发表时间:2021(ICML 2021)
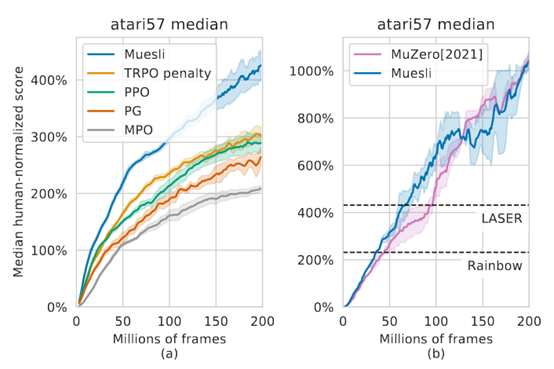
文章要点:这篇文章提出一个更新policy的方式,结合regularized policy optimization 以及model learning as an auxiliary loss。最后直接用policy net输出动作,不做搜索,就能有很好的效果。
具体的,作者提出了clipped MPO (CMPO) regularizer的更新方式。Regularizer为KL散度


有了Regularizer之后,更新就是PG

接着就是用model学一个辅助任务,在model里执行k步,然后有一个policy,用来和真实环境里的policy算一个KL的约束

然后差不多就结束了。作者在这前其实还提了一些设计思路和需要考虑的东西,感觉有点废话,不过还是放到这里

总结:感觉主要的地方已经变成policy optimization了,muzero里面的learned model,tree search基本上都被弱化了,就有点不像是search的算法了。
疑问:里面解释了很多有的没的,没有细看。
- Improvements Optimization Combining Muesli Policyimprovements optimization combining muesli discretizing optimization continuous on-policy optimization proximal policy ppo muesli combining improvements out-performs propagation combining networks improvements performance amp thread improvements performance exceptions reflection amp improvements performance native