1 序言
- 本文章是博主正式入门学习、实践大数据流批一体数据处理的Flink框架的第1篇文章,本文是根据参考文章做完实验后的过程总结、技术总结。
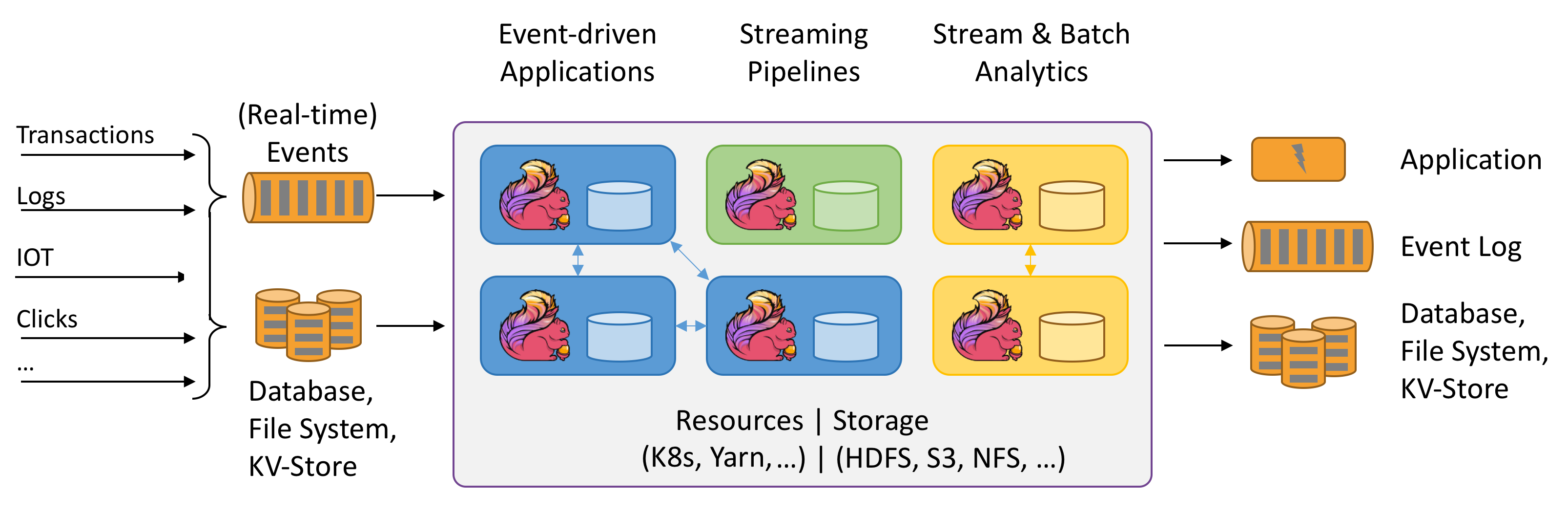
2 实验步骤
- 实验思路:使用
socketTextStream对接netcat
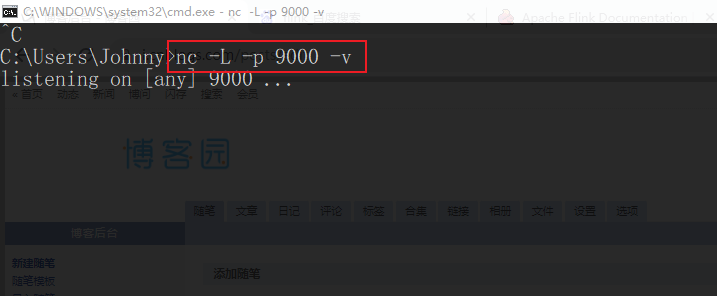
Step0 创建最简易的数据消息通道环境:基于netcat
- 方式1: Windows OS:
nc -l -p 9000
-l: 开启监听
-p:指定端口
- 方式1: MacOS :
nc -lvnp 9000
未亲测
安装方式: Mac安装Netcat教程 - CSDN
Step1 创建Maven项目,引入flink依赖
- pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.johnnyzen</groupId>
<artifactId>study-flink</artifactId>
<version>1.0.0-SNAPSHOT</version>
<name>study-flink</name>
<!-- FIXME change it to the project's website -->
<url>https://flink.apache.org/</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.8</java.version>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<flink.version>1.12.2</flink.version>
<junit.version>4.12</junit.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
</project>
Step2 编写Demo类: WordCount.java
数据处理思路
- inputs:
{"Hello World", "Hello this is a Flink Job"}
分别先后输入2段文本
- data handle process:
- 基于
SocketTextStream,实时接收消息通道的文本数据
{"Hello World", "Hello this is a Flink Job"}
- 首先,将文本分词
"Hello", "World", "Hello", "this", "is", "a", "Flink", "Job"
- 然后,过滤(筛除)掉词汇长度小于4的词汇
"Hello", "World", "Hello", "this", "Flink"
接着,将留下的词汇英文字母全部转大写
最后,打印输出
WordCount
package cn.johnnyzen.study.flink.demo;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.concurrent.TimeUnit;
public class WordCount {
private final static Logger logger = LoggerFactory.getLogger(WordCount.class);
private final static String JOB_NAME = "word-count-job";
public static void main(String[] args) throws Exception {
// 1.准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置运行模式 | STREAMING, BATCH , AUTOMATIC
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//(可选) 设置重启策略 | 没有指定重启策略,在本地部署时,不需要指定重启策略。
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 尝试重启的次数
Time.of(10, TimeUnit.SECONDS) // 间隔
));//以免报: Caused by: org.apache.flink.runtime.JobException: Recovery is suppressed by NoRestartBackoffTimeStrategy
// 2.加载数据源
DataStreamSource<String> elementsSource = env.socketTextStream("127.0.0.1", 9000);
// 3.数据转换
/**
* flapMap operator (flatMap 算子)
* inputStream = { "Hello World", "Hello this is a Flink Job" }
* operator code : val words = dataStream.flatMap ( input => input.split(" ") )
* output: ["Hello", "World", "Hello", "this", "is", "a", "Flink", "Job"]
*/
DataStream<String> originWordsDataStream = elementsSource.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String element, Collector<String> out) {
logger.info("element | {}", element);
String[] wordArr = element.replace(".", " ").replace(",", " ").split(" ");
for (String word : wordArr) {
out.collect(word);
}
}
});
DataStream<String> filterWordDataStream = originWordsDataStream.filter(new FilterFunction<String>() {
@Override
public boolean filter(String word) throws Exception {
boolean flag = false;
flag = word.length() > 3 ? true : false;
return flag;
}
} );
//DataStream 下边为 DataStream 子类
SingleOutputStreamOperator<String> source = filterWordDataStream.map(new MapFunction<String, String>() {
@Override
public String map(String value) {
return value.toUpperCase();
}
});
// 4.数据输出
source.print();
//dataStream.print();
// 5.执行程序
env.execute(JOB_NAME);
}
}
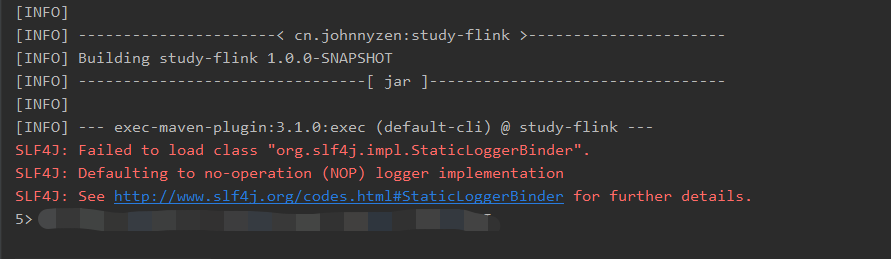
刚启动后
Flink Job
Netcat 窗口
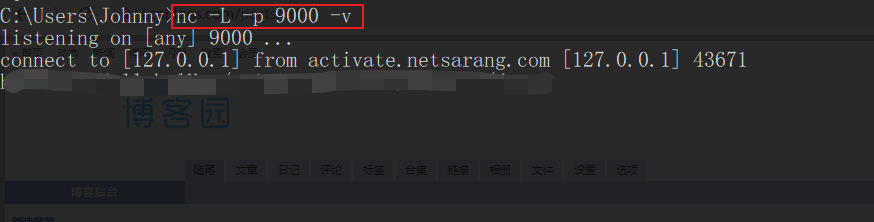
Step3 验证与测试
在netcat终端窗口输入流式文本
Hello World
Hello this is a Flink Job

Flink 作业终端
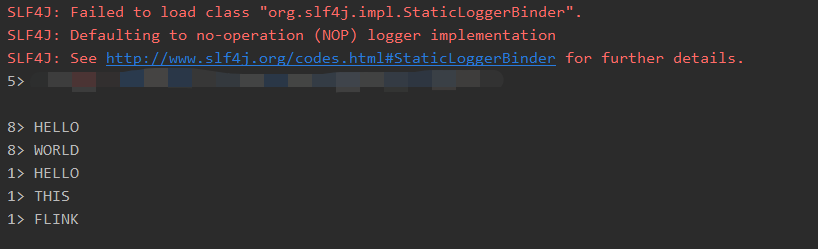
output
HELLO
WORLD
HELLO
THIS
FLINK
X 参考文献
- Apache Flink