Combining
Muesli: Combining Improvements in Policy Optimization
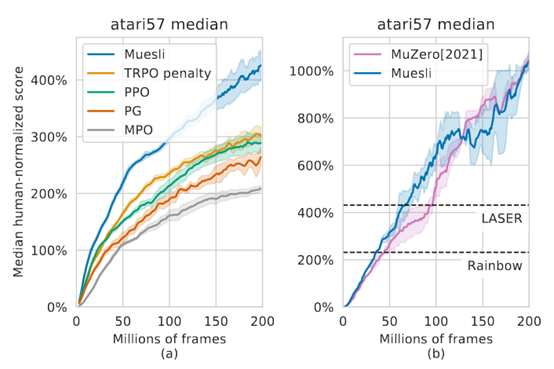 **发表时间:**2021(ICML 2021) **文章要点:**这篇文章提出一个更新policy的方式,结合 ......
Feb 2023-Replay Memory as An Empirical MDP: Combining Conservative Estimation with Experience Replay
将 replay memory视为经验 replay memory MDP (RM-MDP),并通过求解该经验MDP获得一个保守估计。MDP是非平稳的,可以通过采样有效地更新。基于保守估计设计了价值和策略正则化器,并将其与经验回放(CEER)相结合来正则化DQN的学习。 ......
Combining Label Propagation and Simple Models Out-performs Graph Neural Networks
[TOC] > [Huang Q., He H., Singh A., Lim S. and Benson A. R. Combining label propagation and simple models out-performs graph neural networks. ICLR, 20 ......