发表时间:2021(NeurIPS 2021)
文章要点:这篇文章提出一个tandem learning的实验范式来研究为什么offline RL很难学。对于offline RL来说,一个很严重的问题就是extrapolation error,也就是没见过的state action pair的估计是不准确的。再加上bootstrapping的更新方式,就会加剧误差导致over estimation的问题。
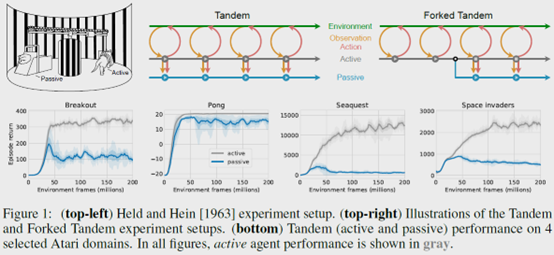
作者基于心理学的实验,提出了一个tandem RL的实验。就是在训练过程中,有一个active agent和一个passive agent。其中active agent和环境交互产生数据,然后active agent和passive agent基于这些数据进行相同的更新,然后来看这两个agent的效果。所以这个实验的区别就是,active agent更新了之后还可以和环境交互得到新的反馈并收集相应的新的data。但是passive agent只能被动的接受这些data拿来更新训练。得到的现象就是passive agent的效果是大大不如active agent的。
作者得到结论有
Bootstrapping并不像之前想象的那样是造成训不好的主要原因(our results indicate an empirically less critical role for bootstrapping than previously hypothesized)。主要的原因还是在于外推误差以及过分的泛化(erroneous extrapolation or over-generalization by a function approximator trained on an inadequate data distribution as the crucial challenge)。
具体的,作者做了这么几个实验。
Tandem:就是之前介绍的有Active and passive agents。并且他们的网络是分别初始化的,也就是说初始参数不同。但是其他都一样,比如网络结构,更新方法等等。
Forked Tandem: 先训练一个agent一段时间,然后active and passive agents都用这个训练的agent作为初始模型。同时,active agent不再训练,只用来和环境交互生成数据。Passive agent根据这些数据进行训练。
作者发现这两个agent大部分的value都不一样,特别是non-argmax actions。而且passive agent的过估计问题随着训练进行越来越严重。

作者就猜测这个过估计的问题可能有三个原因:Bootstrapping,Data Distribution和Function Approximation。

- 对于Bootstrapping,作者基于double DQN设计了四种更新规则
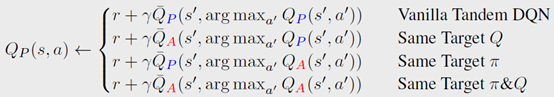
其中第一种就是直接用passive agent的Q来选动作和更新Q value。第二种就是把Q value替换成active agent的。第三种就是把选动作的Q替换成active agent的。第四种就是两者都换成active agent的。如下图结果所示,效果都不行。
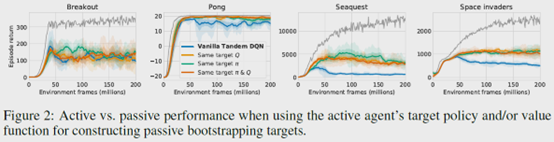
这就说明了并不是bootstrapping的问题造成的offline RL训不上去。 - 接着对于Data Distribution的影响,作者研究了一些可能因素。exploration parameter \(\epsilon\),Sticky actions,Replay size,Fixed policy,Fixed replay,On-policy evaluation,Self-generated data。
作者发现增加\(\epsilon\)后,active agent和passive agent之间的差距变小了,这就说明多覆盖一些non-argmax actions的样本也就是次优动作的样本是有利于缓解offline RL的外推误差的,也就缓解了overestimation。
对于Sticky actions,也就是环境的随机性,实验发现没啥影响。
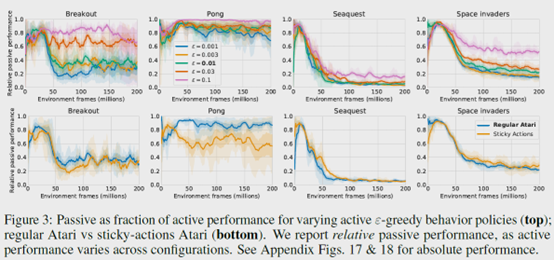
对于Replay size,实验表明增大replay buffer可以缓解问题,但是更多像是减慢performance的下降,并没有解决这个问题。

对于Fixed policy,就是Forked Tandem的设置,产生数据的policy不训练,只生成数据,同时passive agent的初始网络参数和active agent的参数是一样的。但是结果发现,passive agent的performance还是很快下降。这说明问题还是出在learning的过程中,还是由于data distribution和function approximation的原因造成的。
对于Fixed replay,就是说还是基于Forked Tandem,但是data不再更新,就基于现有的数据训练。但是效果还是一样的下降。

对于On-policy evaluation,作者把Q-learning换成了SARSA,也就是说在evaluation的时候不存在off-policy了,完全是on-policy。但是实验仍然效果不行。这说明了也不是off-policy的问题,还是在于data distribution和function approximation的问题。

对于Self-generated data,作者就是说除了active agent外,让passive agent也和环境交互,然后passive agent除了利用active agent收集的数据外,还混入一部分自己交互生成的数据。效果就提升了不少,即使只添加10%的自己的数据,效果也很好了。这说明了,确实是需要自己交互的数据来作为反馈信号,然后修正之前的估值,才是最好的解决办法。

- 最后作者继续做了Function Approximation的影响。主要研究了Optimization和Function class。
对于Optimization,Adam的表现优于RMSProp。另外更新次数越多,performance越差。这说明效果差并不是由更新不充分造成,也间接说明了还是data distribution的问题。
对于Function class,作者发现网络越宽,效果越好。但是网络越深,效果越差。同时,如果保持网络的前面几层随active agent的参数更新,只有最后几层随passive agent更新,效果会好一些。
总结:很有意思的实验,主要在研究的还是说off-policy到底是不是真的off-policy,加上deep了之后问题出在哪。实验很细致,可以多学习。
疑问:感觉还是没有给出具体的解决办法,可能这个问题就是太难了吧。
On-policy evaluation,作者把Q-learning换成了SARSA,这个能算on-policy吗,毕竟都没和环境交互?
- Learning Reinforcement Difficulty Passive Deeplearning reinforcement difficulty passive reinforcement introduction learning deep deep-learning reinforcement learning deep-learning-based learning deep noise reinforcement exploration learning reinforcement distillation teachable learning reinforcement learning chapter reinforcement transformer decision learning