Adversarial Attack(对手的攻击)
- 把训练好的神经网络用在应用上,还需要让其输入人为的恶意行为,要在有人试图欺骗他的情况下得到高的正确率
例如:影像辨识,输入的图片加入一些杂讯(这些杂讯可能肉眼看不出来),使得输出错误,并输入某个指定的错误输出


- 无目标攻击:使输出结果与正确答案的差距越大越好即可,当原图片和攻击图片的差距小于ε时,人就无法分辨
- 目标攻击:输出结果与正确答案的差距越小越好,并且与目标输出越近越好
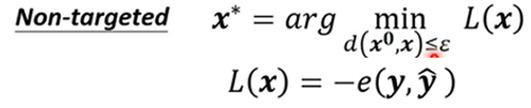


- 把输入图片的参数当成参数,用梯度下降法调输入图片的参数,若超出ε,则设置为ε范围内最近的点


- FGSM(快速梯度符号法):L对xi求出的导数不直接用,而是只取正负符号为g,只对参数做一次修改,得到的结果也必定在四个角上
Black Box Attack(黑箱攻击):
- 不知道模型的参数,去攻击这个模型
1、根据模型的训练资料训练出一个自己的类似模型,攻击自己模型成功的资料可能也能攻击成功目标模型

2、若没有目标的训练资料,可以用一些自己的资料,输入目标模型,得出结果与输入成对去训练自己的模型,攻击自己的模型成功的资料,可能也能攻击成功目标模型
Defence(防卫)
被动防御:
1.在模型前加一个盾牌,用于消减杂讯的威力,例如给输入的图片加入一些模糊

2.基础Generator的方法,让Generator产生一张和输入图片一样的图片,当攻击材料中有一些较小的杂讯,Generator重新画出的图片可能忽略了这些杂讯
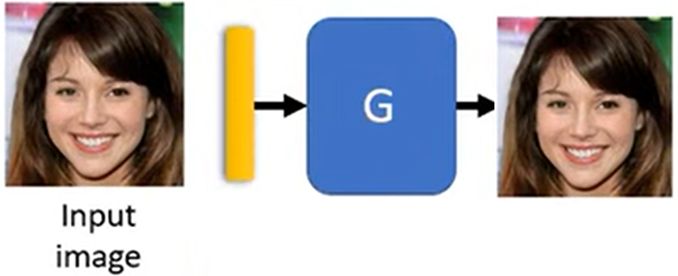
若攻击者知道被动防御的方法,也可以把Generator加入产生攻击材料的一部分继续攻击
3.加上随机性,才可以有效防御,例如,随机把输入的照片放大、缩小或旋转,再随机的贴在灰色背景的某个位置

主动防御:
Adversarial Training(对抗训练):训练阶段就对模型进行攻击,把训练资料拿出来做成攻击材料,攻击成功的重新标注作为训练材料,进行训练(相当于不断找模型的漏洞,再不断完善的过程)
