Recognition
Hierarchical Clustering-based Personalized Federated Learning for Robust and Fair Human Activity Recognition-2023
任务:人类活动识别任务Human Activity Recognition HAR 指标:系统准确性、公平性、鲁棒性、可扩展性 方法:1. 提出一个带有层次聚类(针对鲁棒性和公平的HAR)个性化的FL框架FedCHAR;通过聚类(利用用户之间的内在相似关系)提高模型性能的准确性、公平性、鲁棒性。 2 ......
Deep Residual Learning for Image Recognition:ResNet
Deep Residual Learning for Image Recognition * Authors: [[Kaiming He]], [[Xiangyu Zhang]], [[Shaoqing Ren]], [[Jian Sun]] DOI: 10.1109/CVPR.2016.90 初读 ......
Local Relation Networks for Image Recognition: LRNet
Local Relation Networks for Image Recognition * Authors: [[Han Hu]], [[Zheng Zhang]], [[Zhenda Xie]], [[Stephen Lin]] DOI: 10.1109/ICCV.2019.00356 @in ......
Bottleneck Transformers for Visual Recognition
Bottleneck Transformers for Visual Recognition * Authors: [[Aravind Srinivas]], [[Tsung-Yi Lin]], [[Niki Parmar]], [[Jonathon Shlens]], [[Pieter Abbee ......
Conv2Former: A Simple Transformer-Style ConvNet for Visual Recognition:使用大核卷积调制来简化注意力
Conv2Former: A Simple Transformer-Style ConvNet for Visual Recognition * Authors: [[Qibin Hou]], [[Cheng-Ze Lu]], [[Ming-Ming Cheng]], [[Jiashi Feng]] ......
【论文阅读笔记】【OCR-文本识别】 SEED: Semantics Enhanced Encoder-Decoder Framework for Scene Text Recognition
SEED CVPR 2020 读论文思考的问题 论文试图解决什么问题?写作背景是什么? 问题: 如何利用全局的语义信息提高文本识别模型对低质量文本的鲁棒性和识别效果? 背景: 以往的基于 encoder-decoder 的文本识别方法通常基于局部的视觉特征解码出文本,忽略了对单词显式的全局语义信息的 ......
Exercise 2 - Handwriting Recognition
Exercise 2 - Handwriting Recognition 在课程中,您学习了如何使用Fashion MNIST 进行分类,这是一个包含服装项目的数据集。还有一个类似的数据集叫做 MNIST,其中包含手写项目--数字 0 到 9。 编写一个 MNIST 分类器,训练达到 99% 或以上 ......
【论文阅读笔记】【OCR-文本识别】 LISTER: Neighbor Decoding for Length-Insensitive Scene Text Recognition
LISTER ICCV 2023 读论文思考的问题 论文试图解决什么问题? 由于长尾效应和错误累积等原因,现有的文本识别模型对于长文本的识别能力较差 如何提高模型对于长度较长的文本的识别能力? 文章提出了什么样的解决方法? 提出了 LISTER 模型,引入了 neighbor matrix 的概念, ......
ZYNQ_Target-Recognition Project complete
ZYNQ_Target-Recognition 描述:实现了一个卷积神经网络加速器,成功搭载Yolov3tiny。配合摄像头采集+显示器回显环路,构建了一个高性能实时目标识别与检测系统。 实现方式: Verilog实现卷积加速器的设计, C语言实现Zynq PS端的开发, Python实现神经网络的 ......
【论文阅读笔记】【OCR-文本识别】 CLIPTER: Looking at the Bigger Picture in Scene Text Recognition
CLIPTER ICCV 2023 读论文思考的问题 论文试图解决什么问题? 现有的文本识别方法只关注于局部截取的文本区域,识别模型并没有利用全图的上下文信息,导致其可能对有挑战性的文本的识别效果较差 能否以某种方式使识别器利用上global feature的信息? 文章提出了什么样的解决方法? 提 ......
【论文阅读笔记】【OCR-文本识别】 Scene Text Recognition with Permuted Autoregressive Sequence Models
PARSeq ECCV 2022 读论文思考的问题 论文试图解决什么问题? 一些文本识别模型会对 semantic 信息建模,从而辅助某些困难情况下的文本识别 传统的 auto-regressive 方式限制了语义信息的传输方向;双向的 auto-regressive 聚合增加了不必要的计算量和复杂 ......
《AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》阅读笔记
论文标题 《AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》 谷歌论文起名越来越写意了,“一幅图像值16X16个单词” 是什么玩意儿。 AT SCALE:说明适合大规模的图片识别,也许小规模的不好使 ......
《Deep Residual Learning for Image Recognition》阅读笔记
论文标题 《Deep Residual Learning for Image Recognition》 撑起CV界半边天的论文 Residual :主要思想,残差。 作者 何恺明,超级大佬。微软亚研院属实是人才辈出的地方。 初读 摘要 提问题: 更深层次的神经网络更难训练。 提方案: 提出了残差网络 ......
论文阅读(四)—— Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition
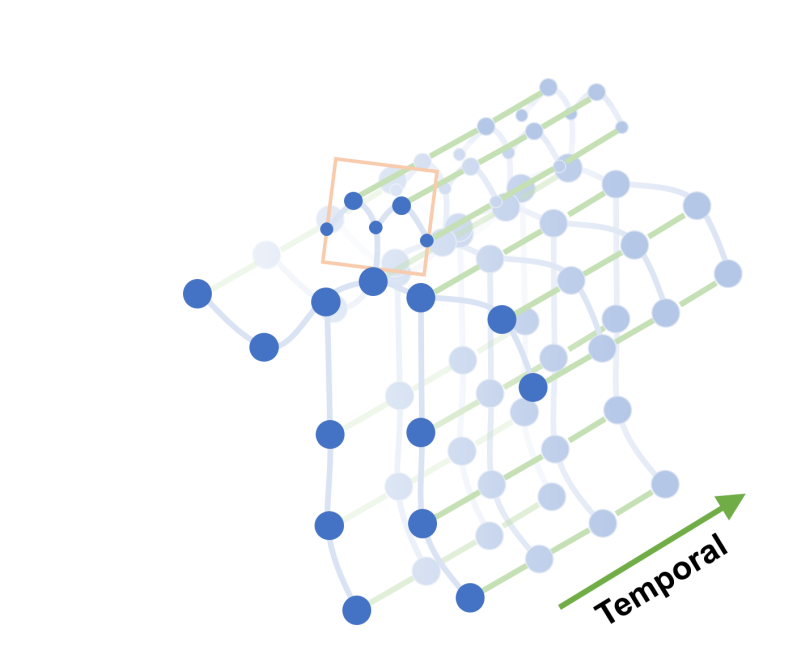 ——Channel-wise Topology Refinement Graph Convolution for Skeleton-Based Action Recognition
代码 实验 python main.py --config config/nturgbd-cross-subject/default.yaml --work-dir work_dir/ntu/csub/ctrgcn --device 0 --num-worker 0 综述 ......
【PRC】鲁棒跨域伪标记和对比学习的无监督域自适应NIR-VIS人脸识别 Robust Cross-Domain Pseudo-Labeling and Contrastive Learning for Unsupervised Domain Adaptation NIR-VIS Face Recognition
【该文章为杨学长的文章,膜拜】 探索跨领域数据中的内在关系并学习领域不变表示 由于需要在低光照条件下实现24h的人脸识别,近红外加可见光的(NIR-VIS)人脸识别受到了更多的关注。但是数据标注是一个难点。该文章提出了Robust crossdomain Pseudo-labeling and Co ......
论文精读:用于少样本图像识别的语义提示(Semantic Prompt for Few-Shot Image Recognition)
原文连接:Semantic Prompt for Few-Shot Image Recognition Abstract 在小样本学习中(Few-shot Learning, FSL)中,有通过利用额外的语义信息,如类名的文本Embedding,通过将语义原型与视觉原型相结合来解决样本稀少的问题。但 ......
机器学习经典教材《模式识别与机器学习》,Pattern Recognition and Machine Learning,PRML官方开放免费下载
微软剑桥研究院实验室主任Christopher Bishop的经典著作《模式识别与机器学习》,Pattern Recognition and Machine Learning,简称PRML,被微软“开源”了。 本书介绍&下载页:(书的介绍页面) https://www.microsoft.com/e ......
利用不可识别的人脸来增强人脸识别性能Harnessing Unrecognizable Faces for Improving Face Recognition
灰色标记:可以日后引用的观点 红色标记:好的写法、语句、单词 紫色标记:文章重点 黄色标记:寻常突出 文章评论:: 创新点:: 主要内容:: gallery中的样本通常是人为采集并精心挑选的,它们具有较好的可识别性;然而,query通常来自于真实场景,它们受多种因素干扰如像素等等。 针对“检测器能检 ......
LHY2022-HW02-Speech Recognition
# 1. 实验结果纪录 纪录一下调整参数带来的结果.不过语音识别这块完全不熟. # 1.1 Simple Baseline * **acc>0.45797** 直接上传助教代码 ,其中(H,W)是图像的原始分辨率,C是通道数,(P,P)是每个图像块的分辨率,N=H×W/P2为图像块的数量,将一个图像块使用可学习的线性层映射到维度为D的隐藏向量,如式(1)所示,线性映射的输出称为patch embeddin ......
Adaptive ship-radiated noise recognition with learnable fine-grained wavelet transform
摘要 分析海洋声环境是一项棘手的任务。背景噪声和可变信道传输环境使舰船辐射噪声的准确识别变得复杂。现有的识别系统在处理多变的水下环境方面能力较弱,在实际应用中表现不佳。为了保持识别系统在各种水下环境下的鲁棒性,本文提出了一种自适应广义识别系统——AGNet (adaptive generalized ......
论文解读(CosFace)《CosFace: Large Margin Cosine Loss for Deep Face Recognition》
论文信息 论文标题:CosFace: Large Margin Cosine Loss for Deep Face Recognition论文作者:H. Wang, Yitong Wang, Zheng Zhou, Xing Ji, Zhifeng Li, Dihong Gong, Jin Zhou ......
python的人脸识别库face_recognition
代码: import cv2 import numpy as np import face_recognition img_train = face_recognition.load_image_file('query/1679370481783.jpg') img_train = cv2.cvtC ......
迁移学习(SOT)《Cross-domain Activity Recognition via Substructural Optimal Transport》
论文信息 论文标题:Cross-domain Activity Recognition via Substructural Optimal Transport论文作者:Wang Lu, Yiqiang Chen, Jindong Wang, Xin Qin论文来源:Neurocomputing论文地 ......