the Stochastic Gradient Descent (SGD):为了提高鲁棒性,SGAIN框架的优化器采用了随机梯度下降(SGD)
一,SGAIN框架有两个重要目的:鉴别器D的目的是最大化正确预测M矩阵的概率;生成器的目的是最小化D预测M矩阵的概率。此外,利用反向传播算法对发生器和鉴别器进行了优化。具体而言,损失介于测量数据的非缺失部分(X⌢)和生成器生成的推算数据的非缺失部分(X)之间。为了提高拼接效率和精度,利用目标函数(7)和(8)对鉴别器和生成器进行了优化。
为了全面评价所提模型的性能,提出了相关系数(R2)、均方根误差(RMSE)和平均绝对误差(MAE)作为时间域中可用的定量性能指标。另外,为了评价模型的预测精度和稳健性,分别引入了预测精度和平均负对数似然(MNLL)。同时,好的模型应具有高的R2值、低的RSME值、低的MAE值、高的精度指数和高的MNLL值。这些绩效指标可以表示为:Yi表示第i个位置的测量值,y‘i表示第i个位置的归属值,σi2表示归属值的方差,y-表示归属值的平均值。
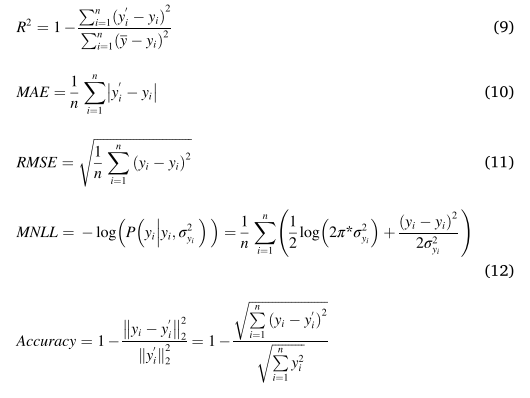
二,该数据补偿方法的实施过程。
Dataset description:本文主要有三种缺失数据填补场景,即不考虑时空相关性的单传感器随机损失(一对一)为第一类,考虑时空相关性(多对一)为第二类的单传感器随机损失,以及考虑时空相关性(多对一)的单传感器连续损失(多对一)为第三类。
Effect of the dataset correlation在以下条件下,皮尔逊相关系数Pearson correlation coefficient (PCC)可以用来衡量数据之间的线性相关程度:(1)两个数据是线性相关的,并且都是连续的;(2)数据服从高斯分布;(3)两个数据是相互独立的。从中心极限定理可知,当数据数目足够多时,数据分布的极限是高斯分布(正态分布)。本文考虑同一主梁上的传感器信号,对桥梁的挠度进行了估算。如图9所示,该桥的挠度数据基本上满足线性关系和高斯分布,因此本文采用皮尔逊系数。对于某些复杂情况下可能发生的其他非线性、非高斯分布数据情况,则考虑Kendall相关系数或Spearman相关系数。
Single-sensor imputation (one-to-one):线性插值法使用一条连接两个已知量的直线来确定两个已知量之间的未知量的值。这种方法比较简单,不能完全提取数据信息来提高插补精度。
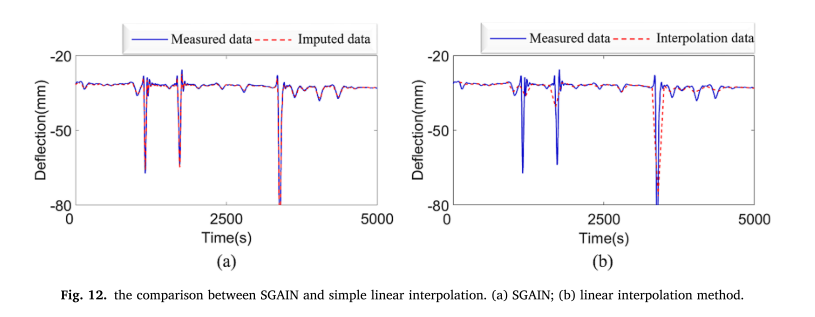
Single-channel random imputation (many-to-one):通道6(N6)被设置为故障传感器,并且主跨度中的通道1、2、3、4、5、7、8被设置为增益输入。从图13可以看出,所提出的框架主要针对具有不同缺失率(例如,10%到90%)的1天随机缺失挠度数据来研究该框架的补偿效果。灰色区域显示了推算结果与真实结果的对比结果。图13中突出的是,sGain保持了良好的补偿性能,特别是在高数据丢失率(例如,90%)的情况下。然而,如图13(E)所示,16小时的微小误差是由于高丢失比例和消失的梯度所致。
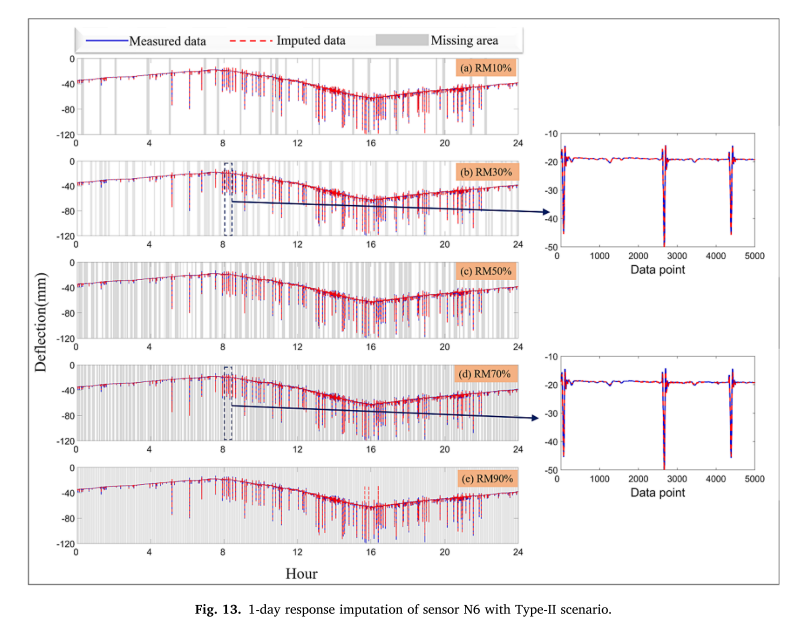
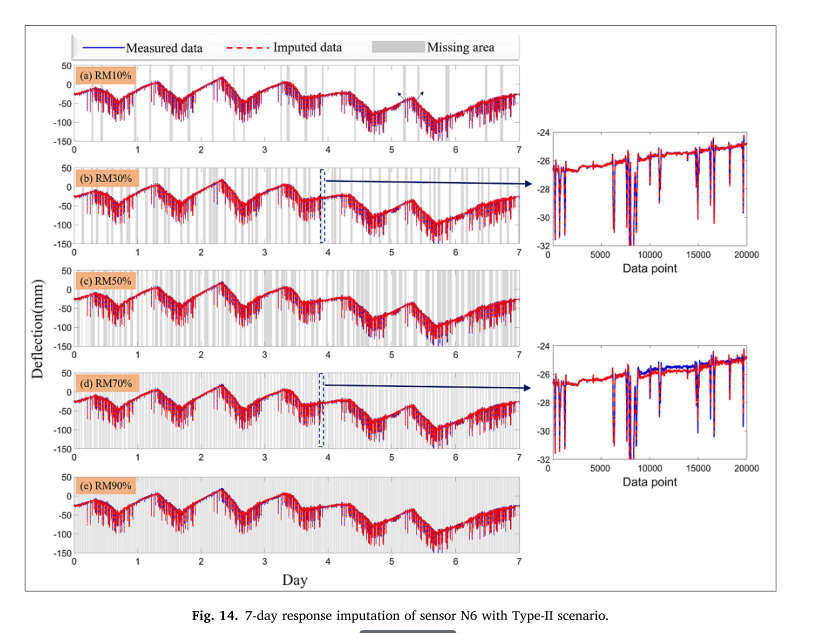
fig.14 即使缺失率高达90%,SAGIN框架的归责效应也提供了突出的结果。这是因为该方法能够提取出故障传感器的非缺失部分,同时吸收了其他传感器的时空相关性,提高了sain归结的学习能力
Continuous missing data imputation (many to one):应用均方根误差或精度来全面反映模型在不同缺失率下的预测能力.实测值与预测值在线性回归中具有较高的拟合度,且预测值与实测值之间的相关性均匀分布在线性回归曲线的两侧区域。此外,基于学习的潜在特征的准确估计和预测结果表明,该方法处理不完整的SHM记录具有令人满意的性能,具有更好的量化能力
主要结论如下:1.在三层相关情景下,SAGIN模型具有显著的补偿效果。在长期的监测数据中,传感器之间具有各种相关性的混合数据集是常见的。由于混合特征的真实性信息有限,混合相关数据集(Level-III)的归属结果不如较好的相关数据集(Level-I和Level-II)准确。2.该方法具有较强的泛化能力,在连续、随机缺失类型和高缺失率的情况下具有最好的性能。随机遗漏和连续遗漏在不同区间内的补差累积速度最快。3.在漏失率不同的三种场景下,本文提出的增益模型的性能均优于传统的增益模型。在这三种场景下,sGain模型的执行时间均优于Gain模型,改善幅度在10%~20%之间;在三种场景下,sain模型的执行时间均优于SVR,改善幅度在20%~30%之间。这种改进具有显著的效率和准确的结果,特别是在数据缺失率较高的情况下。人们相信,当转移到其他有价值的场景时,sain也可以具有良好的归责能力。需要进一步研究多传感器同时丢失的数据,并利用深度学习技术改善响应估计中的模式崩溃和模式下降问题。
- adversarial imputation generative monitoring structuraladversarial imputation generative monitoring self-supervised interpretable adversarial generative adversarial generative network网络 adversarial generative论文nets imputation 水稻imputation面板panel adversarial adversary contrastive-adversarial class-imbalanced unsupervised adversarial adaptation