1.介绍
1.1背景
2020 年 12 月 27 日,prestosql 与 facebook 正式分裂,并改名为
trino。Fackbook: https://prestosql.io/
初创团队: https://trino.io
Presto 是一个 facebook 开源的分布式 SQL 查询引擎,适用于交互式分析查询,数据量支持 GB 到 PB 字节。Presto 的架构由关系型数据库的架构演化而来。它是 hadoop 生态中著名的分布式 SQL 引擎。2019年原作者从 Facebook 分道扬镳更名 Trino。
Presto 是 Facebook 研发的基于 SQL 进行大数据分析的高性能分布式计算引擎,最开始是用来解决Hive速度慢以及异构数据源互通的问题。它在大数据家族中属于MPP(massive parallel processing)计算引擎范畴,其原理是火山(volcano)模型:将SQL抽象成一个个算子(operator),形成管线(pipeline)。目前能够支持 Hive、HBase、ES、Kudu、Kafka、MySQL、Redis、ElasticSearch等 等几十种数据源的读取。
它为何是 SQL 查询引擎?而不是数据库?
和Oracle、MySQL、Hive等数据库相比,他们都具有存储数据和计算分析的能力。如MySQL具有InnoDB存储引擎和有SQL的执行能力;如Hive有多种数据类型、内外表(且这么叫)的管理能力,且能利用MR、TEZ执行HQL。而Presto并不直接管理数据,它只有计算的能力。
Presto 支持从多种数据源获取数据来进行运算分析,一条SQL查询可以将多个数据源的数据进行合并分析。比如下面的SQL:a可以来源于MySQL,b可以来源于Hive。
select a.*,b.* from a join b on (a.id = b.id);
1.2 特点
Presto有如下特点:
- 基于SQL语言,上手成本低,而且功能强大,支持reduce和lambda函数;
- 纯计算引擎,解耦底层存储,可快速缩扩容;
- 纯内存计算,速度快,提供交互式的查询体验;
- 通过插件的方式实现拓展功能,二次开发友好;
1.3 架构
Trino(Presto) 是典型的 MPP 架构,由一个 Coordinator 和多个 Worker 组成,其中 Coordinator 负责 SQL 的解析和调度,Worker 负责任务的具体执行。可配置多个不同类型的 Catalog,实现对多个数据源的访问。
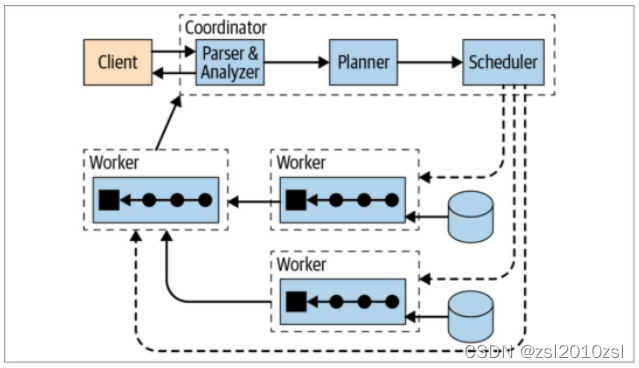
Presto 在整体业务中的架构
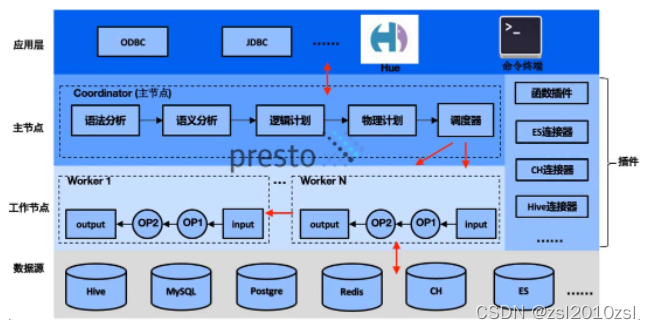
1.4 应用场景
- 实时计算:Trino(Presto)性能优越,实时查询工具上的重要选择。
- Ad-Hoc查询:数据分析应用、Trino(Presto)根据特定条件的查询返回结果和生成报表。
- ETL:因支持的数据源广泛、可用于不同数据库之间迁移,转换和完成ETL清洗的能力。
- 实时数据流分析:Presto-Kafka Connector 使用 SQL对Kafka的数据流进行清洗、分析。
- MPP:Presto Connector有非常好的扩展性,可进行扩展开发,可支持其他异构非SQL查询引擎转为SQL,支持索引下推
2.安装
2.1安装Presto
2.1.1版本选择
在 2020 年 4 月 8 号 presto 社区发布的 332 版本开始,需要 jdk11 的版本.由于现在基本都使 用的是 jdk8,所以我们选择 presto315 版本的,此版本在 jdk8 的环境下是可用的。如果我们生产环境是 jdk8,但是又想使用新版的 presto,可以为 presto 单独指定 jdk11 也可使用。
2.1.2 安装规划
| host | coordinator | worker |
|---|---|---|
| sun75 | √ | × |
| sun77 | × | √ |
| sun46 | × | √ |
2.1.3 PrestoServer && PrestoAgent安装
下载解压
先在coordinator节点安装,后续统一分发
下载安装包到服务器指定目录,此处为/usr/local/src
cd /usr/local/src
wget https://repo1.maven.org/maven2/io/prestosql/presto-server/315/presto-server-315.tar.gz
tar -xvf presto-server-315.tar.gz
wget https://repo1.maven.org/maven2/io/prestosql/presto-cli/315/presto-cli-315-executable.jar
将客户端presto-cli-315-executable.jar放到presto-server-315的bin目录下并修改名称为presto
[root@sun75 bin]# mv presto-cli-315-executable.jar presto
[root@sun75 bin]# ll
total 40
-rwxr-xr-x. 1 root root 1450 Jun 15 2019 launcher
-rw-r--r--. 1 root root 71 Jun 15 2019 launcher.properties
-rwxr-xr-x. 1 root root 14173 Jun 15 2019 launcher.py
-rwxr-xr-x. 1 root root 13710 Dec 14 10:17 presto # 客户端
drwxr-xr-x. 4 root root 47 Jun 15 2019 procname
[root@sun75 bin]# chmod +x presto
创建presto的数据目录(每台机器都要创建),用来存储日志以及数据
mkdir -p /usr/local/src/presto-server-315/data
安装目录下创建etc目录,用来存放各种配置文件
mkdir -p /usr/local/src/presto-server-315/etc
Node Properties配置
在 /usr/lcoal/src/presto-server-315/etc 路径下,配置 node 属性(注意:集群中每台 presto 的 node.id 必须不一样,后面需要修改集群中其它节点的 node.id 值)
vi node.properties
node.environment=develop #环境名称,自己任取.集群中的所有 Presto 节点必须具有相同的环境名称.
node.id=1 #支持字母,数字.对于每个节点,这必须是唯一的.这个标识符应该在重新启动或升级 Presto 时保持一致
node.data-dir=/file/data/presto #指定 presto 的日志和其它数据的存储目录,自己创建前面创建好的数据目录
http-server.log.path=/srv/dstore/1.0.0.0/nfs/cluster/sun75/presto/http-request.log # 请求日志路径
JVM Config配置
在/usr/local/src/presto-server-315/etc 目录下添加 jvm.config 配置文件,并填入如下内容
#参考官方给的配置,根据自身机器实际内存进行配置
-server
-Xmx16G #最大 jvm 内存
-XX:+UseG1GC #指定 GC 的策略
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
-XX:ReservedCodeCacheSize=256M
Config Properties配置
Presto 是由一个 coordinator 节点和多个 worker 节点组成。由于在单独一台服务器上配置 coordinator ,有利于提高性能,所以在 sun75上配置成 coordinator,在 sun77,sun46 上配 置为 worker(如果实际机器数量不多的话可以将在协调器上部署 worker.)在 /usr/local/src/presto-server-315/etc目录下添加 config.properties 配置文件
# 该节点是否作为 coordinator,如果是 true 就允许该 Presto 实例充当协调器
coordinator=true
# 允许在协调器上调度工作(即配置 worker 节点).为 false 就是不允许.对于较大的集群,协调器上的处理工作可能会影响查询性能,因为机器的资源无法用于调度,管理和监视查询执行的关键任务
# 如果需要在协调器所在节点配置 worker 节点改为 true 即可
node-scheduler.include-coordinator=false
# 指定 HTTP 服务器的端口.Presto 使用 HTTP 进行所有内部和外部通信
http-server.http.port=8080
# 每个查询可以使用的最大分布式内存量
query.max-memory=50GB
#查询可在任何一台计算机上使用的最大用户内存量
query.max-memory-per-node=1GB
# 查询可在任何一台计算机上使用的最大用户和系统内存量,其中系统内存是读取器,写入器和网络缓冲区等在执行期间使用的内存
query.max-total-memory-per-node=2GB
# discover-server 是 coordinator 内置的服务,负责监听 worker
discovery-server.enabled=true
# 发现服务器的 URI.因为已经在 Presto 协调器中启用了 discovery,所以这应该是 Presto 协调器的 URI
discovery.uri=http://sun75:8080
http-server.log.max-history=30
http-server.log.max-size=100MB
Log Properties配置
日志配置文件:etc/log.properties。类似Java的日志级别,包括 INFO、DEBUG、ERROR。
com.facebook.presto=INFO
Catalog Properties 配置
Presto 可以支持多个数据源,在 Presto 里面叫 catalog,这里以配置支持 Hive 的数据源为例,配置一个 Hive 的 catalog
在etc目录下创建catalog目录
[root@sun75 catalog]# ll
total 8
-rw-r--r--. 1 root root 260 Dec 14 10:27 hive.properties
-rw-r--r--. 1 root root 111 Dec 14 10:14 mysql.properties
[root@sun75 catalog]#
hive.properties
connector.name=hive-hadoop2
#需要启动hive metastore服务
hive.metastore.uri=thrift://sun75:9083
# hadoop集群的配置文件目录
hive.config.resources=/srv/dstore/1.0.0.0/hdfs/etc/hadoop/core-site.xml,/srv/dstore/1.0.0.0/hdfs/etc/hadoop/hdfs-site.xml
mysql.properties
[root@sun75 catalog]# cat mysql.properties
connector.name=mysql
connection-url=jdbc:mysql://sun75:3306
connection-user=root
connection-password=Hbis@123
elasticsearch.properties
connector.name=elasticsearch
elasticsearch.host=localhost
elasticsearch.port=9200
elasticsearch.default-schema-name=default
localfile.properties
connector.name=localfile
presto-logs.http-request-log.location=/var/log
presto-logs.http-request-log.pattern=messages
分发安装包
scp -r /usr/local/src/presto-server-315 sun77:/usr/local/src
scp -r /usr/local/src/presto-server-315 sun46:/usr/local/src
修改node.properties
[root@sun77 etc]# vim node.properties
node.id=2
[root@sun46 etc]# vim node.properties
node.id=3
修改config.properties
worker 节点(即 sun77 和 sun46 机器)上的 config.properties 配置文件里面的配置内容与 coordinator 所在的节点是不一样的
coordinator=false
http-server.http.port=8080
query.max-memory=50GB
query.max-memory-per-node=1GB
query.max-total-memory-per-node=2GB
discovery.uri=http://sun75:8080
集成kerberos待验证
生成persto主体的princal
kadmin.local -q "addprinc -randkey presto/admin@RONG360.COM"
kadmin.local -q "xst -norandkey -k presto.keytab presto/admin@RONG360.COM"
集成Kerberos环境Hive
修改hive.properties
connector.name=hive-hadoop2
#需要启动hive metastore服务
hive.metastore.uri=thrift://dx-dev-test1026:9083
#配置Presto访问HiveMetastore服务的Kerberos信息,该段配置可以只存在Presto的Coordinator节点
hive.metastore.authentication.type=KERBEROS
hive.metastore.service.principal=hive/_HOST@RONG360.COM
hive.metastore.client.principal=presto/admin@RONG360.COM
hive.metastore.client.keytab=/root/presto.keytab
#配置Presto访问HDFS的Kerberos信息,改段配置可以只存在Presto的Worker节点
hive.hdfs.authentication.type=KERBEROS
hive.hdfs.impersonation.enabled=true
hive.hdfs.presto.principal=presto/admin@RONG360.COM
hive.hdfs.presto.keytab=/root/presto.keytab
# hadoop集群的配置文件目录
hive.config.resources=/etc/hadoop/conf/core-site.xml,/etc/hadoop/conf/hdfs-site.xml
在hive.properties配置文件中增加访问HiveMetastore和HDFS的Kerberos认证信息,将如上配置同步至Presto集群所有节点的${PRESTO_HOME}/etc/catalog/hive.properties文件中。
注意:在配置hive.metastore.url时,需要使用HiveMetastore服务的HOSTNAME,否则在使用Kerberos访问HiveMetastore时会报找不到Kerberos账号的错误。
2.2 安装Trino
2.2.1版本选择
选择最新版本的安装包
JDK版本:
Trino 需要 Java 17 的 64 位版本,最低要求版本为 17.0.3。 早期的主要版本(如 Java 8 或 Java 11)不起作用。 不支持较新的主要版本,例如 Java 18 或 19,它们可能有效,但未经过测试。
https://adoptium.net/zh-CN/download/ ,这里采用trino推荐的JDK版本
采用二进制包的方式安装
下载安装包
wget https://repo1.maven.org/maven2/io/trino/trino-server/435/trino-server-435.tar.gz # 服务端安装包
wget https://repo1.maven.org/maven2/io/trino/trino-cli/435/trino-cli-435-executable.jar # 客户端工具
解压服务端安装包并将客户端工具放置bin目录下,该名称为trino
[root@sun75 bin]# ll
total 13640
-rwxr-xr-x. 1 root root 1511 Dec 26 09:47 launcher
-rw-r--r--. 1 root root 65 Dec 14 12:38 launcher.properties
-rwxr-xr-x. 1 root root 14608 Dec 14 12:38 launcher.py
drwxr-xr-x. 5 root root 68 Dec 14 12:38 procname
-rwxr-xr-x. 1 root root 13942418 Dec 26 09:50 trino # 改名后的客户端工具
[root@sun75 bin]#
由于trino对于JDK要求比较严格,但是本地项目用的是jdk1.8,所以需要单独给trino配置JDK17的环境
将JDK安装包跟Trino打到一起
[root@sun75 trino-server-435]# ll
total 208
drwxr-xr-x. 3 root root 97 Dec 26 10:36 bin
drwxr-xr-x. 3 root root 109 Dec 26 10:47 etc
drwxr-xr-x. 9 root root 121 Dec 26 09:22 jdk-17.0.9+9 # JDK17 解压包
drwxr-xr-x. 2 root root 8192 Dec 14 12:38 lib
-rw-r--r--. 1 root root 190881 Dec 14 12:38 NOTICE
drwxr-xr-x. 49 root root 4096 Dec 14 12:38 plugin
-rw-r--r--. 1 root root 115 Dec 14 12:38 README.txt
[root@sun75 trino-server-435]#
2.2.2 安装
Trino配置方式跟Presto DB大同小异
创建配置路径
mkdir -p etc/catalog
node.properties
node.environment=production
node.id=ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir=/var/trino/data
上述属性描述如下:
node.environment: 环境的名称。集群中的所有 Trino 节点必须具有相同的 环境名称。名称必须以小写字母数字字符开头 并且仅包含小写字母数字或下划线 () 字符。_node.id: 此 Trino 安装的唯一标识符。这必须是 每个节点都是唯一的。此标识符应在 重新启动或升级 Trino。如果运行 单台机器上的 Trino(即同一台机器上的多个节点), 每个安装都必须具有唯一标识符。标识符必须以 替换为字母数字字符,并且仅包含字母数字、或字符。-``_node.data-dir: 数据目录的位置(文件系统路径)。Trino商店 日志和其他数据。
jvm.config
JVM 配置文件 包含命令行列表 用于启动 Java 虚拟机的选项。文件的格式 是一个选项列表,每行一个。这些选项不由 shell,因此包含空格或其他特殊字符的选项应 不被引用
-server
-Xmx16G
-XX:InitialRAMPercentage=80
-XX:MaxRAMPercentage=80
-XX:G1HeapRegionSize=32M
-XX:+ExplicitGCInvokesConcurrent
-XX:+ExitOnOutOfMemoryError
-XX:+HeapDumpOnOutOfMemoryError
-XX:-OmitStackTraceInFastThrow
-XX:ReservedCodeCacheSize=512M
-XX:PerMethodRecompilationCutoff=10000
-XX:PerBytecodeRecompilationCutoff=10000
-Djdk.attach.allowAttachSelf=true
-Djdk.nio.maxCachedBufferSize=2000000
-Dfile.encoding=UTF-8
# Reduce starvation of threads by GClocker, recommend to set about the number of cpu cores (JDK-8192647)
-XX:+UnlockDiagnosticVMOptions
-XX:GCLockerRetryAllocationCount=32
您必须调整 Trino 使用的内存值,该值指定为节点上的可用内存。通常,表示 70 到 85 的值 建议使用总可用内存的百分比。例如,如果所有 workers 和 coordinator 使用具有 64GB RAM 的节点,您可以使用 . Trino 使用大部分分配的内存进行处理,只有一小部分 由 JVM 内部进程(如垃圾回收)使用。-Xmx``-Xmx54G
其余的可用节点内存必须足以运行。 系统和其他正在运行的服务,以及用于本机的堆外内存 代码启动了 JVM 进程。
在较大的节点上,百分比值可以更低。将所有内存分配给 不支持 JVM 或使用交换空间,并且禁用 建议使用操作系统级别。
对于生产群集,建议将超过 32GB 的大内存分配。
因为 通常将 JVM 留在 不一致的状态,我们写一个堆转储,用于调试,并强制 发生这种情况时,请终止进程。OutOfMemoryError
JVM 使用的临时目录必须允许执行代码。 具体而言,装载不得设置标志。在某些安装中,默认目录使用此标志挂载,这 阻止 Trino 启动。您可以通过覆盖 临时目录,方法是将 JVM 选项列表。noexec``/tmp``-Djava.io.tmpdir=/path/to/other/tmpdir
我们设置 GCLocker 重试分配计数 () 以避免过早的 OOM(参见 JDK-8192647-XX:GCLockerRetryAllocationCount=32)
config.properties
以下是协调器的最低配置
coordinator=true
node-scheduler.include-coordinator=false
http-server.http.port=8080
discovery.uri=http://example.net:8080
这是 worker 的最低配置:
coordinator=false
http-server.http.port=8080
discovery.uri=http://example.net:8080
或者,如果要设置单台计算机进行测试,则 同时充当协调器和工作器,请使用以下配置:
coordinator=true
node-scheduler.include-coordinator=true
http-server.http.port=8080
discovery.uri=http://example.net:8080
coordinator: 允许这个 Trino 实例充当协调器,以便 接受来自客户端的查询并管理查询执行。node-scheduler.include-coordinator: 允许在协调器上安排工作。 对于较大的集群,在协调器上处理工作 可能会影响查询性能,因为计算机的资源不是 可用于调度、管理和监控等关键任务 查询执行。http-server.http.port: 指定 HTTP 服务器的端口。Trino 将 HTTP 用于所有 内部和外部的沟通。discovery.uri: Trino 协调器具有所有节点使用的发现服务 寻找彼此。每个 Trino 实例都会向发现注册自身 启动时服务并持续心跳以保持其注册 积极。发现服务与 Trino 共享 HTTP 服务器,因此 使用相同的端口。替换以匹配主机和 Trino 协调员的端口。如果在协调器上禁用了 HTTP, URI 方案必须是 ,而不是 。example.net:8080``https``http
log.properties
io.trino=INFO
连接器
mysql.properties
connector.name=mysql
connection-url=jdbc:mysql://192.168.2.75:3306
connection-user=root
connection-password=Hbis@123
测试会报错
如何将镜像时区更改为亚洲/上海,但仍能从 429 年起连接到 MySQL ·期刊 #20033 ·trinodb/trino ·GitHub的
按照上述记录,解决方式为在jvm.config添加属性
-Duser.timezone=GMT+8
hive.properties
connector.name=hive # 此处必须为hive
#需要启动hive metastore服务
hive.metastore.uri=thrift://sun75:9083
# hadoop集群的配置文件目录
hive.config.resources=/srv/dstore/1.0.0.0/hdfs/etc/hadoop/core-site.xml,/srv/dstore/1.0.0.0/hdfs/etc/hadoop/hdfs-site.xml
测试会报错trino Caused by: IllegalArgumentException: The datetime zone id 'GMT+08:00' is not recognised
看起来是时区格式不对导致,然后将GMT+8改为GMT 后竟然好了
trino> show schemas from mysql;
Schema
--------------------
hive_metastore
hue
information_schema
performance_schema
sun
(5 rows)
Query 20231226_034949_00013_u2b9g, FINISHED, 1 node
Splits: 11 total, 11 done (100.00%)
1.84 [5 rows, 81B] [2 rows/s, 44B/s]
trino> show schemas from hive;
Schema
--------------------
default
information_schema
(2 rows)
Query 20231226_034955_00014_u2b9g, FINISHED, 1 node
Splits: 11 total, 11 done (100.00%)
0.44 [2 rows, 35B] [4 rows/s, 80B/s]
trino>
3.启动
Presto DB和Presto SQL一样
| 命令 | 行动 |
|---|---|
run |
在前台启动服务器并使其保持运行状态。关闭 服务器,在此终端中使用 Ctrl+C 或 另一个终端。stop |
start |
将服务器作为守护程序启动并返回其进程 ID。 |
stop |
关闭以 或 开头的服务器。发送 SIGTERM 信号。start``run |
restart |
停止然后重新启动正在运行的服务器,或启动已停止的服务器, 分配新的进程 ID。 |
kill |
通过发送 SIGKILL 信号来关闭可能挂起的服务器。 |
status |
打印状态行,即“已停止的 pid”或“作为 pid 运行”。 |
启动脚本在安装目录的bin/launcher目录下,我们可以使用如下命令作为一个后台进程启动:
bin/launcher start
另外,也可以用在前台启动的方式运行,日志和目录输出将会写入到 stdout/stderr(可以使用类似daemontools的工具捕捉这两个数据流)
bin/launcher run
启动完之后,日志将会写在var/log目录下,该目录下有如下文件:
launcher.log:这个日志文件由 launcher 创建,并且server的stdout和stderr都被重定向到了这个日志文件中。这份日志文件中只会有很少的信息,包括:
在server日志系统初始化的时候产生的日志和JVM产生的诊断和测试信息。
-
server.log:这个是 Presto 使用的主要日志文件。一般情况下,该文件中将会包括server初始化失败时产生的相关信息。 -
http-request.log: 这是HTTP请求的日志文件,包括server收到的每个HTTP请求信息。
启动成功之后,我们可以通过jps查看到多了一个 PrestoServer 的进程。
[root@sun75 etc]# jps
6051 PrestoServer
访问Presto DB的webui界面
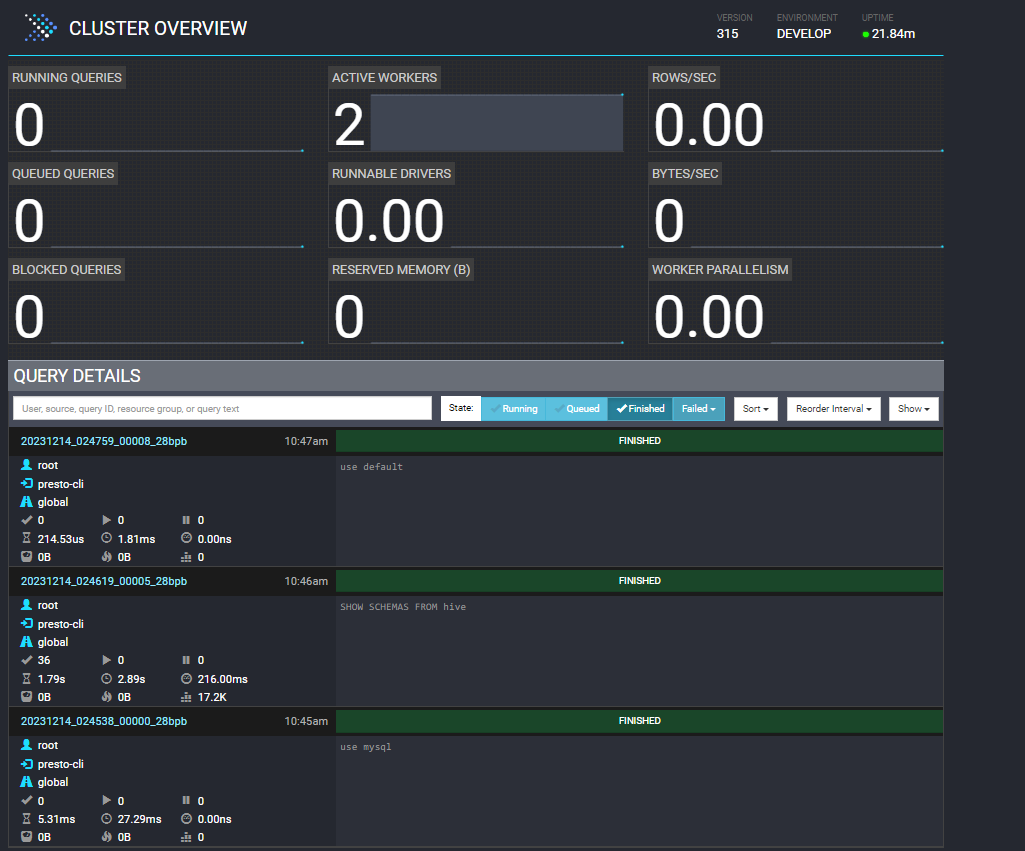
访问Trino界面,没有配置密码前,输入任意密码即可
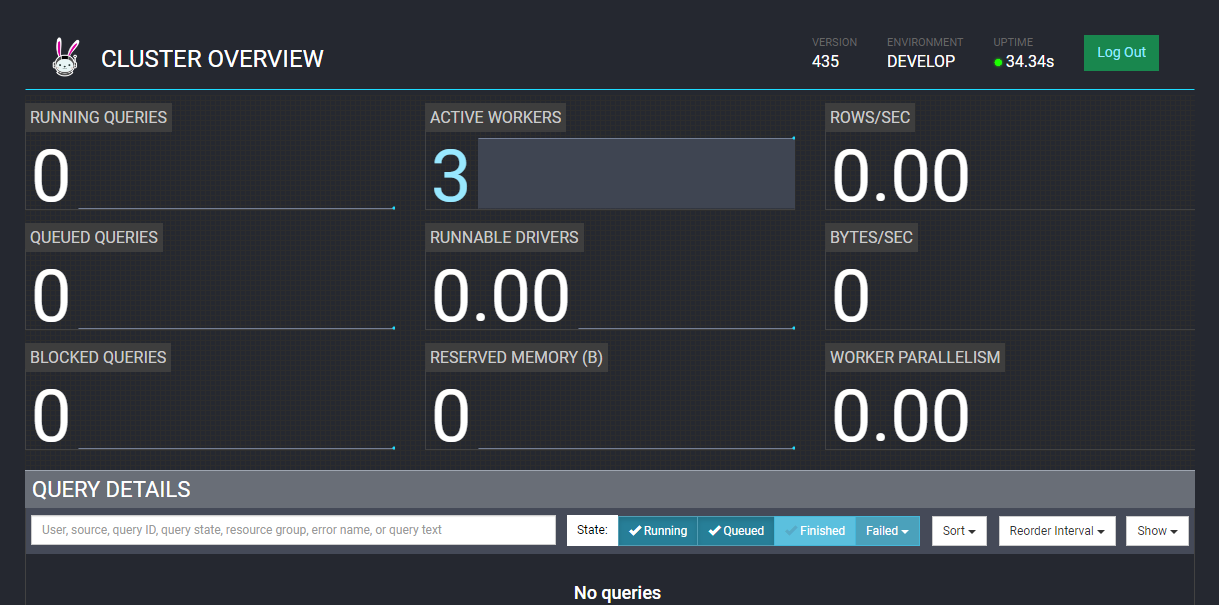
4.客户端操作
presto --server sun75:8080 --catalog mysql
[root@sun46 bin]# ./presto --server sun75:8080 --catalog mysql
presto> show schemas from mysql;
Schema
--------------------
hive_metastore
hue
information_schema
performance_schema
sys
(5 rows)
Query 20231218_022020_00000_fyx3a, FINISHED, 3 nodes
Splits: 36 total, 36 done (100.00%)
0:02 [5 rows, 81B] [3 rows/s, 51B/s]
presto> show schemas from hive;
Schema
--------------------
default
information_schema
(2 rows)
Query 20231218_022036_00001_fyx3a, FINISHED, 3 nodes
Splits: 36 total, 36 done (100.00%)
0:01 [2 rows, 35B] [1 rows/s, 29B/s]
presto>
5.自定义日志路径
Presto日志路径默认在node.properties配置文件中的配置项node.data-dir路径下
-rw-r--r--. 1 root root 136423 Dec 15 2023 http-request.log
-rw-r--r--. 1 root root 2616 Dec 15 14:02 launcher.log
-rw-r--r--. 1 root root 1073982 Dec 15 14:02 server.log
具体目录在bin下的launch.py中设置
代码片段
o.pid_file = realpath(options.pid_file or pathjoin(o.data_dir, 'var/run/launcher.pid'))
o.launcher_log = realpath(options.launcher_log_file or pathjoin(o.data_dir, 'var/log/launcher.log'))
o.server_log = realpath(options.server_log_file or pathjoin(o.data_dir, 'var/log/server.log'))
其中o.data_dir就是node.data-dir配置项拼接,所以可以修改这个路径,让日志文件存到自定义目录,最优的方式是在配置文件中添加自定义配置项,修改如下
vi node.properties
# 自定义路径
custom.log.path=/srv/dstore/1.0.0.0/nfs/cluster/sun75/presto
vi launcher.py
log_path_dstore = node_properties['custom.log.path']
o.pid_file = realpath(options.pid_file or pathjoin(o.data_dir, 'run/launcher.pid'))
o.launcher_log = realpath(options.launcher_log_file or pathjoin(log_path_dstore, 'launcher.log'))
o.server_log = realpath(options.server_log_file or pathjoin(log_path_dstore, 'server.log'))
然后重启即可
参考
https://cloud.tencent.com/developer/article/1892572
http://armsword.com/2020/05/02/the-difference-between-prestodb-and-prestosql/