在本章中,我们将学习Julia异步编程的基础知识,我们将了解:
- tasks
- channels
Tasks
创建任务
从技术上讲,Julia中的任务是symmetric co-routine(对称协同例程)。更通俗地说,task是一项计算工作,可以在将来的某个时刻开始安排,并且可以中断和恢复。要创建任务,我们首先需要创建一个函数来表示任务中要完成的工作。在以下代码中,我们生成一个任务,用于生成两个矩阵并对它们求和。

安排任务
任务已经创建,但是对应的工作尚未开始,我们没有看到函数的任何输出,要运行任务,我们需要进行schedule。

获取任务结果
任务已经执行了,但是看不到结果,为了获得结果,我们需要获取它。

任务异步运行
值得注意的是,任务是异步运行的,为了说明这一点,我们创建并安排一个新任务。

请注意,当任务运行的时候,我们可以执行Julia代码,比如上边的两行单元格。这是为什么呢?因为任务在后台运行,并且该特定任务的大部分时间都处于休眠。因此,在任务休眠的时候可以使用当前的Julia进程进行其他的操作。
任务不并行运行
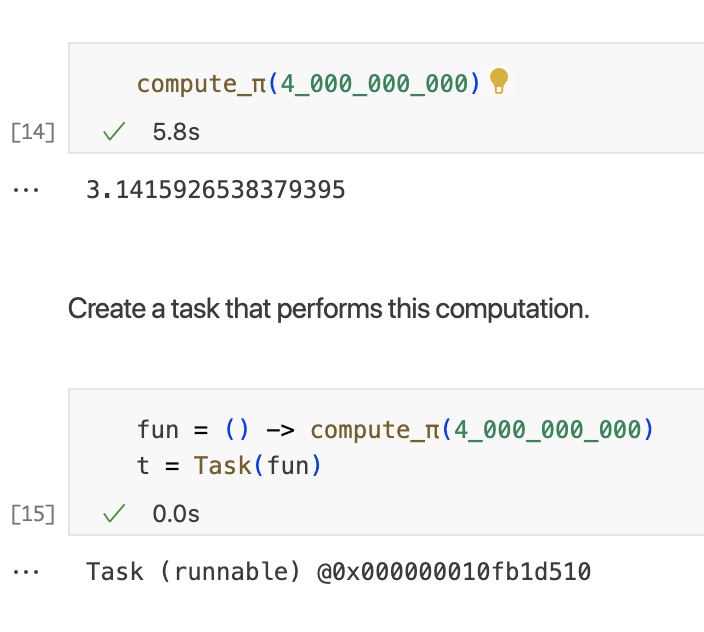
任务不是并行运行的,我们能够在之前的任务运行时运行代码,是因为该任务在睡眠函数中大部分时间都处于空闲状态。如果任务执行实际工作,当前进程将忙于该任务并阻止运行其他任务。让我们举一个具体的例子。以下代码计算近似值pi,使用莱布尼兹公式。近似的质量随着n的增加而提高。

用一个大数调用这个函数,这需要一些时间。
然后创建执行此计算的任务。
安排任务,然后尝试执行下面的第二个单元格,请注意,当前进程将忙于运行该任务。

yield
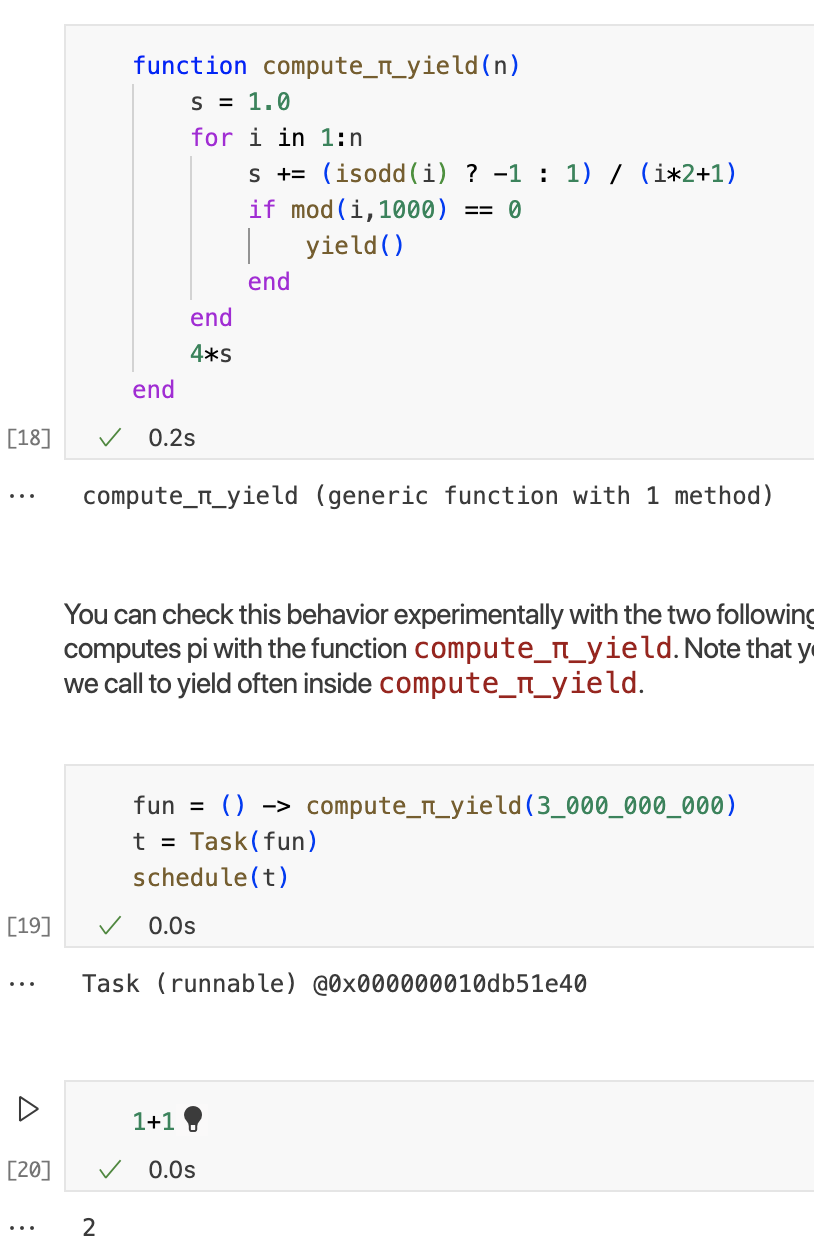
如果任务不并行运行,那么任务的目的是什么?任务很方便,因为他们可以被中断并将控制权切换到其他任务。这是通过yield函数实现的。当我们调用yield时,我们提供了切换到另一个任务的机会。下面函数是上边函数的变体,其中我们每1000次迭代都会产生一次。在调用yield时,我们允许其他任务接管。如果没有对yield的调用,一旦我们启动函数,compute_pi,我们就无法启动任何其他的任务,直到该函数完成为止。
我们可以通过以下代码来检查此行为。在创建并安排一个使用函数计算pi的任务时,我们可以在该任务运行时运行下边的代码,因为我们经常在内部调用yield。
示例:实现sleep函数
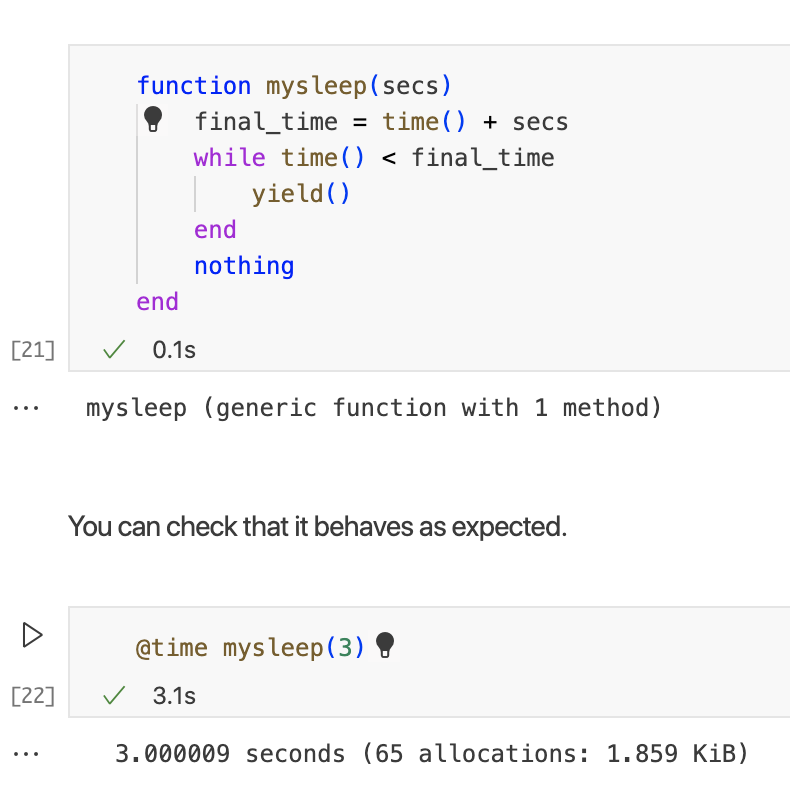
使用yield,我们可以实现自己的sleep函数:

task采用不带参数的函数
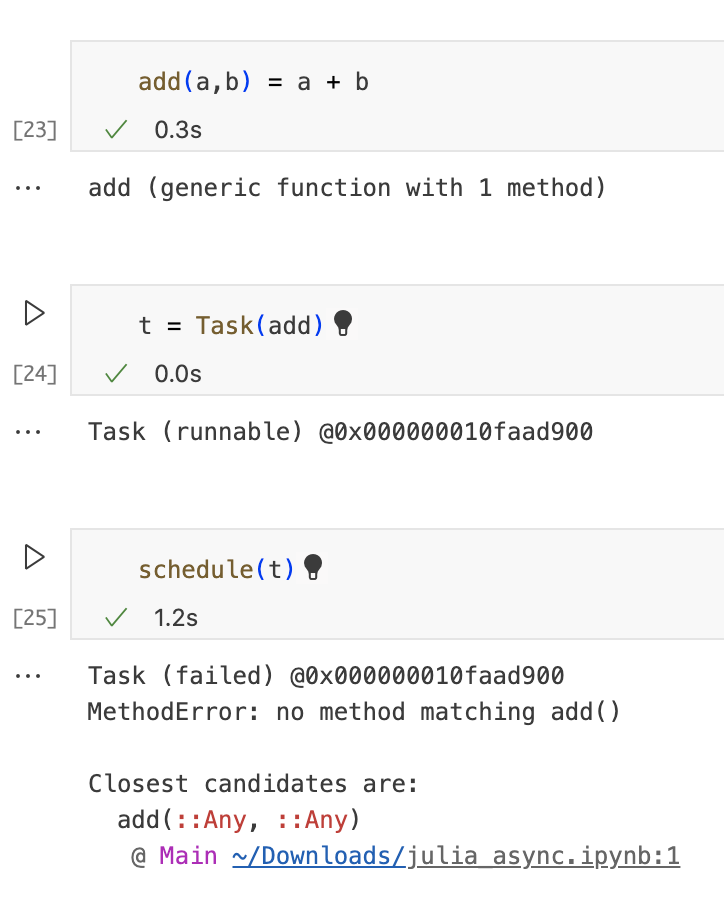
函数需要有0个参数,但是如果需要它可以捕获变量。如果我们尝试使用带有参数的函数创建任务,那么安排它时将会导致错误。
如果需要,我们可以捕获任务运行的函数中的变量,如下面的单元格所示:

有用的宏:@async
到目前为止,我们已经使用低级函数创建了任务,但是还有更方便的方法来创建和调度任务。例如使用@async宏,该宏是用于异步运行一段代码。在幕后,它将代码放入匿名函数中,创建任务并安排它。以下这个单元格和之前的单元格是等价的。
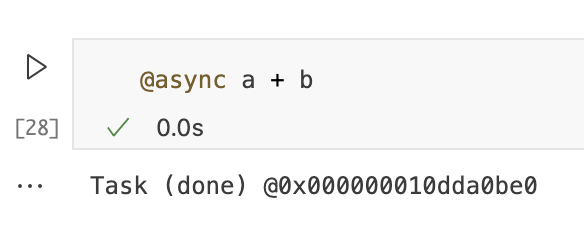
另一个有用的宏:@sync

这个宏用于等待给给定代码块中所有@async创建的任务。
Channels
在任务之间发送数据
Julia提供channels作为在task之间发送数据的方式,channel就像一个FIFP队列,任务可以将值放入其中并从中取出值。在下一个示例中,我们创建一个channel和一个将5个值放入该channel的任务。最后,task关闭通道。

多次执行最后一行代码,我们将从channel中获取值。我们确实在传递来自两个不同task的数值。如果我们执行该单元超过5次,则会引发错误,因为通道已经关闭。
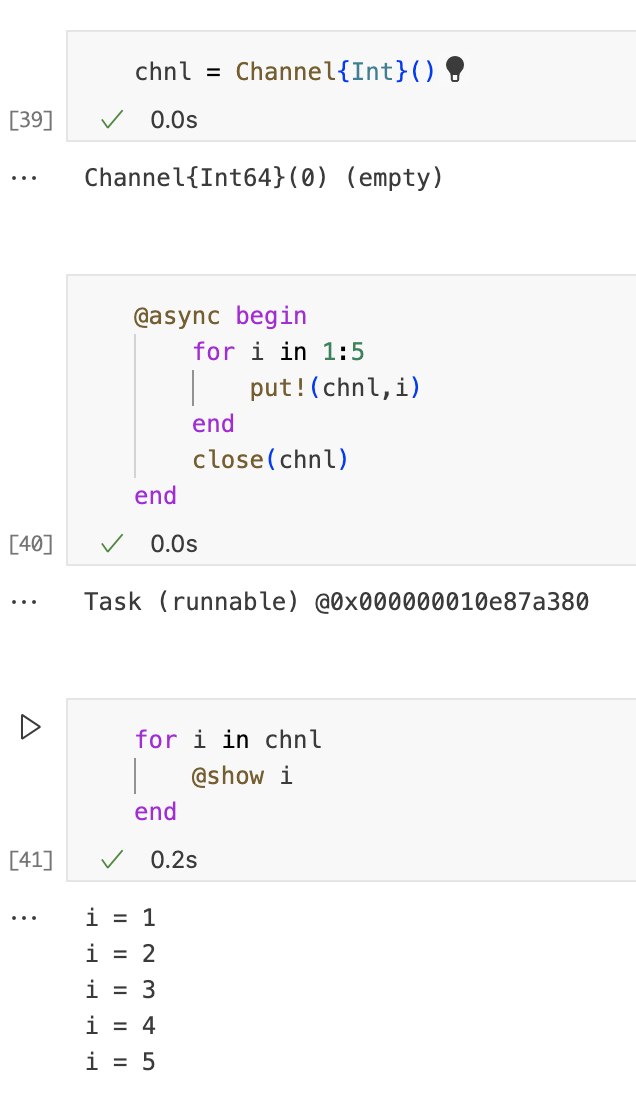
通道是可迭代的,我们可以在for循环中迭代通道,直到关闭通道,而不是从通道中获取值直到发生错误。
Calls to put! and take! are blocking
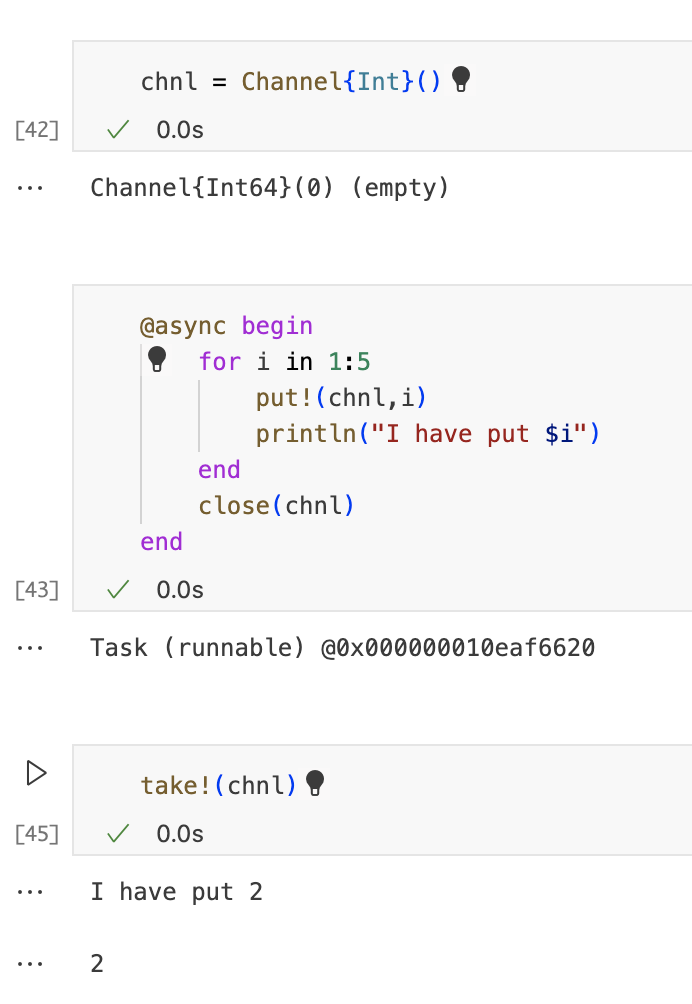
put!和take!是阻塞操作,调用put!会阻塞任务,直到另一个任务调用take!为止,反之亦然。因此,我们需要至少两个任务才能实现此目的。如果我们从同一个任务调用put!和take!,就会导致死锁。我们在前面的示例中添加了一条打印语句。再次运行它并注意如何put!阻塞,直到我们调用take!
Buffered channels
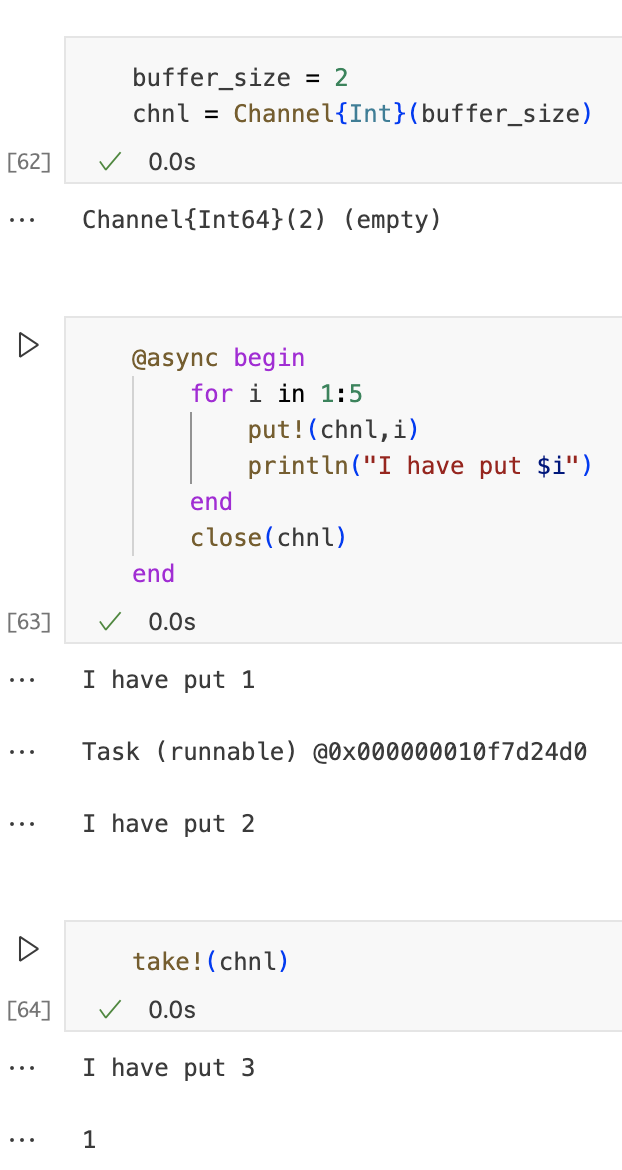
我们可以更灵活一点,使用buffered channel,在这种情况下,put!仅当通道已满时才会阻塞,take!如果通道为空则阻塞。我们重复前面的示例,但是使用大小为2的缓冲通道。请注意,我们可以调用put!直到通道已满。此时,我们需要等待,直到调用take!从通道中删除一个项目,为新项目腾出空间。
Questions
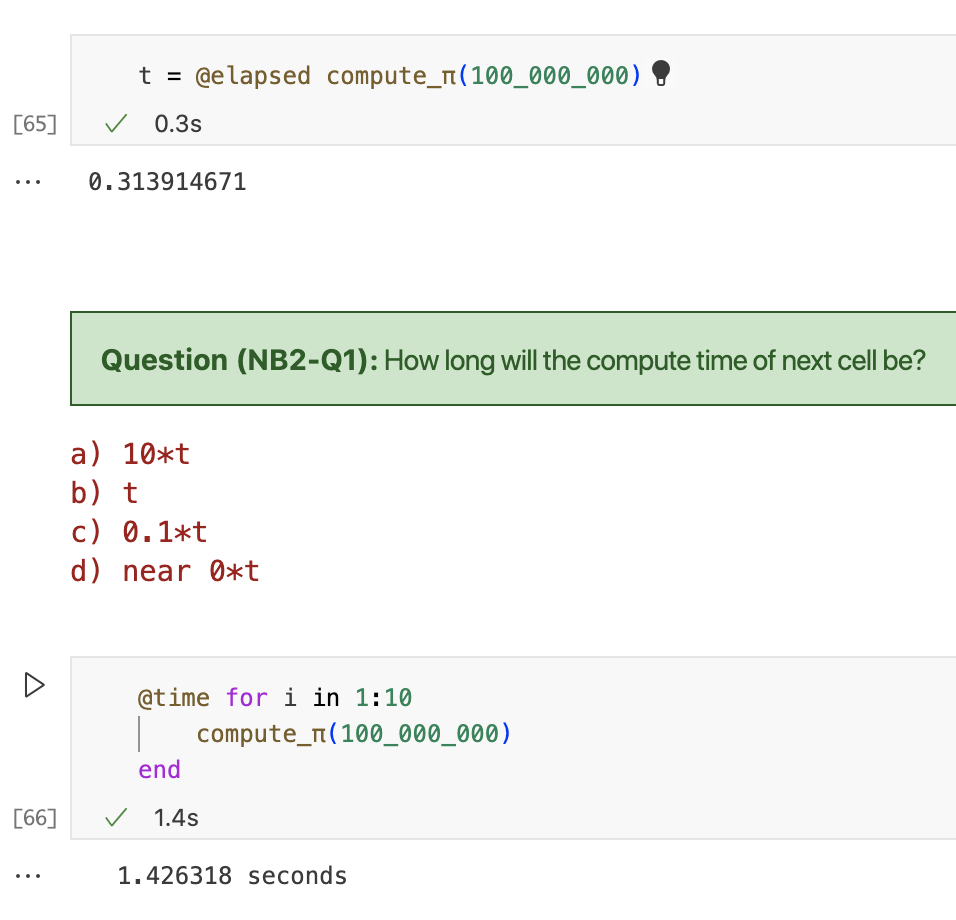
循环大约需要花费十倍的时间,因为运行了十次函数,所以选a。

Q2:The time in doing the loop will be almost zero since the loop just schedules 10 tasks, which should be very fast.
Q3:It will take 2.5 seconds, like in question 1. The @sync macro forces to wait for all tasks we have generated with the @async macro. Since we have created 10 tasks and each of them takes about 0.25 seconds, the total time will be about 2.5 seconds.
@async 宏用于启动异步任务,这意味着它将代码放入一个独立的任务中,不会等待该任务完成,而是会立即继续执行后续的代码。所以,如果你执行 @async a + b,它会非常快速地返回,不会等待 a + b 运行完。
@sync 宏用于等待异步任务的完成,确保在继续执行后续代码之前,所有被标记为异步的任务都已经完成。这是为了确保你的代码在需要异步任务的结果时不会过早地继续执行。
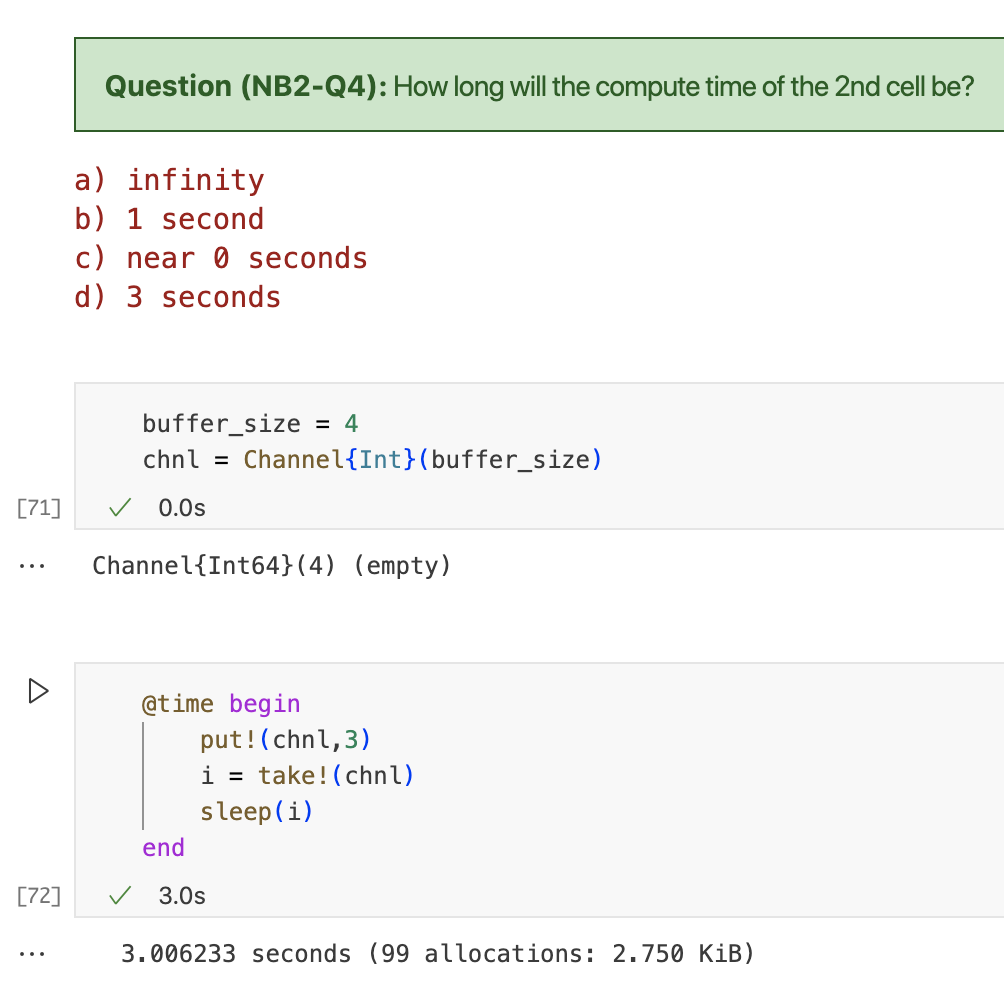
Q4:It will take about 3 seconds. The channel has buffer size 4, thus the call to put!will not block. The call to take! will not block neither since there is a value stored in the channel. The taken value is 3 and therefore we will wait for 3 seconds.
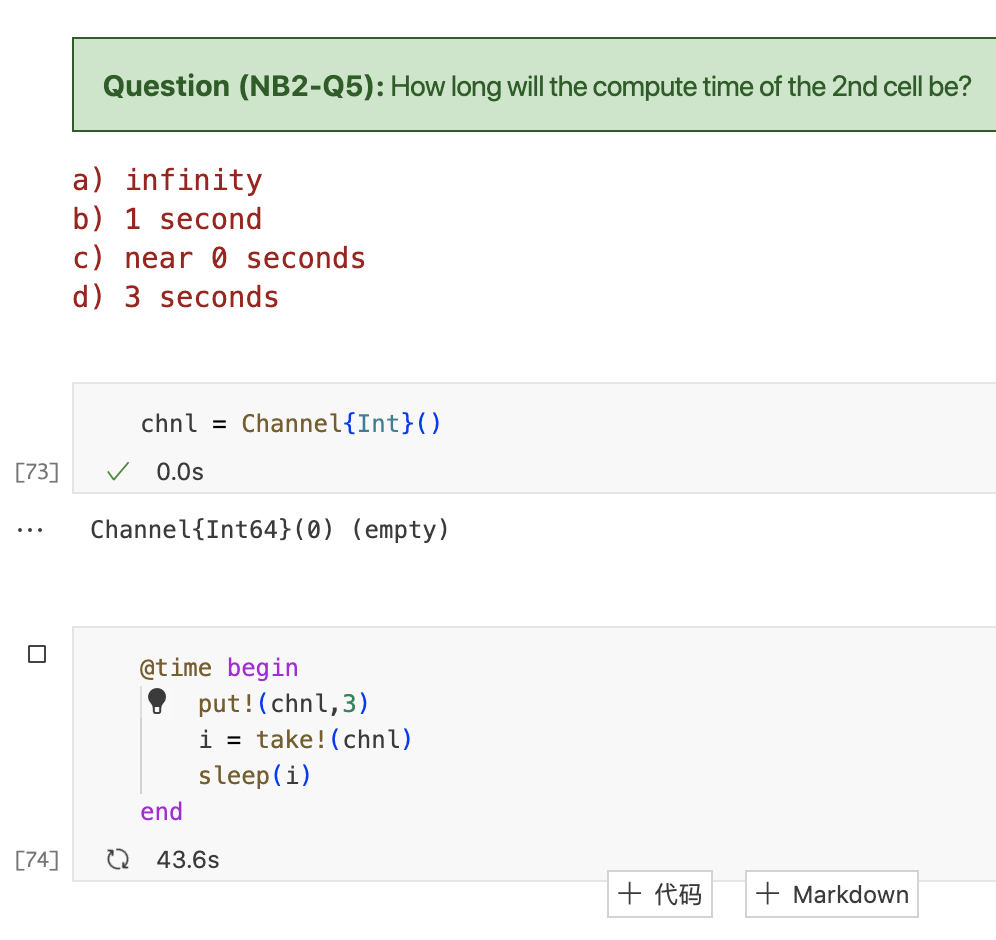
Q5:The channel is not buffered and therefore the call to put! will block. The cell will run forever, since there is no other task that calls take! on this channel.