动量adagrad rmsprop adam
亚当斯(Adams)预测-修正算法
亚当斯(Adams)预测-修正算法 由亚当斯-巴什福特(Adams-Bashforth)显式预测公式和亚当斯-莫顿(Adams-Moulton)隐式修正公式组成的预测-修正(PECE)对。 function [ YMat ] = Adams( func, tvec, y_init, order ) ......
动量编码器
自监督学习 自监督学习属于无监督学习范式的一种,不需要人工标注的类别信息,直接利用数据本身作为监督信息。自监督学习分为自监督生成式学习和自监督对比学习。 自监督生成式学习的方法 以图片为例,自监督学习可以是将图片的位置信息,旋转角度,以及图片在视频帧中的顺序作为标签。 比如对一张原图,将其旋转90° ......
应用动量定理处理流体问题
建立流体模型 对于一段流体 质量具有连续性,其密度为 \(ρ\) 流速为 \(v\) 流体横截面积为 \(S\) 微元研究 微元作用时间:\(Δt\) 微元作用长度:\(vΔt\) 则对应的质量为: \[Δm=ρSvΔt \]随后建立方程,应用动量定理研究即可。 ......
Deep Learning —— 异步优化器 —— RMSpropAsync —— 异步RMSprop
代码地址: https://github.com/chainer/chainerrl/blob/master/chainerrl/optimizers/rmsprop_async.py def update_core_cpu(self, param): grad = param.grad if gr ......
Keras Adam
keras.optimizers.Adam(learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False) learning_rate: float >= 0. 学习率。 beta_1: f ......
梯度下降、Mini-Batch梯度下降、动量梯度下降、Adam
梯度下降、Mini-Batch梯度下降、动量梯度下降以及Adam都是用于训练机器学习模型的优化算法。 梯度下降 (Gradient Descent): 梯度下降是一种优化算法,用于调整模型参数以最小化损失函数。 想象一下你站在山上,想要找到山底的最低点。你每一步都沿着最陡峭的下坡方向走,直到到达最低 ......
9 Adam
import numpy as np import matplotlib.pyplot as plt import scipy.io import math import sklearn import sklearn.datasets from opt_utils import load_param ......
Adam Gąsienica‑Samek Contest 1-I、竞赛图、倍增
Adam Gąsienica‑Samek Contest 1-I、竞赛图、倍增 题面:https://codeforces.com/gym/104479/problem/I 题意: 有一张 \(n\) 个点的竞赛图,图未给出,但是对每个点 \(i\) ,知道一个 \(c_i\) 表示从 \(i\) ......
8.动量梯度下降
import numpy as np import matplotlib.pyplot as plt import scipy.io import math import sklearn import sklearn.datasets from opt_utils import load_param ......
深度学习-梯度下降MiniBatch、RMSprop、Adam等
目录 0、综述: SGD 1、mini-batch 2、指数平均加权 3、理解指数加权平均 4、指数加权平局的修正 5、动量梯度下降法 6、RMSprop 7、Adam优化算法 8、衰减率 9、局部最优 0、综述: 在VSLAM后端中有各种梯度下降优化算法,例如:最速下降法、牛顿法、高斯-牛顿法、L ......
行业ETF动量轮动策略
6月底回测了 EarlETF 大佬的《[行业动量策略](https://mp.weixin.qq.com/s/DTnPgUItMHGVye3tUwPbKQ "行业动量策略")》,结果确实不错,而且最近两年的超额比较高。但是今年没有跑过沪深300。 
# 动量(momentum) 动量类似于物理中的运动物体具有惯性,下一个时刻的运动方向,会与上个时刻的运动方向有关。 梯度下降的过程中,参数w朝着损失函数的偏导数的方向迭代,也就是下降得最快方向。 
▪ momentum(动量,惯性) ▪ learning rate decay # 1 momentum 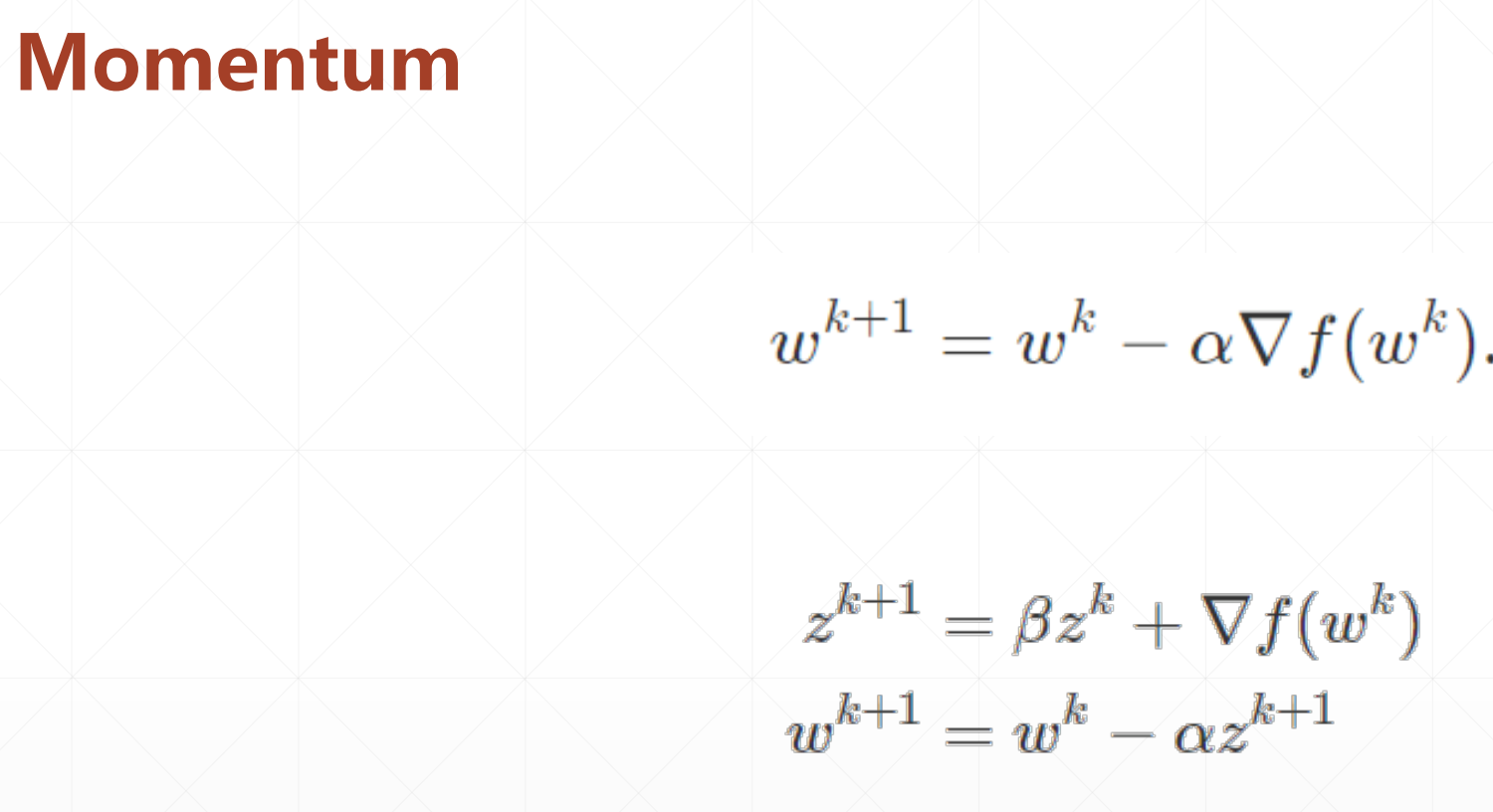 分 ......
动力总成悬置系统解偶计算及优化程序解偶计算能量分布矩阵6*6;ADAMS计算能量分布矩阵6*9;基于fmincon/fgo
动力总成悬置系统解偶计算及优化程序解偶计算能量分布矩阵6*6;ADAMS计算能量分布矩阵6*9;基于fmincon/fgoalattain动力总成悬置优化程序;解偶计算GUI。可提供理论计算分析,为什么Adams的能量分布矩阵与一般论文6*6不一样;为什么Adams计算的各方向能量之和不为100%。 ......
对于动量法,adagrad,RMSProp,Adam的理解
#### 对于adagrad的理解 [“随机梯度下降、牛顿法、动量法、Nesterov、AdaGrad、RMSprop、Adam”,打包理解对梯度下降法的优化_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV1r64y1s7fU/?spm_id_fro ......
2.2类神经网路训练不起来怎么办 (二): 批次 (batch) 与动量 (momentum)
# 1. Batch(批次) > 对抗临界点的两个方法就是batch 和 momentum 将一笔大型资料分若干批次计算 loss 和梯度,从而更新参数.每看完一个epoch就把这笔大型资料打乱(shuffle),然后重新分批次.这样能保证每个epoch中的 batch 资料不同,避免偶然性. > ......
Adam 优化算法的基本机制
Adam 算法和传统的随机梯度下降不同。随机梯度下降保持单一的学习率(即 alpha)更新所有的权重,学习率在训练过程中并不会改变。而 Adam 通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率。 ......