Deeplab系列讲解
DeepLab系列论文一共有四篇,分别是DeepLab V1、DeepLab V2、DeepLab V3、DeepLab V3+。
因为卷积神经网络的空间信息细节已经被高度抽象画,所以它就具有很好的平移不变性,这样可以能够很好的处理图像分类问题,但是它的最后一层的输出不足以准确的定位物体进行像素级分类
一、基础知识
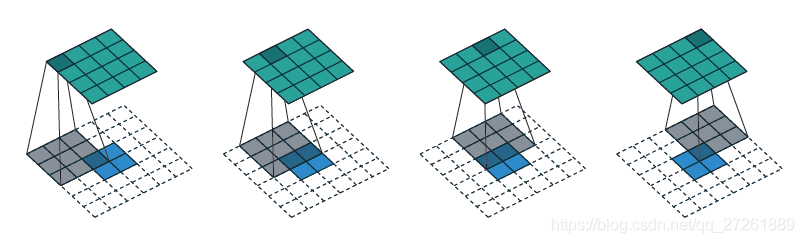
1.1 空洞卷积
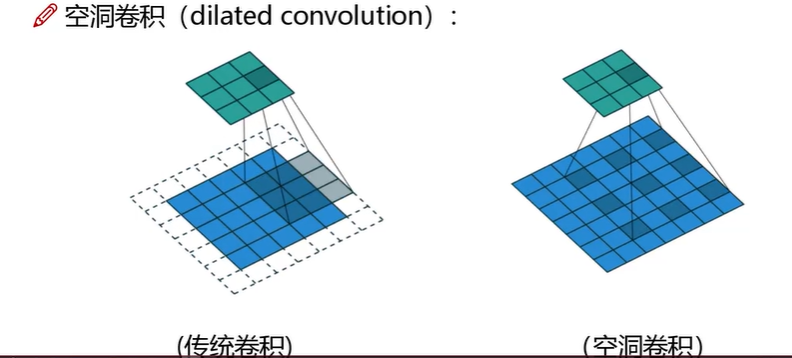
如上图所示,同样的两个卷积输出的特征图大小事3×3,其中传统卷积3×3对应的感受野的大小是5×5(此处stride为2),空洞卷积参数也是3×3,但这是尺寸为5×5,这是dilated为2自动构建的空洞卷积。其对应的感受野则是7×7。
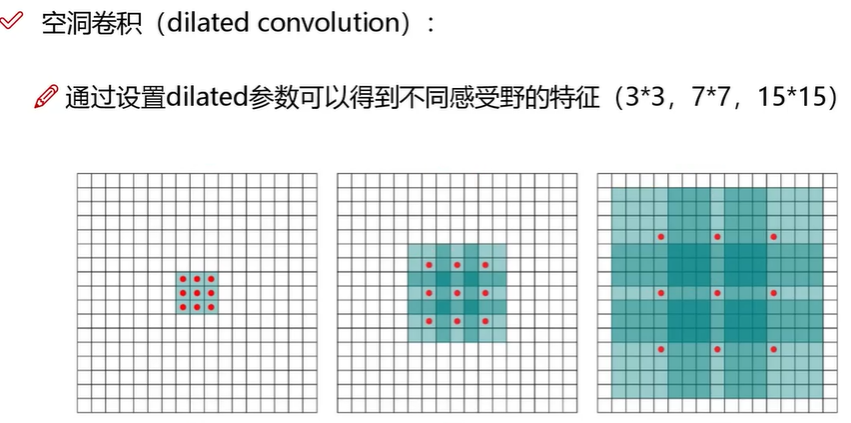


上面两图清晰表达了网络中常用3×3卷积进行堆叠操作了,在感受野相同情况下,堆叠计算量少,同时增加了非线性变换。
1.2 SPP

SPP网络在yolo中也曾经应用过,即通过maxpooling操作,使输出固定。原理是:无论输入的特征图尺寸多大,分别分成4×4,2×2,1×1大小的块,如此输出就是(16+4+1)×256.(在maxpoolin构建中因为输入特征图大小不同,则pool的size以及stride也不同)

第一张图为图像金字塔解决多尺度问题,此处耗时。第二张为unet结构,多尺度输入。第三张为unet引入了空洞卷积,第四章则是在spp中引入了空洞卷积替代了maxpool,具体为:
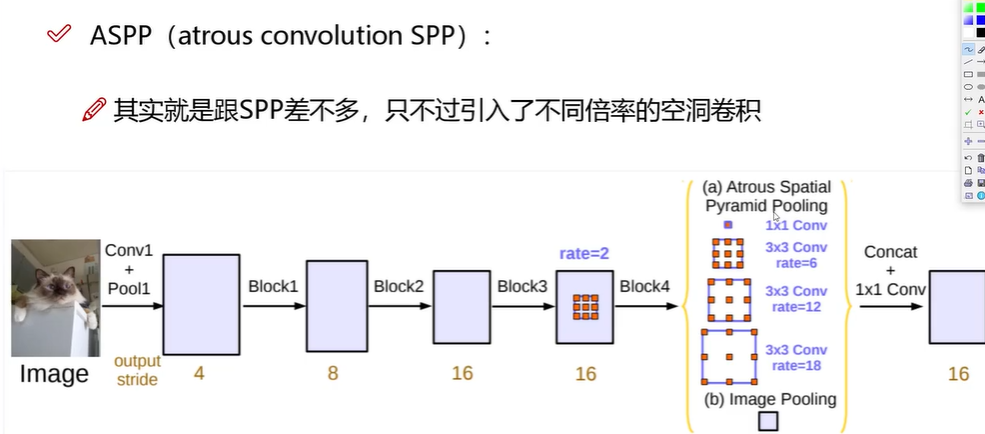
因为空洞卷积的rate不同,感受野不同,重点关注特征也不同,进而实现了多尺度问题,同时保证输出的大小相同,为contact打好基础。这就是ASPP。
1.3 DeeplabV3+!
DeepLab v1:空洞卷积+CRF
- 减少下采样次数,尽可能的保留空间位置信息;
- 使用空洞卷积,扩大感受野,获取更多的上下文信息;
- 采用完全连接的条件随机场(CRF)这种后处理方式,提高模型捕获细节的能力。
DeepLab v2:ASPP
- 在DeepLab v1的基础上提出了图像多尺度的问题,并提出ASPP模块来捕捉图像多个尺度的上下文信息。
- 仍然使用CRF后处理方式,处理边缘细节信息。
DeepLab v3:改进ASPP
- 改进了ASPP模块:加入了BN层,
- 探讨了ASPP模块的构建方式:并行的方式精度更好。
- 由于大采样率的空洞卷积的权重变小,只有中心权重起作用,退化成1×11×11×11×1卷积。所以将图像级特征和ASPP特征进行融合。
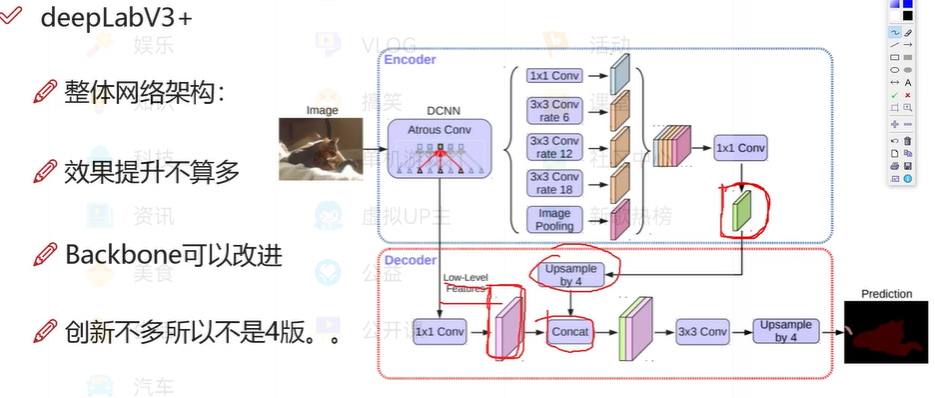
DeepLab v3+:deeplabv3 + encoder-decoder
- 使用了encoder-decoder(高层特征提供语义,decoder逐步回复边界信息):提升了分割效果的同时,关注了边界的信息
- encoder结构中:采用Xception做为 BackBone,并将深度可分离卷积(depthwise deparable conv)应用在了ASPP 和 encoder 模块中,使网络更快。
deeplab的思想与unet不相同,在向分类网络靠拢,区别在于head的处理方式不同。如果从分割理论上将编码和解码差异还是比较大。
二、源码讲解
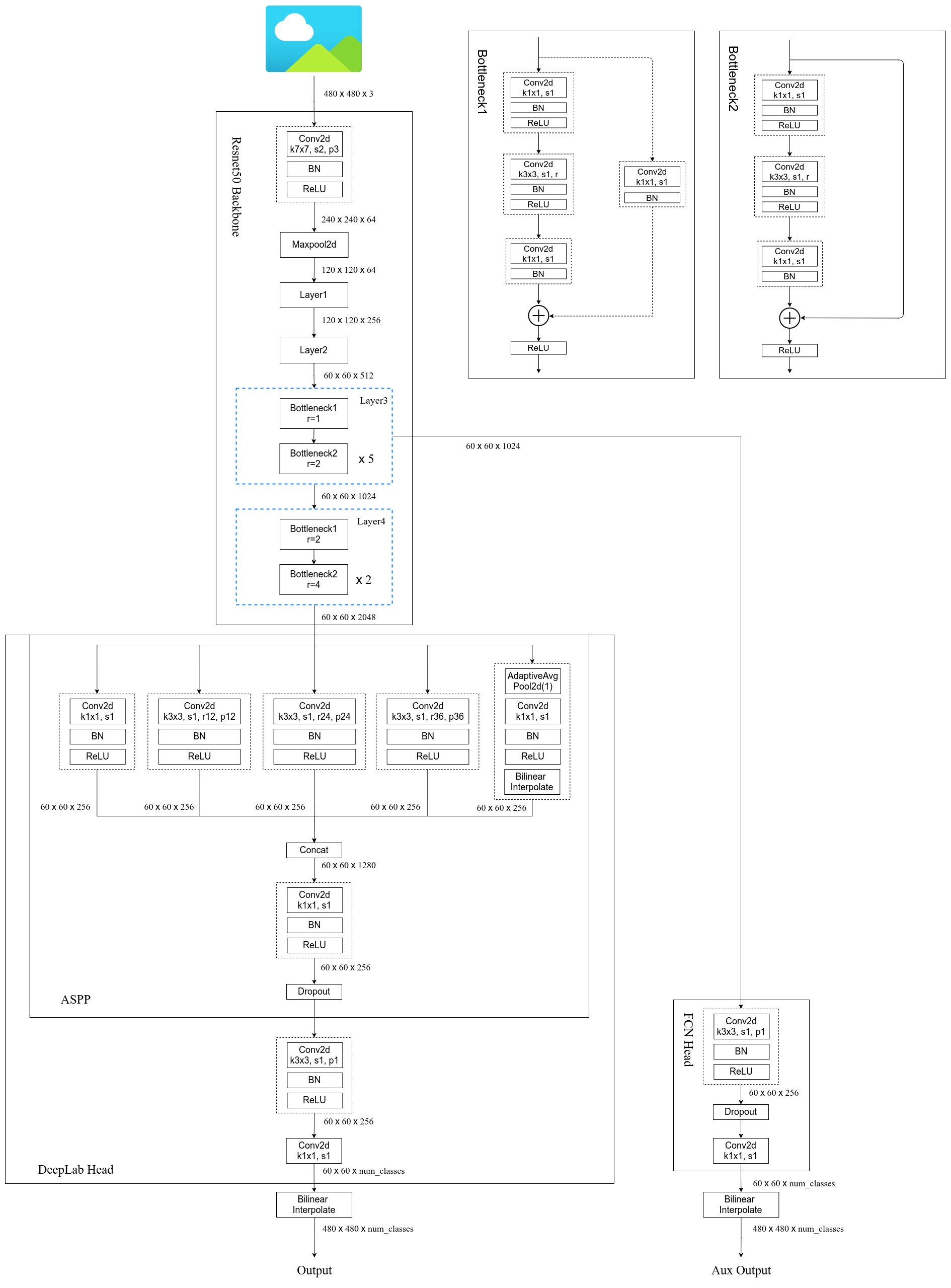
2.1 不同网络层的配置文件讲解

文章中源码使用mmsegmention,上图分别是三个网络的配置文件详情,为此针对重点模块讲解。
2.2 整体逻辑
在网络构造中,基本使用EncoderDecoder引擎,训练的代码为:
def loss(self, inputs: Tensor, data_samples: SampleList) -> dict:
"""Calculate losses from a batch of inputs and data samples.
Args:
inputs (Tensor): Input images.
data_samples (list[:obj:`SegDataSample`]): The seg data samples.
It usually includes information such as `metainfo` and
`gt_sem_seg`.
Returns:
dict[str, Tensor]: a dictionary of loss components
"""
x = self.extract_feat(inputs)
losses = dict()
loss_decode = self._decode_head_forward_train(x, data_samples)
losses.update(loss_decode)
if self.with_auxiliary_head:
loss_aux = self._auxiliary_head_forward_train(x, data_samples)
losses.update(loss_aux)
return losses
大体逻辑为:
1、主干网络提取特征
2、解码头进行loss计算
3、一般还有辅助头,同时更新loss
主干提取代码为:
def extract_feat(self, inputs: Tensor) -> List[Tensor]:
"""Extract features from images."""
x = self.backbone(inputs)
if self.with_neck:
x = self.neck(x)
return x
loss的代码操作为:
def _decode_head_forward_train(self, inputs: List[Tensor],
data_samples: SampleList) -> dict:
"""Run forward function and calculate loss for decode head in
training."""
losses = dict()
loss_decode = self.decode_head.loss(inputs, data_samples,
self.train_cfg)
losses.update(add_prefix(loss_decode, 'decode'))
return losses
def _auxiliary_head_forward_train(self, inputs: List[Tensor],
data_samples: SampleList) -> dict:
"""Run forward function and calculate loss for auxiliary head in
training."""
losses = dict()
if isinstance(self.auxiliary_head, nn.ModuleList):
for idx, aux_head in enumerate(self.auxiliary_head):
loss_aux = aux_head.loss(inputs, data_samples, self.train_cfg)
losses.update(add_prefix(loss_aux, f'aux_{idx}'))
else:
loss_aux = self.auxiliary_head.loss(inputs, data_samples,
self.train_cfg)
losses.update(add_prefix(loss_aux, 'aux'))
return losses
将特征图和真实标定图像进行loss计算,具体实现代码见下节讲解。
在代码中,loss的具体实现在head里面的loss实现,进而找到ASPP的代码,在
class ASPPHead(BaseDecodeHead):
"""Rethinking Atrous Convolution for Semantic Image Segmentation.
This head is the implementation of `DeepLabV3
<https://arxiv.org/abs/1706.05587>`_.
Args:
dilations (tuple[int]): Dilation rates for ASPP module.
Default: (1, 6, 12, 18).
"""
继承了基类,基类有其loss执行,代码为:
def loss(self, inputs: Tuple[Tensor], batch_data_samples: SampleList,
train_cfg: ConfigType) -> dict:
"""Forward function for training.
Args:
inputs (Tuple[Tensor]): List of multi-level img features.
batch_data_samples (list[:obj:`SegDataSample`]): The seg
data samples. It usually includes information such
as `img_metas` or `gt_semantic_seg`.
train_cfg (dict): The training config.
Returns:
dict[str, Tensor]: a dictionary of loss components
"""
seg_logits = self.forward(inputs)
losses = self.loss_by_feat(seg_logits, batch_data_samples)
return losses
进而找到ASPP的forward函数
def forward(self, inputs):
"""Forward function."""
output = self._forward_feature(inputs)
output = self.cls_seg(output)
return output
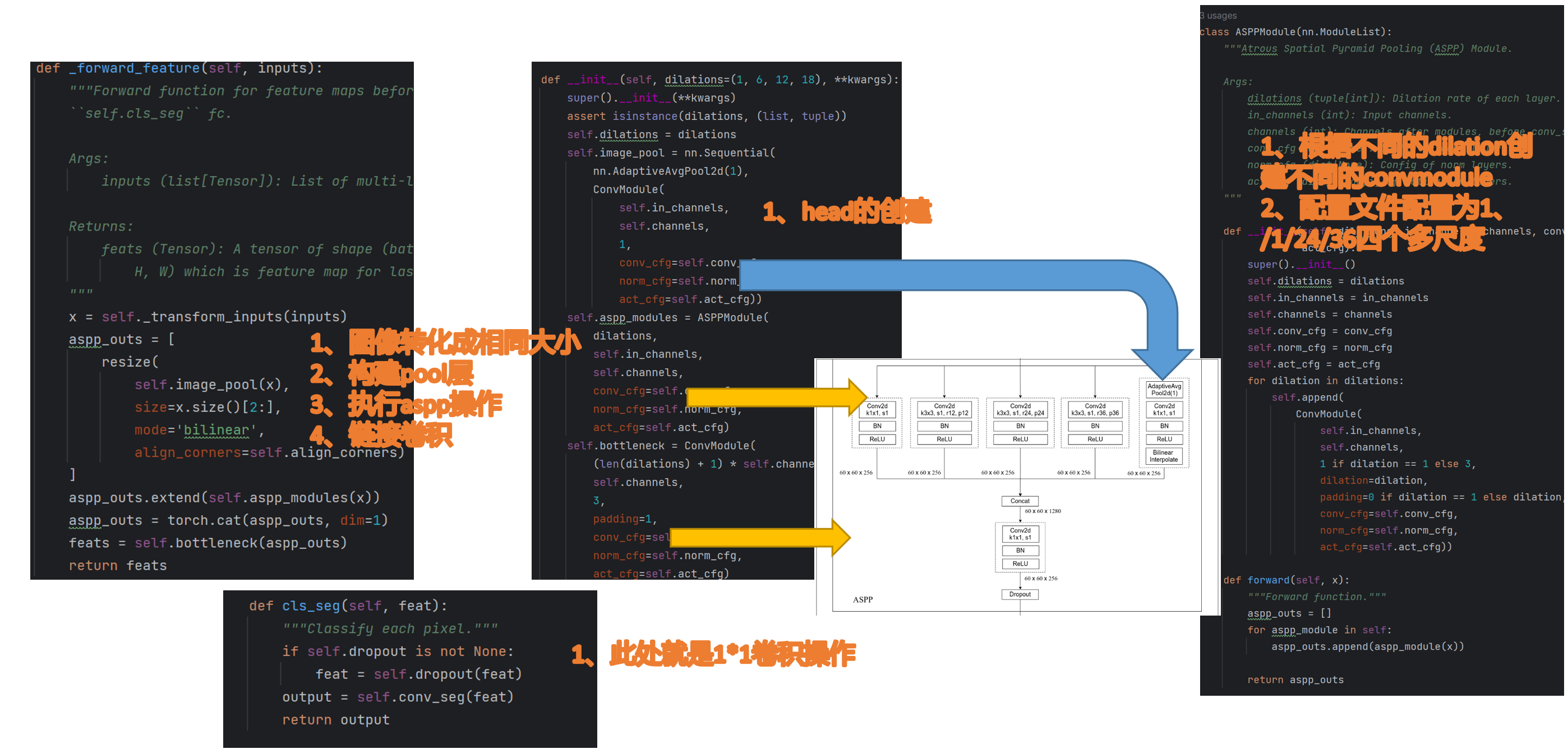
整体代码结构比较简单
2.3 ResnetV1c
@MODELS.register_module()
class ResNetV1c(ResNet):
"""ResNetV1c variant described in [1]_.
Compared with default ResNet(ResNetV1b), ResNetV1c replaces the 7x7 conv in
the input stem with three 3x3 convs. For more details please refer to `Bag
of Tricks for Image Classification with Convolutional Neural Networks
<https://arxiv.org/abs/1812.01187>`_.
"""
def __init__(self, **kwargs):
super().__init__(deep_stem=True, avg_down=False, **kwargs)
正如注释所讲,这是常规的残差网络,但此处用了3个3×3卷积,替换了7×7卷积,此处不再详解
2.3 逆卷积
对于一个图片A,设定它的高度和宽度分别为Height,Width,通道数为Channels。 然后我们用卷积核(kernel*kernel)去做卷积,(这里设定卷积核为正方形,实际长方形也可以类推),步长为stride(同样的,不区分高宽方向),做padding,卷积后得到B。重复上面的话就是利用一个卷积操作将A变成B
逆卷积的示意图。
第一步:对输入的特征图a进行一些变换,得到新的特征图a′
第二步:求新的卷积核设置
第三步:用新的卷积核在新的特征图上做常规的卷积,得到的结果就是逆卷积的结果。
class DeconvModule(nn.Module):
"""Deconvolution upsample module in decoder for UNet (2X upsample).
This module uses deconvolution to upsample feature map in the decoder
of UNet.
Args:
in_channels (int): Number of input channels.
out_channels (int): Number of output channels.
with_cp (bool): Use checkpoint or not. Using checkpoint will save some
memory while slowing down the training speed. Default: False.
norm_cfg (dict | None): Config dict for normalization layer.
Default: dict(type='BN').
act_cfg (dict | None): Config dict for activation layer in ConvModule.
Default: dict(type='ReLU').
kernel_size (int): Kernel size of the convolutional layer. Default: 4.
"""
def __init__(self,
in_channels,
out_channels,
with_cp=False,
norm_cfg=dict(type='BN'),
act_cfg=dict(type='ReLU'),
*,
kernel_size=4,
scale_factor=2):
super().__init__()
assert (kernel_size - scale_factor >= 0) and\
(kernel_size - scale_factor) % 2 == 0,\
f'kernel_size should be greater than or equal to scale_factor '\
f'and (kernel_size - scale_factor) should be even numbers, '\
f'while the kernel size is {kernel_size} and scale_factor is '\
f'{scale_factor}.'
#重点在此
#放大系数等于stride。根据逆卷积步骤,根据stride首先插值形成新的特征图,大小已经等于
#输出特征图大小,剩下就是普通卷积的操作了
stride = scale_factor
padding = (kernel_size - scale_factor) // 2
self.with_cp = with_cp
deconv = nn.ConvTranspose2d(
in_channels,
out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding)
norm_name, norm = build_norm_layer(norm_cfg, out_channels)
activate = build_activation_layer(act_cfg)
self.deconv_upsamping = nn.Sequential(deconv, norm, activate)
2.3 ASPP
先看ASPP的整体结构为:
def _forward_feature(self, inputs):
"""Forward function for feature maps before classifying each pixel with
``self.cls_seg`` fc.
Args:
inputs (list[Tensor]): List of multi-level img features.
Returns:
feats (Tensor): A tensor of shape (batch_size, self.channels,
H, W) which is feature map for last layer of decoder head.
"""
x = self._transform_inputs(inputs)
#获取特征图,此处对应的imagepool模块,先变小,再变大,此处特征图大小不变
aspp_outs = [
resize(
self.image_pool(x),
size=x.size()[2:],
mode='bilinear',
align_corners=self.align_corners)
]
#此处将特征图输入到aspp模块,获取到了4个特征图
aspp_outs.extend(self.aspp_modules(x))
#所有特征图连起来,然后卷积操作
aspp_outs = torch.cat(aspp_outs, dim=1)
feats = self.bottleneck(aspp_outs)
return feats
def forward(self, inputs):
"""Forward function."""
output = self._forward_feature(inputs)
output = self.cls_seg(output)
return output