整体流程于上一份微调文件基本一致,此份是详细备份及关键说明:
1.处理文件
处理好法律名词解释为json文件的格式,其中prompt column为 content,response column 为summary,如下:
(如果KEY不是content-summary的形式,也可修改train.sh对应的项,见后文)

2.数据上传与下载
将处理好后的文件压缩上传,打开oss软件,.\oss login登录后使用oss指令上传文件:
cp 压缩文件所在目录\xxx.zip oss://
在恒源云的终端,登录后转到对应的文件夹(此处是ChatGLM/ChatGLM-6B-main/ptuning),下载后解压,指令如下:
`cd /ChatGLM/ChatGLM-6B-main/ptuning //转到微调文件夹
`oss cp oss://xxx.zip .`//下载压缩数据文件
`unzip -q xxx.zip` //解压
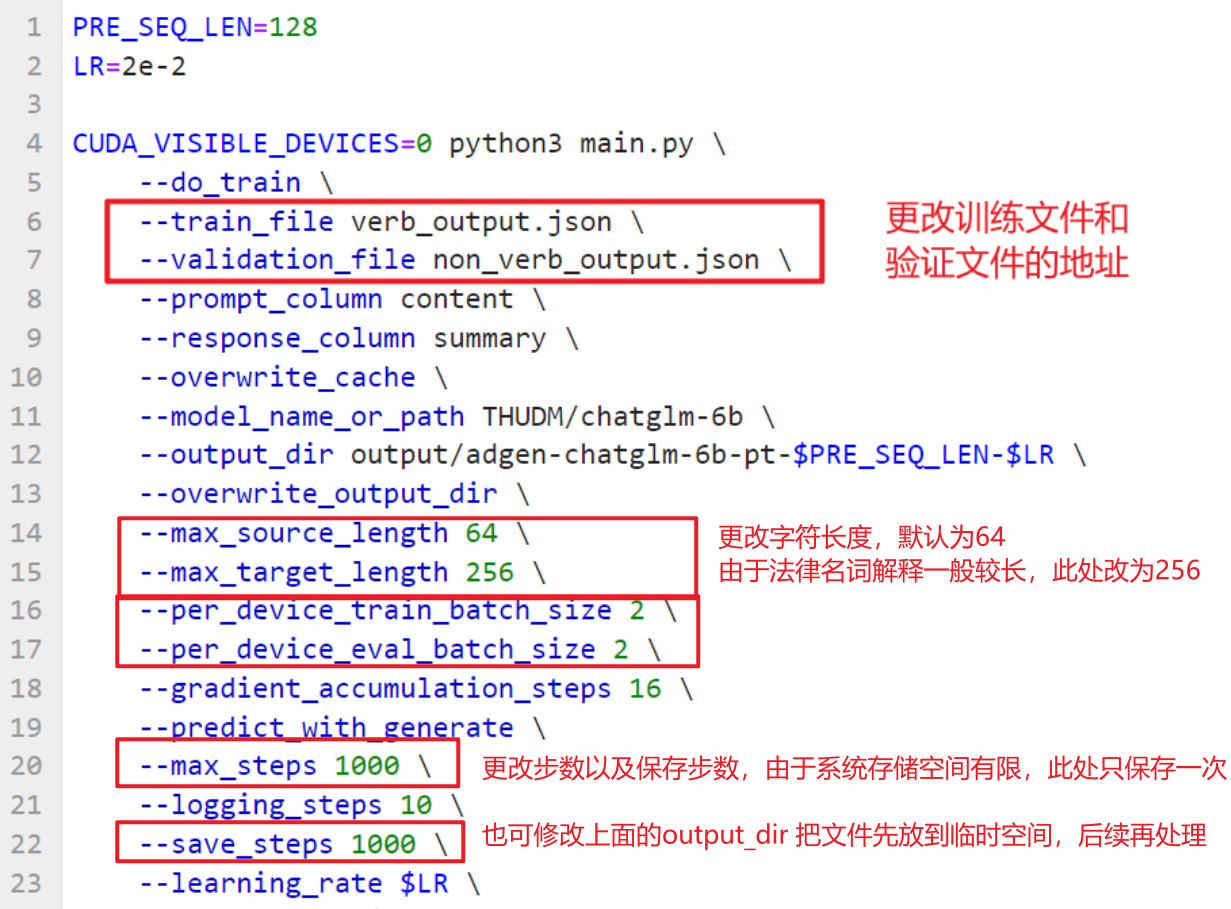
3.更改训练文件参数
修改train.sh和evaluate.sh中的train_file、validation_file和test_file为你自己的 JSON 格式数据集路径,并将prompt_column和response_column修改为 JSON 文件中输入文本和输入文本对应的 KEY。
同时要更改字符长度,因为法律名词的解释较长,所以将target改为256比较合适。
修改batch size,可以增加显存的利用率,默认为1,此处设置为2,可尝试设为4。
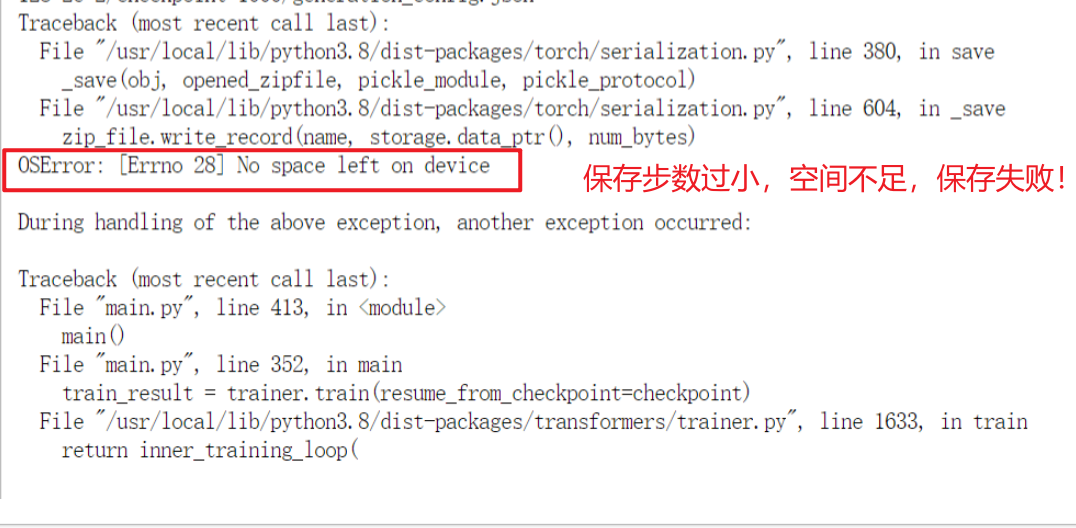
修改步数,主要是save step,由于系统空间较小,可通过增大save step来减少保存次数,减少存储量;还可以通过更改输出目录,将输出保存到临时空间中,不会占用系统空间,但是后续还需移动。
4.启动训练
上述更改保存后,执行代码开始训练
bash train.sh
此步骤后,生成的文件默认存放于 ./output/adgen-chatglm-6b-pt-8-1e-2/。
5.评估
修改evaluate.sh文件,修改内容同上,不再赘述。同时运行,生成评估文件
bash evaluate.sh
此步骤后,结果存放于 ./output/adgen-chatglm-6b-pt-8-1e-2/generated_predictions.txt。
6.部署模型
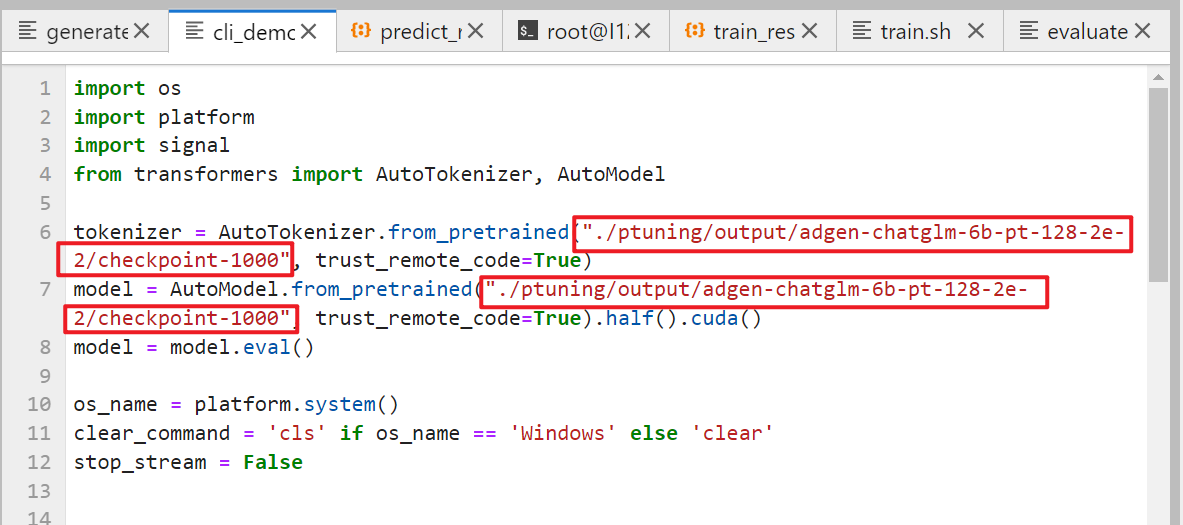
返回ChatGLM/ChatGLM-6B-main/,修改cli_demo.py文件。将文件中的模型改为训练后产生的checkpoints的地址(此处为./ptuning/output/adgen-chatglm-6b-pt-128-2e-2/checkpoint-1000)
上述步骤保存后,执行代码开始运行:
python cli_demo.py
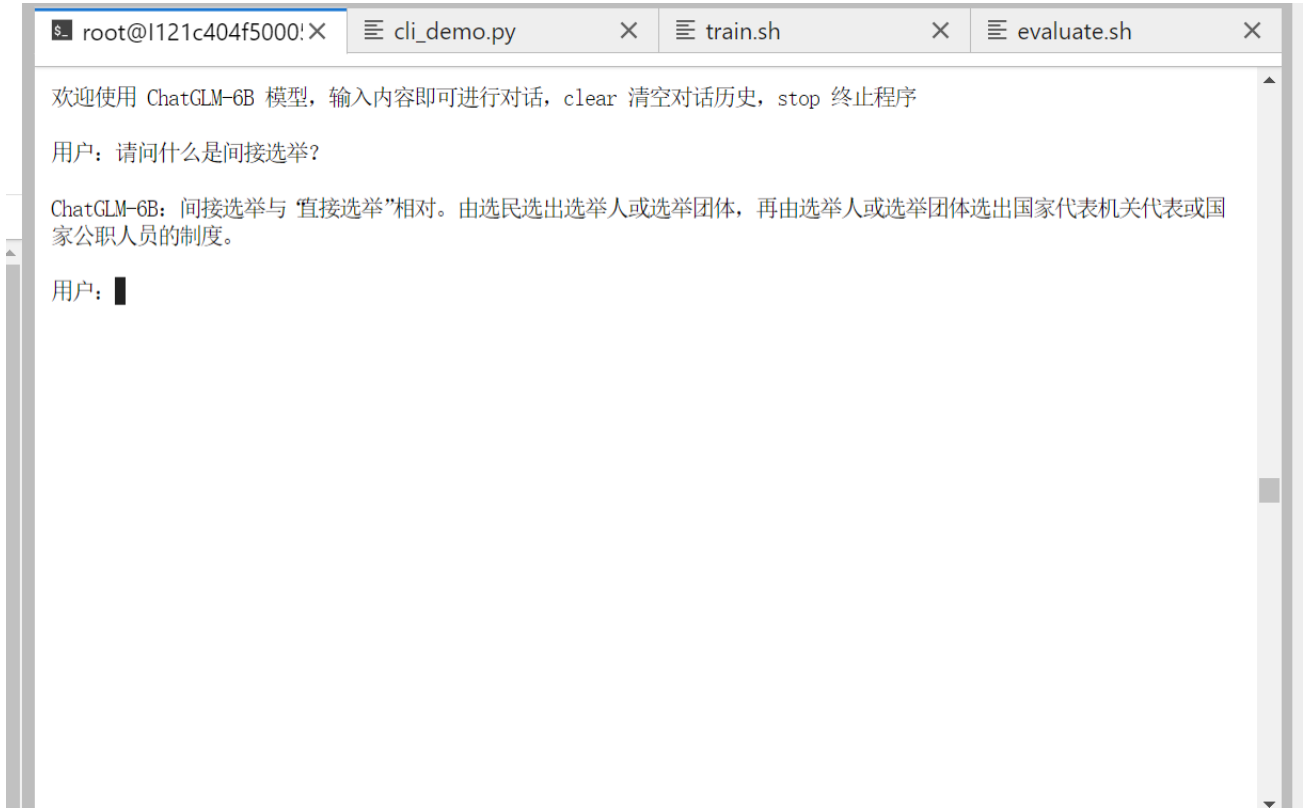
(注意:根据官方文档说明,微调后模型只支持第一轮对话,后续对话可能会生成错误!)

附:
对于以下情形,如果要直接定位到详细解释,就需要把训练数据改为具体解释,而不是“详见xxx”这种格式。

