1. Batch(批次)
对抗临界点的两个方法就是batch 和 momentum
将一笔大型资料分若干批次计算 loss 和梯度,从而更新参数.每看完一个epoch就把这笔大型资料打乱(shuffle),然后重新分批次.这样能保证每个epoch中的 batch 资料不同,避免偶然性.
epoch是指将数据集分成batch后,将所有batch训练一遍,就是一个epoch

那么,为什么使用\(batch\)呢?
1.1 大小批次的运算时间对比
下图是两种\(batch\)的情况,第一种是\(full\) \(batch\),所有数据集都归于一个\(Batch\).第二种是极端的反面,一次只看一笔训练资料.

设大批次含有20笔资料,小批次含有1笔资料,那么大批次就是看完20笔资料后再更新参数,而小批次则是看1笔资料就更新一次参数,总共更新20次.我们可以看到大批次的单次运算时间长但效果好,小批次的单次运算时间短但效果差,需要运算多次效果才好.可以把大批次想象成迫击炮,小批次想象成加特林.
但是大批次时间长是没有考虑使用\(gpu\)(并行运算)的结果.如果采用GPU就可以做平行运算,从下图运算结果可以看出来:含有10笔资料和含有1000笔资料的批次,每次更新的运算时间差不多,但是含有的资料再增加,超过\(gpu\)的承受能力,运算时间就会急剧增加了.
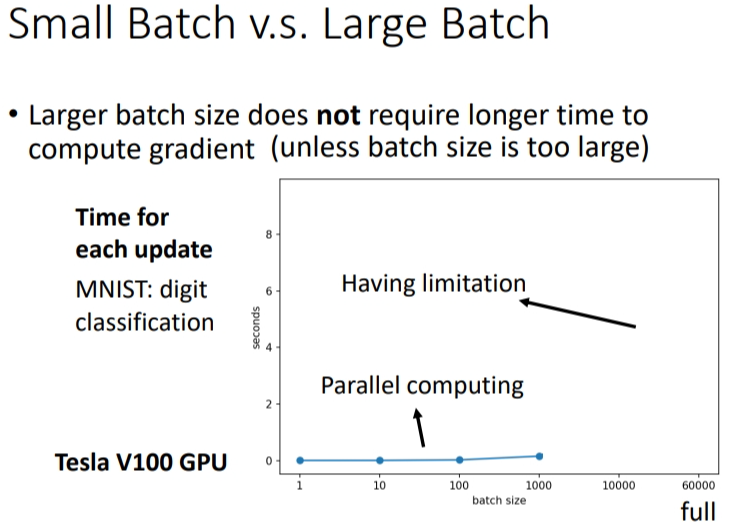
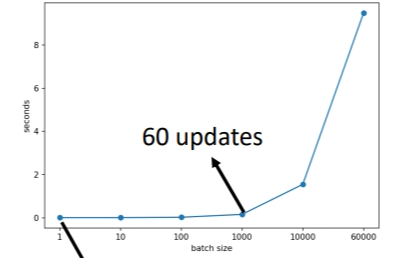
刚刚讲的运算时间是针对单次更新.而在1 个 epoch 中,小批次反而耗时更长,大批次耗时更短.原因是:同样是60000笔资料,小批次要更新60000次,而大批次只要更新60次,一次更新花费的时间又是差不多的,最后叠加起来肯定是大批次耗时更少.
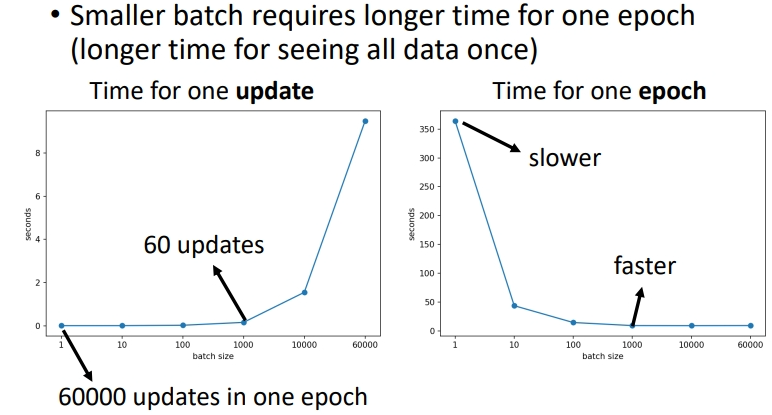
总结:没有平行运算时,单次更新大批次耗时更长;有平行运算时,单次更新大小批次耗时差不多,而 1 个 epoch中大批次耗时更短.

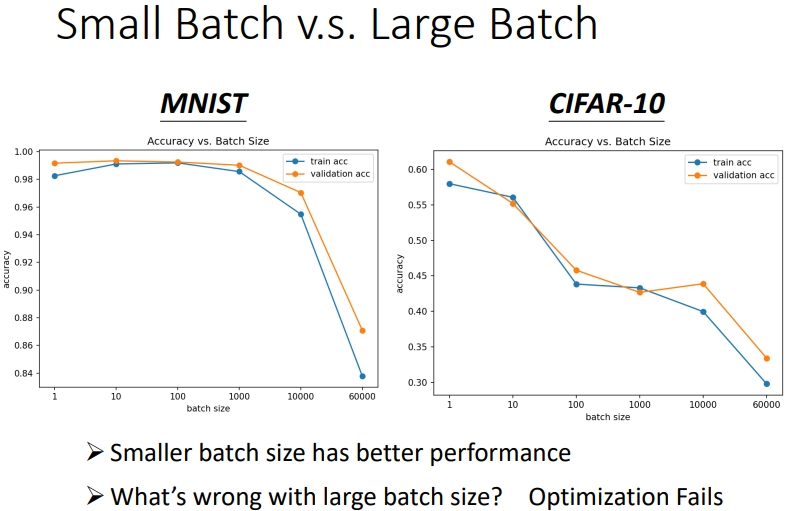
1.2 大小批次的性能对比
小批次有更好的性能.由图可知同一个模型,同一个网络,\(training\)误差随着\(batch\) \(size\)的增大而增大,\(testing\)的误差也是.如果是 model bias 的问题,那么在 size 小的时候也会表现差,而不会等到 size 变大才差.同样也不是过拟合问题,因为在这张图上并没有改变模型,按道理模型能表示的function space是一样的.所以这是Optimization issue(优化问题)导致大批次性能差.