Bottleneck Transformers for Visual Recognition
* Authors: [[Aravind Srinivas]], [[Tsung-Yi Lin]], [[Niki Parmar]], [[Jonathon Shlens]], [[Pieter Abbeel]], [[Ashish Vaswani]]
初读印象
comment:: (BoTNet)通过在ResNet的最后三个瓶颈块中使用全局自注意力替换空间卷积,并且没有其他变化,在实例分割和目标检测方面显著改善了基线,同时也减少了参数,在延迟方面的开销最小。
动机
卷积操作虽然可以有效地捕捉局部信息,但是需要堆叠多层才能实现全局聚合,而自注意力可以直接计算任意两个位置之间的交互,从而学习更丰富的关联特征。文章旨在提出一种简单而强大的混合架构,即BoTNet,来利用卷积和自注意力的优势。
方法
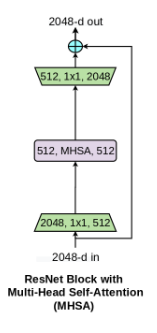
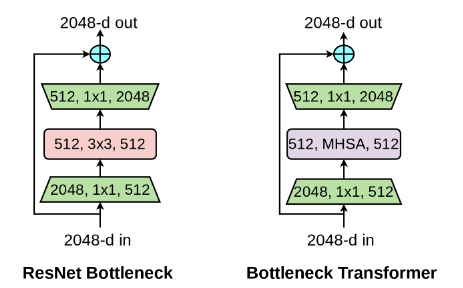
将最后三层的3×3卷积换成多头子注意力。
BoTNet是一种同时使用卷积和自注意力的混合模型。
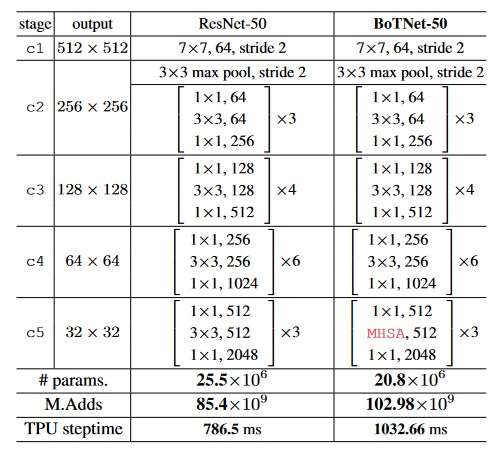
BoTNet-50 ( BoT50 )的架构:BoT50与ResNet - 50 ( R50 )的唯一区别是在c5中使用了MHSA层(图4 )。对于1024 × 1024的输入分辨率,c5第1块的MHSA层工作在64 × 64上,其余两块工作在32 × 32上。我们还报告了参数、乘法加法( m . add )和训练时间吞吐量( v3-8 Cloud - TPU上的TPU - v3步时)。Bot50仅比R50多1.2倍M . Adds。整个训练过程的开销为1.3 x。BoT50也比R50少1.2倍。
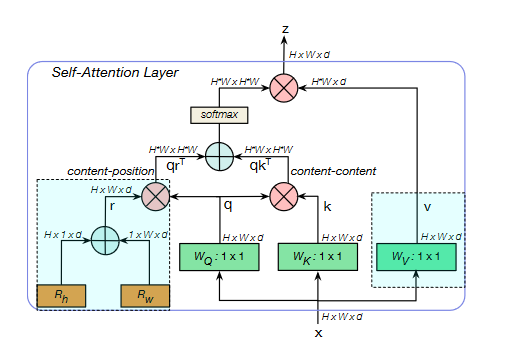
在BoT块中使用的多头自注意力( MHSA )层。虽然我们使用了4个头,但为了简单起见,我们没有将它们显示在图上。all2all注意力都是在一个2D特征图上进行的,其相对位置分裂,分别为高度和宽度编码Rh和Rw。注意力logit为qkT + qrT,其中q,k,r分别表示查询、密钥和位置编码(我们使用相对距离编码),⊕和∂分别表示元素和和矩阵乘法,1 × 1表示逐点卷积。除了使用多个表头外,突出显示的蓝色方框(位置编码和值投影是非本地层中没有的三个元素。
- Transformers Recognition Bottleneck Visual fortransformers recognition bottleneck visual image transformers recognition 16x image transformers recognition笔记 bottleneck recognition face_recognition zynq_target-recognition recognition-vgg length-insensitive insensitive recognition decoding zynq_target-recognition recognition complete