Hive
基于HDFS和MapReduce提供了一个基本的SQL的数据仓库方案。关键点:在数据库系统设计时,如何把查询语言和计算框架分离,做好对现有系统的复用
设计目标
写SQL执行MapReduce任务
数据模型
从MapReduce任务到SQL语言间存在很多鸿沟
序列化和类型信息,基于SQL的数据库有明确的表结构,字段类型明确。MapReduce任务中没有字段与字段类型。要对数据的输入输出加上类型系统。GFS论文中输入数据的解析由用户进行解析,Hadoop中可自定义 InputFormat/OutputFormat 和对应的 RecordReader/RecordWriter 实现。这些接口将MapReduce读写HDFS与序列化的过程单独剥离出来。用户在实现具体map和reduce函数时,只要关心业务逻辑即可,因为map和reduce中输入输出的key和value都是java类型对象。
Hive利用了Hadoop这个功能。Hive使用者不再面对“输入文件、输入文件的格式”,而是直接读取Hive中的“表”,拿到的格式也是数据库概念中的“行”。通过 InputFormat 解析拿到一个 key-value 对就是一“行”数据。既然是数据库表,则Hive不需要key-value对,所以拿到kv对后再使用序列化/反序列化器获得Row对象,其包含一个个Column的值

Hive在 InputFormat/OutputFormat 外添加了一层序列化/反序列化将数据转化为数据库中的“行”
Hive支持整型、浮点型、字符串、数组、关联数组、结构体等。
数据存储
底层表以文件形式放在HDFS上,一张Hive表占用一个HDFS目录,里面存放实际数据文件。运行Hive的HQL就是通过MapReduce扫描文件获得结果。但每次分析都要全表扫描,因为HDFS没有索引,数据使用类似CSV的格式存储。于是采用分区、分桶。
例如按照日期和国家分区,通过在表的目录里添加两次目录,分别通过 ds=20090101 和 ctry=CA 标注。执行涉及日期和国家过滤条件时无需全表扫描。
/wh/T/ds=20090101/ctry=CA
/wh/T/ds=20090101/ctry=US
/wh/T/ds=20090102/ctry=CA
/wh/T/ds=20090102/ctry=us
...
FROM (
SELECT a.status, b.school, b.gender
FROM status_updates a JOIN profiles b
ON
(a.userid=b.userid and a.ds="2009-01-01")
)subq1
// 会根据时间条件查询分区,获取目录里的文件分桶:分区后的子目录,Hive能针对某一列的Hash取模分成多个文件。不能用于过滤检索,但提供了采样分析功能。如:将日志按id分成100个桶,在分析数据时指定看5个桶的数据,即可采样5%。
/wh/T/ds=20090101/ctry=CA/000000_0
/wh/T/ds=20090101/ctry=CA/000001_0
/wh/T/ds=20090101/ctry=US/000000_0
/wh/T/ds=20090101/ctry=US/000001_0架构和性能
数据表的字段和类型通过SerDer解析确定,数据的分区分桶就是通过目录和文件名区分
- 对外接口
命令行、Web界面、JDBC、ODBC - 驱动器
将HQL语言变为MapReduce任务,不涉及分布式和计算,只涉及编译 - Metastore
用于存储Hive里各种元数据,表的名称、位置、列的名称类型。通过从使用关系型数据库存储。若没有Metastore的话Hive就像Pig只是一个DSL,正是Metasotre让Hive变成完整的数据仓库解决方案。驱动器各个模块也要通过Metastore里数据,校验解析HQL时的字段,确定执行时从哪些目录读取。
驱动器
- 编译器
将HQL编译为逻辑计划,得到一个实际的抽象语法树(AST),每个节点都是操作符 - 优化器
拿到逻辑计划,根据MapReduce任务特定优化,变成物理计划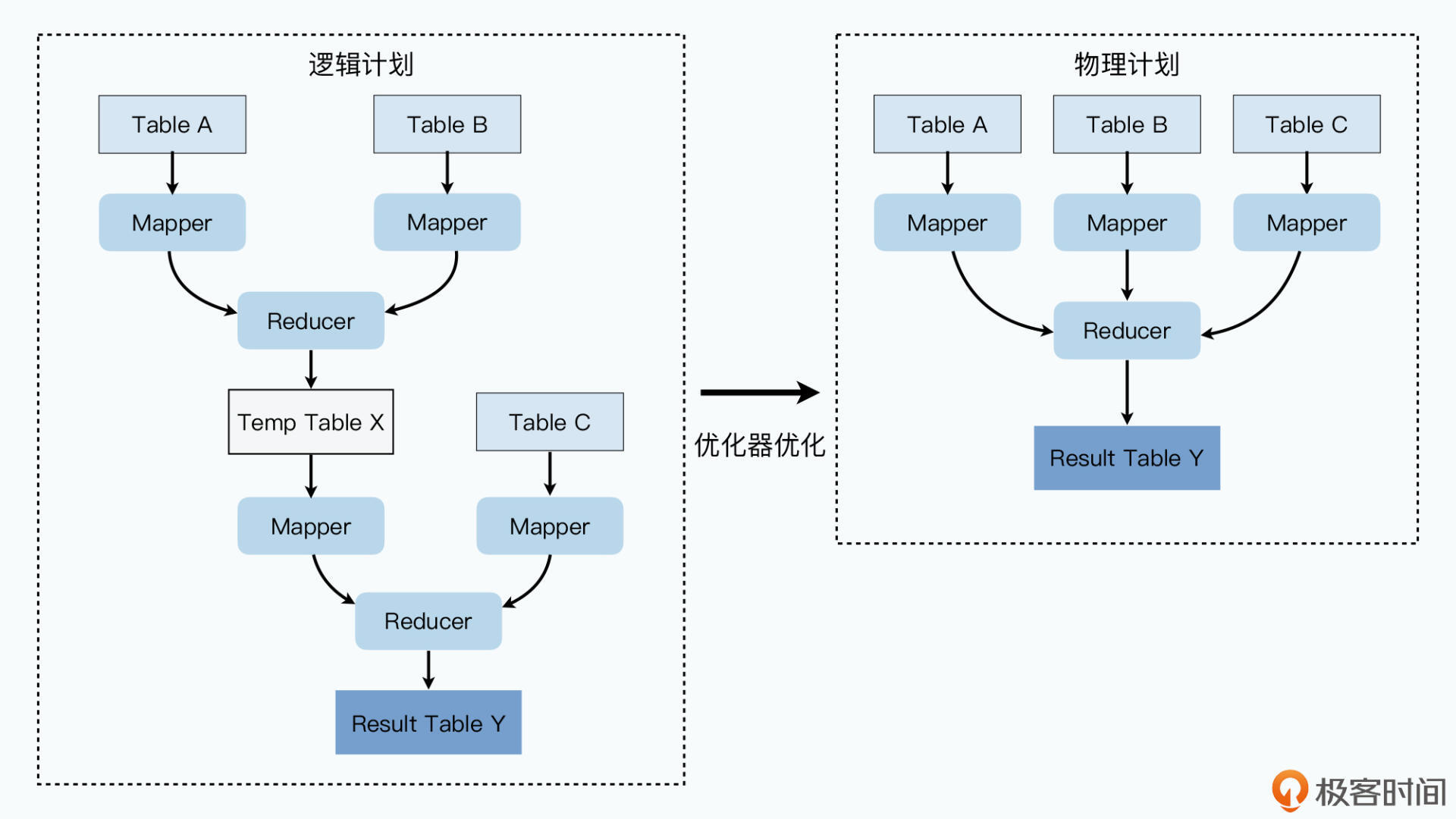
- 一个执行引擎和有向无环图
通过一个执行引擎和DAG,按照顺序执行,执行引擎就是Hadoop的MapReduce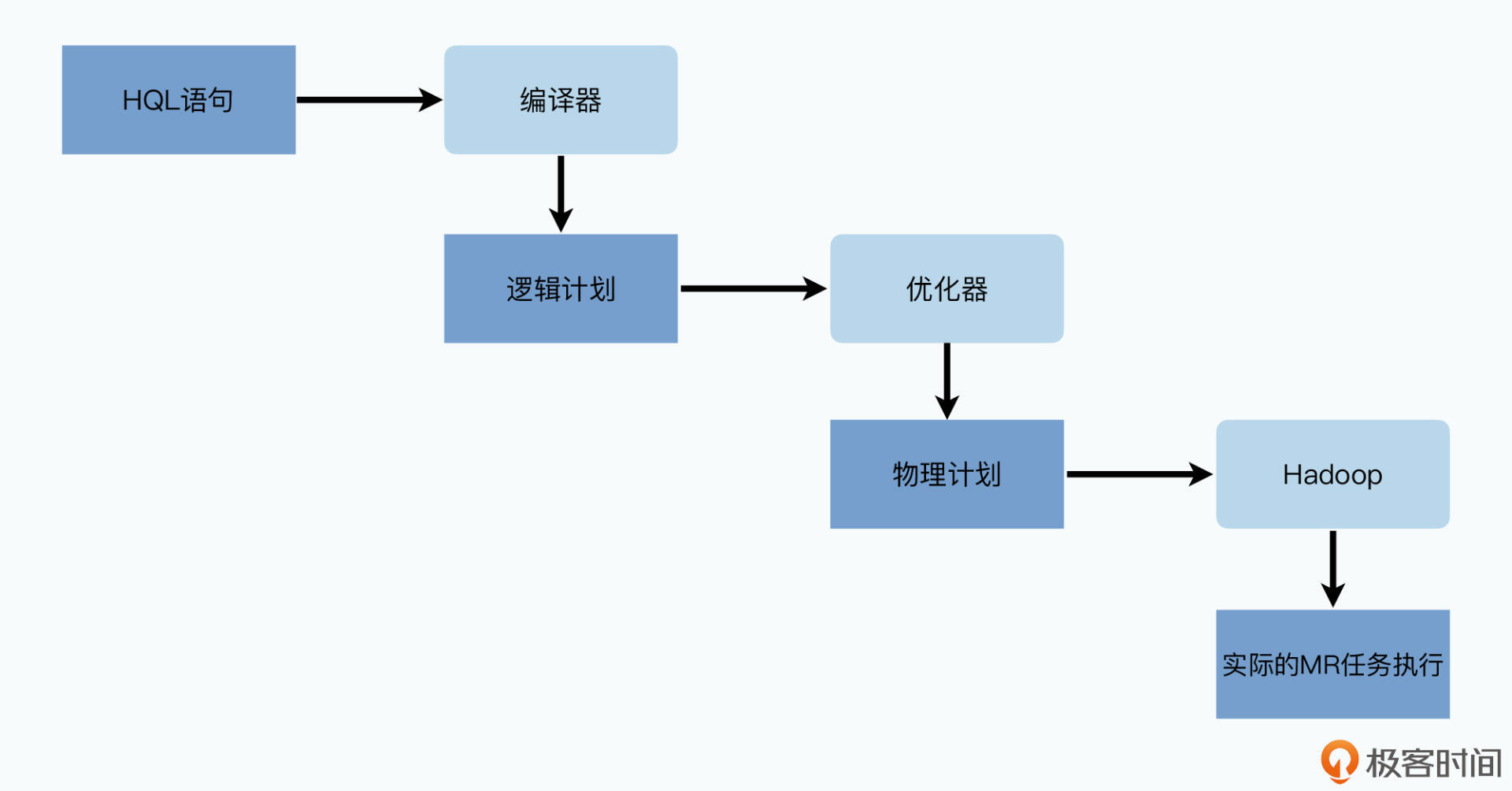
Hive就是一个HQL编译器 + 优化器,存储与计算都是由Hadoop实现。
HQL的编译与优化:Hive SQL的编译过程 - 美团技术团队 (meituan.com) tech.meituan.com/2014/02/12/hive-sql-to-mapreduce.html