GFS
重点是:高可用、可扩展性、透明
几个设计理念:
- 故障很常见,而非意外
- 存储内容为大文件,通常在几个GB
- 文件的修改方式是追加而非随机写,读多写少
- 增加系统灵活性,如放松对GFS的一致性要求
架构
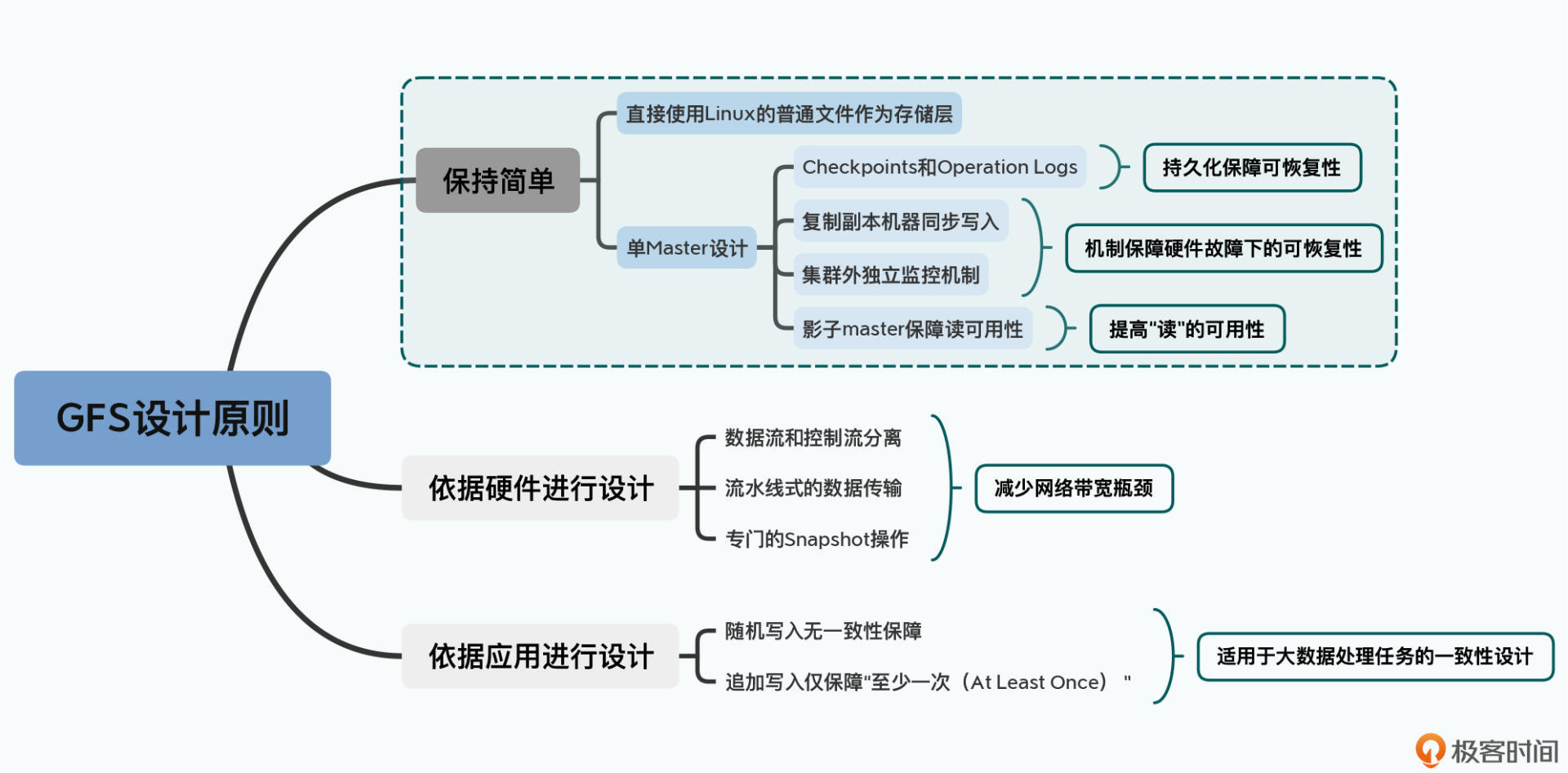
GFS包括单节点Master、备用的shadow master、多个chunkserver、多个client,
- clinet:专用接口,与应用交互
- master:维持元数据,统一管理chunk位置和租约
- chunkserver:存储数据
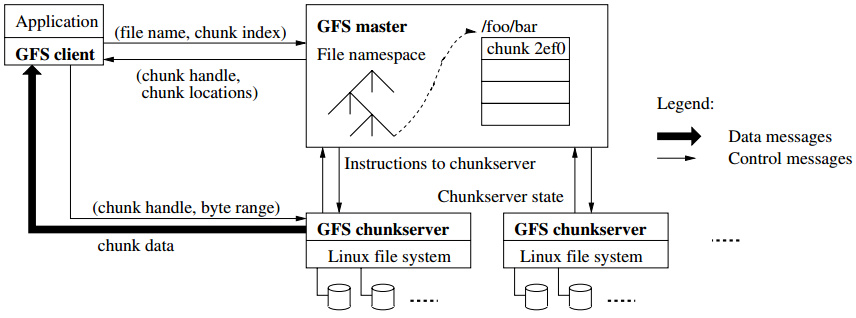
每个文件分为固定大小的chunk,每个chunk在创建时在master中生成chunk handle。chunk默认在chunkserver中存储3份,大小为64MB,设计这么大有利于
- 减少内部寻址次数和交互次数
- client可能在chunk上执行多次操作,节省网络开销
- 大chunk减少了chunk数量,节省了元数据开销
chunk变大可能导致热点问题,多个线程操作一个chunk,这方面GFS在一致性上做出性能的妥协。
chunk在文件中分布是随机的:
Master
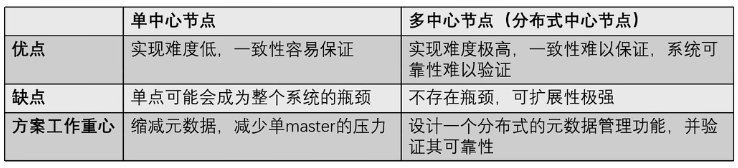
master是唯一可写入数据的节点,使用backup master作为备份,shadow master作为只读节点。
使用单节点设计,简化复杂度,存储三类数据:
- 所有文件和chunk的namespace(持久化)
- 文件到chunk的映射(持久化)
- 每个chunk的位置(不持久化,集群启动时从chunk server中收集)
高可用设计
通用做法是共识算法,如paxos和raft。GFS诞生时共识算法不成熟,故采用主备思想分别为元数据和文件数据单独设计了高可用方案。
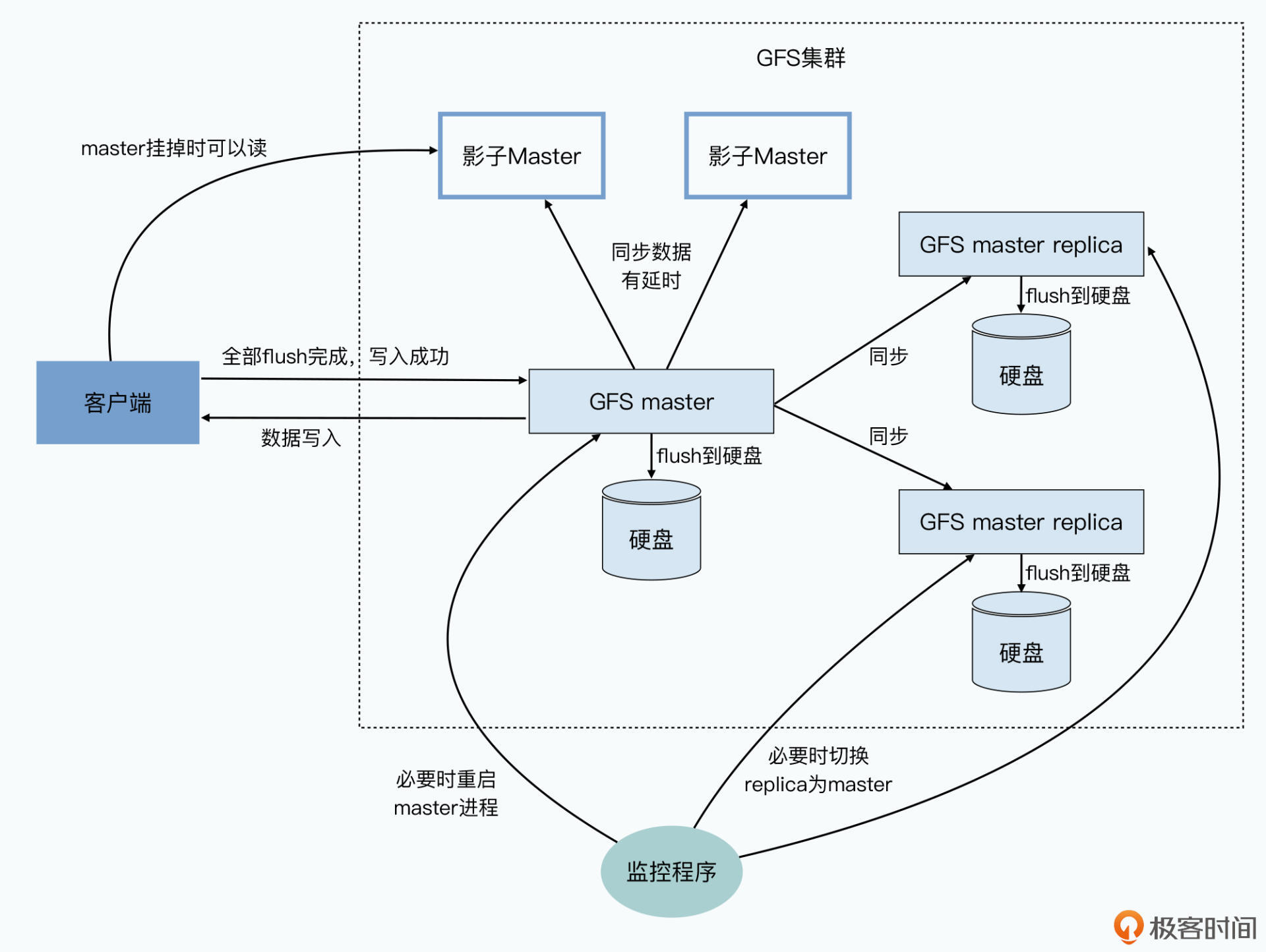
master高可用
GFS中除了正在使用的primary master外,还维持一个shadow master作为备份。正常运行时所有的修改操作都要先记录日志(WAL write ahead log)再修改内存数据。primary master实时向backup master同步WAL,只有backup master完成同步日志,元数据才算修改成功。WAL可顺序写入,写入速度根快,方便同步。
master所有数据存在内存,这样才能满足性能要求,为了方式宕机丢失,定期生成相应的checkpoints进行持久化。master重启后读取最新的checkpoint并重放之后的日志,恢复到最新状态。
当master宕机,通过Chubby(本质是一种共识算法)识别并切换到backup master。GFS的master高可用机制与MySQL的主备机制很像。GFS还定期对内存做checkpoint以减少回放日志的代价。backup master使用同步复制,作为master的后备;shadow master使用异步复制,是只读的,用于减轻master压力。
chunkserver 高可用
每个chunk三个副本,每次集群启动时master从chunkserver收集信息
- GFS中对一个chunk的写入,必须保证在3个副本中都完成才视为完成
- 一个chunk的所有副本都有完整数据
- 如果一个chunkserver宕机,另外两个chunk副本仍保留数据
- 若宕机副本一段时间后仍没恢复,master可在其他chunkserver创建一个新副本,仍将数目维持在3个
- 维持每个chunk的校验和
- GFS采用租约(Lease)机制,将文件读写权限下放给某个chunk副本。此副本称为primary,在有效期内其负责对应chunk的读写
- 租约的主备只决定控制流走向,不影响数据流(数据流采用就近流动)
chunk的创建由master进行:
- 新chunk创建
- chunk副本复制(re-replication):某chunkserver宕机,要恢复chunk副本数
- 负载均衡(rebalancing):master定期对chunkserver检测,某个chunkserver负载过高则将副本搬到其他chunkserver
创建chunk副本时位置的选择:
- 新副本所在chunkserver的资源利用率较低
- 新副本所在chunkserver最近创建的chunk副本不多,为了防止瞬间增加大量副本,成为热点
- chunk的其他副本不在同一机架,保证机架或机房级的高可用
GFS读写流程
读写流程与一致性关系密切。在读写过程中使用了分离控制流和数据流与流水线思想。
GFS读取文件
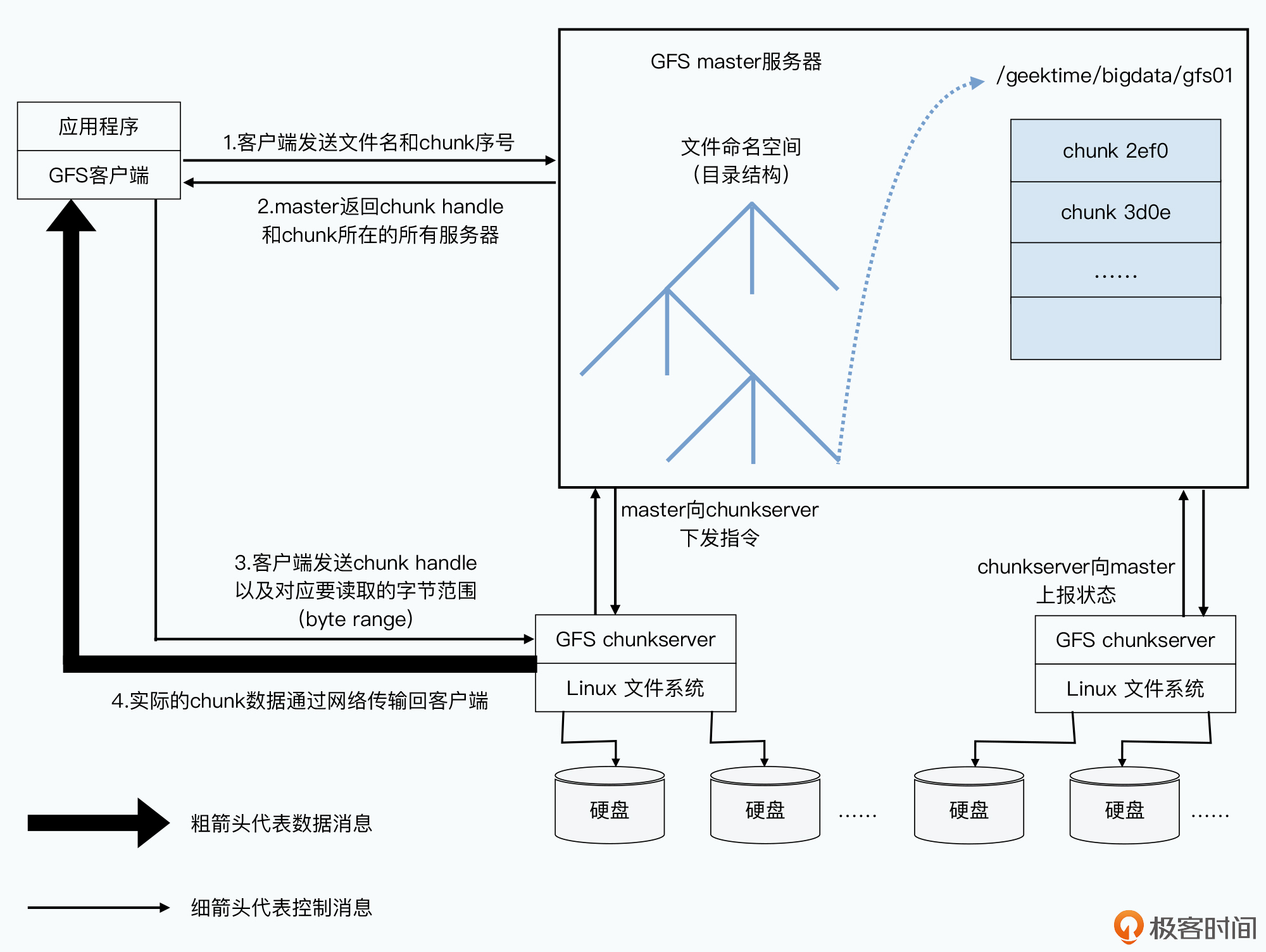
对于读取操作,性能最重要,可容忍版本落后,不可容忍错误。
- 用户发送请求给client,如果缓存没命中则转发给master获取元信息并缓存
- master根据文件名给出所有chunk名
- client从master获取chunk位置并计算偏移量,如果只读取部分则在master中计算偏移量,从偏移量对应的chunk编号开始读取即可
- client向离自己最近的chunkserver读取数据,如果其没有所需chunk,说明缓存失效需要再请求元数据
- 读取时通过chuck校验和验证,不通过则选择其他副本读取
- client返回读取结果
采用了许多措施防止master成为性能瓶颈:
- GFS的数据流不经过master,而是直接由client和chunkserver交互,只有控制流经过master
- GFS的client会缓存master的元数据,一般无需访问master
- 为了避免master内存成为系统瓶颈,采用了增大chunk大小以节省数量、对元数据进行定制化的压缩等
GFS写文件
- 改写 overwrite:保证正确,不在意性能
- 追加 append:为了极致的性能,允许一定异常,但不允许丢失
“三写一读”方案:三个副本都写入才返回结果,比起读更在意写,这样保证读时的一致性。使用两个技术:
- 流水线技术
client将文件发送到离自己最近的副本,无论是否有租约。其接收的同时向其他副本转发。
相比于普通的主备同步,这样节省了网络传输代价 - 数据流与控制流分离
GFS对一致性的保证不受数据同步的干扰。
数据量大的数据流以性能优先,数据量小的控制流由持有租约的chunkserver自己决定,以保证写入的一致性。
进而达到性能和一致性的均衡
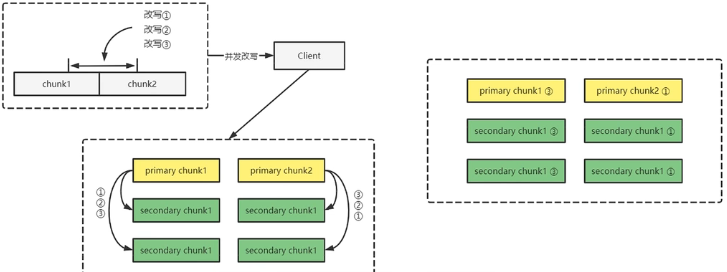
写入流程:
- 第12步访问master询问chunk的租约在哪个chunkserver上,即primary replica和其他副本位置
- client将数据推送到最近节点,其边接收边向其他节点同步,使用流水线技术(对应第3步,此处数据量大,出错概率高,从此处重试)
- 节点接收到数据并不立刻写下,而是放在一个LRU缓冲区中
- 所有副本接收数据后client发送正式写入请求到 Primary Replica。Primary Replica接收到这个请求后将这个chunk上所有操作排序,按顺序写入(Primary Replica唯一确认写入顺序,保证副本一致性)
- GFS面对几百个并发的客户端,Primary Replica 将多个请求排序,再将chunk写入顺序同步到 Secondary Replica
- 所有 Secondary Replica 返回写入完成
- Primary Replica 返回写入结果给 Client
当一个写入操作涉及多个chunk,client将其分为多个写入执行

改写
- 与上述操作相同,多次重复页不会产生副本不一致
- 一个改写可能涉及多个chunk,部分成功部分失败时读到的文件不正确
- 保证分布式改写的强一致性很困难,没有全局唯一时间戳MVCC,只有使用阻塞整个文件写入保证
- 推荐追加方式
追加
在文件后新增一个chunk,追加数据不能大于一个chunk的大小。如果原有文件最后一个chunk有空隙,使用padding填充。
GFS 一致性模型
GFS放宽了对数据一致性的要求。只对顺序写入保持了一致性。
GFS的文件数据一致性分3个层次:
- consistent 一致的:从所有副本读取的数据一致
- defined 已定义的:在consistent基础上与用户最新写入保持一致
- inconsistent 不一致的

- 串行改写和追加都是defined,因为所有副本都完成改写才算成功,所以重复执行不会引起不一致
- 失败通常意味着有副本重试多次都无法成功写入,大概率是宕机
- 并发写
- 改写:写操作的chunk副本间一定一致,但是多个chunk对改写的执行顺序不一定相同,可能使改写的结果和与预期的结果不一致
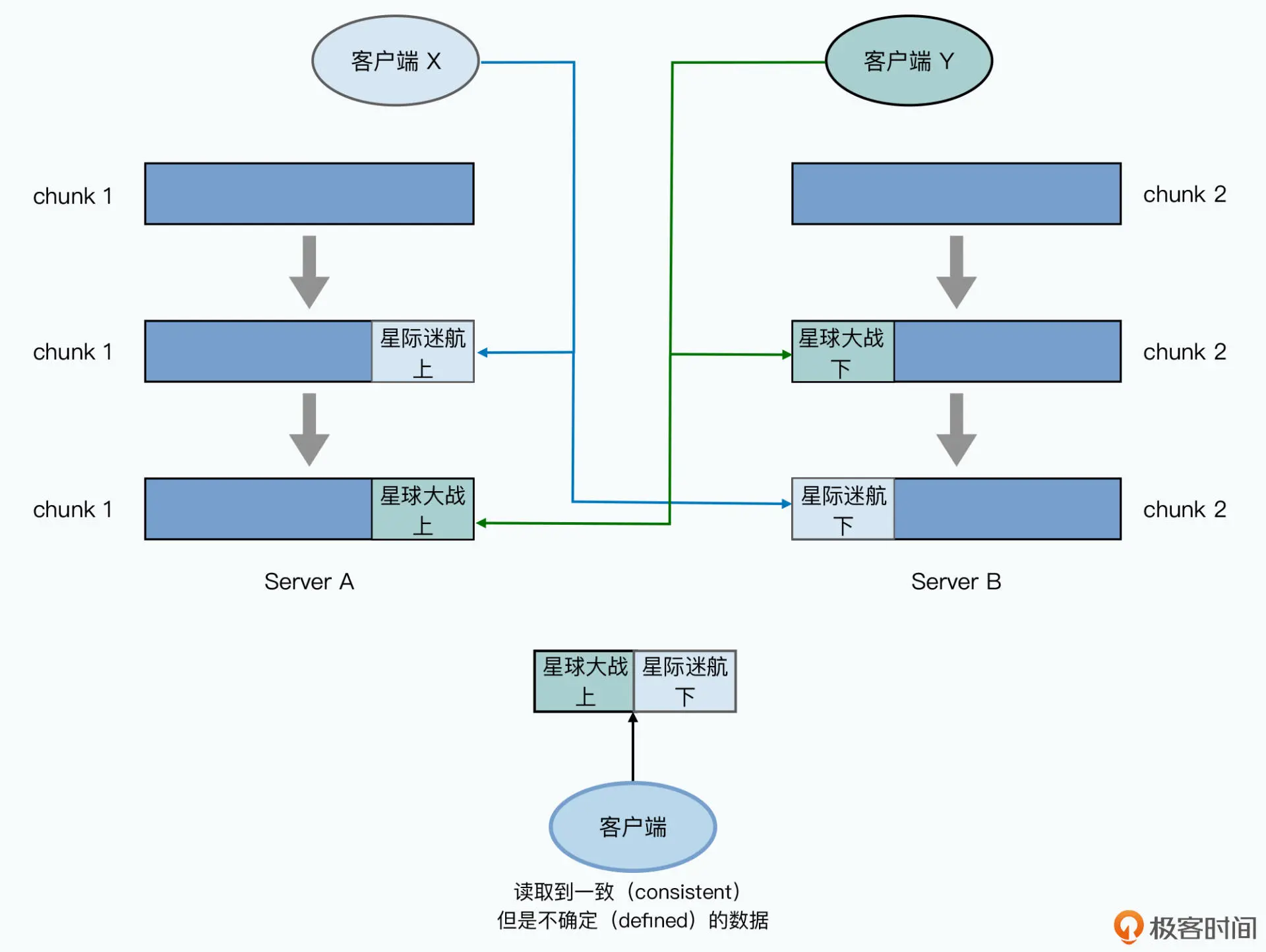
GFS没有全局一致概念,只有chunk级一致
原因在于:
1. 数据写入顺序不通过master协调,而是经由存储了主副本的chunkserver
2. 随机写既有可能跨越多个chunk - 追加:为了实现追加一致性对追加做了额外限制
1. 单次append的大小不超过一个chunk默认64MB
2. 文件最后一个chunk大小不足以提供空间则用padding填满,然后创建新chunk填充
每次append都限制在一个chunk,可保证原子性,并发执行也可保证client读取符合最新追加- 重复追加问题:对原文件“ABC”追加“DEF”,当失败一次再重复执行得到“ABCDEF”,两次都正确得到“ABCDEFDEF”。可通过记录文件长度、各副本定期校验等方法解决此问题
- 并发场景下重复追加:操作XYZ同时向QPR节点写入ABC三个数据
追加A时某个节点失败则整个操作不成功,随后BC被追加,然后才开始重试失败数据
得到的结果为 ABCA、ABCA、BCA
这就是GFS承诺的“至少一次”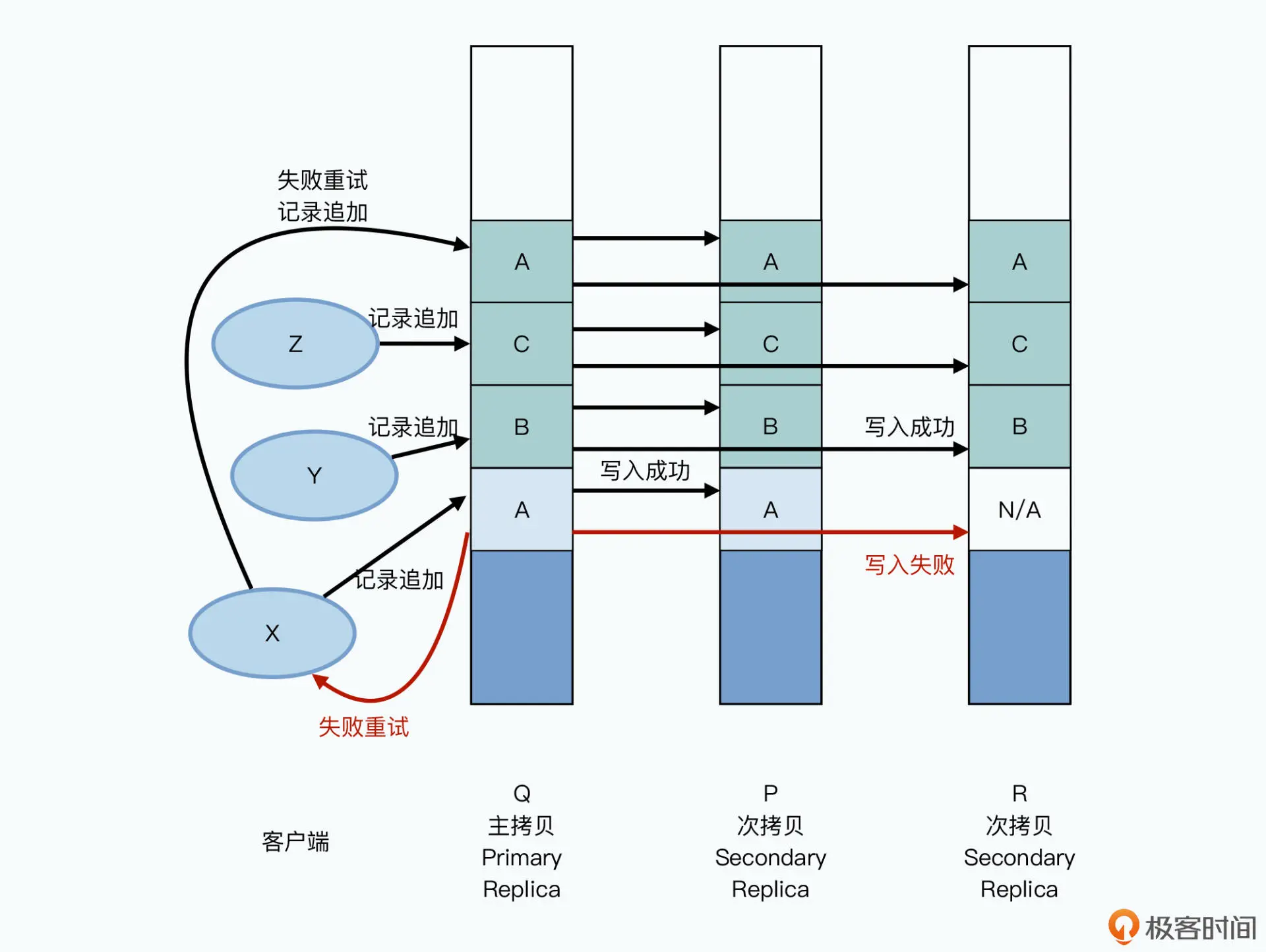
- 改写:写操作的chunk副本间一定一致,但是多个chunk对改写的执行顺序不一定相同,可能使改写的结果和与预期的结果不一致
GFS 如何保证多副本一致?
- 一个chunk所有副本写入顺序一致,这是由控制流和数据流分离实现的,控制流由primary发出,副本的写入顺序也是由primary到secondary
- 使用chunk版本号检测chunk副本是否宕机过。失效的副本不在被master记录,GC程序自动回收
- master定期检测chunk副本的checksum确定是否正确
- GFS 推荐使用追加达到更高一致性

快照机制 Snapshot
保持文件的一个瞬间状态,用于备份或回滚。使用COW写时复制技术。
- master 回收对应chunk的租约,停止对应chunk的所有写入
停止文件 fileA 写入 - 拷贝一份文件的元数据并重命名为快照,仍指向元文件
生成 fileA_backup 元数据 - 增加文件对应的全部chunk引用计数
fileA 和 fileA_backup 都指向对应chunk - master正常授权租约,允许对chunk进行写入
开启文件 fileA 的写入 - 下次修改文件时,发现其chunk引用技术大于1,修改时先拷贝一个新chunk,向新的写入
对应3各chunk A B C,C有写入,那么拷贝C为C',并写入C',fileA 指向 ABC',fileA_backup 指向 ABC
垃圾回收 GC
使用场景:
- 直接删除文件
- 丢失修改操作而失效的副本,失败的场景
- checksum校验失败而失效的副本
机制:
- 删除文件时不立即删除,而是修改文件元数据。Master定期扫描namespace元数据,删除超过一定时间就将其删除
- Master 定期扫描各chunkserver汇报的chunk集合,发现没有对应元数据的chunk就将其删除