Introduction
Here we re-evaluate llama2 benchmarks to prove its performence.
datasets
In this blog, we'll test the following datasets shown in the images.
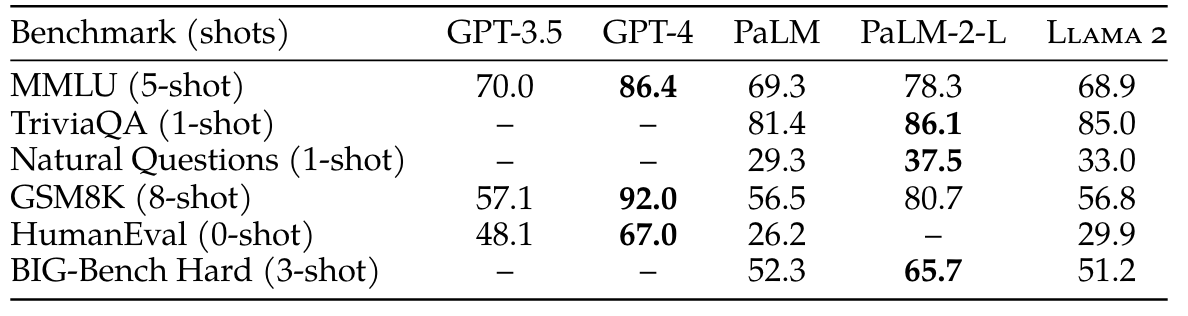
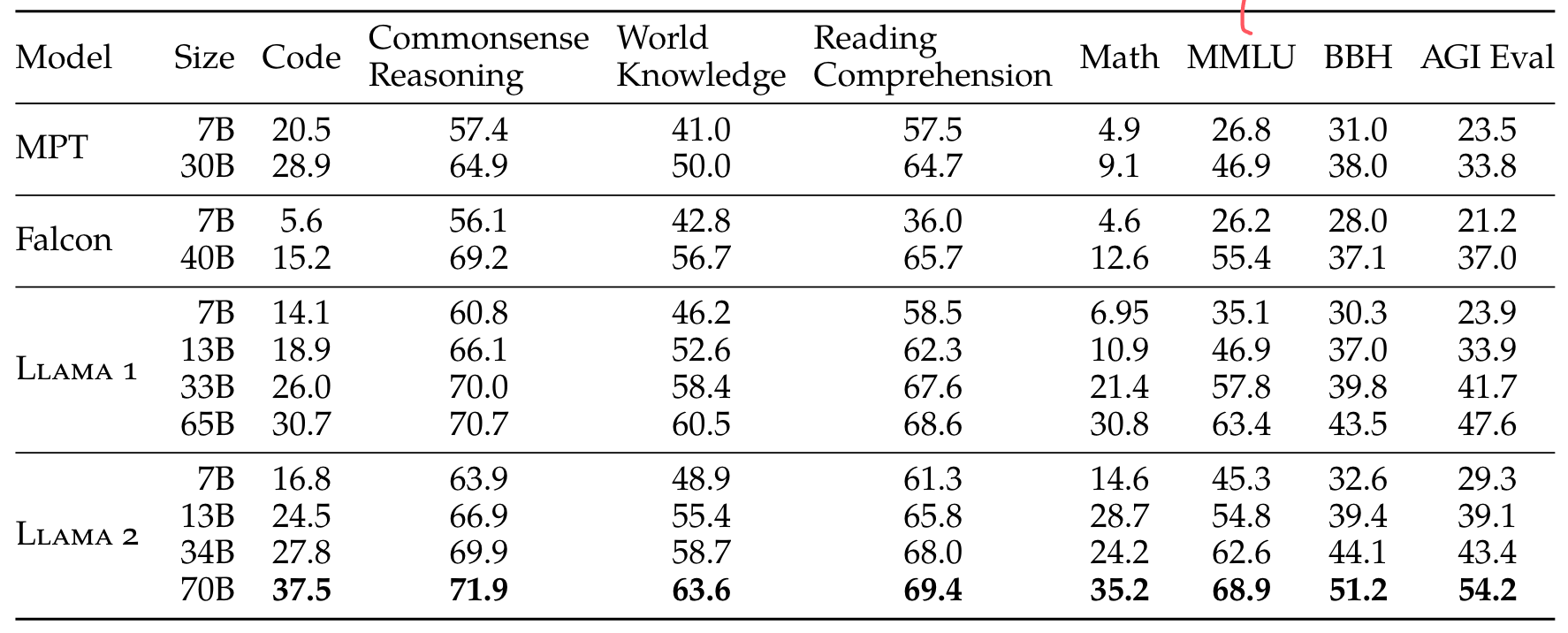
from here you can find the dataset
- Code. We report the average pass@1 scores of our models on HumanEval (Chen et al., 2021) and MBPP (Austin et al., 2021).
- Commonsense Reasoning. We report the average of PIQA (Bisk et al., 2020), SIQA (Sap et al., 2019), HellaSwag (Zellers et al., 2019a), WinoGrande (Sakaguchi et al., 2021), ARC easy and challenge (Clark et al., 2018), OpenBookQA (Mihaylov et al., 2018), and CommonsenseQA (Talmor et al., 2018). We report 7-shot results for CommonSenseQA and 0-shot results for all other benchmarks.
- World Knowledge. We evaluate the 5-shot performance on NaturalQuestions (Kwiatkowski et al., 2019) and TriviaQA (Joshi et al., 2017) and report the average.
- Reading Comprehension. For reading comprehension, we report the 0-shot average on SQuAD (Rajpurkar et al., 2018), QuAC (Choi et al., 2018), and BoolQ (Clark et al., 2019).
- MATH. We report the average of the GSM8K (8 shot) (Cobbe et al., 2021) and MATH (4 shot) (Hendrycks et al., 2021) benchmarks at top 1.
mmlu: address
TriviaQA: huggingface address1 huggingface address2
GSM8K: huggingface address
HumanEval: huggingface address
BIG-Bench Hard: huggingface address
Hella-Swag: huggingface address
NQ(natural question): github address huggingface address
MBPP: huggingface address
PIQA: huggingface address
SIQA: huggingface address
ARC: huggingface address
WinoGrande: huggingface address
OpenBookQA: huggingface address
CommonsenseQA: huggingface address
SQuAD: huggingface address SQuADv2
QuAC: huggingface address
BooIQ: huggingface address