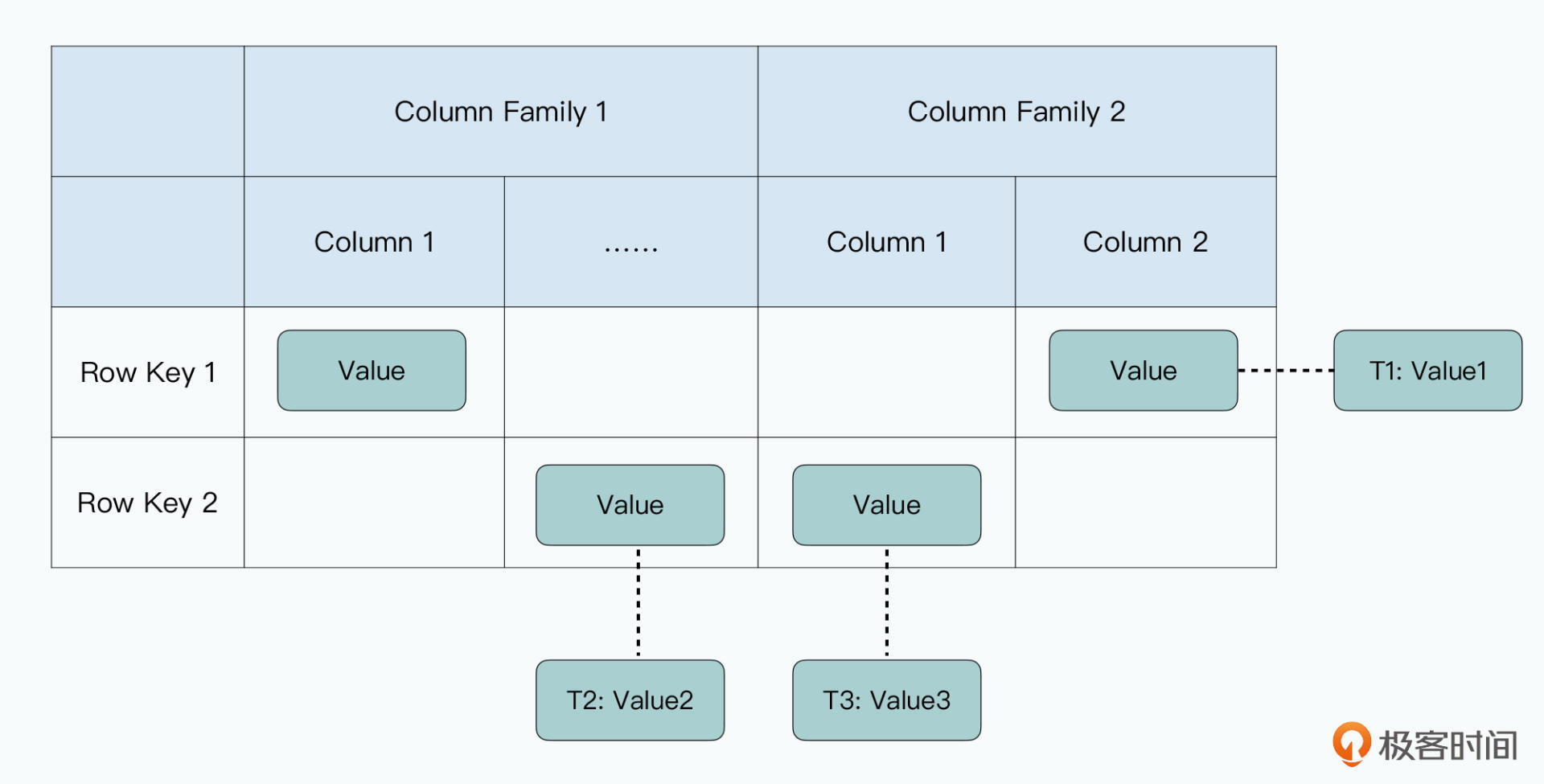
Megastore 存在 Bigtable 中一行数据每列的value可能有不同的时间戳
Spanner 的实现中,对应时间戳再整条数据上:(key:string, timestamp:int64) => string 而不像Bigtable中将列族和列也放到映射关系之前。Spanner的底层数据存储落在一个叫Colossus的分布式文件系统。采用Paxos算法同步复制数据,作用在每个Tablet上。Spanner中的Tablet不像实体组,而是只有一条根实体记录,对事务产生很大影响。
采用基于Leader的Paoxs算法,不过Leader不是在每轮事务中指定,因为其不像Megastore中每个实体组都是一个迷你数据库。一个Paxos状态机要管理整个Tablet里多跳记录,这个Leader类似Chubby锁里的“租约”机制。租约0~10s期间Leader不会改变,写入也是从Leader发起的,所有副本都有完整数据,多以读数据可从任意副本进行。
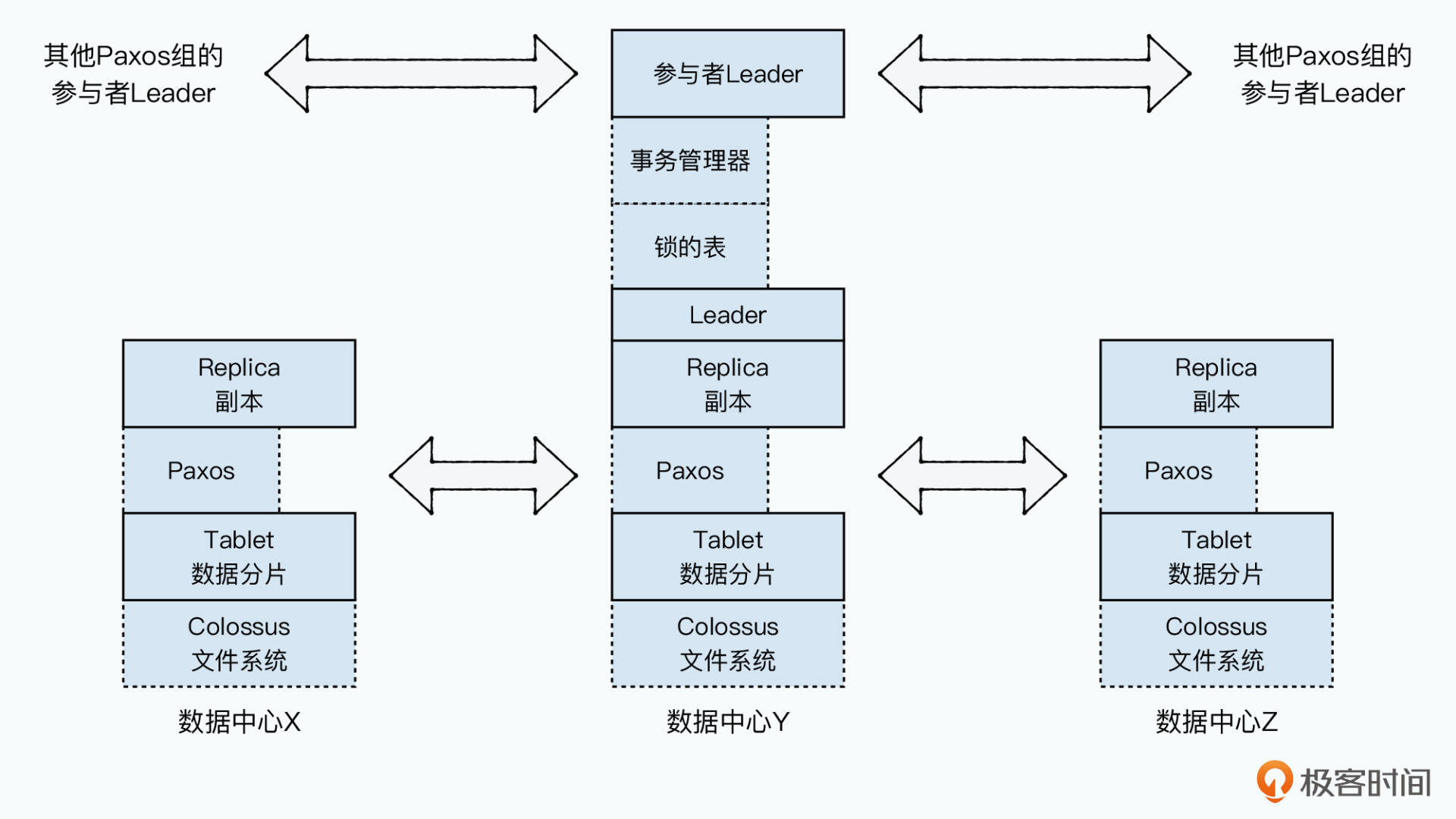
数据写入时Spanner写入两份日志:Paxos日志,Tablet日志。
Spanner 完全重新设计开发了一个支持同步复制的底层存储引擎,Megastore基于Bigtable间接实现日志和数据存储
数据调度
一个Tablet及所有副本组成一个Paxos组,在不同数据中心间的数据调度就是在不同Paxos组间进行的。不同Paxos组可能涵盖相同Zone,Spanner 的数据时在各个Zone间混合存储的,而非像MySQL那样分库分表。
Spanner 的数据调度不是一条条的,而是一片一片的。一小片连续的行键在Spanner中叫做一个“目录”(Directory)。一个Paxos组包含多个目录。Bigtable中一个Tablet中行键是连续的;但Spanner中一个目录中行键是连续的,不同目录间是离散的。这样是因为:数据访问有局部性,但不是所有连续的行键数据都会被一起频繁访问。
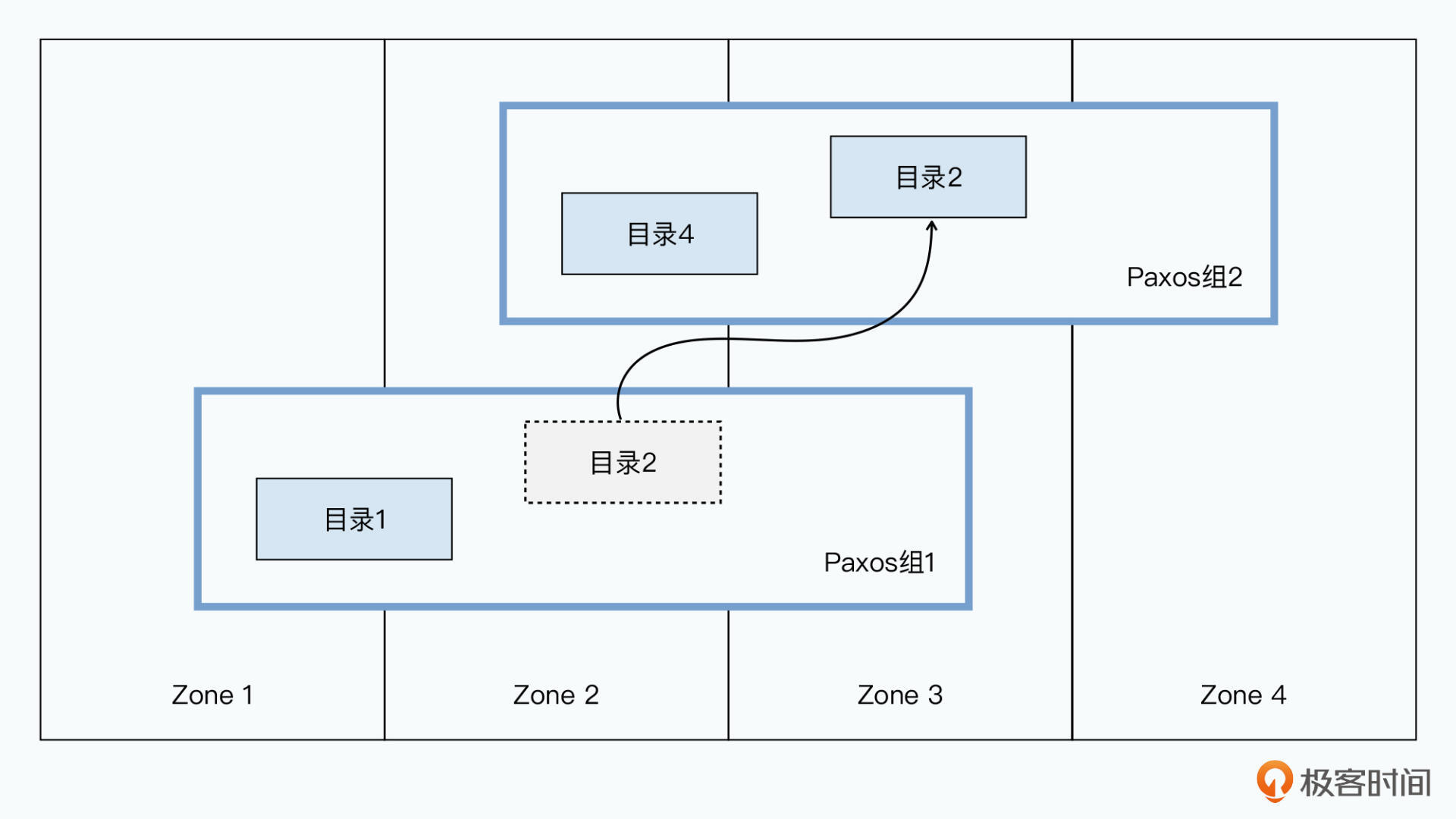
这种设计下,那些频繁共同访问的目录可调度到相同Paxos组。这样无论读写都可在一个Paxos组里完成。这样可根据实际数据被访问后的统计进行动态调度,而不是局限于设计表结构时要万无一失。
不同Paxos组间数据的转移通过一个movedir后台任务。为了避免在转移数据过程中阻塞正常的数据事务读写,这个任务不是一个事务。它在后台快将所有数据转移完成时,再启动一个事务转移最后剩下的数据来减少阻塞时间。
当一个目录变得太大时Spanner还会分片存储,不同分片存到不同Paxos组,也就是不同Zone和服务器,movedir转移的也不是整个目录而是分片。
数据模型
Spanner的数据模型和Megastore基本一致。一个相册例子:
CREATE TABLE Users {
uid INT64 NOT NULL, -- 主键,数据表行键
email STRING
} PRIMARY KEY (uid),DIRECTORY;
CREATE TABLE Albums {
uid INT64 NOT NULL,
aid INT64 NOT NULL,
name STRING
} PRIMARY KEY (uid,aid), -- 联合主键
INTERLEAVE IN PARENT Users ON DELETE CASCADE; -- 父表的行键和子表所有相同行键数据共同构成一个目录
-- 构成级联删除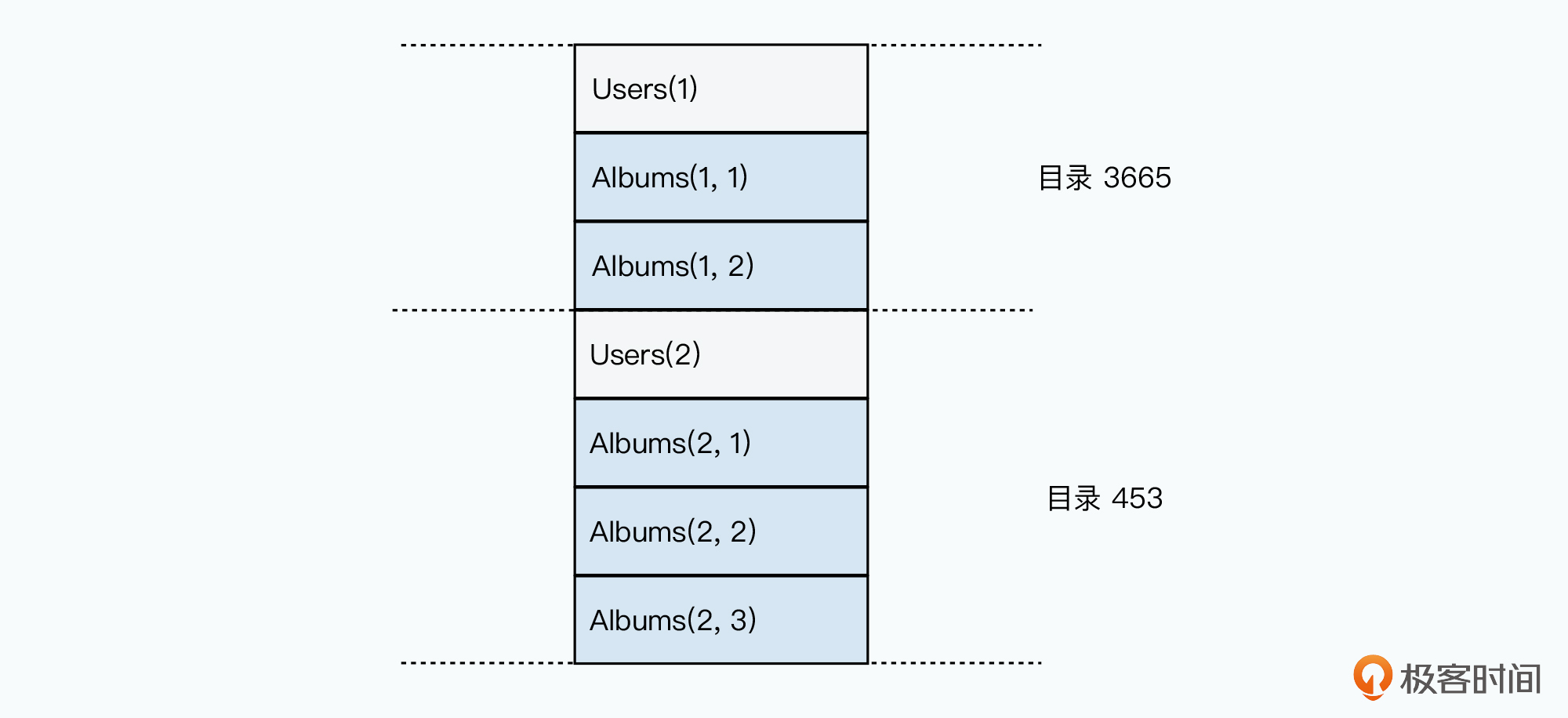
图中一对多的外键关联是明确定义的,方便Spanner管理数据布局和目录调度,先沟通的父子行的数据在一个目录中
小结
- 整体架构,多个Zone里的一个个分布式数据库组合在一起
Megastore中每个数据中心有完全相同副本;Spanner每个Zone的数据可能完全不同,根据延时策略将不同数据调度到不同数据中心 - 单个Zone内,有Zonemaster、Spanserver、LocationProxy三种不同服务对应Bigtable中服务
多个Zone之上,通过Universemaster作为控制台控制Zone,通过Placement Driver进行调度 - Spanserver采用B树,而不是Bigtable的稀疏列+LSM树
- 数据的同步复制层面,Spanner将Tablet作为单元,Megastore将实体组作为单元。Metastore在每次数据写入时写入Leader,Spanner为Leader设定租期
- 数据调度层面,Spanner以目录为单位调度数据,目录的大小介于Tablet和记录之间,这也使得单个Tablet里的数据不一定是连续的行键
- 数据模型层面,Spanner基本继承Megastore,不同数据表间明确对应的父子关系有助于Spanner调度数据,将经常要共同访问的数据放到同一个Zone
时间性能
Spanner的整个架构仍遵循标准的分布式数据库的架构设计,让数据尽可能接近用户以尽可能减小网络时延。最大的挑战是如何实现事务,两个要点:
- 在不可靠网络和不可靠时钟下,有哪些实现事务的困扰?
- 为什么Megastore的2PC难以解决,该如何设计解决?
Megastore 事务性能
Megastore只在单个实体组实现一阶段事务,跨越实体组时需要采用消息机制或2PC。例如A转账给B时,必须使用2PC。此时应该采用A所在Paxos的Leader作为协调者还是B的?还是使用整个Spanner宇宙的协调者?还是直接使用客户端作为协调者?若通过B向C、C向A转账,那协调者又该是谁?三个事务并发时如何解决冲突?
因为每个事务请求来自不同客户端,所以客户端不知道有哪些并发事务更无法解决冲突,所以不能让客户端作为协调者。也不能使用Spanner宇宙级别协调者,无论是并发数、网络延时都会超出其负载。所以还是让Paxos的Leader作为协调者出现。事务跨越不同Paxos Group时,要两个Paxos的Group之间做一些协调工作并解决潜在的并发冲突问题。
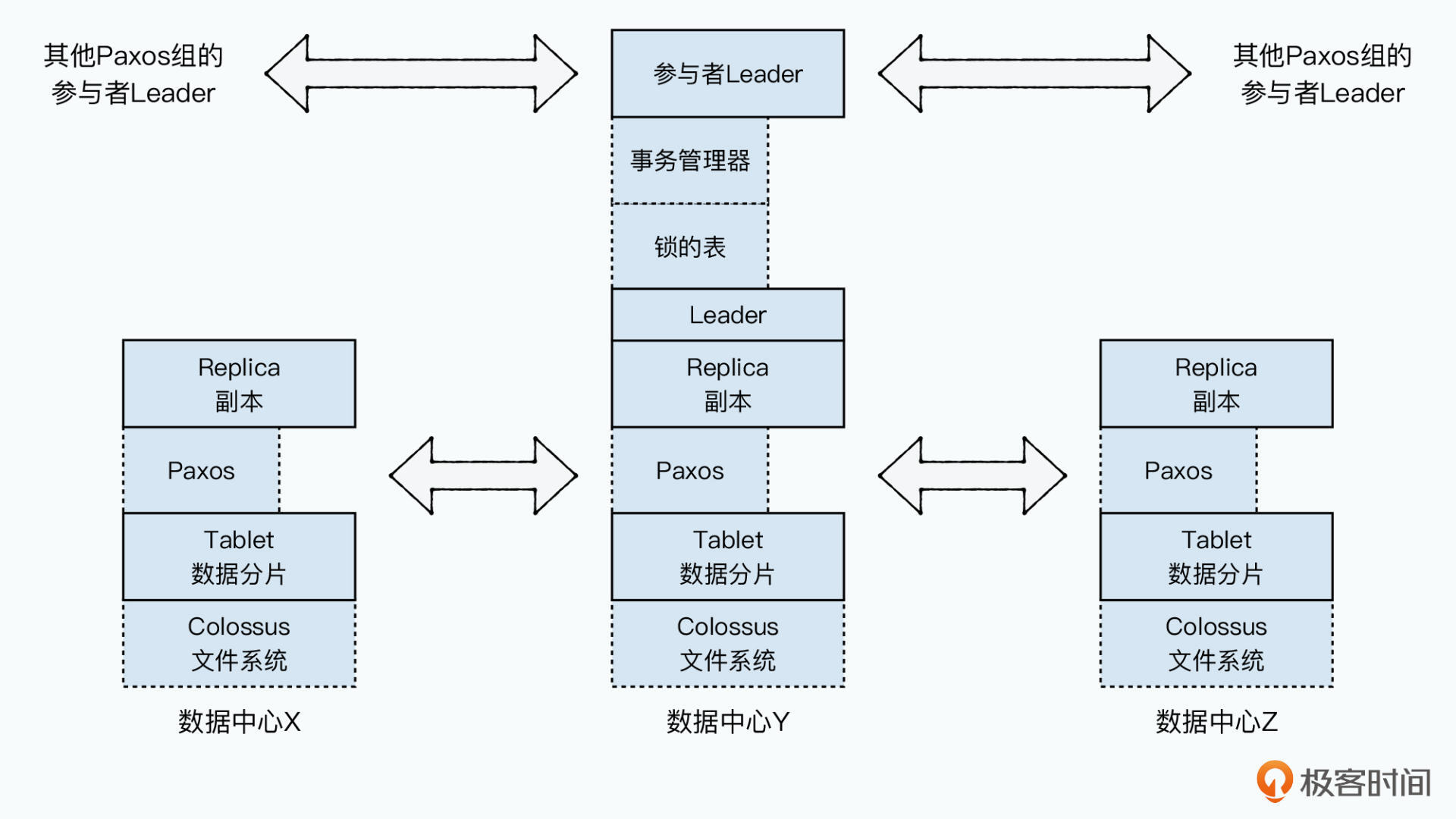
每个Spanserver上都有一个事务管理器用于支持分布式事务,其也是参与者Leader(Participant Leader),会和其他参与者Leader协商,完成事务的2PC。每个Spanserver里,都有一张锁表(Lock Table),要实现事务时从锁表里获取锁。
单个Paxos Group内部的事务无需使用事务管理器,直接从锁表获取锁,在本地通过Paxos进行事务日志提交即可。跨Paxos Group的事务,通过多个事务管理器互相协调实现一个2PC。整个事务管理器通过存储到下面的Paxos组里,复制到多个副本中。所以事务管理器的事务状态都是持久化并高可用的。
分布式事务下的可线性化
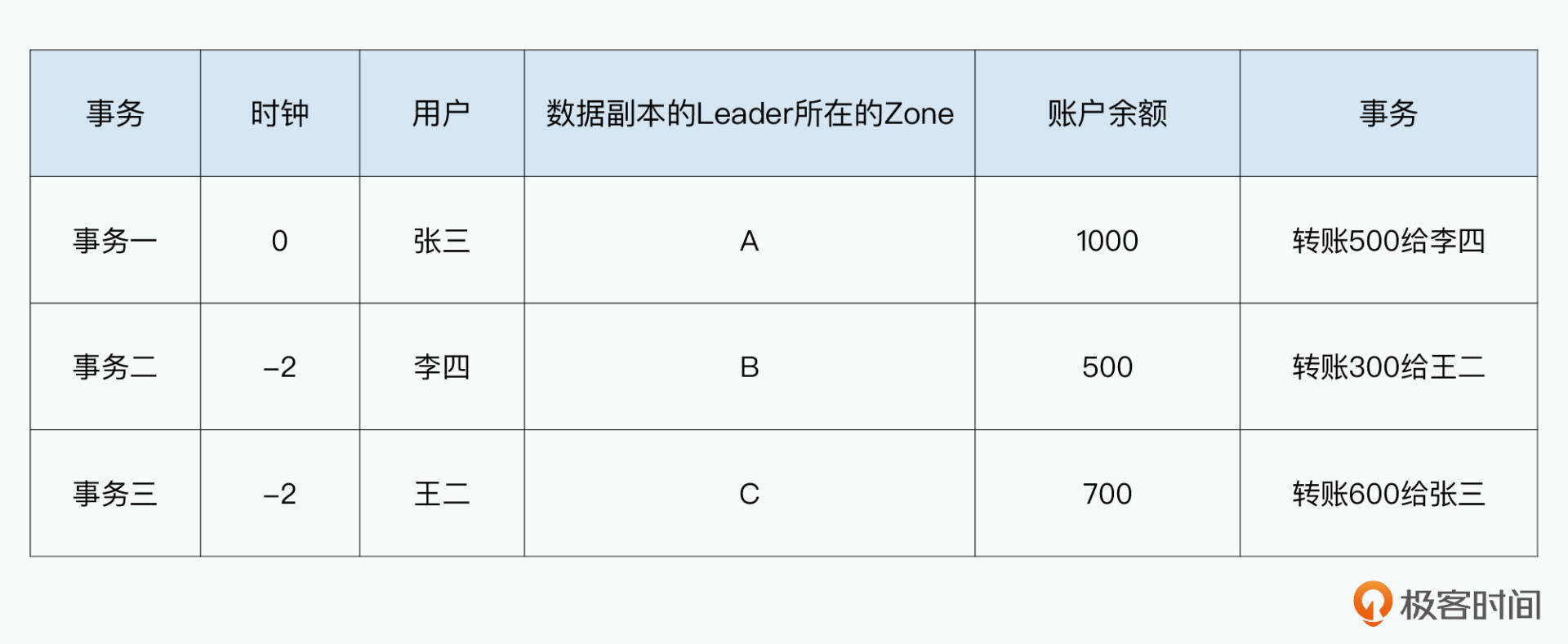
两个事务并发:张三转账给李四,李四转账给王二。这三个人不在一个Paxos组,所在Paxos组的Leader也不在同一个Zone。
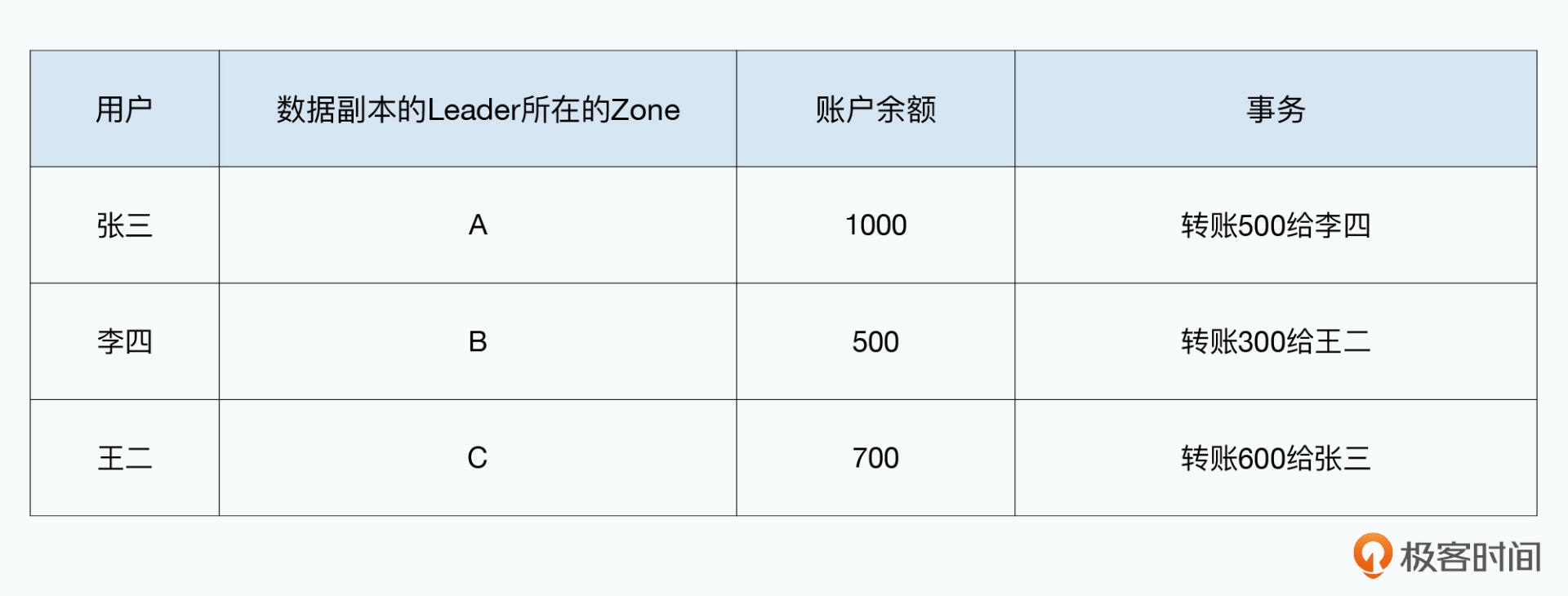
三个事务并发:
- 张三(1000)-500-> 李四
- 李四(500) -300-> 王二
- 王二(700) -600-> 张三
因为三个用户在不在一个Zone,所以从不同Leader发起,此时要解决分布式数据库的事务并发问题。将数据打上版本,多事务并发时确保读取最新版本数据。事务提交时判读读写数据是否有更新版本,避免错误覆盖已更新数据。也就是“乐观锁”的并发机制。也可以通过加互斥锁的方式,但此时无法读到正在进行的事务,只能读到事务开始前的数据,所以也需要“版本”信息。
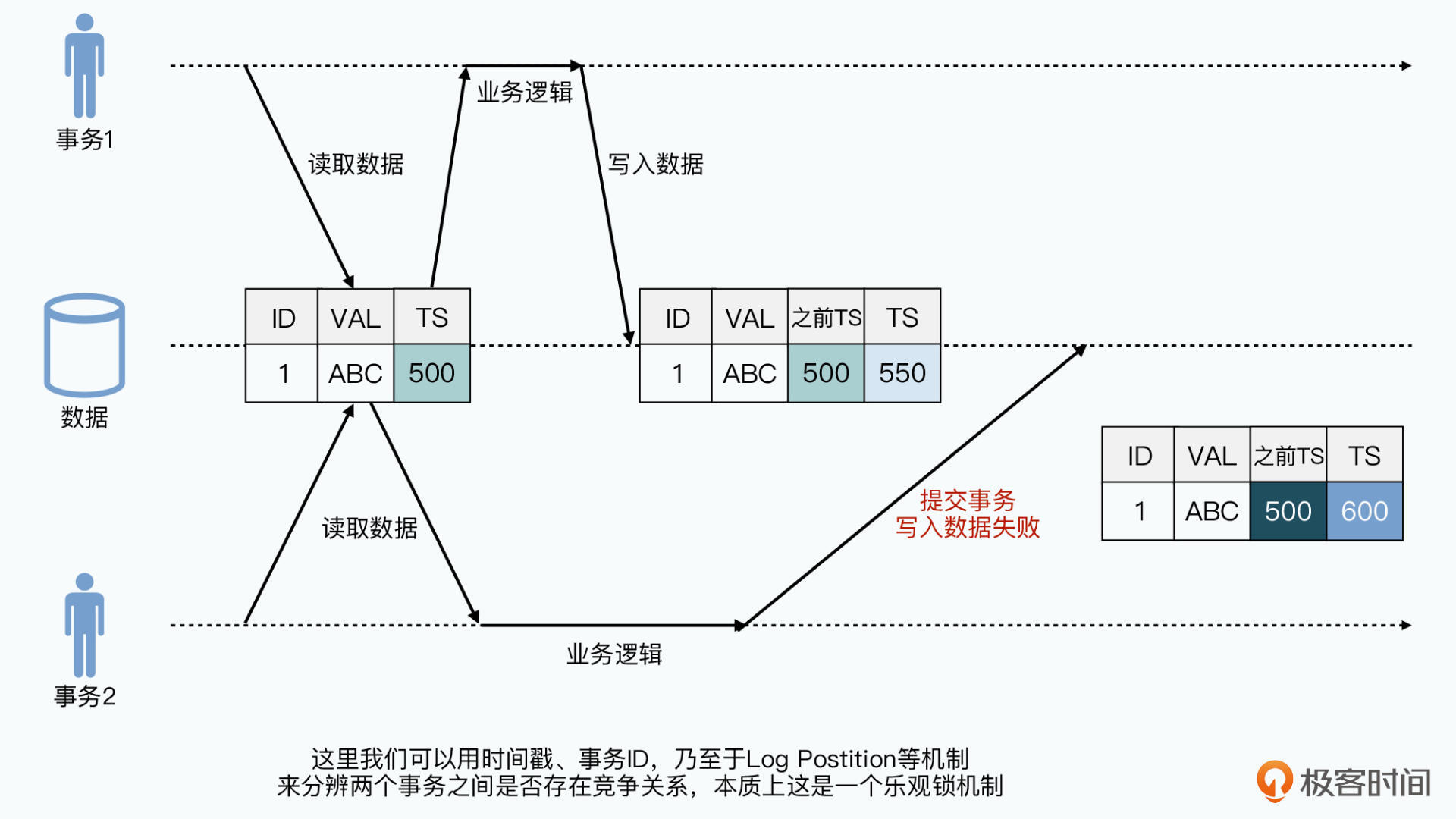
单机事务环境可通过自增ID解决,分布式环境下如何让两台服务器公用一个自增版本呢?使用时间戳,只要时间分的够细也是能分出先后的。如果恰巧一样,可以通过加上机器ID进行区分和排序。但是:
- 如何保证服务器时钟同步?
- 使用提交事务服务器还是存储数据副本服务器的时间戳?
- 不一样时有什么问题?
分布式事务的时间悖论
时间精度问题:服务器间时钟做不到完全同步,服务器使用石英振荡器计时,与日常石英钟一样每天有1秒的误差。即使使用NTP协议,由于网络延迟也有几十毫秒的误差。
分布式环境下不同节点间时间误差,会使各个参与者服务器本地时间戳遇到事务版本不一致问题。例如之前的转账例子:
- 张三(1000)-500-> 李四
- 李四(500) -300-> 王二
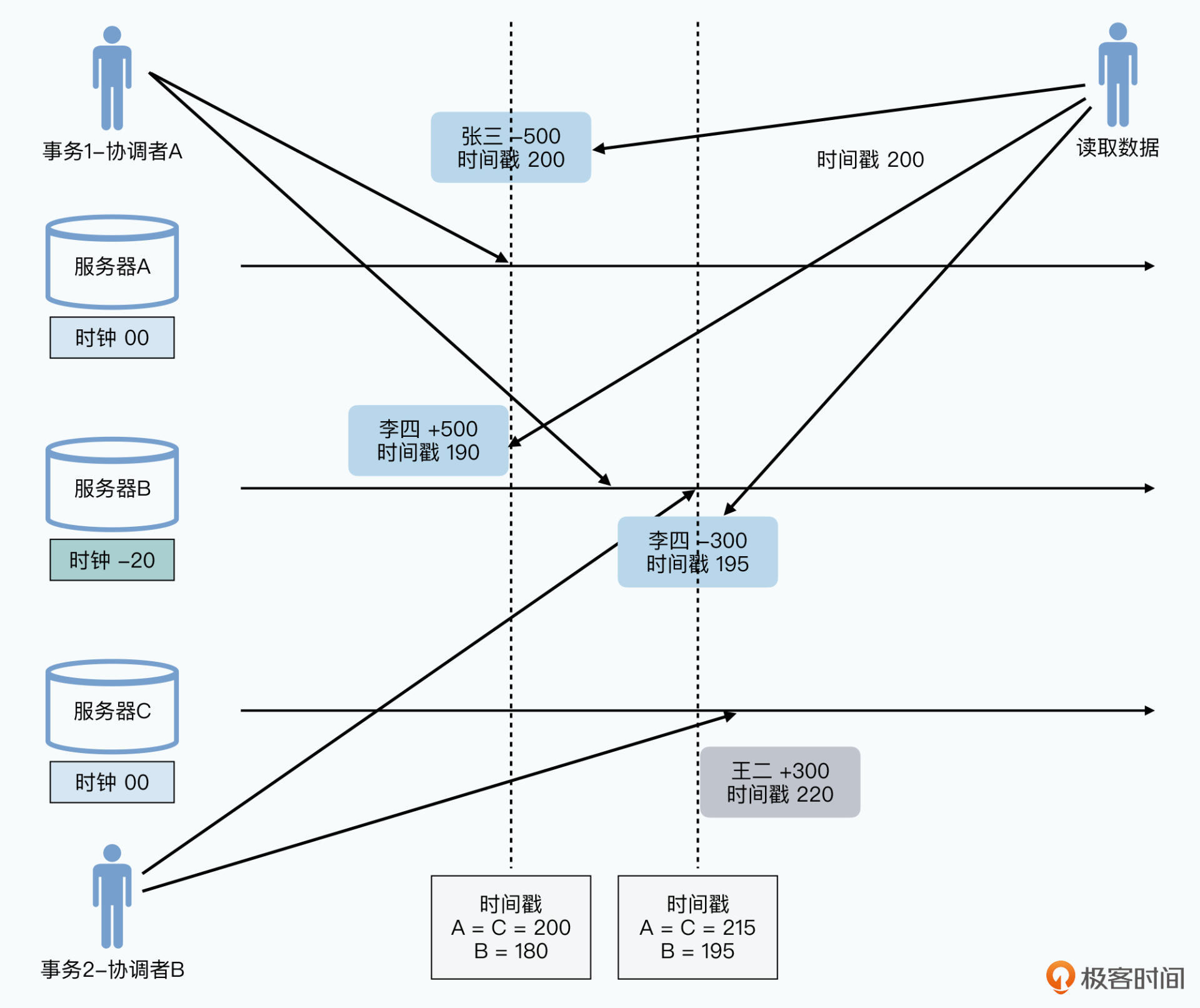
使用不同的本地时间:
事务1、2同时发生,张三的数据发生在第200毫秒,李四的数据到达B时在第210毫秒。B的时钟比A慢20毫秒,所以事务一在AB上的时间戳分别为200和190。
事务二从B发起,在本地195毫秒写完,对应A的215毫秒。请求传递到C时,C的本地时间为220毫秒。
此时读取数据是使用时间戳200毫秒,事务1是完整的,事务2中李四的钱转走了,但王二那里没到账。
发送事务请求时带上时间戳:
这时可以保障多个服务器里时间戳一致,再比如那个例子:
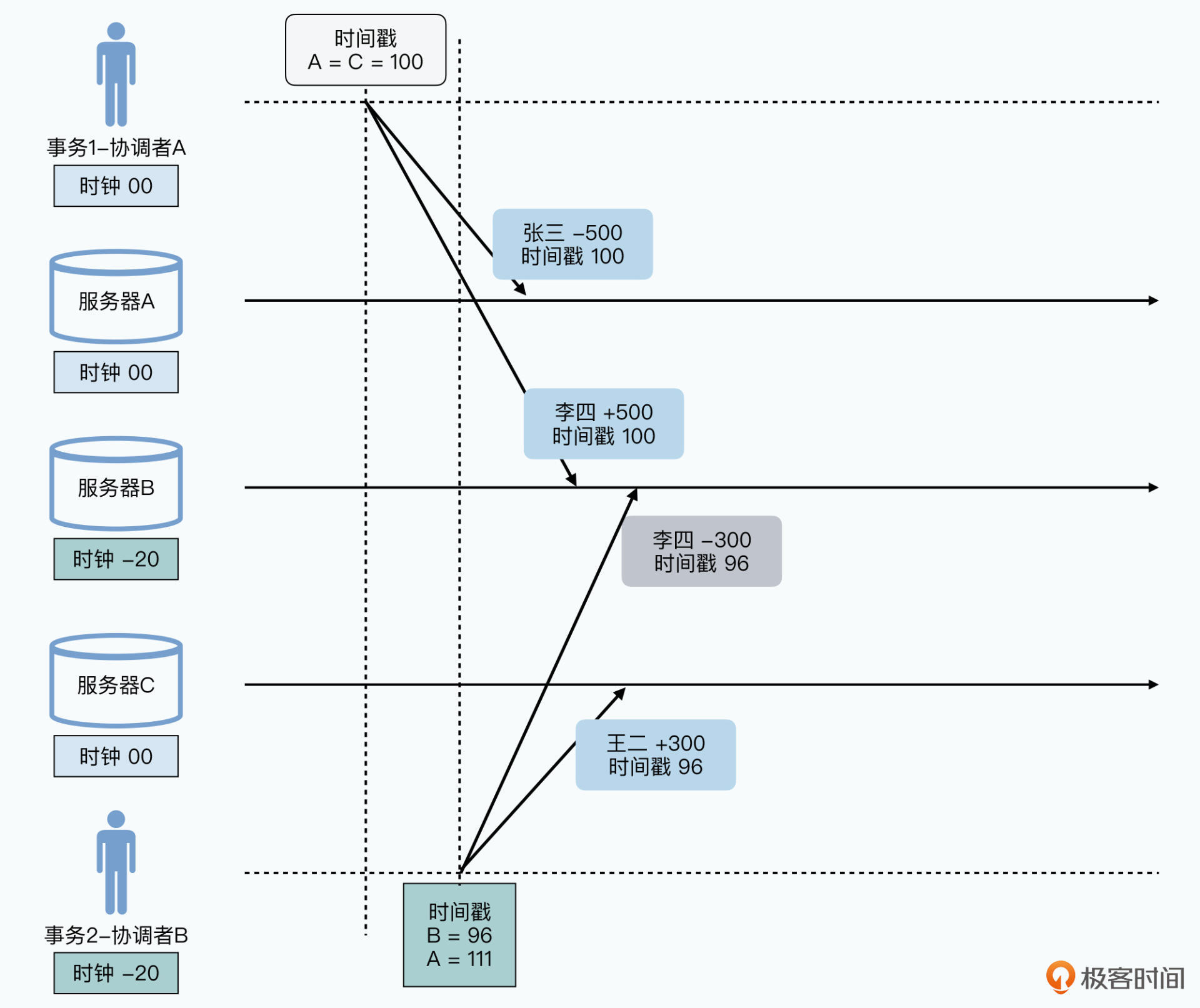
事务1在第100毫秒发起,要花10毫秒完成;事务2在第111毫秒发起,花10毫秒完成。如果时间同步,那么先执行完事务1再执行事务2。
如果事务2所在B比事务1所在A慢15毫秒,事务2发起请求时带上的时间戳是 111-15=96 毫秒,当B开始事务2时:事务1已写入成功,时间戳为100。事务2此时应当使用哪个时间戳读取快照?
- 采用事务请求的96毫秒,数据库事务读不到最新数据。事务提交会覆盖数据
- 读取最新的100毫秒数据,提交时会发现原有的时间戳100数据和当前时间戳100的数据冲突,无法提交
所以这回导致后提交的事务无法正常提交
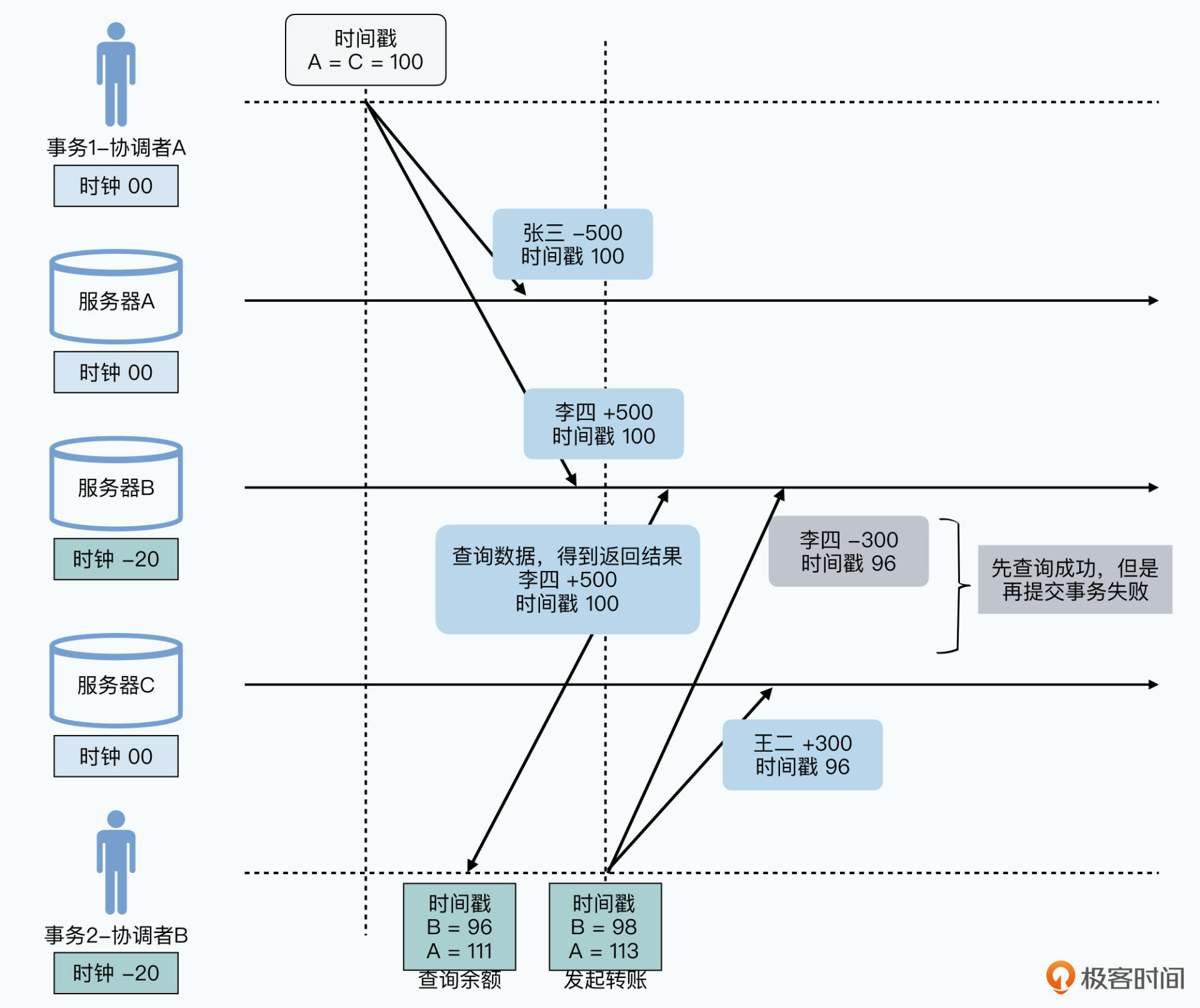
协调者先获取参与者时间,选最快的那个:
如事务2中采用参与者C的时钟。但在两个事务有交集的情况下,将事务2拆分为两个独立操作会更加奇怪:
- 事务1写入成功,对应时间戳为100
- 机器B发起事务2,拆分成两个步骤:
1. 查询张三的余额,时间戳 96
但机器A上最新数据时间戳为100,读不到数据就是业务出错;若是直接读最新版本数据,转账时会出错
2. 查询到余额后转账,时间戳 98
机器B发起转账时写入本机的时间戳为事务开始时的96,但是上一条数据的时间戳为100,提交失败
这些情况导致无法实现“可线性化”“外部一致性”(external consistency)
原子钟和置信区间
- 尽可能缩短时钟差异
- 让所有数据写入不再是有一个时间戳,而是一个时间戳范围
通过缩短时钟差异保证不会超过这个范围,通过这个范围进行一个“有条件等待”,确保事务提交的先后顺序。
原子钟和GPS
更换时钟同步方式,这二者利用物理学规律计时无需担心局域网时延,且二者公用可以互为备份。每个数据中心部署timemaster机器,相互间校验时间。
条件等待策略
通过原子钟和GPS,Spanner可将时钟误差范围缩小到1~7毫秒,平均4毫秒。所以让提交的事务等待7毫秒
- 不再只依赖协调者时间,而是考虑所有事务参与者的服务器时钟
- 提交事务时不仅看协调者本地时间,还有所有事务参与者中最大的本地时钟
- 不看此刻某一台机器时间戳,而是给每个事务请求分配一个时间戳。其要确定先后顺序不会乱
- 事务实际提交时,对比分配的时间戳和本地时间戳。若本地时间戳加上误差还没到分配时间,事务一直等待。等事件过去后再实际提交
Spanner在所有服务器上加了一个中间层,2PC时通过协调者收集所有事务参与者本地时间。推断“最坏”情况下什么时候完成,其不可早于实际可用时间,并将其作为事务实际时间戳。
小结
要实现全球事务要面临很多问题,最主要就是跨数据中心的网络时延和服务器时钟不同步。Google采用原子钟+GPS缩短服务器时钟差异,但其不会消失。当时钟差异缩短后可解决:收集所有参与事务的机器的时间,为事务分配一个时间戳,在各个机器上都等待这个时间戳过去后再提交。因时间差异最大7ms,所以最坏情况就是等7ms。
严格串行化的分布式系统
- Spanner 的分布式事务具体实现
- 分布式数据库的可串行化和可线性化概念的相关与差别
可串行化
数据库事务隔离概念,与分布式没有直接联系。一个事务集合中事务满足全序关系排序,也就是在外部看来事务是按照某个顺序一个个执行的。例如
- 事务1,张三有500元,向李四转账400元
- 事务2,李四有100元,向王二转300元
只有当事务1执行成功再执行事务2,这样两个事务才能都执行成功。但是可串行情况下,如果事务1已完成,但是事务2仍读到事务1提交前的数据,那么事务2仍会失败。
分布式情况下很有可能发生上述失败情况:事务1已提交完成,但是因为没同步到所有副本,事务2只能读旧的数据快照,当为了确保事务隔离性是可串行化的,不能让事务2完成提交。
可以接受可串行化但不可线性化的系统,它至少保证了数据库里数据的正确性。即使之前事务失败,仍可在应用操作层等待重试。
可线性化
分布式系统中概念,指对单个对象的操作是“实时”的,也就是写入数据成功后会读取到刚刚写入的值。
这似乎是理所当然的,但是单机和分布式环境下都可能被打破。单机环境下,数据写入CPU Cache但没同步到主存;分布式环境下,数据写入一个数据中心,但1秒后在另一个数据中心读时数据还未能同步。CAP中的一致性大部分都是在探讨这个问题。
可线性化完全可以和数据库事务的可串行化无关。要注意可线性化时针对单个对象的,若两个事务没有交集,那么它们在系统里记录的事务事件无需保证先后顺序:
- 事务1,张三向李四转400元
- 事务2,王二向赵大转200元
二者没有共同操作的对象,什么顺序都可以。如果再加一个事务3,李四向王二转300元。此时事务1、2、3需要一个明确的排序,因为事务间是有交集的。
严格串行化
可串行化和可线性化组合,在分布式数据库领域被称为严格串行化(Strict Serializability)。也就是在外部看来,事务是串行执行的,一旦事务执行成功,无论从哪个节点都能读到相应的数据。Spanner不仅因支持可串行化而在内部看起来一致,对于所有外部使用者也是一致且正确的,所以其自称“外部一致”数据库。
Spanner 事务的具体实现
TrueTime API
为解决时钟误差,通过TrueTime API提供一个有误差范围的“时间”概念。
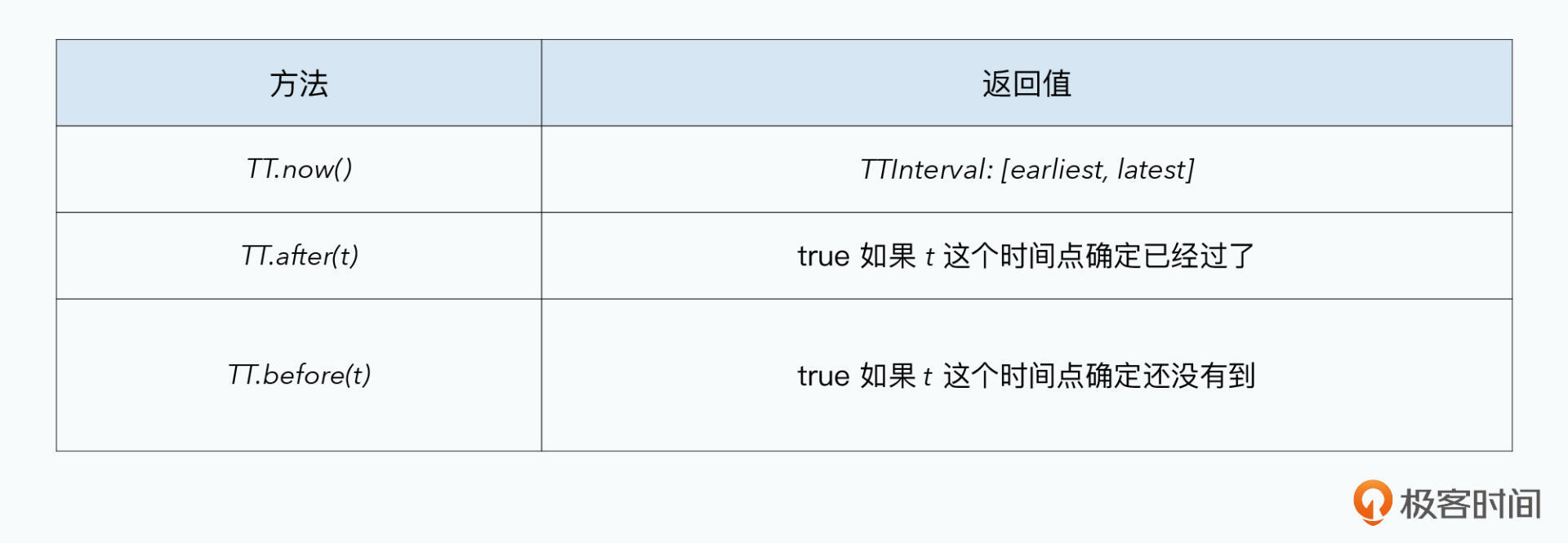
Spanner 假设有一个绝对准确的时钟,每个时间点都是绝对时间。论文中任何事件对应一个时间点 tabs(e) ,e表示事件Event,tabs表示绝对时间。去任何服务器拿时间,得到的都是[earliest, lastest]这种时间范围。
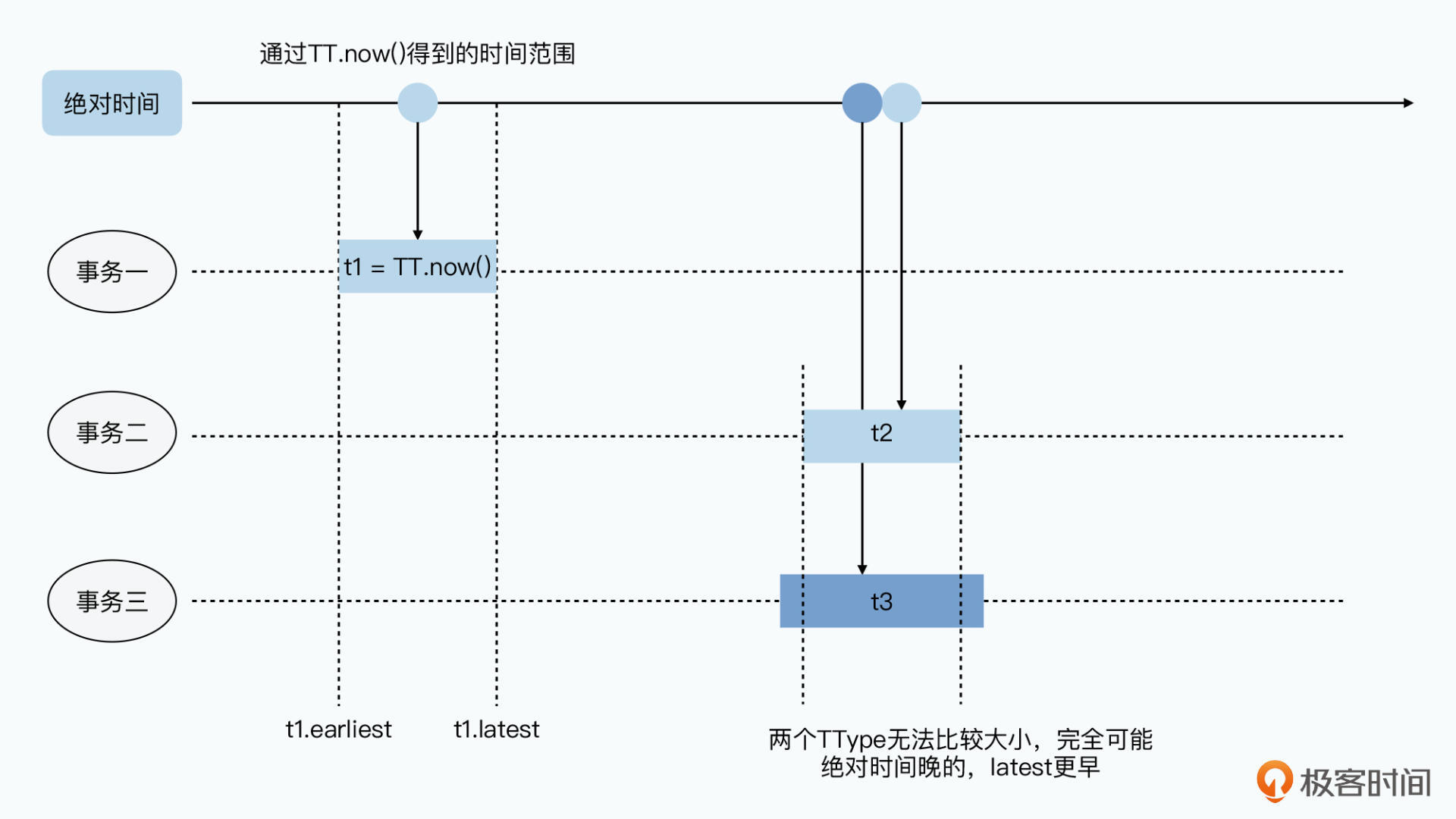
Spanner为了保障可线性化,就是确保绝对时间t时之前提交的事务全部都能读取,之后的事务全部都读不到。
Spanner 支持的读写类型
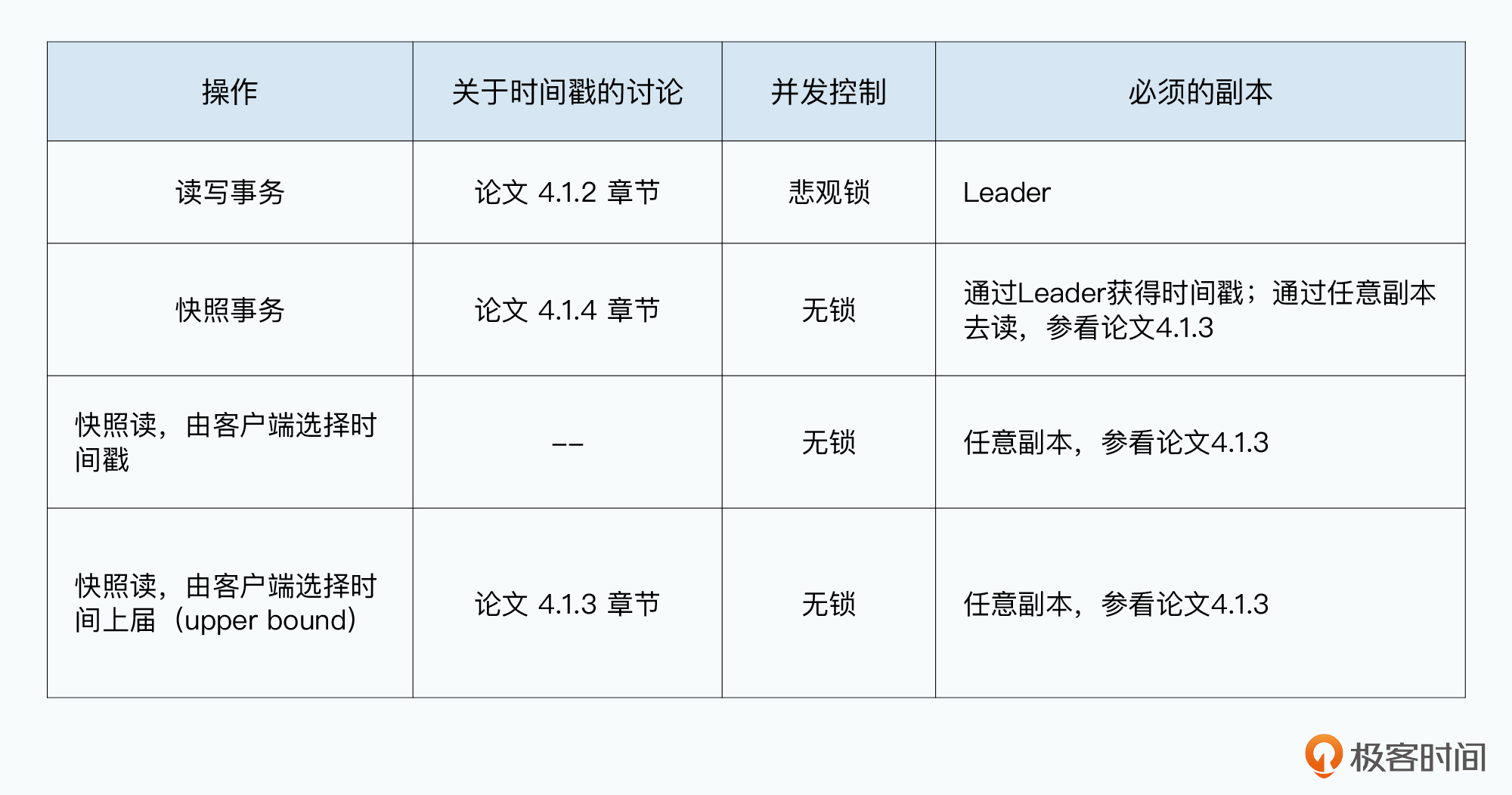
Spanner 支持3种操作:
- 读写事务
- 快照读事务
- 普通的快照读
只有读写事务能修改数据库里的数据,使用悲观锁保证对应数据行被独占;所有读事务都是无锁的,其他读写事务都不会影响数据读取。
快照读事务和普通快照读,唯一差异在于这个快照“时间戳”由谁提供。前者由Spanner系统提供。后者由应用指定,有两种方式:1.客户端选一个时间戳 2.指定一个时间戳上界,Spanner在这个时间戳上界之下选一个。
注意:这里的时间戳都是绝对时间戳,而非本地时钟的时间戳
读写事务
Spanner 事务的第一个挑战就是事务写入的时间戳该是什么?
- 将每个Paxos组看成一个单元,内部通过Paxos协议同步,暂不关注内部,将其当做一台服务器看
- 分布式事务是多个Paxos组参与的2PC,选定一个Paxos组是协调者,其余的是参与者
流程如下:
- 客户端的请求先到达协调者,Spanner里的协调者也是事务参与者
- 在2PC种,协调者向参与者的Paxos的Leader发起一个提交请求(Prepare request),此时参与者为要更新的数据获取一个写锁。参与者为这个事务生成一个Prepare请求的时间戳,且向Paxos里写一条Prepare请求记录。这个时间戳比直接分配给事务的时间戳都要晚,及Paxos组分配时间戳时保证单调递增。
- 协调者不给自己发Prepare请求,等所有参与者返回事务是否可提交的应答。返回包括参与者为Prepare request分配的时间戳。协调者为这次事务生成一个事务提交时间戳。其要满足:
- 他要等于或晚于返回的时间戳
第二阶段事务提交时间不能比第一阶段事务准备时间还早 - 比当前的Leader分配给之间事务的时间戳晚
- 要晚于 TT.now().latest,也就是考虑时钟误差的协调者当前时间戳
实际提交事务时间要比确定要提交事务的时间晚
- 他要等于或晚于返回的时间戳
- 得到时间戳后协调者等待到TT.after(s),也就是考虑误差情况下绝对时间晚于这个选择的事务提交时间之后,协调者向参与者发送提交请求,所有参与者提交的事务有相同的时间戳,且再完成后释放写锁。
- 协调者返回结果给客户端
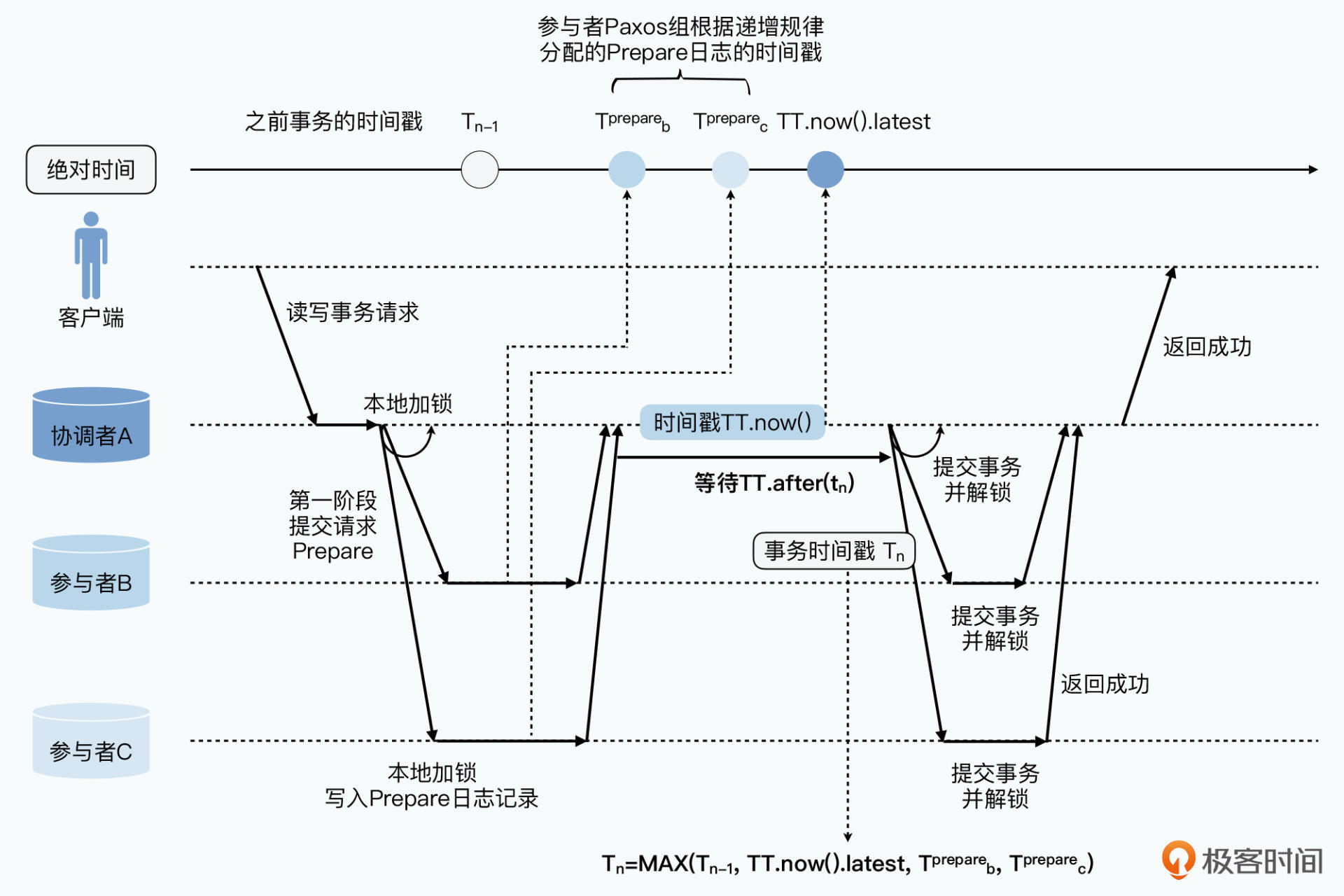
这样,并发事务写同一记录时能确保事务时间戳是有先后关系,例如:
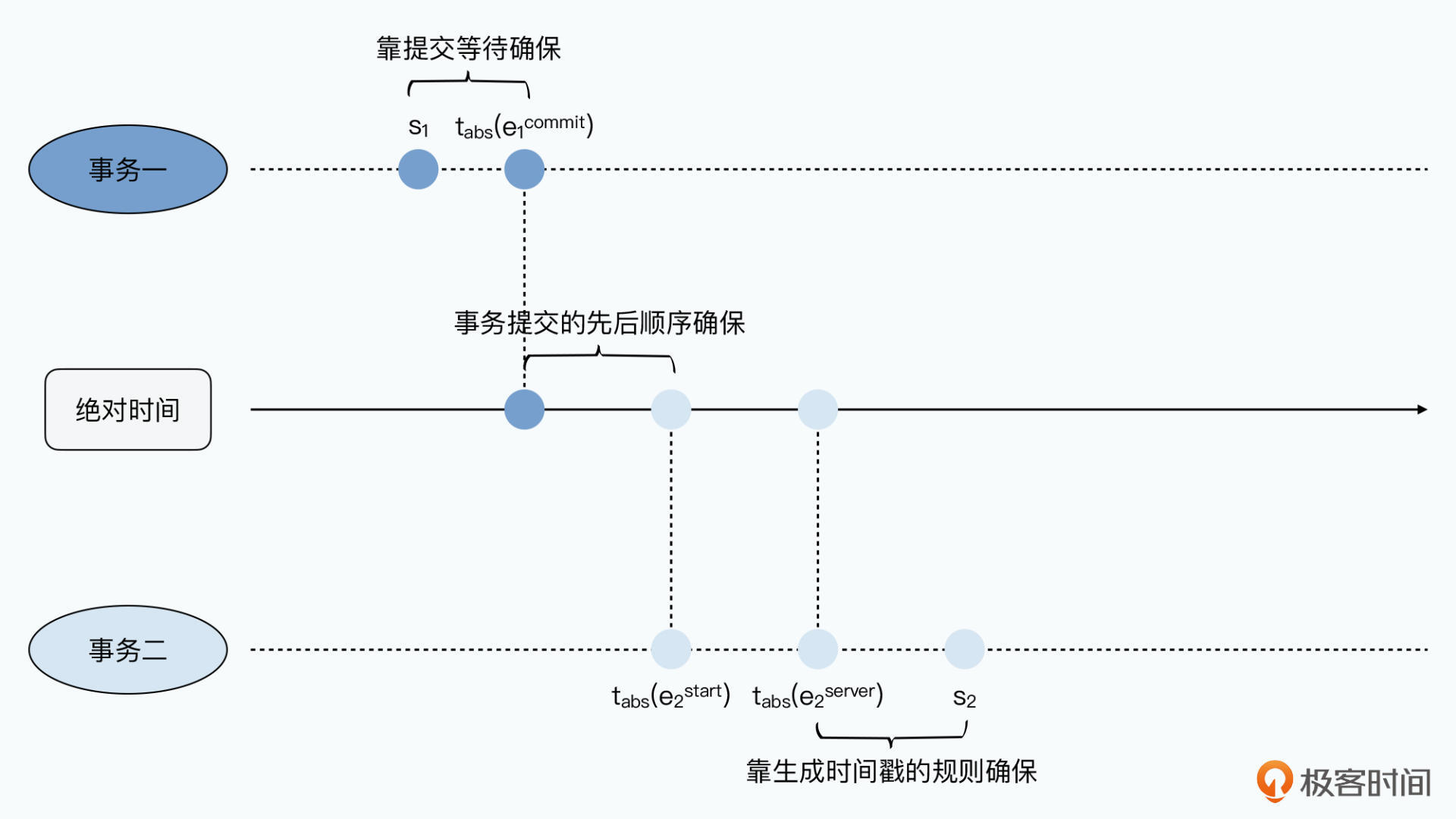
之前遇到时间戳问题,事务执行后因BC时钟比A慢,所以事务二提交的时间戳可能早于事务一。
- 事务1使用AB中较快的时钟生成事务的提交时间戳
- B这里的Paxos里最新分配的事务时间戳要晚于刚才已提交的事务,事务2生成的事务提交的时间戳一定晚于事务1
Spanner 论文中证明了如果两个事务牵涉到Paxos组,有交集情况下,后提交的时间戳一定晚于先提交的事务。
- s_1 < t_abs(e_1^commit) 系统为事务1生成的时间戳,一定早于事务实际提交的绝对时间。Spanner 在事务提交时会进行提交等待(commit wait)来确保这一点
- t_abs(e_1^commit) < t_abs(e_2^start) 事务2开始时间晚于事务1提交时间。首先事务提交有先后顺序;其次Spanner事务采用悲观锁,两个读写事务要写入相同记录,后一个要等前一个将锁释放。后一个事务的绝对时间会晚于前一个事务提交的绝对时间
- t_abs(e_2^start) <= t_abs(e_2^server) 事务2开始时间早于事务2决定要提交事务的绝对时间
- t_abs(e_2^server) <= s_2 事务2选取的时间戳晚于选取时的绝对时间。因为选取时间戳是在决定提交之后,选取本地TrueTime的时间范围内最晚的,只要误差可信,这个时间戳一定晚于决定提交那一刻的绝对时间
读写事务下,事务可能要等待一段时间,且与时钟误差相关。可也是采用原子钟+GPS以缩短时钟差异的原因
快照事务 & 快照读取
Spanner 运行从任何一个副本读,但是Paxos下不能保证每个副本都拥有最新数据。数据写入只需多数通过即可。Spanner的解决方案:每次数据库读取都会带上一个时间戳,客户端没指定时系统为它分配时间戳S_read,是由对应记录的Paxos组的Leader生成。最简单方式就是使用Leader的 TT.now().lastest,也就是考虑误差当前可能最晚时间。
当读请求到达某个副本时,这个副本的本地数据是最新版本么?直接返回本地时间还是同步最新数据后再返回?为此,每个副本本地维护一个 t_safe 值。只要请求带来的 s_read 比这个值小,那本地副本就足够新,可返回 s_read 这个时间节点下最新数据快照。t_safe取值如下:t_safe = min( t_sage^paxos, t_safe^TM )
- 每个副本维护一个当前已被应用的最大Paxos写入时间戳 t_safe^paxos。这个时间戳也是已提交并更新到数据库里最新事务的时间戳
- 副本维护另一个时间戳 t_safe^TM,拿到所有进行中的事务再Prepare阶段写入日志的时间戳,实际事务提交实际 s_i,g^prepare一定晚于这个时间。在所有这些进行中事务时间戳里选最小的一个减1,得到
t_safe^TM = min_i(s_i,g^prepare) - 1。之后不会再有事务提交时间早于这个 - 在二者中选较小的那个时间戳作为 t_safe,这个时间戳之前的所有数据在当前副本已完成同步。若 s_read 比这个时间早就直接返回数据;否则等 t_safe 变得比 s_read 还大后才返回结果
但Paxos组里没数据更新,t_safe就一直不更新?
- 每个Paxos组的Leader都维护一个映射关系,叫 MinNextTS(n)
这个映射函数给我们下一次Paxos能分配到的最小时间戳。每次Paxos数写入都生成这个时间戳,然后Paxos的Leader把 t_safe^paxos 改为 MinNextTS(n)-1 ,也就是下一次数据可写入前的时间节点。这会使得 t_safe^paxos 尽可能晚,减小它小于 s_read 的概率,尽量避免读请求等待 - Paxos的Leader即使没有数据写入也默认8秒更新一次 MinNextTS(n),时间后推则 t_safe^paxos 也相应向后更新
如果没有正在进行的事务,Leader分配 s_read 会简单些,不分配 TT.now().lateast 而是直接拿到当前Paxos组最大写入时间戳用于获取数据。否则我们的请求需要阻塞或需要客户端从其他副本读取,性能会变差。
小结
Spanner 引入 TrueTime API 实现严格串行化。写数据时的时间戳要考虑所有参与者时钟并选最晚的那个。在提交时也要考虑误差已确保写入的绝对时间晚于系统生成的时间戳。
读数据时带上时间戳,防止副本没有同步到最新数据。
每个数据副本保存本地Paxos最新写入数据的时间戳,同时考虑事务进行一半。所有已同步数据和进行中事务的时间戳中最早的那个就是当前副本确定拥有的最新的更新。通过对比本地副本的这个时间戳和读请求的时间戳,可知道直接返回还是等同步之后再返回。
现有 TiDB、CockroachDB 等开源的强一致性、高性能、全球分布式的数据库。