原文连接:https://blog.csdn.net/weixin_43651049/article/details/122733618
1. 理解线性回归模型
回归模型研究的是因变量(目标)和自变量(预测器)之间的关系,因变量可以是连续也可以离散,如果是离散的就是分类问题。思考房价预测模型,我们可以根据房子的大小、户型、位置、南北通透等自变量预测出房子的售价,这是最简单的回归模型,在初中里面回归表达式一般这样写,其中x是自变量,y是因变量,w是特征矩阵,b是偏置。
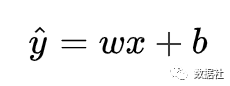
2. 回归问题
各个数据点都沿着一条主轴来回波动的问题都算是回归问题。
2.1 回归和分类
回归问题和分类问题最大的区别在于预测结果:
连续——回归
离散——分类
根据预测值类型的不同,预测结果可以分为两种:连续和离散,结果是连续的就是预测问题。
“连续”不是一个简单的形容词,而是有着严格的数学定义。最直接的例子就是时间,时间当然是连续的,连续型数值在编程时通常用int和float类型来表示,包括线性连续和非线性连续两种。相比之下,离散型数值的最大特征是缺乏中间过渡值,所以总会出现“阶跃”的现象,譬如“是”和“否”,通常用bool类型来表示。
3. 预测未来
回归问题是一类预测连续值的问题,而能满足这样要求的数学模型称作回归模型。
机器学习的回归模型预测未来的条件:需要有充足的历史数据。只要找到相关联的线索,就能够推理出最终的结果。预测难在待预测对象与什么相关是未知的,但其中的关联关系藏在历史数据之中,需要通过机器学习算法把它挖掘出来。
从数学角度来看,就是对输入数据点的拟合。
3.1 机器学习实现预测的流程
墙体坍塌可能由许多偶然因素导致,我们都不是土木专家,不妨凭感觉随手列出几条可能导致墙坍塌的因素:譬如可能与砌墙的材质有关,土坯墙总比水泥墙容易垮塌;可能与使用时间的长短有关;可能与承建商有关,喜欢偷工减料的工程队容易出“豆腐渣工程”;还有一些外部环境因素,譬如整天风吹雨淋的墙容易垮塌;最后就是墙体坍塌之前总会有一些早期迹象,譬如已经出现很多裂缝等。
上面所列因素有三种情况:与坍塌密切相关,与坍塌有点关系,以及与坍塌毫无瓜葛。如果人工完成预测任务,当然最重要的工作就是找出哪些是密切相关的,放在第一位;哪些是有点关系的,放在参考位置;哪些毫无瓜葛,统统删掉。可是我们又怎么知道哪些因素有哪些关系呢?这时我们就可以制作一张调查表,把砌墙用的什么材料、已经用了多久、出现了多少条裂缝等情况一一填进去,这就是前面所说的数据集中每一条样本数据的维度。就像商家很喜欢通过网上问卷来了解用户偏好一样,我们也利用调查表来了解墙体坍塌有什么“偏好”。
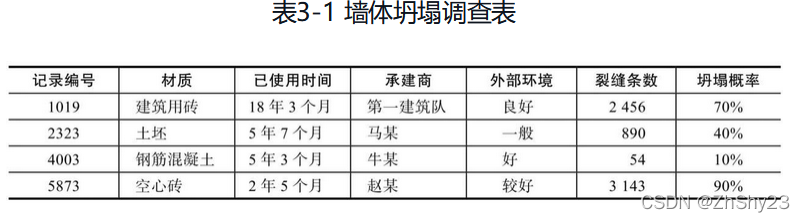
最后一栏“坍塌概率”,这是我们最关心的,也是有监督学习所必需的,这些已知的坍塌概率以及相关的维度数据将为未知概率的预测提供重要帮助。
最后也是最关键的一步,是找出各个维度和坍塌之间的概率,而这个步骤将由模型自行完成。我们要做的只是将长长的历史数据输入回归模型,回归模型就会通过统计方法寻找墙体坍塌的关联关系,看看使用时间的长短和承建商的选择谁更重要,相关术语叫做训练模型,从数学的角度看,这个过程就是通过调节模型参数从而拟合数据。
模型训练完毕后,再把当前要预测的墙体情况按数据维度依次填好,回归模型就能告诉我们当前墙体坍塌概率的预测结果。
3.2 总结
1. 收集数据;
2. 找出数据各个维度与结果之间的概率;
3. 将历史数据输入回归模型——训练模型——调节模型参数从而拟合数据;
4. 模型训练完毕后,把当前要预测的结果按数据维度依次填好,回归模型进行预测。
4. 线性方程
线性——像直线那样
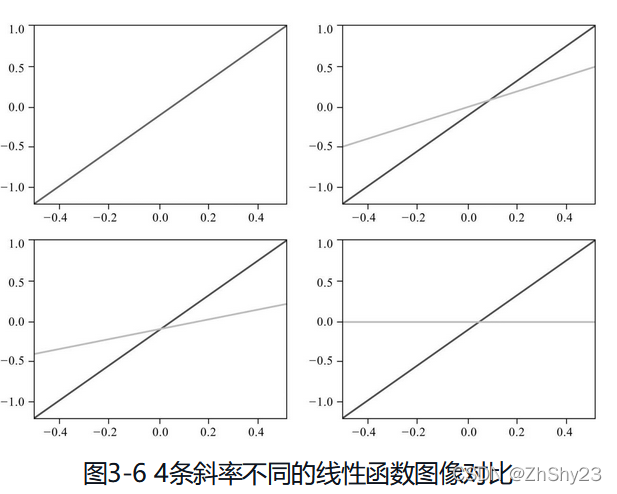
直线方程通常写成:y=kx+b,k为斜率,b为截距。
这两个参数空值直线进行“旋转”和“平移”动作。
调整斜率,可以“旋转”直线:
调整截距,实现直线的上下平移:
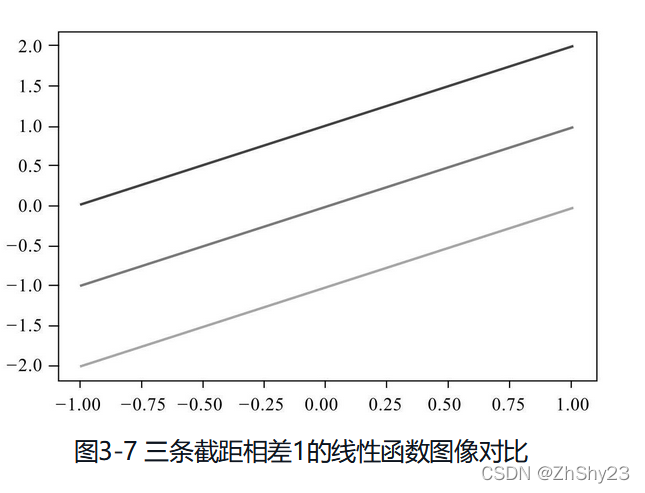
线性方程与直线方程存在差距:直线是二维平面图像,线性所在的空间是多维的;
机器学习中,斜率k使用权值w表示,通过调整w和b的值就能控制直线在多维空间中进行旋转和平移;
这个通过调整权值来达到目的的过程叫做权值调整或者权值更新,对于线性模型而言,学习过程的主要工作就是权值调整,只要旋动旋钮,合理搭配旋转和平移这两套简单的动作,就能完成对输入数据的拟合工作,从而解决回归问题。
4.1 权值调整
在机器学习中,通过调整权值来完成学习,并最终进行预测的算法很多,这也是一种非常常见的学习手段。对于为什么调整权值能够进行预测,实际上也有多种解释,上面从几何角度给出了解释,此外还有代数角度的解释。
以三个输入维度A、B、C来预测P为例,我们的线性方程可以写为:
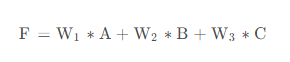
假设我们知道P的值其实就是与A的值有关,与B、C毫无关系,那么,怎样调整线性方程才可以根据输入准确预测出P的值呢?
我们知道,线性方程的计算结果F是三个维度的加权和,想要使F与P最接近,只需要让线性方程中B、C这两个加项对结果影响最小即可。这个好办,只要使这两项的权值最小,也就是W2和W3的值为0就可以了。
这就是从代数角度来解释为什么调整权值能够提高预测结果的准确性。这里实际上体现了一种假设,就是待预测的结果与输入的某个或某几个维度相关,而调整权值的目的就是使得与预测结果相关度高的权值越高,确保相关维度的值对最终加权和的贡献越大,反之权值越低,贡献越小。
5. 线性回归的算法原理
5.1 拟合
对于一个线性回归问题,也就是说,这里的“神秘方程”就是一个线性方程,相应的数据集点也一定是根据线性排布的,那么,我们要做的就是不断调整线性方程的两个按钮,作出一条能够一一通过这些点的直线,也就是拟合。这个能够拟合数据集点的线性方程,就是我们要找的“神秘方程”。
我们知道调整的目的是使得线性方程尽可能拟合数据集点,而调整的方法是通过旋动旋钮来调整权值,但仔细一想就会发现还缺失中间一环:怎样调整权值才能最终达到拟合数据的目标?
这里触及到机器学习的最核心概念:在错误中学习。
这中间一环需要分两个步骤:首先知道偏离了多少,然后向减少偏差的方向调整权值。
“在错误中学习”也不只是简单一句话,具体来说需要经过以下两个步骤:
偏差度量:想要修正弹道,我们不仅要知道偏了,还要知道偏了多少,找到目标和实际的偏差距离。日常中我们会选择用尺子一类的工具来度量距离,而在机器学习中我们使用“损失函数”,数学家已经为我们准备好了“尺子”,多款数学工具都可用于度量偏差的距离。
权值调整:调整权值要解决两个细节问题,即权值是要增加还是减少、增加多少或者减少多少?
再一次感谢数学家,这两个问题都可以直接使用现成的数学工具进行解决,机器学习中将这些数学工具称为“优化方法”。