函数式编程
-
函数式编程是一种基于函数的编程范式,它通过编写函数来描述程序的行为。函数被视为一等公民,可以作为参数、返回值和变量来使用。函数式编程通常使用高阶函数、不可变数据和递归等技术来描述程序的行为。
-
命令式编程:基于指令的编程范式,它通过编写一系列指令来描述程序的行为。程序员需要显式地指定程序的每个步骤和操作,以及它们的执行顺序和条件。命令式编程通常使用变量、循环、条件语句和函数等基本结构来描述程序的行为。
-
面向对象编程:基于对象的编程范式,它通过定义对象和类来描述程序的行为。对象是程序的基本单元,它封装了数据和行为,并与其他对象进行交互。面向对象编程通常使用封装、继承和多态等技术来描述程序的行为。
函数式编程特点
- 纯函数(无副作用及并发问题)
- 不依赖外部状态(避免使用全局变量)
- 不修改输入参数
- 资源及时释放(可以使用上下文管理器)
- 结果一致性(不可变数据)
- 避免使用可变参数
- 参数固定时返回值不变(可以用返回结果代替函数调用)
- 高阶函数
- 函数可以作为参数及返回值(实现复杂组合和转换)
- 函数可以“管理”函数,动态为函数添加功能(装饰器)
- 函数派生
- 函数可以固定部分参数派生出新的函数(偏函数)
- 递归
- 函数可以相互调用也可以直接或间接调用自身
- 用来实现循环和分治等算法,以避免使用可变状态和循环变量
函数式编程优缺点
优点
- 相对于命令式编程模块化封装,可复用
- 相对于命令式编程,过程拆分及见名知义的函数组合可读性及可维护性教好
- 结果可预知,无副作用和并发问题
- 相对于面向对象编程运行效率略高
缺点
- 不共享数据,当多个参数有多个相同的参数时,函数参数冗余度较高
- 无状态,不适合可变数据和状态变化类场景
- 可读性问题:高阶函数、不可变数据及递归的学习曲线较陡峭
- 大量高阶函数、匿名函数递归的使用可能使可读性较差
- 性能问题:函数式编程通常需要创建大量的中间对象和函数调用,使得代码的性能可能不如面向对象编程
函数编写基本规范
- 函数名见名知义
- 蛇形命名法
- 函数功能及参数注释
- 尽量短小,单一职责
- 尽量编写纯函数,使用不可变数据,不产生副作用
- 尽可能使用异常处理来处理错误,而不是返回错误码或None等
typing类型注释
- 基本类型 int、float、str、list、dict、tuple
- 嵌套类型及子元素类型 List、Dict、Tuple
- 可选类型 Union、Optional
- 泛类型 Callable, Iterable, Any
- 特定类对象
- 自定义类型及类型别名 NewType、TypeVar、 TypeAlias
高阶函数
以函数作为参数或返回值的函数称为高阶函数。
def info(func):
return func
高阶函数使用场景
允许用户通过一个函数指定数据操作规则
根据用户参数返回不同的函数(函数工厂)
对用户函数进行处理(装饰器)
回调函数
回调函数是指将一个函数作为参数传递给另一个函数,并在后者执行完特定的操作后调用前者。
回调函数通常用于异步编程中,当一个操作完成后,它会调用回调函数来通知调用者。
def add(x, y, callback): # 支持指定回调函数
result = x + y
callback(result)
def print_result(result): # 具体的回调函数
print("The result is:", result)
add(2, 3, print_result) # 输出 "The result is: 5"
函数工厂
函数工厂指可以根据用户参数返回不同的函数,用户得到具体的函数后,再次调用以得到结果。
def lazy_load(file_path):
f = open(file_path)
def load_json():
import json
return json.load(f)
def load_yaml():
import yaml
return yaml.safe_load(f)
if file_path.endswith('.yaml'):
return load_yaml
elif file_path.endswith('.json'):
return load_json
else:
raise Exception('不支持该文件类型')
load = lazy_load('a.json')
data = load()
匿名函数(函数表达式)
匿名函数是一种没有名称的函数,也称为lambda函数。在Python中,可以使用lambda关键字来定义匿名函数。
匿名函数通常用于需要一个简单的函数,但不需要定义一个完整的函数的情况。
lambda arguments: expression
其中,arguments表示函数的参数,可以是一个或多个参数,用逗号分隔。expression表示函数的返回值,可以是任意表达式。
通过赋值给变量,匿名函数也可以变成“有名”函数。
add = lambda a,b: a+b
def add(a, b):
return a + b
常见高阶函数使用
max() / min()
max() / min() 除了按元素本身比较外,还支持通过key指定一个函数,按元素总的某项值进行比较。这个函数满足以下要求:
- 参数是序列的一项
- 返回一个可比较类型(如字符串、数字等)
data = [
{'name': '张三', 'gender': 'male', 'age': 23, 'score': 83},
{'name': '李四', 'gender': 'female', 'age': 21, 'score': 65},
{'name': '王五', 'gender': 'male', 'age': 24, 'score': 73},
{'name': '赵六', 'gender': 'female', 'age': 20, 'score': 89},
{'name': '孙七', 'gender': 'female', 'age': 20, 'score': 81},
]
# max() 支持按用户指定函数(规则),求最大值
print('年龄最大的', max(data, key=
lambda x: x['age']))
# min() 支持按用户指定函数(规则),求最小值
print('分数最低的', min(data, key=lambda x: x['score']))
sorted() / groupby()
sorted() / group_by()除了按元素本身比较外,还支持通过key指定一个函数,按元素总的某项值进行比较。这个函数满足以下要求:
- 参数是序列的一项
- 返回一个可比较类型(如字符串、数字等)
import itertools
# sorted() 支持按用户指定函数(规则),进行排序
print('按分数排序', sorted(data, key=lambda x: x['score']))
# group_by(),支持按用户指定函数(规则),进行分组
key = lambda x: x['gender']
sorted_data = sorted(data, key=key)
for gender, group in itertools.groupby(sorted_data, key=key):
print(gender, len(list(group)))
filter() / map()
filter()支持按用户指定函数过滤数据,这个函数的要求为:
- 参数为序列的一项
- 函数返回True时保留该项,否则舍弃该项数据
data = [1, 2, 3, 4, 5, 6]
result = filter(lambda x: x % 2 == 0, data)
print(list(result))
map()支持按用户指定函数对数据进行批处理,返回由每一项处理后结果组成的新序列。
data = [1, 2, 3, 4, 5, 6]
result = map(lambda x: x ** 2, data)
print(list(result))
注意:filter()函数返回由过滤后的项组成的迭代器,可以遍历输出或转为列表显示。
reduce()
functools.reduce()支持按用户指定函数逐项归并数据(先前两项运算,结果再与下一项运算,依次类推),并返回最终计算结果。这个函数的要求为:
- 参数为序列的两项数据
- 返回一个计算结果,并可继续作为参数和下一项进行计算
from functools import reduce
from operator import add
data = [1, 2, 3, 4, 5, 6]
result = reduce(add, data)
print(result)
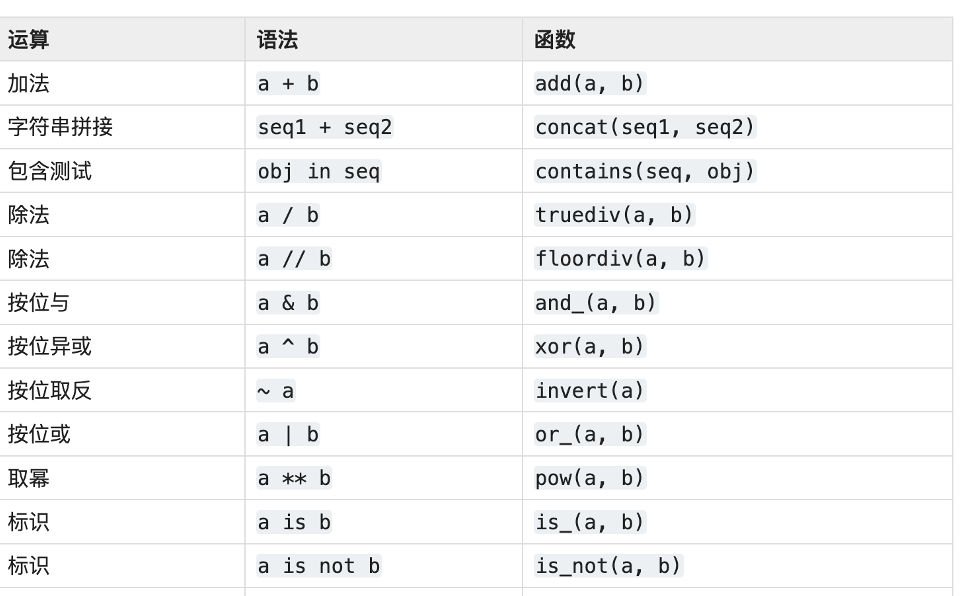
Python内置操作operator
当我们在高阶函数中需要一些基本操作时,可以使用operator 模块。
operator 提供了一套与Python的内置运算符对应的高效率函数。
例如,operator.add(x, y) 与表达式 x+y 相同。
为了向后兼容性,也保留了许多包含双下划线的函数,如operator.__add__(x, y),功能与 operator.add(x, y) 一致。
装饰器
装饰器是一种特殊的语法,它可以用来修改函数或类的行为。
装饰器本质上是一个高阶函数,它接受一个函数或类作为参数,并返回一个新的函数或类。
def decorator(func):
return func
@decorator
def func():
pass
func() # 相当于 decorator(func())
闭包
闭包是一种函数式编程的技术,它可以让函数访问其定义时的环境变量,即使这些变量在函数调用时已经不存在了。
在Python中,闭包通常使用嵌套函数来实现。
闭包使用场景
- 保存状态
- 实现装饰器
- 实现回调函数

装饰器使用场景
- 添加日志
- 计时器
- 超时时间及重试
- 参数及权限检查
- 返回值格式化
- 缓存
- 注册
常见内置装饰器
内置
@property / @xx.setter
@classmethod / @staticmethod
functools
@cache / @cached_property / @lru_cache
@singledispach / @singledispatchmethod
@warps
contextlib
@contextmanager
@redirect_stdout
@redirect_stderr
Flask
@app.route()
@app.before_first_request
@app.before_request
@app.after_request
@app.teardown_request
Pytest
@pytest.fixture
@pytest.mark.paramitrize()
@pytest.mark.skip()
@pytest.mark.skipif()
@pytest.mark.xfail()
Ddt
@ddt.ddt
@ddt.data
@ddt.filedata
@ddt.unpack
装饰器编写
简单装饰器
装饰器函数是指,输入一个函数对象,返回一个函数对象。我们可以在装饰器里获取函数的信息,也可以增加新的信息,或返回一个新的函数。
def info(func):
print(f'调用函数: {func.__name__}')
return func
@info
def add(a, b):
return a + b
普通装饰器
一般情况下,我们要实现获取函数参数或对函数功能进行修改,实际上是创建一个新的函数,替换掉原有函数。用户使用我们替换后的函数使用,我们便可以获取用户传入的参数,然后通过调用原函数来实现相同的功能,并根据情况增加新的功能。
import functools
def info2(func):
@functools.wraps(func) # 保留原函数属性
def new_func(*args, **kwargs): # 与原函数功能一致,支持任意参数
print(f'调用函数: {func.__name__} 参数:{args} {kwargs}')
return func(*args, **kwargs) # 内部包裹调用原函数
return new_func # 返回替换后的新函数
@info2
def add(a, b):
return a + b
注意:为了把新函数伪装的像原函数一样,我们可以使用functools.wrap()来保留原函数的函数名称、注释等属性。
返回装饰器的函数
如果需要通过参数对装饰器行为进行定制,可以在外面包裹一个函数,函数根据实际参数调用后,返回一个装饰器。
def info3(show_result=True) : # 3. 带参数的装饰器(返回装饰器的函数)
def info2(func):
def new_func(*args, **kwargs): # 与原函数功能一致,支持任意参数
print(f'调用函数: {func.__name__} 参数:{args} {kwargs}')
start_time = time.time()
result = func(*args, **kwargs) # 内部包裹调用原函数
if show_result is True:
print(f'调用结果: {result} 耗时: {time.time()-start_time}')
return result
return new_func # 返回替换后的新函数
return info2
@info3(show_result=True)
def add(a, b):
return a + b
注意:带参装饰器即使使用默认参数时,也需要加括号调用@info3()使用,因为它本质上不是一个装饰器,只有调用后才返回一个装饰器。
装饰器示例
超时时间控制
import functools
import signal
import time
def timeout(seconds: int):
def decorator(func):
def handler(signum, frame):
raise TimeoutError(f'函数 {func.__name__} 运行超时 超时时间: {seconds}秒')
@functools.wraps(func)
def wrapper(*args, **kwargs):
signal.signal(signal.SIGALRM, handler)
signal.alarm(seconds)
result = func(*args, **kwargs)
signal.alarm(0)
return result
return wrapper
return decorator
失败重试
import functools
def retry(retry_times=3, retry_interval=1, exception_class=Exception):
def decorator(func):
def wrapper(*args, **kwargs):
for i in range(retry_times):
try:
return func(*args, **kwargs)
except exception_class as e:
print(f'函数执行失败: {e}')
if i < retry_times - 1:
print(f'{retry_interval}秒后重试 ...')
time.sleep(retry_interval)
raise exception_class(f'重试{retry_times}次后,函数执行失败')
return wrapper
return decorator
参数类型检查
待补充
函数注册
registry = []
def register(func):
registry.append(func)
return func
@register
def step1():
print('步骤1')
@register
def step2():
print('步骤2')
def run_all():
for func in registry:
func()
多重装饰器的调用顺序
函数可以包裹多层装饰器,作用顺序是从下向上逐层包裹。
@decorator1
@decorator2
def func():
pass
func() # 相当于 decorator1(decorator2(func))
递归函数
递归函数是指,直接或间接调用自身的函数。
递归在特定条件下可以代替循环来调用自身来处理同类问题。
def increase(n=0):
n = n + 1
increase(n)
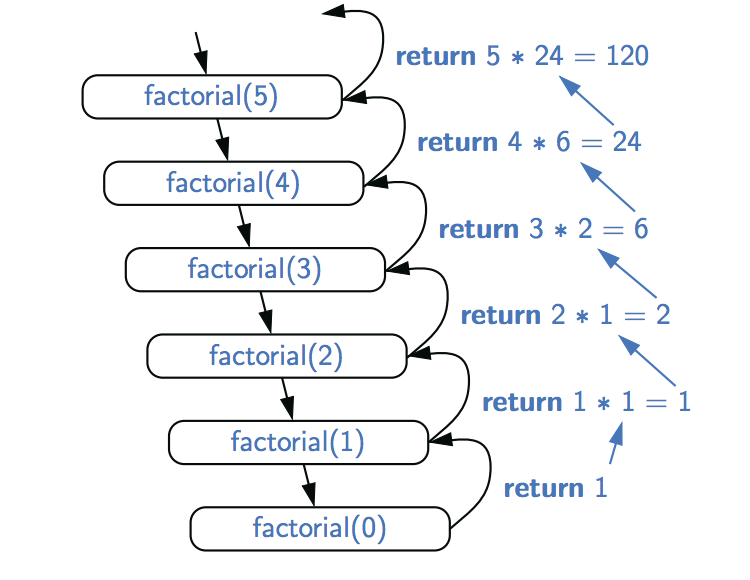
注意:递归调用一般要设置结束递归的条件,否则会陷入无限循环调用。
Python为递归设置的最大递归深度,无限递归会抛出RecursionError: maximum recursion depth exceeded
递归的优缺点及适用场景
优点
- 将复杂问题处理变得简单
缺点
- 递归调用会占用大量的栈空间,可能导致栈溢出
- 递归算法的效率通常比迭代算法低,因为递归调用需要额外的函数调用开销。
适用场景
- 树形结构
- 排列组合
- 分治算法
- 动态规划
递归算法
递归的基本思想是将一个大问题分解成若干个小问题,然后通过递归调用解决小问题,最终将所有小问题的解合并成大问题的解。递归算法通常包含两个部分:递归基和递归步骤。递归基是指问题的最小规模,可以直接求解。递归步骤是指将问题分解成更小的子问题,并通过递归调用解决子问题。
递归解决问题的思路
- 层模型:确定递归参数及返回值
- 出口条件:确定递归结束条件(递归基)
- 每层策略:确定递归步骤及调用顺序
递归注意事项
- 出口可达到
- 趋近出口(任何分支下)
- 最大递归深度
- 缓存中间结果
递归使用示例
斐波那契数列
斐波那契数列是典型的数列,形如1,1,2,3,5,8,13,21,34,...,前两项为1,后面每项是前两项的和。
函数在运行时可以调用其他函数(也可以调用自己),其他函数可以再调其他函数(可以再调自己),直到最后的调用返回了结果,再依次向前计算。因此使用递归的解法为:
例如:求fib(9)->调用自身先求fib(8)和fib(7)->调用自身先求fib(7)和fib(6)->...调用自身求fib(2)和fib(1), 已知fib(2)和fib(1)都为1,再逐步返回结果进行累加。
def fib(n: int):
if n <= 2: # 出口条件
return 1
return fib(n - 1) + fib(n - 2) # 每层策略
注意:每次都存在重复计算,例如计算fib(8)时需要计算fib(7)和fib(6), 计算fib(7)时还需要计算fib(6),我们可以使用缓存@functools.lru_cache来提升运行效率。
目录遍历
文件目录是一种典型的树状结构,目录中可以有子目录,子目录中还可以有子目录,因此我可以可以用递归来处理目录遍历,函数只需要处理本目录的逻辑,遇到子目录时调用自己,按同样逻辑处理即可。
import os
def wark_dir(path: str):
for file_name in os.listdir(path):
file_path = os.path.join(path, file_name)
if os.path.isdir(file_path):
wark_dir(file_path) # 递归遍历子目录
else:
print(file_path) # 输出文件路径
注意:树状结构有广度遍历和深度遍历两种方式,递归默认按深度遍历方式进行。
二分查找
二分查找也称折半查找,是一种非常高效的对有序数列的查找方式。二分查找充分运用来递归和分治的思想,先将当前数列从中间分开,通过与中间数的比对来决定查找较小的部分还是较大的部分,然后重复上述策略,这样每次数列长度减半,直到找到或两边没有值。
def binary_search(arr, target, left, right):
if left > right:
return -1 # 没有找到目标元素,返回-1
mid = (left + right) // 2
if arr[mid] == target:
return mid # 找到目标元素,返回索引
elif arr[mid] > target:
return binary_search(arr, target, left, mid - 1) # 在左半部分查找
else:
return binary_search(arr, target, mid + 1, right) # 在右半部分查找
迭代器
迭代器是一种可以遍历数据集合的对象,它可以按照一定的顺序依次访问数据集合中的每个元素。迭代器可以用于处理大量数据,而不会占用太多的内存空间。
迭代器是一种实现了迭代器协议的对象,迭代器协议包括两个方法:
可迭代的-for循环的真相
for循环在遍历数据时,相当于每次用next()获取该数据的下一项,直到遇到StopIteration异常
for element in [1, 2, 3]:
print(element)
for element in (1, 2, 3):
print(element)
for key in {'one':1, 'two':2}:
print(key)
for char in "123":
print(char)
for line in open("myfile.txt"):
print(line, end='')
迭代器示例
__iter__方法返回迭代器对象本身__next__方法返回下一个元素,当迭代器没有下一个元素时,next()方法会抛出StopIteration异常。
class Reverse:
"""Iterator for looping over a sequence backwards."""
def __init__(self, data):
self.data = data
self.index = len(data)
def __iter__(self):
return self
def __next__(self):
if self.index == 0:
raise StopIteration
self.index = self.index - 1
return self.data[self.index]
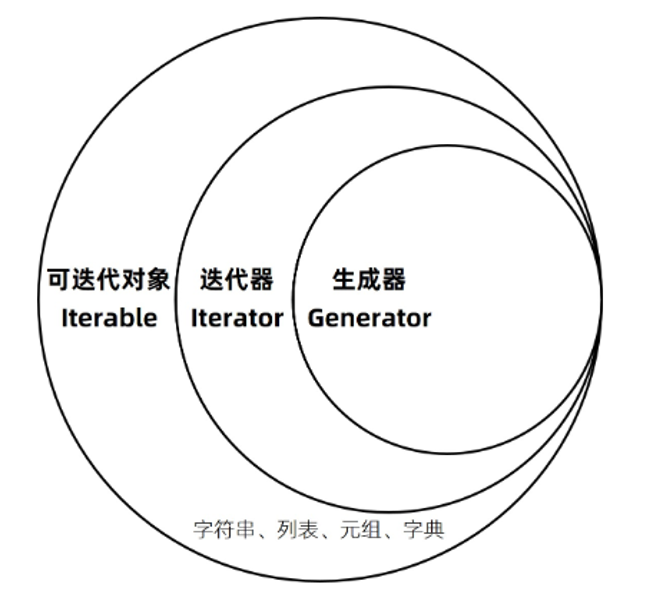
可迭代对象Iterable、
迭代器(一种类型)Iterator、
生成器(一种类型) Generator的关系
- 可迭代的(可for循环遍历的)
- 字符串、列表、字典、元祖,...
- 迭代器
- 文件对象
- 生成器
迭代器适用场景
- 处理大量数据:迭代器可以用于处理大量数据,而不会占用太多的内存空间。
- 处理无限序列:迭代器可以无限生成数据,因此可以用于处理无限序列等场景。
- 惰性计算:迭代器可以避免不必要的计算,因此可以用于处理复杂的计算场景。
- 逐步生成数据:迭代器可以逐步生成数据,因此可以用于处理需要逐步生成数据的场景。
迭代器优缺点
优点:
节省内存空间:迭代器可以按需生成数据,而不是一次性生成所有数据,因此可以节省内存空间。
惰性计算:迭代器只有在需要时才会生成数据,因此可以避免不必要的计算。
可以处理大量数据:迭代器可以用于处理大量数据,而不会占用太多的内存空间。
可以无限生成数据:迭代器可以无限生成数据,因此可以用于处理无限序列等场景。
缺点:
不能随机访问:迭代器只能按照顺序访问数据,不能随机访问。
不能重复访问:迭代器只能被迭代一次,不能重复访问。
性能较低:迭代器的性能较低,因为它需要不断地生成数据。
常见内置迭代器的使用-itertools
无限迭代器
- count():生成无限递增数列
- cycle('ABCD'):生成无限循环序列
- repeat('A', 10):生成无限重复(也支持指定重复次数)序列
有限迭代器
- groupby():分组
- chain('A', 'B', 'C') / chain.from_iterable(['A', 'B'], ['C']):连接元素组成序列
- pariwise('ABCDEFG'):前后两两组合,组成新序列 - AB CD EG G
- zip_longest():zip() 多个序列一对一组合(按最长的),组成新序列
- takewhile() / dropwhile() / filterfalse() / compress() :过滤生成新序列
- accumulate() :逐个累加
- tee():平均拆分为多个序列
- islice():切片拆分序列
排列组合
- combinations() / combinations_with_replacement() :组合(不考虑顺序)ABC, 2 -> AB BC AC
- permutaions():排列组合 ABC -> AB AC BC BA CA CB
- product():笛卡尔积(全排列)-> AA AB AC BA BB BC CA CB CC
生成器-用函数表示的一种迭代器
生成器 是一个用于创建迭代器的简单而强大的工具。 它们的写法类似于标准的函数,但当它们要返回数据时会使用 yield 语句。 每次在生成器上调用 next() 时,它会从上次离开的位置恢复执行(它会记住上次执行语句时的所有数据值)
生成器是一种特殊的迭代器,它可以动态地生成数据,而不是一次性生成所有数据。
生成器编写方法
- 生成器表达式
- 生成器函数
生成器示例
在函数中可以使用yield来多次返回多个值。当遇到yield时,被调函数会暂停将值返回给调用方,并等待调用方再次调用。包含yield语句的函数调用时返回的是一个生成器对象。
def reverse(data):
for index in range(len(data)-1, -1, -1):
yield data[index]
除了生成器函数外,我们还可以使用类似推导式的语句(生成器表达式)来编写简单的生成器,使用小括弧包裹的推导式会产生一个生成器(不会立即执行,遍历它时才会执行)。
同时生成器表达式也可以结合函数使用实现延迟计算。
data = 'hello,world'
reversed_data = (data[index] for index in range(len(data)-1, -1, -1))
sum(i*i for i in range(10))
推导式
列表推导式
- 遍历一组数据生成新列表
- 遍历时条件筛选
- 多重循环
- 实现步骤批处理
字典推导式
- 遍历一组数据生成字典
- zip()组合key和value
上下文管理器
上下文管理器是一种用于管理资源的对象,它可以在进入和离开代码块时执行特定的操作,例如打开和关闭文件、获取和释放锁等。
上下文管理器可以使用with语句来创建和使用。
上下文管理器协议包括两个方法:
__enter__方法在进入代码块时执行__exit__方法在离开代码块时执行。当代码块执行完毕或者发生异常时,__exit__方法会被调用,可以在这个方法中进行资源的释放和清理操作。
上下文管理器使用场景
-
自动释放资源
-
with open() as f:
-
with threading.Lock():
-
with sqlite3.connect('example.db') as conn:
-
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
-
with pytest.raises() ...
-
with requests.Session() ...
-
异常处理
上下文管理器编写
类式写法
编写上下文管理类,需要在实现__enter__进入和__exit__退出方法。__enter__方法返回用户使用as时拿到的结果。__exit__中也可以控制和处理异常。
以下是一个切换执行目录并自动退出(切换回原目录)的上下文管理器的实现。
import os
class SwitchDir:
def __init__(self, path: str):
self.__origin_path = os.getcwd()
self.__path = path
def __enter__(self):
os.chdir(self.__path)
return self.__origin_path
def __exit__(self, exc_type, exc_value, trace):
os.chdir(self.__origin_path)
函数式写法
也可以使用contextlib中的contextmanager装饰器来将一个函数变成上下文管理器。进入和退出方法使用yield分割,并使用yield返回结果(with ... as 变量得到的结果)
import os
import contextlib
@contextlib.contextmanager
def switch_dir(path: str):
origin_path = os.getcwd()
os.chdir(path)
yield origin_path
os.chdir(origin_path)
偏函数
偏函数是根据一个已有函数,固定部分参数来快速派生出一个新函数。
from functools import partial
def add(a, b):
return a + b
add_10 = partial(add, 10)
print(add_10(5))
练习
高阶函数练习
装饰器练习
- @safe:控制异常,带该装饰器的函数发生异常时不报错而改为打印异常并返回None
- @result_and_err:带该装饰器的函数强制改为返回二元结果result和err,无异常时时正常结果和返None,否则返回None和异常对象
递归练习
- 跳台阶问题
- 快速排序
迭代器练习
生成器练习
上下文管理器练习