作者
pengdonglin137@163.com
现象
在一台ARM64的Centos7虚拟机里加载 https://github.com/504ensicsLabs/LiME 编译出的内核模块时发生宕机:
insmod limi.ko path=/root/allmem.dump format=raw
上面的目的是把机器物理内存的内容全部dump到文件中,大致的实现过程是,遍历系统中所有的"System RAM",然后处理每一个物理页:根据物理页帧获取对应的page,然后调用kmap_atomic得到虚拟地址,最后将这个虚拟页的数据读取出来存放到文件中。
分析
宕机的调用栈如下:
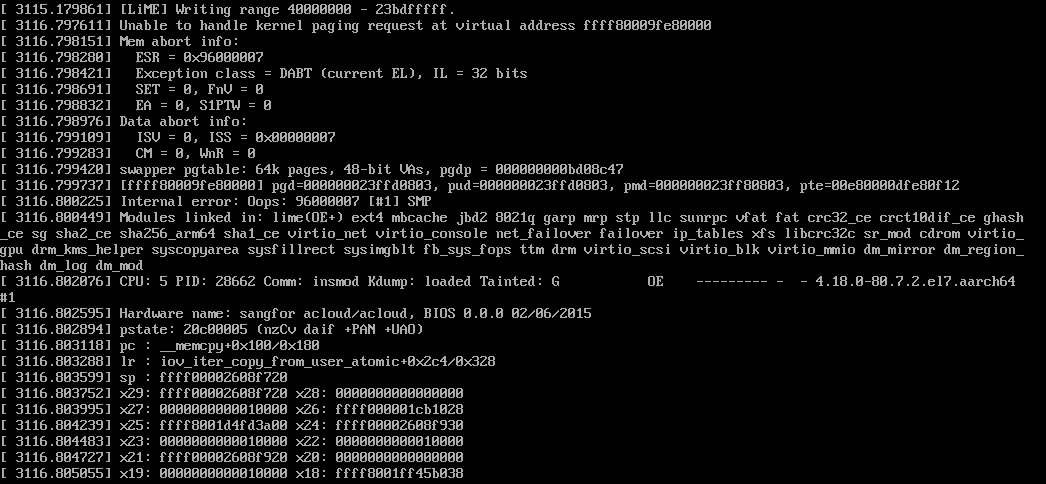
如果对ARM64的页表属性很熟悉的话,应该可以看出PTE的bit0是0,说明这是一个无效的PTE,虽然其他的bit看上去很正常。
如果对页表熟悉不熟的话,当然也可以分析,就是麻烦一些,下面按不熟的方法来。
在源码中加调试语句,把每次访问的物理也的信息打印出来:
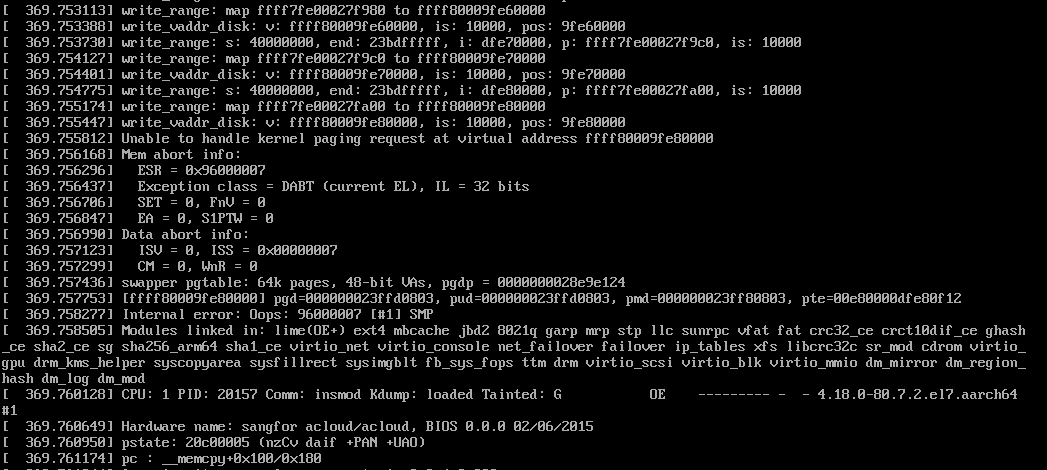
反复几次,发现每次都是这个地址出错0xffff80009fe80000,对应的物理地址是0xdfe80000。
为了测试这个问题,我单独写了一个demo模块,单独去访问这个地址,发现确实会宕机。
查看代码,发现驱动中使用kmap_atomic获取page对应的虚拟地址:

看上去直接返回的是这个page对应的64KB物理内存在直接映射区的虚拟地址,而且是在开机时就映射好的,没有道理不能访问呀:
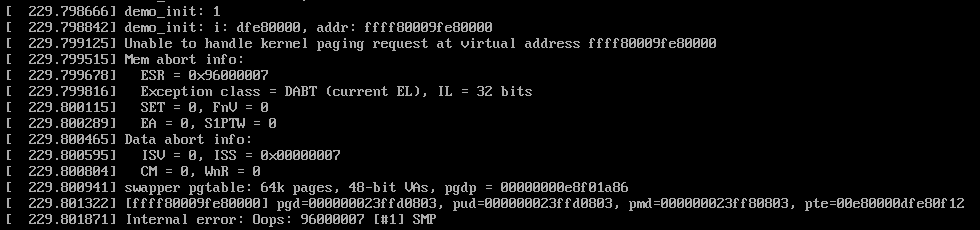
ESR的内容记录了发生异常的原因,在读的时候发生了DARA ABORT异常。
查看这段物理地址空间在crash kernel的范围内:(/proc/iomem)
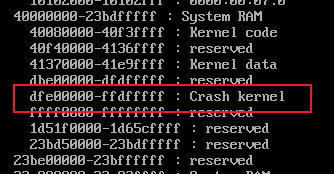
难道跟crash kernel有关?暂时放下这个。
那是不是可以把之前可以访问的物理页的映射信息也打出来比较一下呢?
那么如何将某个虚拟地址的页表映射信息输出呢?
内核提供了show_pte这个函数:arch/arm64/mm/fault.c
void show_pte(unsigned long addr)
{
struct mm_struct *mm;
pgd_t *pgdp;
pgd_t pgd;
if (is_ttbr0_addr(addr)) {
/* TTBR0 */
mm = current->active_mm;
if (mm == &init_mm) {
pr_alert("[%016lx] user address but active_mm is swapper\n",
addr);
return;
}
} else if (is_ttbr1_addr(addr)) {
/* TTBR1 */
mm = &init_mm;
} else {
pr_alert("[%016lx] address between user and kernel address ranges\n",
addr);
return;
}
pr_alert("%s pgtable: %luk pages, %llu-bit VAs, pgdp=%016lx\n",
mm == &init_mm ? "swapper" : "user", PAGE_SIZE / SZ_1K,
vabits_actual, (unsigned long)virt_to_phys(mm->pgd));
pgdp = pgd_offset(mm, addr);
pgd = READ_ONCE(*pgdp);
pr_alert("[%016lx] pgd=%016llx", addr, pgd_val(pgd));
do {
pud_t *pudp, pud;
pmd_t *pmdp, pmd;
pte_t *ptep, pte;
if (pgd_none(pgd) || pgd_bad(pgd))
break;
pudp = pud_offset(pgdp, addr);
pud = READ_ONCE(*pudp);
pr_cont(", pud=%016llx", pud_val(pud));
if (pud_none(pud) || pud_bad(pud))
break;
pmdp = pmd_offset(pudp, addr);
pmd = READ_ONCE(*pmdp);
pr_cont(", pmd=%016llx", pmd_val(pmd));
if (pmd_none(pmd) || pmd_bad(pmd))
break;
ptep = pte_offset_map(pmdp, addr);
pte = READ_ONCE(*ptep);
pr_cont(", pte=%016llx", pte_val(pte));
pte_unmap(ptep);
} while(0);
pr_cont("\n");
}
但是函数并没有调用EXPORT_SYMBOL_GPL导出给模块用,怎么办呢?
可以使用内核提供的kallsyms_lookup_name来获取这个函数的地址:
void (*func)(unsigned long addr);
func = kallsyms_lookup_name("show_pte");
func(addr);
如果内核连kallsyms_lookup_name都没有导出怎么办?
可以使用kprobe。在调用register_kprobe注册kprobe的时候,会根据设置的函数名称得到函数地址,然后存放到kprobe->addr中,那么我们可以先只设置kprobe->symbol_name,当注册成功可以访问kprobe->addr得到函数的地址。目前在最新的6.5版本的内核里,register_kprobe也是导出的。
有了show_pte,那么可以输出之前几个地址的PTE的内容:
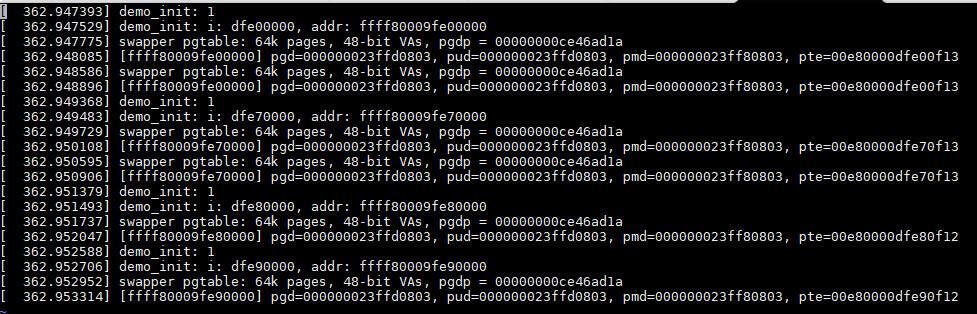
对比发现PTE的值排除物理地址占用的bit外,属性部分只有bit0的内容不同。
既然kmap_atomic直接返回了物理页的线性地址,那么可不可以通过ioremap把这个有问题的物理地址重新映射一下呢? 我测试了一下,不行,在ioremap时会检查要映射的物理地址是否是合法的系统物理内存地址,更明确地说是DDR内存,这里要跟设备内存地址区别开来。如果是系统物理内存,那么直接返回0. 这么处理也好理解,既然是ioremap,当然应该针对的是io memory,如寄存器地址。下面是ARM64上ioreamp的定义:
#define ioremap(addr, size) __ioremap((addr), (size), __pgprot(PROT_DEVICE_nGnRE))
#define ioremap_nocache(addr, size) __ioremap((addr), (size), __pgprot(PROT_DEVICE_nGnRE))
#define ioremap_wc(addr, size) __ioremap((addr), (size), __pgprot(PROT_NORMAL_NC))
#define ioremap_wt(addr, size) __ioremap((addr), (size), __pgprot(PROT_DEVICE_nGnRE)
void __iomem *__ioremap(phys_addr_t phys_addr, size_t size, pgprot_t prot)
{
return __ioremap_caller(phys_addr, size, prot,
__builtin_return_address(0));
}
static void __iomem *__ioremap_caller(phys_addr_t phys_addr, size_t size,
pgprot_t prot, void *caller)
{
unsigned long last_addr;
unsigned long offset = phys_addr & ~PAGE_MASK;
int err;
unsigned long addr;
struct vm_struct *area;
/*
* Page align the mapping address and size, taking account of any
* offset.
*/
phys_addr &= PAGE_MASK;
size = PAGE_ALIGN(size + offset);
/*
* Don't allow wraparound, zero size or outside PHYS_MASK.
*/
last_addr = phys_addr + size - 1;
if (!size || last_addr < phys_addr || (last_addr & ~PHYS_MASK))
return NULL;
/*
* Don't allow RAM to be mapped.
*/
if (WARN_ON(pfn_valid(__phys_to_pfn(phys_addr))))
return NULL;
area = get_vm_area_caller(size, VM_IOREMAP, caller);
if (!area)
return NULL;
addr = (unsigned long)area->addr;
area->phys_addr = phys_addr;
err = ioremap_page_range(addr, addr + size, phys_addr, prot);
if (err) {
vunmap((void *)addr);
return NULL;
}
return (void __iomem *)(offset + addr);
}
可以看到,上面的内存属性都是DEVICE MEMORY,其中pfn_valid(__phys_to_pfn(phys_addr))就是用来判断是否是系统物理内存的,如果是的话,返回true,那么ioremap就会直接返回0.
下面分析PTE是怎么构造的呢?
下面分析缺页异常中中构造PTE的部分:
handle_pte_fault
|- do_anonymous_page
|- entry = mk_pte(page, vma->vm_page_prot);
这里vm_page_prot存放的就是PTE中属性部分,这些属性是通过vm_get_page_prot根据vm_flags转换而来:
/* description of effects of mapping type and prot in current implementation.
* this is due to the limited x86 page protection hardware. The expected
* behavior is in parens:
*
* map_type prot
* PROT_NONE PROT_READ PROT_WRITE PROT_EXEC
* MAP_SHARED r: (no) no r: (yes) yes r: (no) yes r: (no) yes
* w: (no) no w: (no) no w: (yes) yes w: (no) no
* x: (no) no x: (no) yes x: (no) yes x: (yes) yes
*
* MAP_PRIVATE r: (no) no r: (yes) yes r: (no) yes r: (no) yes
* w: (no) no w: (no) no w: (copy) copy w: (no) no
* x: (no) no x: (no) yes x: (no) yes x: (yes) yes
*/
pgprot_t protection_map[16] __ro_after_init = {
__P000, __P001, __P010, __P011, __P100, __P101, __P110, __P111,
__S000, __S001, __S010, __S011, __S100, __S101, __S110, __S111
};
pgprot_t vm_get_page_prot(unsigned long vm_flags)
{
pgprot_t ret = __pgprot(pgprot_val(protection_map[vm_flags &
(VM_READ|VM_WRITE|VM_EXEC|VM_SHARED)]) |
pgprot_val(arch_vm_get_page_prot(vm_flags)));
return arch_filter_pgprot(ret);
}
EXPORT_SYMBOL(vm_get_page_prot);
上面这些宏定义在arch/arm64/include/asm/pgtable-prot.h中,
#define PAGE_NONE __pgprot(((_PAGE_DEFAULT) & ~PTE_VALID) | PTE_PROT_NONE | PTE_RDONLY | PTE_NG | PTE_PXN | PTE_UXN)
#define PAGE_SHARED __pgprot(_PAGE_DEFAULT | PTE_USER | PTE_NG | PTE_PXN | PTE_UXN | PTE_WRITE)
#define PAGE_SHARED_EXEC __pgprot(_PAGE_DEFAULT | PTE_USER | PTE_NG | PTE_PXN | PTE_WRITE)
#define PAGE_READONLY __pgprot(_PAGE_DEFAULT | PTE_USER | PTE_RDONLY | PTE_NG | PTE_PXN | PTE_UXN)
#define PAGE_READONLY_EXEC __pgprot(_PAGE_DEFAULT | PTE_USER | PTE_RDONLY | PTE_NG | PTE_PXN)
#define __P000 PAGE_NONE
#define __P001 PAGE_READONLY
#define __P010 PAGE_READONLY
#define __P011 PAGE_READONLY
#define __P100 PAGE_READONLY_EXEC
#define __P101 PAGE_READONLY_EXEC
#define __P110 PAGE_READONLY_EXEC
#define __P111 PAGE_READONLY_EXEC
#define __S000 PAGE_NONE
#define __S001 PAGE_READONLY
#define __S010 PAGE_SHARED
#define __S011 PAGE_SHARED
#define __S100 PAGE_READONLY_EXEC
#define __S101 PAGE_READONLY_EXEC
#define __S110 PAGE_SHARED_EXEC
#define __S111 PAGE_SHARED_EXEC
其中BIT0对应的是宏是PTE_VALID,有问题的PTE的BIT0确实是0.
然后搜索一下这个宏在内核中的用法,发现使用这个宏的函数还不少:
int set_memory_valid(unsigned long addr, int numpages, int enable)
{
if (enable)
return __change_memory_common(addr, PAGE_SIZE * numpages,
__pgprot(PTE_VALID),
__pgprot(0));
else
return __change_memory_common(addr, PAGE_SIZE * numpages,
__pgprot(0),
__pgprot(PTE_VALID));
}
/*
* This function is used to determine if a linear map page has been marked as
* not-valid. Walk the page table and check the PTE_VALID bit. This is based
* on kern_addr_valid(), which almost does what we need.
*
* Because this is only called on the kernel linear map, p?d_sect() implies
* p?d_present(). When debug_pagealloc is enabled, sections mappings are
* disabled.
*/
bool kernel_page_present(struct page *page);
static inline pte_t pte_mkpresent(pte_t pte)
{
return set_pte_bit(pte, __pgprot(PTE_VALID));
}
static inline int pte_protnone(pte_t pte)
{
return (pte_val(pte) & (PTE_VALID | PTE_PROT_NONE)) == PTE_PROT_NONE;
}
接着看到arch_kexec_protect_crashkres调用了set_memory_valid,这个函数是给crash_kernel所在的内存设置属性的,将那段内存映射的属性设置为无效,防止被破坏。
void arch_kexec_protect_crashkres(void)
{
int i;
kexec_segment_flush(kexec_crash_image);
for (i = 0; i < kexec_crash_image->nr_segments; i++)
set_memory_valid(
__phys_to_virt(kexec_crash_image->segment[i].mem),
kexec_crash_image->segment[i].memsz >> PAGE_SHIFT, 0);
}
结合之前看到的iomem的内容,基本可以确认就是这导致的。
下面验证了一下,将/etc/default/grub中配置的crashkernel=auto删除,然后重新生成grub.cfg,重启后再次加载limi模块就可以正常运行了。