摘要:
- 本文说首次实现了大规模点云场景中基于点的模型的实时检测(<30ms);
- 首先指出FPS采样策略进行下采样是耗时的,尤其当点云增加的时候,计算量和推理时间快速增加;
- 本文提出IC-FPS;包含两个模块:local feature diffusion based background point filter (LFDBF);Centroid Instance Sampling Strategy (CISS);LFDBF用来排除大量的背景点,而CISS用来替代FPS;
简介:
早期的工作将点云投影为多视图,或体素点云,并通过3D卷积提取特征。这些方法虽然取得了很好的效果,但在将点云转换为block等中间表示时,不可避免地会丢失信息,导致模型性能下降。目前的方法依赖于复杂的下采样策略和SA层提取邻居特征;用来区分前景点背景点;这种方法是低效的;
- 首先为了提高下采样速度。提出了CISS替代FPS;
- 其次提出质心点偏移模块,用来恢复实例目标的原始的几何结构;
- LFDBF可以区分前/背景点,减少计算量;
- 为了进一步提高LFDBF的性能,提出了Density-Distance Focal Loss,以确保对远距离处稀疏的前景点进行有效采样;
- 结合CISS和LFDBF,提出IC-FPS;
相关工作:
略
实例质心特征扩散采样模块:
总览
3D检测更加关注目标对象;通常将大量的背景点作为输入,导致后续计算效率低下;
此外,现有的基于点的方法存在FPS等复杂的下采样策略,增加了计算成本和推理时间;
IC-FPS结合LFDBF和CISS对前景和背景区域进行分类,并对点云进行高效下采样;
邻域特征扩散模块(NFDM)进一步扩大前景块特征的扩散范围,减少下采样造成的信息损失;
IC-FPS可以插入到任何基于点的三维物体检测模型中,进行端到端训练;
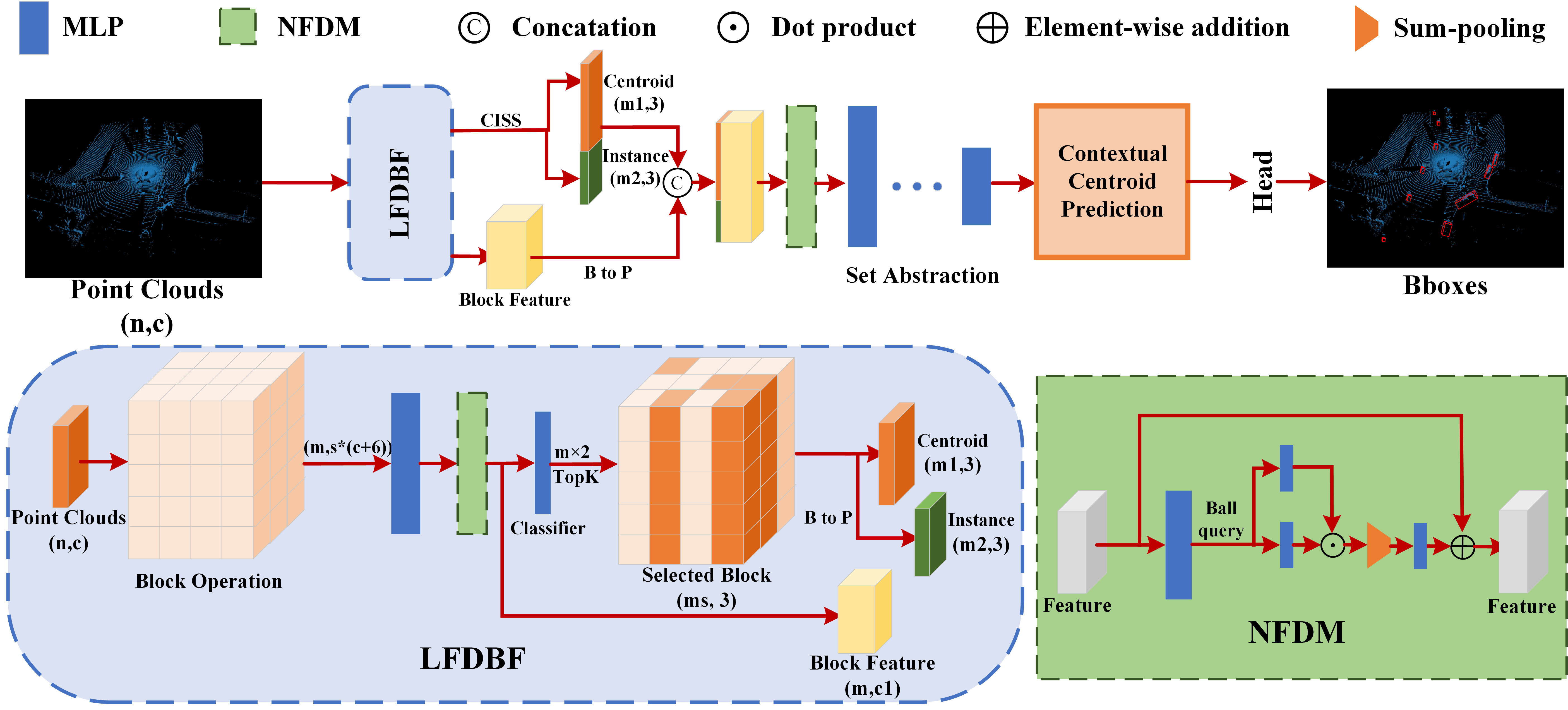
图2.IC-FPS框架框图。B到P表示块中的所有点都被选中。n、m、ms、m1、m2分别表示输入的点云个数、有效块个数、选中块个数、选中质心个数、选中实例个数。橙色的块被选为前景块。c和c1分别表示输入通道数和特征通道数。
LFDBF
此算法可以有效的去除背景点;
给定一组点P={pi|i=1,...,N} ∈RN×c;N表示点的数量和c表示通道数;如图2所示,我们将点P的集合划分为块,并推导出大小为[m, s, c]的矩阵,其中m为有效块的个数,s为块中的点个数;
为了高效提取每个块的局部特征,采用PointPillars方法获取块内的相对位置信息;
然后将矩阵大小折叠为[m, s, (c + 6)],其中额外的六个维度包括每个块中点到中心点的相对距离和质心位置;{∇x,∇y,∇z,xc,yc,zc}? 图2中的标注和原文不一致
有效的分类前景点和背景点需要每个块的邻居特征,而MLP仅提取每个块的特征;构造NFDM代替3D卷积,有效的提取块间的邻居信息;
NFDM采用多尺度球查询作为RANDLA-Net中KNN的替代,以提高处理速度;
如图3所示,在得到每个块的邻域范围后,将每个块的邻域特征扩散到邻域中的其他块;
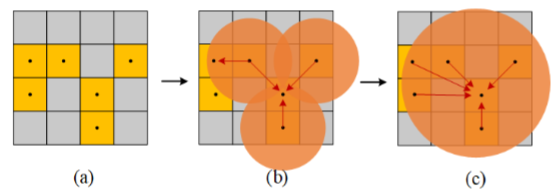
图3.邻域特征扩散模块图。(a)表示块特征,(b)表示第一个NFDM有效块的特征扩散范围,(c)表示第二个NFDM有效块的特征扩散范围。黄色区域为有效块,橙色区域为特征扩散范围。每个块使用球查询来获取其邻域,并将其特征扩散到邻域内其他有效块中。
使用NFDM后得到的特征来评估每个块。采用MLP作为分类网络计算块的置信度。置信度越高,该块就越有可能是“前景块”。
将置信度大于阈值α的块视为前景块,其特征表示为Fi∈R(ms×c1),其中c1为通道数,ms为前景块数。前景块中的所有点都定义为前景点。
为了更好地对点云中距离较远的稀疏前景区域进行采样,我们提出了一种基于正态分布的密度-距离焦损失LDDFL,以防止距离较远的实例被过滤掉。密度约束MDen根据块中的点密度分配不同的权重。
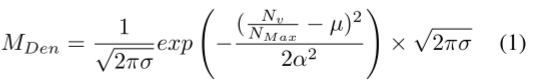
其中,µ、σ为正态分布的位置参数和尺度参数。Nv和Nmax分别表示block中的有效点数和最大值。距离约束MDis对远距离的对象赋更多的权值,表示为:
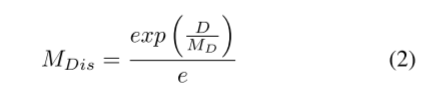
其中D为点到坐标系原点的距离,MD为最远点到原点的距离。密度-距离焦距损耗LDDFL表示为:
![]()
CISS
CISS的目标是高效采样中心点,并在第一层SA层中替代FPS。我们认为FPS的成功有两个原因:1️⃣FPS根据点密度自适应选择中心点,即在高密度区域中选择更多的中心点。2️⃣FPS从原始点云中采样样本并保留几何结构信息,有利于提高后续检测框回归的精度。
因此,我们将部分前景点添加到中心点中,以增加实例对象的样本密度。构造质心点偏移模块来恢复点云原始几何结构。
原始实例点采样:导出前景块后,计算块的质心位置,记为Di∈Rms×3。根据分类置信度从高到低对质心点进行排序,选择最高的m1点。此外,同时选择到原点距离最短的m2点。在后续模型中,将实例点和质心点作为第一SA层的中心点。算法1是CISS的详细程序。
块质心点偏移:将原始点云的位置信息逐层添加到之后的网络中,有利于适应原始点云结构。但质心与实际点云位置存在偏差。直接使用质心可能会丢失原始的位置信息,模型在回归过程中无法准确预测边界盒的大小。因此,我们提出了质心点偏移模块,将质心移动到最近的实例点,以有效地恢复目标的原始大小。质心点偏移损失函数LCB表示为:
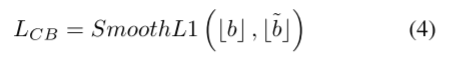
其中b是质心点到最近实例点之间的预测偏移量,˜b表示质心点到最近实例点的实际偏移量。⌊⌋表示centroid是否出现在实例框中。

质心特征扩散采样框架
在图2中,我们应用另一个NFDM来扩大每个中心点特征的扩散范围。通过叠加两个NFDMs,IC-FPS可以有效地减少由于降采样造成的信息损失,并取代复杂的第一个SA层。
总损失包括密度-距离焦距损失LDDFL、质心点偏移损失LCB、分类损失Lcls和包围盒生成损失Lbox,如式5所示。
![]()
实验
实施细节
我们选择3DSSD [30]/SASA [3]/IA-SSD[35]作为基线构建模型。首先对输入点云进行块划分。块大小设置为[0.075,0.075,1]。在LFDBF模块中,点云通过类似于PointPillars的方法进行扩展,然后输入到三个大小为(16,16,32)的MLP层。第一个NFDM的扩散半径设置为4.0,最大扩散点个数设置为16个。置信阈值设置为0.45。我们在DDFL中设µ= 0.5和σ = 0.5(方程3)。CISS中质心偏移模块包含两个MLP层,其大小为(16,3),对于第二个NFDM,扩散半径设为[0.2,0.8],最大扩散点数设为16。
我们在实验中配置了三个不同数量的IC-FPS模块,分别是IC-FPS- S /ICFPS-M/IC-FPS- L。采样的质心点和实例点的最大个数分别为16384/2048、26000/4096和30720/8197。
我们的实验采用了相同的训练策略和每个基线的模型结构,只是第一个SA层被IC-FPS取代。在IA-SSD实验中,batch size设置为8,学习率设置为0.01,使用Adam[8]优化器,weight decay设置为0.01。在3DSSD和SASA实验中,batch size设置为2,学习率设置为0.002。实验在NVIDIA A40 GPU和AMD EPYC 7402 CPU上进行。