Conv2Former: A Simple Transformer-Style ConvNet for Visual Recognition
* Authors: [[Qibin Hou]], [[Cheng-Ze Lu]], [[Ming-Ming Cheng]], [[Jiashi Feng]]
初读印象
comment:: 研究一种更有效的利用卷积编码空间特征的方法,利用卷积调制来简化自注意力操作。
动机
最近,一项名为ConvNeXt的有趣工作表明,通过简单地对标准ResNet进行现代化改造,并使用与Transformers相似的设计和训练配方,卷积神经网络的性能甚至优于一些流行的ViTs。Rep LKNet也展示了利用大核卷积进行视觉识别的潜力。这些探索促使许多研究者通过利用大核卷积,或高阶空间交互,或稀疏卷积核等重新思考卷积神经网络的设计。到目前为止,如何更高效地利用卷积来构建强大的ConvNet架构仍然是一个热门的研究课题。
比较了ViTs和卷积神经网络编码空间信息的不同方式。如下图左图所示,自注意力通过对所有其他位置的加权求和计算每个像素的输出。这个过程也可以通过计算大核卷积的输出和值表示之间的Hadamard积来模拟,本文称之为卷积调制,如下图右图所示。不同的是,卷积核是静态的,而自注意力产生的注意力矩阵可以适应输入。实验表明,使用卷积生成权重矩阵也能产生很好的效果。
 简单地将ViTs中的自注意力替换为所提出的卷积调制操作,得到所提出的网络Conv2Former。其背后的含义是,本文旨在使用卷积来构建Transformer风格的ConvNet,其中卷积特征被用作权重来调节值表示。与经典的自注意力ViTs相比,该方法与许多经典的卷积神经网络一样,是全卷积的,因此它的计算量随着图像分辨率的提高而线性增加,而不是像Transformers中的计算量的平方增加。这使得该方法对稠密预测的任务更加友好。
简单地将ViTs中的自注意力替换为所提出的卷积调制操作,得到所提出的网络Conv2Former。其背后的含义是,本文旨在使用卷积来构建Transformer风格的ConvNet,其中卷积特征被用作权重来调节值表示。与经典的自注意力ViTs相比,该方法与许多经典的卷积神经网络一样,是全卷积的,因此它的计算量随着图像分辨率的提高而线性增加,而不是像Transformers中的计算量的平方增加。这使得该方法对稠密预测的任务更加友好。
方法
整体架构
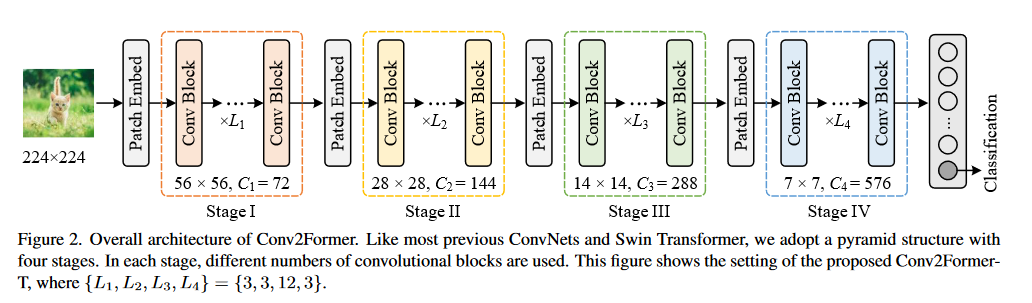
采用和swin transformer相同的架构。
在每个连续的阶段之间,使用一个补丁嵌入块来降低分辨率,它通常是一个2 × 2的卷积,步长为2。
卷积调制
使用一个深度可分离卷积对输入X进行调制,得到的A和V进行点积。
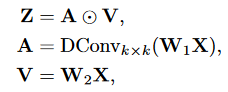 上述卷积调制操作使得每个空间位置(h , w)与以( h , w)为中心的k × k正方形区域内的所有像素相关。
上述卷积调制操作使得每个空间位置(h , w)与以( h , w)为中心的k × k正方形区域内的所有像素相关。

与自注意力相比,该方法利用卷积来建立关系,特别是在处理高分辨率图像时,比自注意力更有存储高效。与经典的残差块相比,由于采用了调制操作,该方法也能适应输入内容。
Micro Design
- 使用11×11的大核卷积 。
- 在点积前既不使用激活也不使用归一化层。
- 使用layer normalization和GELU
- 卷积 Transformer-Style Conv2Former Recognition Transformer卷积transformer-style conv2former recognition transformer-style 卷积 巅峰transformer模型 conv2former recognition face_recognition zynq_target-recognition recognition-vgg length-insensitive insensitive recognition decoding zynq_target-recognition recognition complete