
letgo
摘要
HPC需要容错,而检查点技术开销太大。
提出letgo,能在崩溃时继续执行HPC。为什么能提?1.有的HPC应用有比较好的内在容错能力,可以重新利用默认机制。
用五个benchmark,结果不错
introduction
letgo能够存在的依据:
一旦发出导致崩溃的错误信号,就可以重新调整默认机制的用途,并尝试修复损坏的应用程序状态并继续应用程序执行。
-
一大类 HPC 应用程序本质上对局部数值扰动具有弹性,因为它们要求计算结果随着时间的推移而收敛。因此,他们能够掩盖一些数据损坏
-
许多 HPC 应用程序都有特定于应用程序的验收检查。这些检查可用于过滤掉应用程序输出中的明显偏差,并降低产生错误结果的可能性
-
大多数导致崩溃的错误会导致少量动态指令内的程序崩溃,因此不太可能传播到应用程序状态的大部分。导致崩溃的故障的影响可能仅限于应用程序状态的一小部分,从而允许恢复。
letgo是怎么做的:
LetGo 通过在运行时监控应用程序来工作;当发生导致崩溃的错误时,LetGo 会拦截硬件异常(例如,分段错误),并且不会将异常传递给应用程序。相反,它将应用程序的程序计数器前进到下一条指令,绕过导致崩溃的指令。
此外,LetGo 采用各种启发式方法来调整应用程序寄存器文件的状态,以隐藏被忽略指令的影响,并尽可能确保应用程序状态不被破坏。
设置检查,如果程序通过检查,那么就不需要恢复。
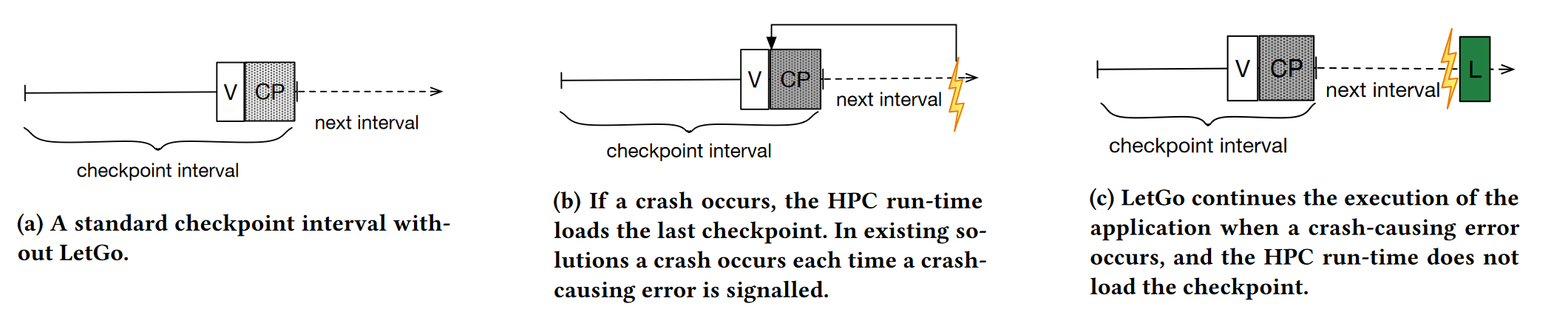
letgo消除的开销:
-
错误时从前一个检查点启动的开销
-
崩溃频率低,降低了检查点的频率
letgo的潜在成本:
-
SDC率增加导致错误结果,但是在可接受范围。
-
增加很低。
-
未检测到的错误即使不用letgo也会产生错误结果。
-
letgo的组成:“design LetGo”
LetGo 既不需要对应用程序进行修改,也不需要提供应用程序的源代码进行分析
-
一个监视器“monitor” ,用于拦截和处理发生导致崩溃的错误时生成的操作系统信号
-
一个修改器“modifier” ,它采用启发式方法调整程序状态以提高运行速度。
letgo的效果:“evaluate LetGo”
它创造了一个机会,可以牺牲对结果的信心来换取效率
-
LetGo 在大约 62% 的情况下能够继续应用程序的执行
-
SDC率(未检测到的错误输出)的增加较低:算术平均值为0.913%。
letgo的灵感来源:“inspired by”
-
故障遗忘计算“failure-oblivious computing” ,专注于从软件错误引起的故障中恢复
-
近似计算“approximate computing” 假设忽略应用程序执行期间的一些错误,仍然会产生可接受的结果
与失败遗忘计算“Failure oblivious computing” 的不同点:
-
LetGo 关注所有类型的崩溃,而上述技术则关注越界内存访问,这是 HPC 系统中崩溃源的一个子集
-
我们关注我们认为此类技术可能会产生重大影响的 HPC 应用程序
与近似计算“Approximate computing” 的不同点
LetGo 并不旨在大幅放松计算的准确性,这与近似计算或概率计算是不同的理念
background
影响letgo效率的因素:
-
应用程序级别的接受检查,用于检测在向用户提供结果之前应用程序状态是否已损坏,
-
HPC应用程序的弹性特征,使其能够经受小的数值扰动。
“Application acceptance checks.”结果验收检查
结果验收检查通常由应用程序开发人员编写,以确保计算结果不会违反应用程序特定的属性,例如能量守恒或结果近似的数值容差。
“Fault masking in HPC applications”HPC应用程序中的故障屏蔽。
对于一个收敛的迭代方法,由硬件故障引入的数值误差可以在这个收敛过程中被消除(尽管可能需要更长的时间)。
系统设计
目标是证明运行时框架的可行性并评估其潜在影响,该框架允许程序在发生导致崩溃的错误后避免终止并纠正其状态。
四个要求:
-
“Transparency”
-
“Convenience” ,LetGo不应对应用程序的编译级别做出任何假设或要求更改应用程序的编译过程
-
“Low overhead”
-
“A low rate of newly introduced failures” ,为了让 LetGo 变得实用,未检测到的错误结果的增加率应该很低
整体设计
-
检测操作系统引发的异常
-
拦截操作系统信号
-
修改应用程序针对这些信号的默认行为
-
诊断程序的哪些状态已损坏
-
修改应用程序状态以尽可能确保应用程序的连续性
过程
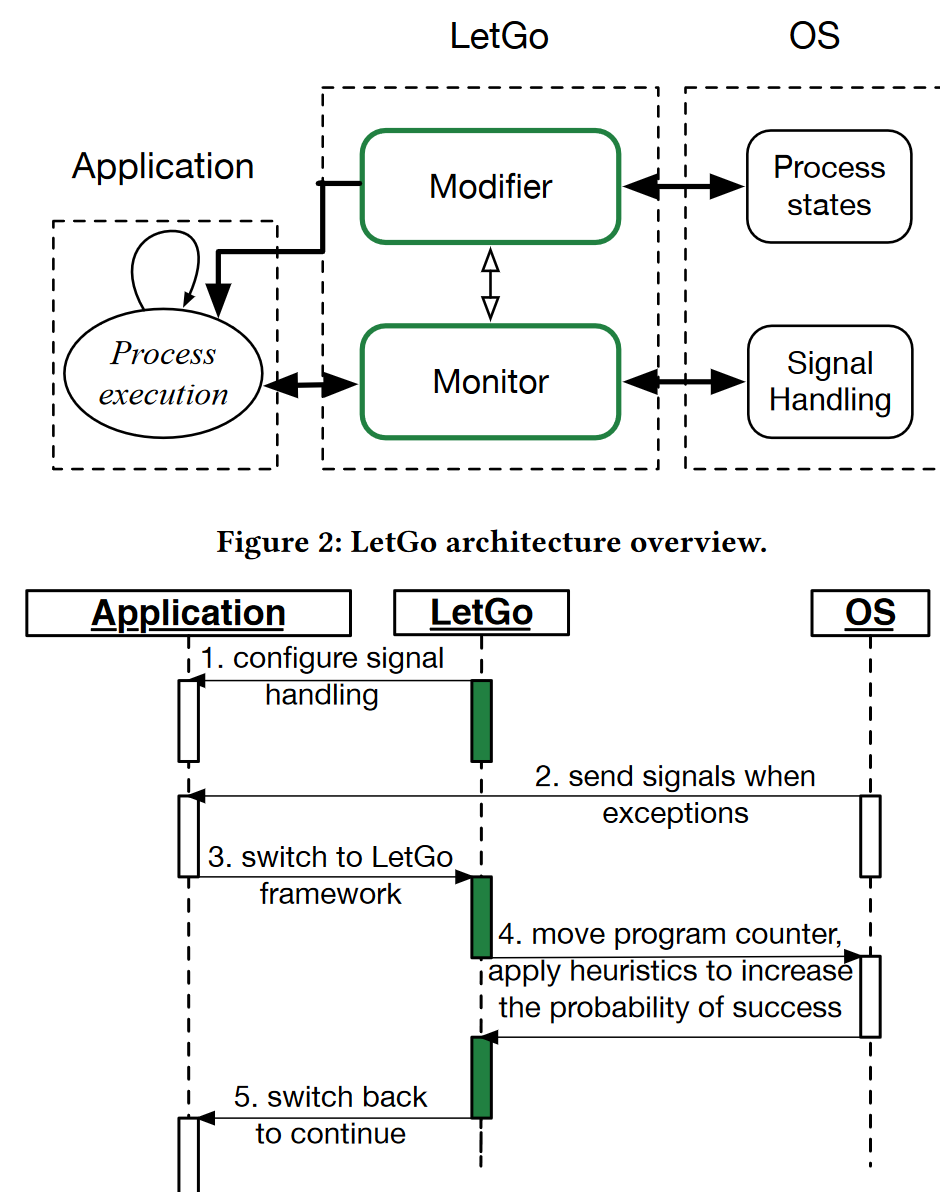
-
LetGo 首先安装监视器 - 即配置信号处理,并在调试器。
-
如果应用程序遇到信号,LetGo 会检测到它
-
并控制应用程序
-
为了避免失败,LetGo 会增加应用程序的程序计数器(即指令指针)并调整必要的程序状态
-
修改后,LetGo 让应用程序继续运行,不受任何进一步的干扰
modifier怎么避免崩溃:
它将程序计数器(即指令指针)推进到下一条指令,并检查并修改应用程序状态(例如栈指针),以增加成功继续执行的可能性。
启发式方法(“Heuristics” )
两个目标:
-
首先,增加应用程序继续执行后不会再次崩溃的可能性;
-
其次,减少数据损坏进一步传播的机会。
两个问题:
-
推进程序计数器可能会绕过内存加载或存储,因此应该保存来自内存加载的值的目标寄存器(或用于存储的内存位置)可能包含不正确的值,如果稍后使用该寄存器,则可能导致后续错误
-
如果故障已经损坏了栈指针寄存器 sp或基指针寄存器 bp,并且由于LetGo而应用程序继续执行,那么由于 sp 和 bp 被重复使用,再次收到与内存违规相关的系统异常的可能性很高。
如何解决(两个启发式方法):
-
如果程序由于内存加载/存储指令中的错误而崩溃,LetGo将要写入的寄存器(其中保存从内存加载的数据)填充为“虚假”值。对于程序停在内存存储指令的情况,由于内存存储操作不成功,该内存位置中的值保持不变。
-
如果故障影响堆栈指针寄存器或基指针寄存器中的值,则损坏的寄存器可能导致连续的内存访问违规。
由于 LetGo 避免执行运行时跟踪,因此静态确定 sp 和 bp 值的正确性变得具有挑战性。采用检测和纠正实现启发式
-
检测:对于每个函数,可以通过静态分析近似绑定sp和bp中的值之间的差异,因此可以计算出此范围,以最小的工作量指示在运行时sp或bp中的损坏。
-
纠正:由于sp和bp通常在每个函数的开始时保持相同的值,因此可以使用其中一个值来校正另一个值中的错误
-

push %rbp: 将当前函数调用的基址指针(base pointer)rbp 压入栈中,用于保存前一个函数调用的堆栈帧基址。
mov %rsp, %rbp: 将当前栈指针 rsp 的值赋给 rbp,建立当前函数调用的堆栈帧。
sub $0x290, %rsp: 从当前栈指针 rsp 减去 0x290,为当前函数调用在栈上分配 0x290 字节的内存空间。
从示例代码可以看到:
-
bp通常指向堆栈的顶部(第2行),因此在每个函数调用的开始,sp和bp通常携带相同的值。
-
根据在堆栈上分配的内存大小(第3行),可以推断出bp的范围为sp < bp < sp + 0x290
当程序收到异常并停在涉及堆栈操作的指令处,LetGo 运行以下步骤:
-
首先,通过搜索该指令所属函数的开头,获取
待分配的内存大小,然后定位到显示函数在堆栈上需要多少内存的指令上(通过分析汇编代码)。 -
其次,它根据大小计算有效范围,并检查 bp 是否在其中,
-
最后,如果范围约束无效,则 LetGo 复制sp 到 bp 的值(反之亦然,具体取决于导致崩溃的指令中使用了哪一个)。
应用这些启发式的LetGo版本称为LetGo - E ( nhanced ),不应用启发式的LetGo版本称为LetGo - B ( asic )。
实现“Implementation”
用gdb,pin,pexpect实现letgo
gdb
gdb 提供了处理操作系统信号和更改程序寄存器中的值的接口。
LetGo 使用 gdb 重新定义应用程序针对操作系统信号的行为,例如SIGSEGV、SIGBUS 和 SIGABRT。由于大多数应用程序崩溃是由于与内存相关的错误(例如分段错误或总线错误)
LetGo 对 gdb 的使用不需要进行任何源代码级别的分析
PIN
由于 LetGo 只需要程序的静态信息,因此无需跟踪动态程序状态,只需要 PIN 内部的反汇编器。因此,LetGo 的性能开销非常小
pexpect:expect
letGo 使用 pexpect,即 expect 的 Python 扩展,来自动化 LetGo 与应用程序之间的所有交互,例如配置信号处理程序和更新寄存器值等。
所有与 gdb 进程和目标应用程序之间的交互都是通过 pexpect 自动化完成,且限制在一些有限的 gdb 命令上,比如 "print" 或 "set"。
评估方法“EVALUATION METHODOLOGY”
这一节的重点是评估 LetGo 将崩溃转化为成功应用程序运行的能力。
-
首先描述了我们使用的故障模型和故障注入方法
-
然后解释了各种故障结果类别受到 LetGo 影响的方式
-
提出了用于定量评估 LetGo 效果的指标
故障模型
软错误是处理器中硬件错误的主要来源之一[4],也是本工作的重点。
我们考虑发生在处理器的计算单元(如ALUs、流水线锁存器和寄存器文件)中的故障。
不考虑缓存或主内存中的故障
使用单比特翻转模型
假设在应用程序运行中最多发生一个导致崩溃的软错误
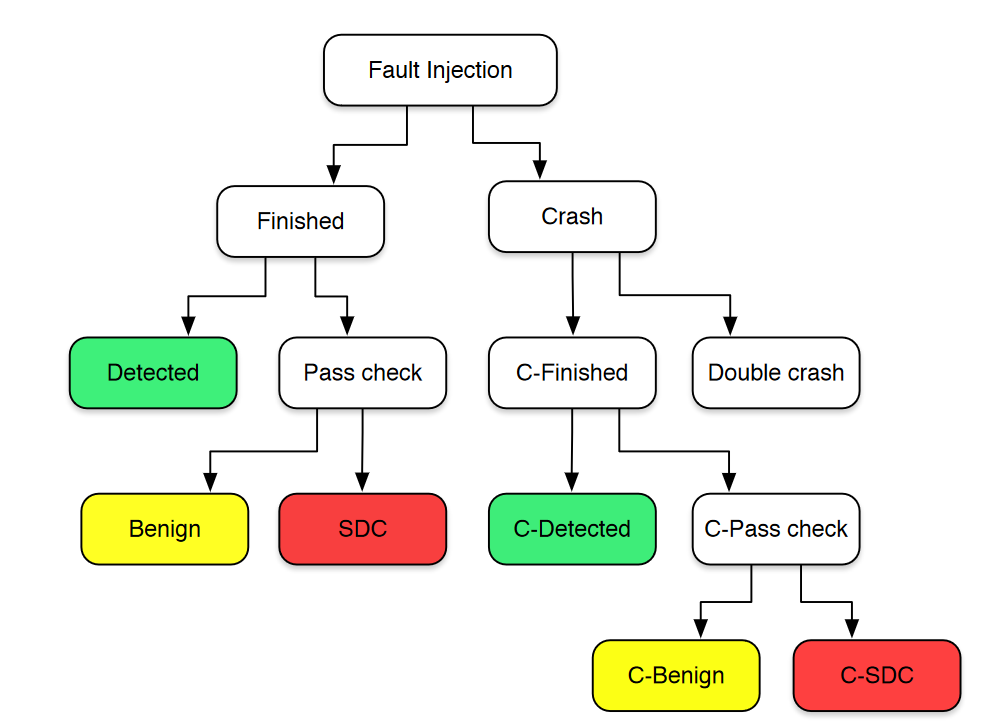
错误类型 “Categories of Fault Outcomes”
故障要么导致程序崩溃,要么不导致程序崩溃。
引入了Detected(被检测出的不正确的输出),Benign(结果无错),SDC(未被检测到的错误输出);以及使用了letgo后的状态
效率指标 “Metrics of Effectiveness”
“Continuability”
"Continuability"(可继续性)是指 LetGo 能够将一个崩溃的程序转换为一个能够完成执行的程序的概率,而不考虑输出的正确性。
“Continued_detected”
“Continued_correct”
“Continued_SDC”
什么应用适合letgo:
-
Continuability 高
-
Continued_correct 高,Continued_SDC 低
故障注入方法 “Fault Injection Methodology”
为了评估 LetGo,我们实现了一个基于 gdb 和 PIN 2 的软件故障注入工具。
-
首先,我们执行一次性的分析阶段,使用 PIN 工具计算动态指令的数量。由于我们假设所有动态指令受到故障的概率相等,我们使用总指令数来随机选择每次故障注入运行中要注入故障的指令。
-
在故障注入阶段,我们使用 gdb 在随机选择的动态指令处设置断点,并在该指令执行完成后通过翻转其目标寄存器中的单个位来注入故障。
分析阶段每个应用程序运行一次,相对较慢。另一方面,注入阶段执行数万次,速度更快。
基准测试 “Benchmarks”
LULESH [20], CLAMR [43], HPL [46], SNAP [35], PENNANT [33] and COMD [10]
这些基准符合应用程序级接受检查是被很好定义/实现的假设。所有基准都表现出基于收敛的迭代计算模式。
实验结果 “EXPERIMENTAL RESULTS”
旨在了解 LetGo 是否确实能够在发生导致崩溃的错误时继续应用程序执行,并且对应用程序的正确性和效率影响最小
letgo的效率
对 LetGo 的两个版本进行了故障注入实验,分别是 LetGo-B(基本版本,使用最小的修复启发式)和 LetGo-E(使用第4节中描述的高级启发式的版本)。
观察:
-
所有应用程序的平均崩溃率为56%
-
使用 LetGo-E,平均而言,这些崩溃中的62%可以转化为继续运行应用程序直至终止
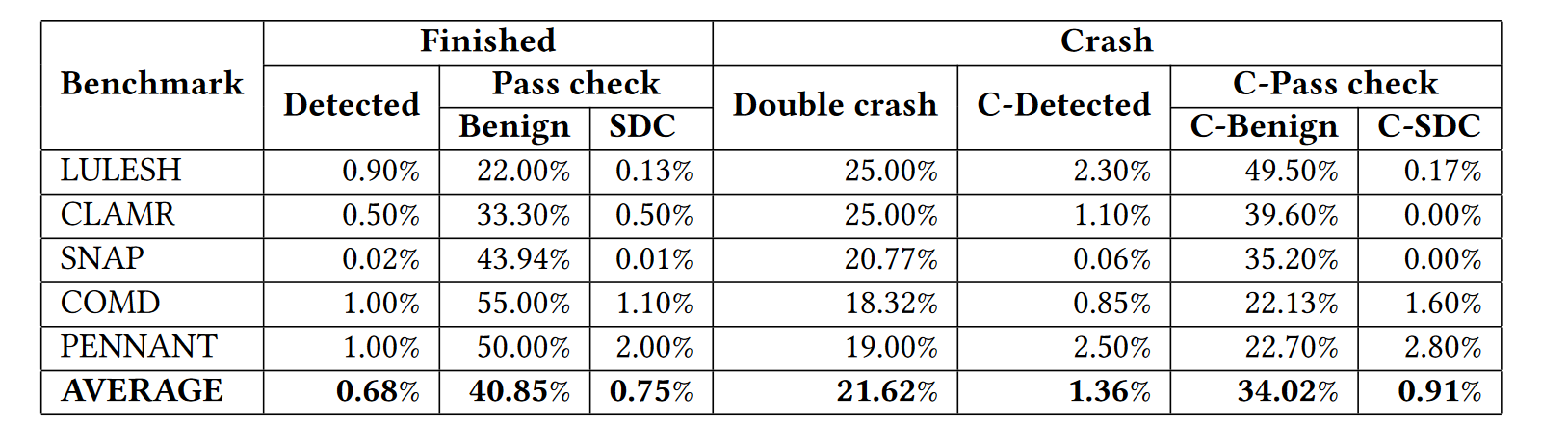
对letgo-e的观察:基于Table 3” (Fang 等, 2017, p. 9)
我们发现 LetGo-E 有很高的可能性将崩溃转化为良性状态或检测到的状态,同时仅在一定程度上增加了产生的 SDCs
-
LetGo-E 能够在面对导致崩溃的错误时启用继续执行的能力
-
LetGo-E 能够将超过一半的崩溃转化为生成正确的结果
-
LetGo-E 保持了原始应用程序的低 SDC 率
-
应用程序级可接受的检查 Continued_detected

letgo-e与letgo-b比较:基于“Figure 5” (Fang 等, 2017, p. 10)
-
总体而言,LetGo-E 的平均 Continuability 比 LetGo-B 高14%。
-
LetGo-E 使用的启发式对接受检查的有效性影响不大。
-
LetGo-E 允许更多的崩溃转化为正确的结果
-
LetGo-E 使用的启发式对不正确的执行并没有太大的影响。
性能负担
不考虑 C/R 方案的上下文中进行单个应用程序运行的实验来实验性地测量 LetGo 的性能
LetGo 的开销有两个来源:
-
使用 gdb 运行程序
-
在发生崩溃后调整程序状态
首先测量 LULESH 在三个输入大小下使用 LetGo 运行的执行时间。带有 gdb 的 LULESH 表现出一致较低的开销(即,与在没有 gdb 的情况下运行相比,每种情况都低于1%)。这是因为 LetGo 既不更改应用程序的编译级别,也不在应用程序上设置断点。
图3中的第4步所花费的时间:发现在我们的所有基准测试中,LetGo 花费的挂钟时间大致在2-5秒之间,并且正如预期的那样,当我们增加输入大小时,它保持不变。 LetGo 采取两个行动来调整程序状态:1) 找到下一个 PC,2) 如有必要应用两个启发式。这两个行动只需要一个反汇编器来获取程序的静态指令级信息 - 我们使用 PIN。
C/R环境中的letgo“LETGO IN A C/R CONTEXT” (Fang 等, 2017, p. 10)
本节旨在评估 LetGo 在使用 C/R 机制的长时间并行应用程序上的端到端影响。
建模采用了C/R机制 的典型 HPC 系统作为一个状态机,并构建了系统的连续时间事件模拟。
该模拟框架使我们能够比较在有和没有 LetGo 的情况下的资源使用效率。
在本节的其余部分,当我们提到 LetGo 时,我们指的是 LetGo-E。
对模型的假设:
-
Crash原因假设:假设所有的崩溃都是由于瞬态硬件故障引起的,因此从检查点重新启动应用程序就足以从崩溃中恢复。这意味着系统假设崩溃是可通过重新启动来纠正的。
-
检查点过程不受故障影响的假设:假设检查点过程本身不会受到故障的影响。这意味着在创建检查点时,系统不考虑到可能会发生故障的情况。
-
应用程序无其他容错机制的假设:假设应用程序除了使用 C/R(和 LetGo)之外,没有其他的容错机制。这意味着系统不考虑应用程序在遇到故障时可能采取的其他恢复措施。
-
应用程序行为不受故障影响的假设:假设应用程序在面临故障时不会修改其行为。这意味着系统不考虑应用程序可能根据故障改变其执行方式。
-
同步协调检查点的假设:在对多节点平台建模时,假设 HPC 系统使用同步协调检查点,这意味着通过同步在不同节点上同时进行检查点。当一个节点崩溃时,系统中的所有节点都必须回退到最后一个检查点,并一起重新执行。
模型参数“Table 4:” (Fang 等, 2017, p. 11)
-
Configured(配置参数)
-
Estimated(估计参数)
-
Derived(派生参数)
不使用letgo的C/R 方案的状态机模型
有三种状态:COMPutation、Checkpoint 和 VERIF-ication(COMP,CHK,VERIRF)

始时,应用程序进入 COMPutation 状态进行正常计算。如果没有发生崩溃(1⃝)并且对应用程序数据/输出进行接受检查,应用程序从 COMP 状态转移到 VERIF 状态。
如果检查通过,应用程序从 VERIF 状态转移到 CHK(5⃝),并立即进行检查点。
如果应用程序未通过检查,它会从 VERIF 状态转移到 COMP 状态(2⃝)
在检测到故障(4⃝)或应用程序在 COMP 状态时发生故障但没有导致崩溃的情况下,应用程序会从 COMP 状态返回到自身,保持在 COMP 状态,并增加故障次数(3⃝)
当系统中积累了故障时,模型假定硬件瞬态故障是独立事件,因此应用程序通过验证检查的概率被建模为 (P_v)f aults。
P v是应用程序在正常运行时通过验证检查的概率。
faults 是系统中累积的故障数量。
使用 LetGo 的 C/R 方案的状态机模型
多了两种状态"LETGO" 和 "CONT"inue
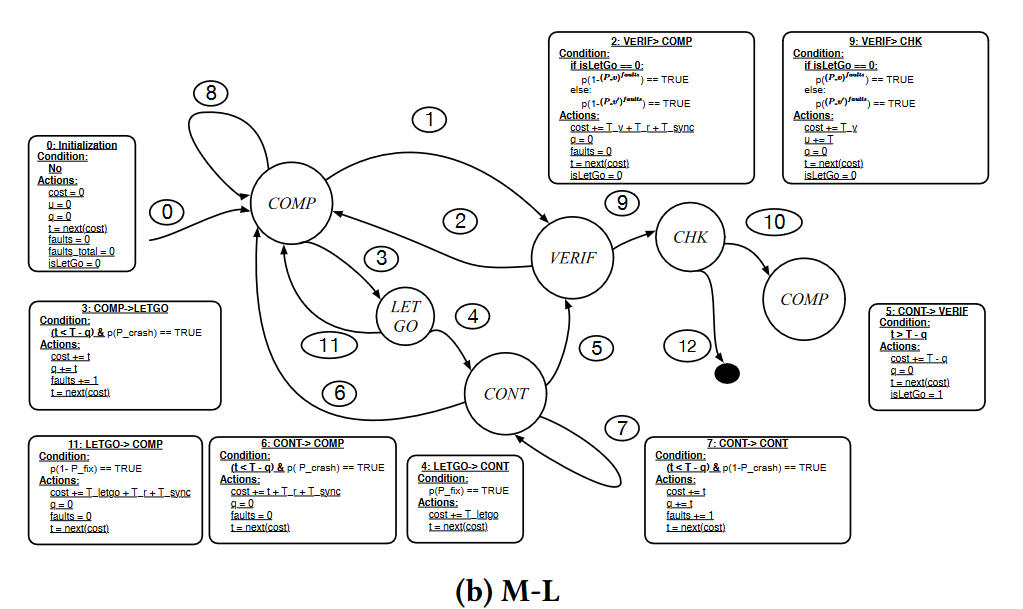
-
当在计算过程中发生故障(即崩溃)时(应用程序仍处于 COMP 状态),会发生从 COMP 状态到 LETGO 状态的转换(3⃝)。
-
如果 LetGo 继续执行应用程序,应用程序从 LETGO 状态转移到 CONT 状态(4⃝),否则,应用程序返回到 COMP 状态(11⃝)。
-
在应用程序保持在 CONT 状态时,发生的故障可能会导致另一次崩溃,并使应用程序转移到 COMP 状态(6⃝),或者不会导致崩溃,使应用程序继续到 VERIF 状态。
-
"isLetGo" 标志用于选择不同的基础概率(P_v 或 P_v’),即应用程序通过验证检查的概率(5⃝)。
-
在应用程序转移到 VERIF 状态之前,使用 (P_v )f aults 或 (P _v ′)f aults 来计算实际概率(8⃝和7⃝)。
评估指标
目标是了解在长时间运行的应用程序使用 C/R 方案并存在故障的情况下,LetGo 对资源使用效率的影响
定义资源使用效率为累积的有效时间与总共花费时间之比(即 u/cost)
参数选择“Choice of parameters” (Fang 等, 2017, p. 11)
检查点开销
写入检查点到持久存储所花费依赖于硬件特性的时间。
先进硬件支持,如突发缓冲,代表了额外的成本。
一个开销更低的检查点方案将使系统能够更经济地提供服务。
MTBF(故障间平均时间)Mean Time Between Failures
作者选择了 [5] 中提到的系统作为基线,该系统包含约 10,000 个节点,通常每天经历大约 2 次故障,其 MTBF 为 12 小时。基于这个数据,作者对规模更大的系统进行了 MTBF 的缩放,并考虑了节点级可靠性较低的系统。这一步骤有助于确定用于模拟的故障间隔时间,以使模拟更贴近实际系统的性能和可靠性特征。
两个数据点来证明了他们选择参数的合理性:
快速估算:对于我们在模拟中选择的每个检查点开销值,我们假设系统级检查点将主内存的一部分写入持久存储。
未来系统要求:具有单个作业平均中断时间超过 24 小时,并且对于增量检查点方案(即将系统 80% 的聚合内存检查点到持久存储的时间),写入检查点的时间应小于 7.2 分钟(432秒)
运行模拟
他们使用不同的参数集对模型进行初始化,并在生成的故障序列上运行模拟,以确定每个基准应用的渐近效率值。这一步骤旨在通过对长时间模拟(10年)的运行来获取对每个基准应用的效率评估。
实验结果
展示了在不同检查点开销下,C/R 系统在有和没有 LetGo 的情况下的效率。
参数:
-
选择了一个 MTBFaults 为 21600 秒(即 MTBF = 12 小时)
-
同步开销为检查点间隔的 10% 。(同步开销:在多节点系统中,为了实现协调一致的检查点,需要对各个节点进行同步操作的时间开销。)

图7展示了在检查点开销为1200秒时,效率提高最多和最少的两个应用
在实验结果中,LetGo 能够提高系统效率,效果在我们的基准应用中为1%到11%之间。随着检查点开销的增加(从12秒到1200秒),所有应用的效率提高,但与此同时,每个应用的绝对效率降低。
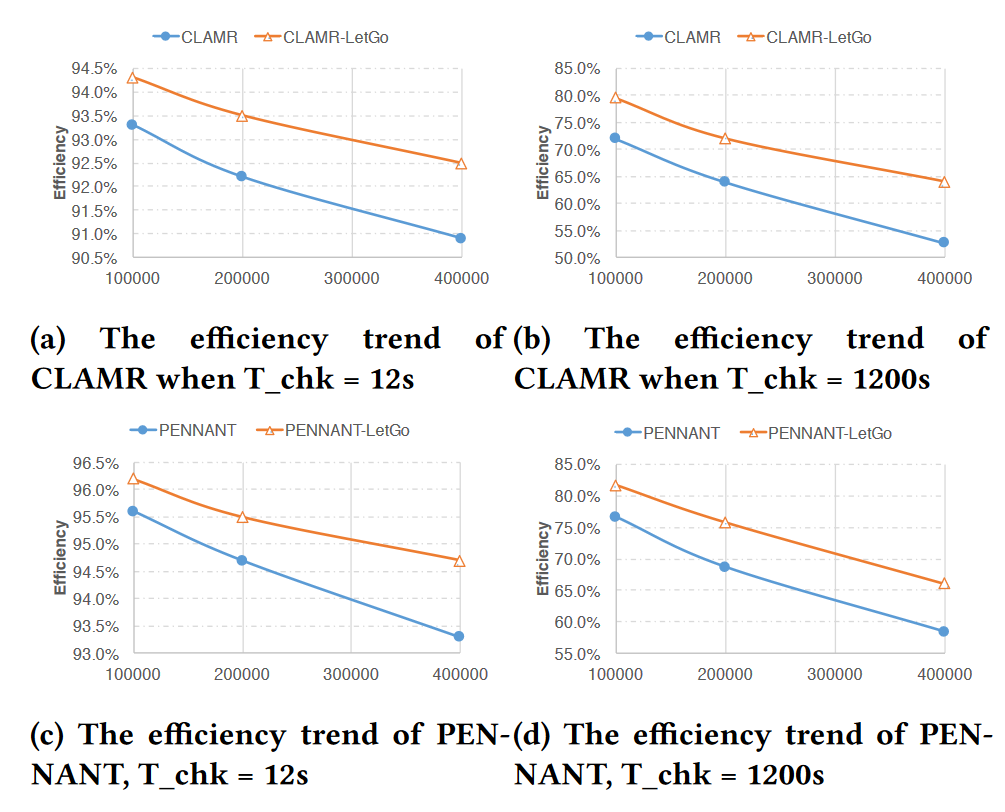
将系统规模从100,000节点扩展到200,000和400,000节点。系统规模的扩大导致整个系统的 MTBF 降低,分别为6小时和3小时。
随着系统规模的增加,系统的效率,包括有和没有 LetGo 的情况,都会降低,这是符合预期的。
对于有 LetGo 的系统,效率下降的速率要低于没有 LetGo 的系统。 这种趋势在所有基准应用中都是一致的,表明 LetGo 在系统规模增大时提供了更好的效率。
讨论
对HPL运行letgo的结果
HPL 的应用级别的验收检查更加严格,这使得 HPL 成为 LetGo 的一个潜在良好选择。然而,尽管 HPL 的崩溃率仍然较高(34%),但低于其他基准应用的崩溃率,其他应用的崩溃率约为 60%。这可能会减轻 LetGo 的影响。
LetGo 本身并不适用于像 HPL 这样的应用程序,可能需要其他的错误纠正机制(例如 ABFT)来处理这类程序。
何时/如何用letgo
这段文字讨论了运算符在决定是否使用 LetGo 时可能考虑的一些因素:
i) 系统多频繁经历导致应用程序崩溃的硬件故障;
ii) 在使用 LetGo 的情况下,应用程序经历额外 SDC 的可能性;
iii) 特定 C/R 方案对该应用程序和部署的检查点开销;
iv) 可接受的SDC 率增加。
目标是大规模的应用程序
当前的 LetGo 实现专注于单线程场景。主要的设计和实现基础没有阻碍扩展到并发/多线程应用程序。
硬件故障模型
导致应用程序崩溃的位翻转仍然是故障的常见根本原因。
由于 LetGo 允许应用程序在出现错误的情况下继续运行,因此可能可以将其用于应用程序特定的硬件容错机制的(重新)配置,以实现节能
- Applications Lightweight Continuous Framework Failuresapplications lightweight continuous framework failures root authentication failures身份 indexing failures时报 数据 lightweight cryptographic failures control warrior applications self-supervised transformers lightweight supervised continuous lightweight translating pseudocode mechanism