对于adagrad的理解
“随机梯度下降、牛顿法、动量法、Nesterov、AdaGrad、RMSprop、Adam”,打包理解对梯度下降法的优化_哔哩哔哩_bilibili

AdaGrad对学习率进行了一个约束,对于经常更新的参数,我们已经积累了大量关于它的知识,不希望被单个样本影响太大,希望学习速率慢一些;对于偶尔更新的参数,我们了解的信息太少,希望能从每个偶然出现的样本身上多学一些,即学习速率大一些。这样大大提高梯度下降的鲁棒性。而该方法中开始使用二阶动量,才意味着“自适应学习率”优化算法时代的到来。
它是在冲量法的基础上优化的。st是样本的某个特征的梯度的内积再平方和再开根(这样的设计是有点像BN,这里也是起到了当上一次梯度变化特别大的时候,能在后面的轮次中对变化率起到约束的作用)在以往更新轮次上的积累。(adagrad最大的特点就是对于每一轮的更新,对不同特征做一个坐标缩放,一个样本不同的特征对应的学习率是不一样的)
下面是李宏毅对于st设计成特征的梯度的内积再平方和再开根的解释
Gradient Descent_1_哔哩哔哩_bilibili
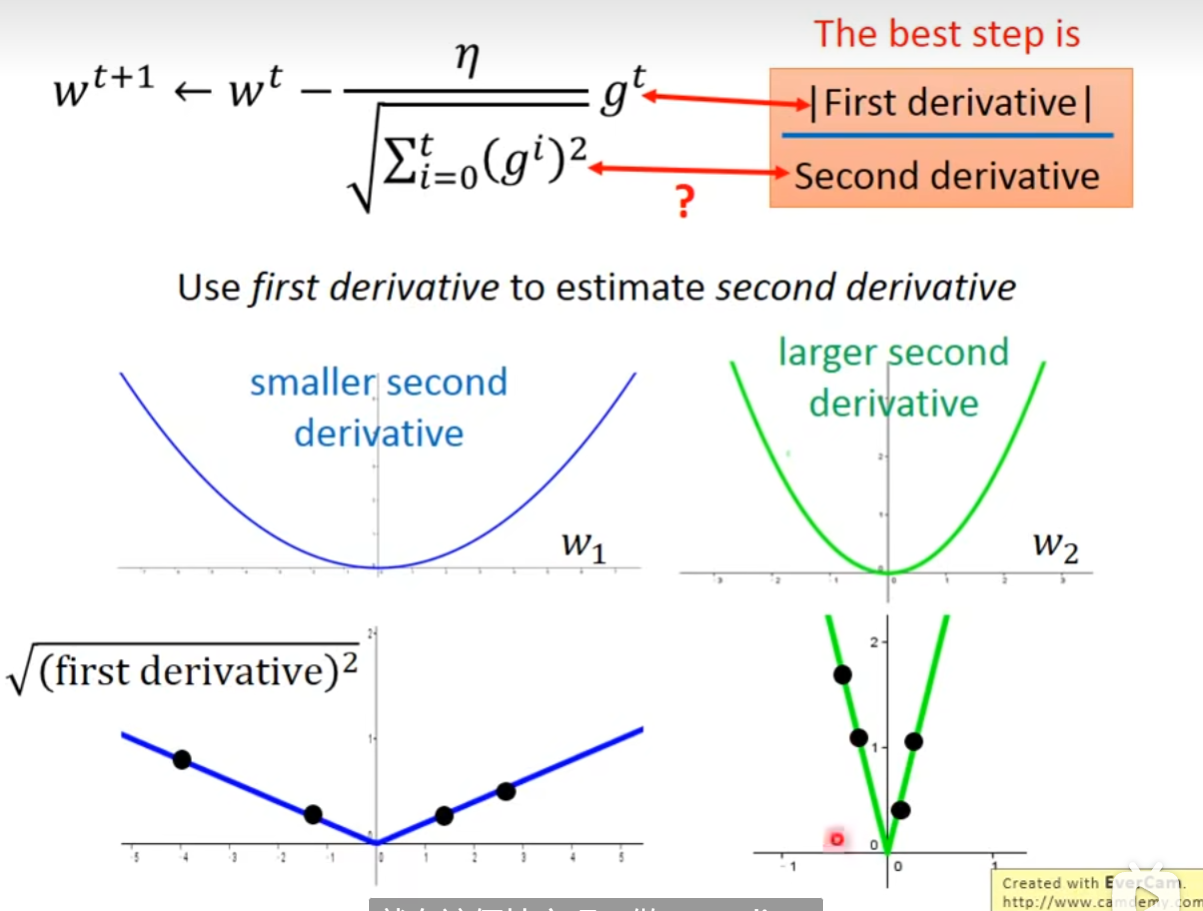
下面就是一个直观的对比,st是一阶导的平方和,其实就是对样本点的一阶导的和体现出二阶导的大小。放在分母,这样近似起到一个“归一”的作用。因为这确实可以约束学习率的变化。
补充:这里可以与动量法作为对比。

上图所示,以2维特征为例(分成w,b只是方便表示)。
动量法影响的是“梯度”这一步,也就是只会影响模型参数更新路径的方向选择;而adagrad影响的是“学习率”这一步,也就是只会影响更新路径的步长。所以结果就是动量法可以使各个特征更新的方向不那么"震荡",adagrad可以使各个特征更新的步长变化得不那么“急剧”。而RMSProp是在adagrad的基础上,为了解决st随着训练轮次的积累,一定是变大的,导致学习率一定是变小的,就显得没有约束的问题。它引入指数加权平均,使得st受约束。而adam就是结合了RMSProp和动量法,使得参数更新不仅方向上变化不震荡,步长上变化也不急剧。所以才会说adam的泛用性强,各个模型都能用(最大的优点也是缺点)(但它不一定是最优解,这个要注意)